Quadrupped-Legged Robot Movement Plan Generation using Large Language Model
Abstract: Traditional control interfaces for quadruped robots often impose a high barrier to entry, requiring specialized technical knowledge for effective operation. To address this, this paper presents a novel control framework that integrates LLMs to enable intuitive, natural language-based navigation. We propose a distributed architecture where high-level instruction processing is offloaded to an external server to overcome the onboard computational constraints of the DeepRobotics Jueying Lite 3 platform. The system grounds LLM-generated plans into executable ROS navigation commands using real-time sensor fusion (LiDAR, IMU, and Odometry). Experimental validation was conducted in a structured indoor environment across four distinct scenarios, ranging from single-room tasks to complex cross-zone navigation. The results demonstrate the system's robustness, achieving an aggregate success rate of over 90\% across all scenarios, validating the feasibility of offloaded LLM-based planning for autonomous quadruped deployment in real-world settings.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows a new, easier way to control a dog-like, four-legged robot. Instead of using complicated controls or programming, people can simply type what they want in normal language (like “Go to the pantry, then to the lab”), and an AI system turns those words into step-by-step moves the robot can follow. Because the robot’s small computer isn’t powerful enough to run the AI by itself, the heavy thinking happens on another computer (a server), while the robot handles the actual moving and sensing.
What did the researchers want to know?
- Can regular people give natural-language instructions and have a quadruped robot understand and act correctly?
- Can a big LLM safely turn those instructions into a clear, step-by-step plan the robot can execute?
- If the AI “brain” runs on an external server, can the robot still move smoothly and reliably in real time?
- How often does the system succeed in different types of tasks, from simple (within one room) to complex (across multiple areas)?
How did they do it?
The robot and its “senses”
- The robot is a quadruped called the Jueying Lite 3.
- It has sensors:
- LiDAR: like a spinning laser “scanner” that measures distances to build a 3D picture of the room (think of it as the robot’s “laser eyes”).
- IMU: like an inner ear that helps it know its tilt and movement.
- Odometry: keeps track of how far it has walked.
- These sensors are combined (sensor fusion) so the robot knows where it is and where obstacles are.
Teaching the robot the building
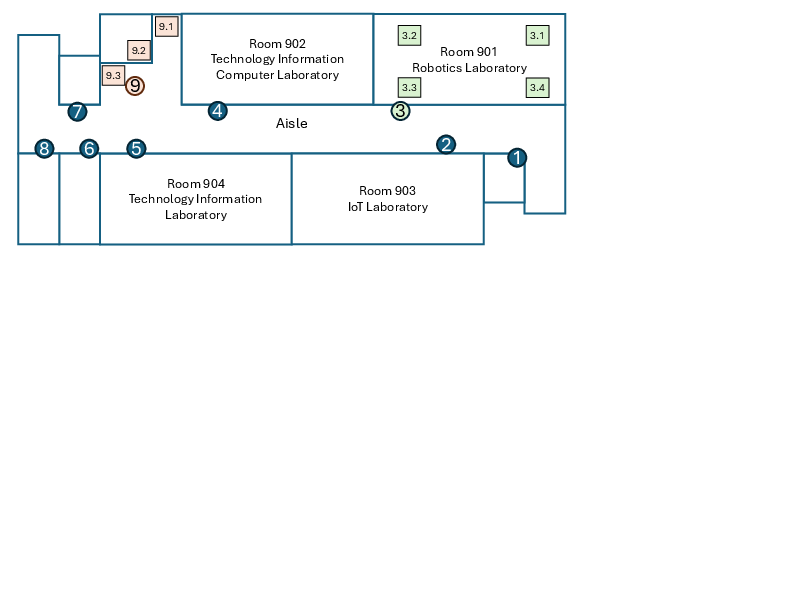
- The team first made a detailed indoor map using SLAM (Simultaneous Localization and Mapping). You can imagine SLAM like drawing your own floor plan while walking around.
- They marked important places on the map as “waypoints,” like “Lab Door,” “Pantry Shelf,” or “Elevator.” A waypoint is simply a named spot with coordinates on the map—like a pin dropped on a digital floor plan.
Talking to the robot
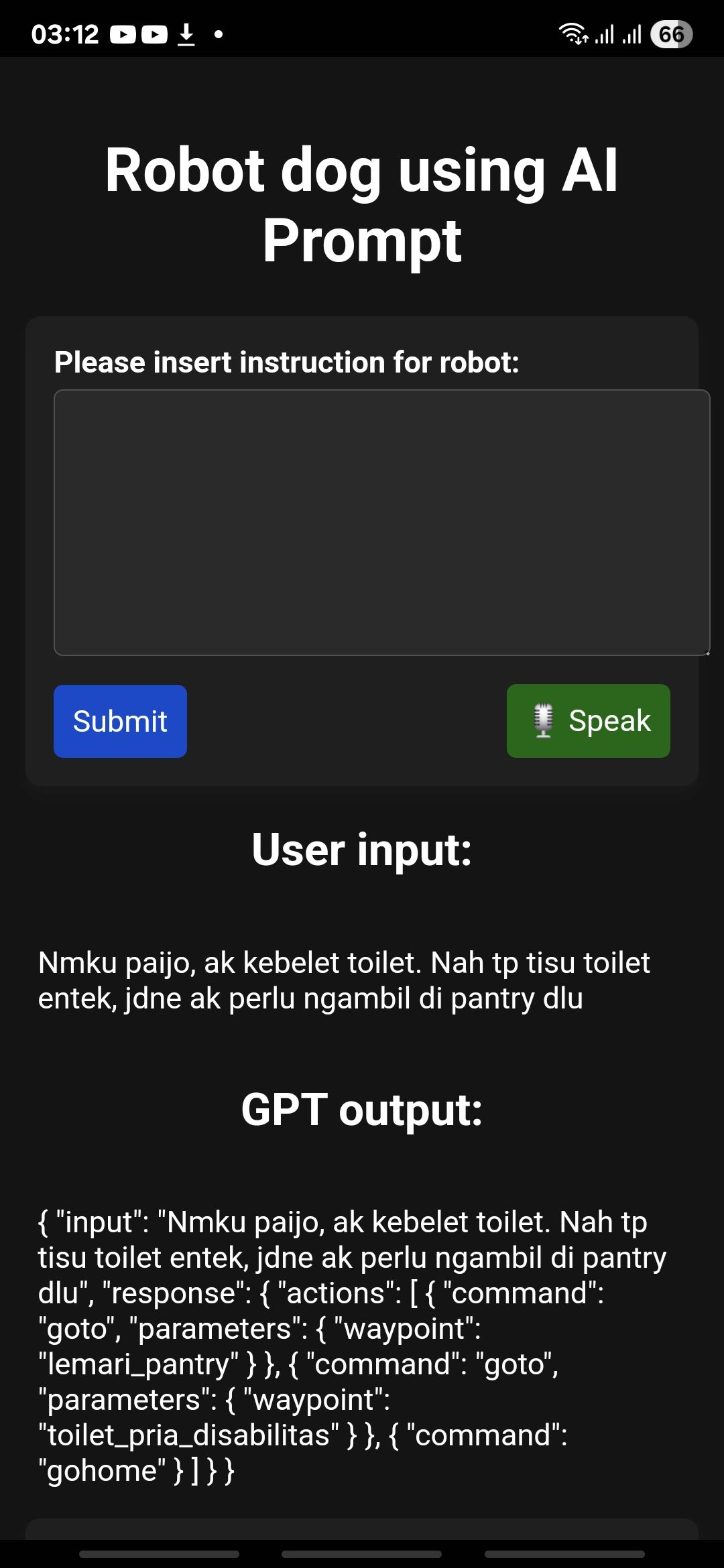
- A simple web page (made with Flask) lets a user type instructions in everyday language (they used Indonesian in the tests).
- An LLM (Google Vertex AI Gemini) reads the instruction and outputs a plan in JSON (a neat, computer-friendly list of steps). Example actions look like:
- command: "goto", parameters: { waypoint: "pantry" }
- command: "wait", parameters: { seconds: 10 }
- The researchers designed careful prompts so the LLM:
- Uses only allowed actions (like goto, wait).
- Avoids making up fake places.
- Follows examples that show how to break a long instruction into several steps.
Who does the heavy thinking?
- The robot has two onboard computers:
- Motion host: talks to motors and sensors.
- Perception host: handles mapping and planning.
- A third machine, the “development host” (off the robot), runs the LLM. Think of it like calling a smart friend for advice: the robot asks the server, “What’s the plan?”, then follows it locally.
- This setup is called “offloading” because the AI work is moved off the robot to a stronger computer.
Turning plans into motion
- The JSON plan from the LLM is sent to ROS (Robot Operating System), which is like the robot’s operating system for movement.
- ROS uses the map and waypoints to plan paths and send safe, step-by-step movement commands.
- As the robot moves, its sensors keep it on track and help avoid obstacles.
What did they find?
They tested four kinds of tasks in a real building (labs, hallways, pantry, restrooms, elevator):
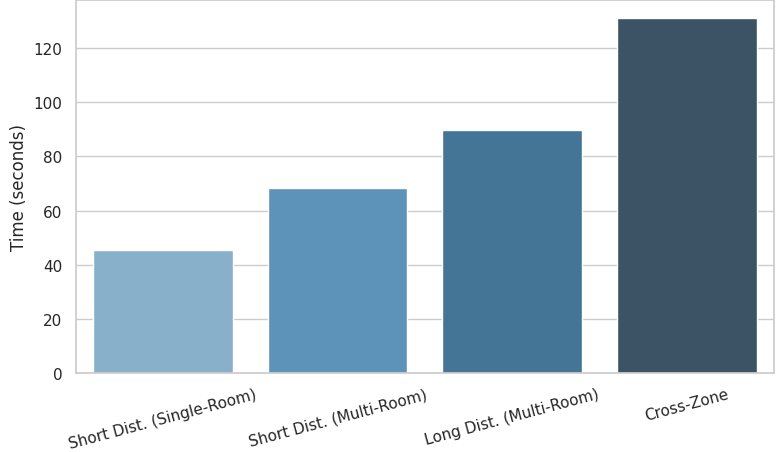
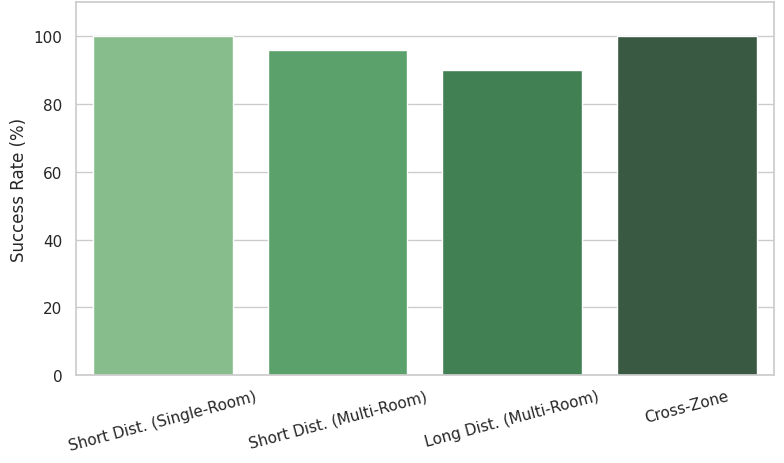
- Single-room short tasks: 100% success, average 45.26 seconds
- Multi-room short tasks (nearby places): 96% success, average 68.27 seconds
- Multi-room long tasks (farther apart): 90% success, average 89.71 seconds
- Cross-zone tasks (several areas in one trip): 100% success, average 130.98 seconds
Overall, the system succeeded in more than 90% of trials. As tasks got longer and more complex, they took more time (which makes sense), but success stayed high. When failures happened, they mostly came from local navigation issues (like adjusting paths), not from the LLM’s planning. The LLM’s JSON plans were consistently correct and usable.
Why this matters:
- It proves that natural-language control for a quadruped robot can work well in the real world.
- Offloading the AI to an external server makes this possible even with a lightweight, cheaper robot computer.
What does this mean for the future?
- Easier robot use: People without programming skills can guide robots in labs, offices, schools, or hospitals just by typing or speaking instructions.
- Lower cost and weight: Robots don’t need big, power-hungry onboard GPUs because the AI can run elsewhere.
- More capable service robots: The team plans to add:
- RAG (Retrieval-Augmented Generation) so the robot can remember previous instructions and use them as context.
- Vision-LLMs so the robot can understand what it sees (e.g., “That’s the pantry shelf”) and adjust on the fly.
In short, this research shows a practical way to make dog-like robots more helpful and easier to control, bringing us closer to everyday, human-friendly robot helpers.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, articulated as concrete, actionable items for future research.
- Generalization beyond a single, structured indoor site: Evaluate in diverse buildings, unstructured layouts, outdoor settings, and cluttered/dynamic environments.
- Dynamic obstacle handling and closed-loop plan repair: Integrate real-time feedback to update or re-plan LLM-generated sequences when the environment changes mid-execution.
- Expressivity of the action vocabulary: Extend beyond
gotoandwaitto support conditional logic, loops, branching, error recovery, and task-level optimization (e.g., route reordering). - Legged locomotion constraints: Assess compatibility between ROS move_base-style planning and quadruped footstep/gait constraints; add terrain-aware locomotion, stairs, and narrow passage handling.
- Cross-floor navigation realism: Move from “go to elevator” waypoints to actual elevator interaction (call, ride, exit) or stair traversal, with safety and reliability guarantees.
- Robustness to natural language variability: Test multilingual inputs, speech-to-text pipelines, colloquial phrasing, typos, synonyms, and ambiguous commands; implement clarification dialogues.
- Safety guarantees and formal verification: Establish formal constraints, runtime safety monitors, and certification-ready evidence that LLM plans cannot generate unsafe behaviors or hallucinated waypoints.
- Cloud dependency and latency: Quantify end-to-end latency (LLM inference + network roundtrip) and its impact on responsiveness; evaluate offline fallback (local or edge models), caching, and degraded modes.
- Security, access control, and adversarial inputs: Harden the Flask interface and prompt pipeline against unauthorized access, prompt injection, and malicious commands; define authentication and role-based restrictions.
- JSON schema adherence and recovery: Provide guarantees (or detectors) for strictly valid JSON outputs; implement auto-correction, schema validation, and fallback behaviors for malformed or incomplete plans.
- Mapping and semantic waypoint upkeep: Automate POI creation, update, and synchronization when the environment changes; measure localization drift and its effect on waypoint accuracy.
- Baselines and comparative evaluation: Compare LLM-based interface against traditional GUIs/teleoperation, symbolic planners, or rule-based parsers on task success, efficiency, and user burden.
- Metrics beyond success rate and average time: Report LLM inference time, network bandwidth/latency, CPU/GPU utilization, battery consumption, localization accuracy, and failure mode taxonomy.
- Failure analysis depth: Provide root-cause analysis for multi-room failures (e.g., localization errors, costmap issues, LLM misinterpretation); quantify how each subsystem contributes to failure rates.
- Route optimality and efficiency: Assess whether LLM plan ordering is near-optimal; integrate path cost awareness (e.g., travel time, congestion, energy) into the planner.
- Social navigation and HRI: Evaluate behavior around people (comfort distance, etiquette, yielding), and conduct user studies on intuitiveness, trust, workload, and satisfaction.
- Privacy and data governance: Analyze risks of sending user commands/context to cloud LLMs; define data retention, anonymization, and compliance policies.
- Scalability and multi-user/robot coordination: Test concurrent users, command arbitration, multi-robot tasking, and scheduling under shared resources.
- Reproducibility and transparency: Release the exact system prompt(s), code, map assets, and datasets of commands; specify model versions, parameters (e.g., temperature), and ROS planner configurations.
- Integration with perception (VLM) and memory (RAG): Move beyond stated future work to empirically validate how visual grounding and long-horizon memory improve plan correctness and robustness.
- Handling of no-go zones and permissions: Incorporate semantic constraints (restricted areas, time-based access, gender-specific restrooms) into planning and user feedback.
- Robustness to network outages: Define timeouts, retries, local buffering, and safe fallback behaviors when connectivity to the LLM service is lost mid-task.
- Task compositionality and object interaction: Explore object search, recognition, and manipulation (where feasible for the platform), including alignment between language goals and sensory evidence.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be implemented now with the paper’s architecture (LLM offloading, ROS navigation, 3D LiDAR SLAM, semantic waypoints, Flask web interface, cloud LLM).
- Sector: Education and Research — Natural-language building guide on campuses
- Use case: “Guide me to TW903, then the elevator,” with multi-room and cross-zone navigation (validated in the paper).
- Tools/products/workflows: Semantic waypoint map of campus building; Flask web UI; LLM-to-ROS bridge publishing JSON “goto” actions; RViz-based localization; HDL-Localization for 3D maps.
- Assumptions/dependencies: Pre-mapped indoor environment; stable Wi‑Fi for LLM calls; safe robot routes; staff oversight during initial deployment.
- Sector: Enterprise/Office — Autonomous indoor courier and errand-running
- Use case: Delivering items between labs/offices/pantry; “Go to lab shelf, then pantry, then elevator nearest to pantry.”
- Tools/products/workflows: “LLM Navigation Controller” (server) + ROS move_base; semantic POI catalog (lab shelves, assembly tables, pantries); operator web UI.
- Assumptions/dependencies: Defined routes and POIs; hallway clearance; elevator integration via human assistance or external control system; battery management scheduling.
- Sector: Industrial Facilities — Facility inspection and routine patrols
- Use case: Natural-language patrol sequences across rooms and corridors (e.g., restrooms, pantry, elevators).
- Tools/products/workflows: Patrol plan templates with LLM prompt; JSON action primitives (“goto,” “wait”); ROS logs for audit; time-based schedule triggers.
- Assumptions/dependencies: Reliable localization; updated semantic waypoints; policies for human-robot interaction in shared spaces.
- Sector: Hospitality/Museums — Robotic docent or wayfinding assistant
- Use case: Escort visitors across exhibits or rooms using spoken or typed requests.
- Tools/products/workflows: Visitor mobile interface; content-linked POIs; operator override via RViz; fleet dashboard for multiple robots.
- Assumptions/dependencies: Crowd-aware speed limits; signage and staff processes; consistent connectivity.
- Sector: Healthcare (non-clinical logistics) — Portering within structured hospital floors
- Use case: Moving supplies/specimens between wards and labs using natural-language tasks (pilot-level deployments).
- Tools/products/workflows: Hospital floor POIs; governance guardrails in the LLM prompt (restricted zones, infection control).
- Assumptions/dependencies: Compliance approvals; staff co-supervision; map accuracy; robust handoff workflow at elevators/doors.
- Sector: Software/Robotics — Developer tooling derived from the paper
- Use case: Packaging the LLM-to-ROS bridge and prompt templates; a “Semantic Waypoint Editor” for ROS maps; Flask UI starter kit.
- Tools/products/workflows: Open-source modules for JSON action parsing; CI-tested prompt templates; map/POI annotation workflow; deployment scripts for development host.
- Assumptions/dependencies: ROS ecosystem familiarity; cloud LLM API (e.g., Vertex AI Gemini); LAN/Wi‑Fi configuration.
- Sector: Policy/Operations — Reducing training burden for robot operators
- Use case: Natural-language control for non-experts to execute multi-step navigation plans.
- Tools/products/workflows: Standardized command taxonomies; operator SOPs for mapping, localization, and mission start/stop; audit logs of LLM JSON actions.
- Assumptions/dependencies: Safety gating in prompts (no hallucinated waypoints); versioned semantic maps; escalation paths for failures (e.g., multi-room revalidation).
- Sector: Daily Life — Building errands and assistance in dorms/residential complexes
- Use case: “Pick up package at lobby shelf, bring to pantry, then wait by elevator.”
- Tools/products/workflows: Tenant mobile web app; POI setup in shared areas; action limits and timeout rules.
- Assumptions/dependencies: Building access rules; shared-space etiquette; connectivity; noise and speed constraints.
Long-Term Applications
These applications require further research, scaling, or development (e.g., adding VLM/RAG, improving local navigation recovery, edge inference, multi-robot coordination, regulatory alignment).
- Sector: Robotics/Software — Onboard (edge) LLM planning to remove cloud dependency
- Use case: Running compressed LLMs on Jetson (e.g., Orin) for offline mission planning.
- Tools/products/workflows: Model distillation/quantization; caching prompt results; edge inference orchestration.
- Assumptions/dependencies: Sufficient GPU/TPU resources; acceptable latency; robust fallback behavior.
- Sector: Robotics/Perception — Visual-LLM integration for dynamic grounding
- Use case: “Go to the table with the red toolbox,” on-the-fly visual POI detection/captioning (as envisioned in the paper).
- Tools/products/workflows: Camera calibration; VLM grounding to ROS frames; visual-semantic mapping updates; perception safety filters.
- Assumptions/dependencies: Additional sensors/cameras; compute headroom; data privacy policies for visual data.
- Sector: Enterprise/Healthcare/Hospitality — RAG-enabled personalized and context-aware missions
- Use case: Remember user preferences, past routes, blocked areas, and schedule; adapt plans over long horizons.
- Tools/products/workflows: Mission memory store; RAG pipelines; access controls; PII governance.
- Assumptions/dependencies: Data retention policies; user consent; failure-aware memory updates.
- Sector: Logistics/Operations — Multi-robot fleet coordination via natural language
- Use case: LLM dispatcher produces coordinated JSON plans across robots (“Robot A checks pantry, Robot B patrols restrooms”).
- Tools/products/workflows: Multi-agent ROS; conflict resolution; shared map state; task allocation algorithms.
- Assumptions/dependencies: Reliable inter-robot comms; leader election; fleet safety and collision avoidance.
- Sector: Public Safety/Disaster Response — Semi-structured search-and-rescue
- Use case: Quadrupeds navigate debris-laden or partially mapped areas with natural-language directives.
- Tools/products/workflows: Robust SLAM under degradation; satellite/mesh comms; human-in-the-loop oversight; mission triage prompts.
- Assumptions/dependencies: Terrain-capable hardware; resilience to occlusions; emergency policies and liability frameworks.
- Sector: Smart Buildings/Facilities — Digital twin integration for semantic maps
- Use case: Automatic ingestion of BIM/IFC data to generate and maintain POIs and navigation constraints.
- Tools/products/workflows: Map–twin sync services; zone permissions; dynamic route optimization (e.g., closed corridors).
- Assumptions/dependencies: Building data access; standards alignment; change management process.
- Sector: Standards/Policy — Natural-language command taxonomies and safety guardrails
- Use case: Industry-wide schemas for JSON actions, restricted intents, and verification checks before execution.
- Tools/products/workflows: Prompt governance; safety validators (e.g., waypoint existence, collision risk); audit trail standards.
- Assumptions/dependencies: Multi-stakeholder adoption; regulatory input; interoperability across vendors.
- Sector: Energy/Operations — Mission planning with battery-aware scheduling
- Use case: LLM plans multi-stop routes balancing charge levels and dock availability.
- Tools/products/workflows: Battery telemetry; charging dock mapping; time-window constraints; energy-aware planners.
- Assumptions/dependencies: Accurate energy models; dock infrastructure; forecast of corridor traffic.
- Sector: Localization/Mapping — Autonomous semantic map building and continual refinement
- Use case: Robots learn and label new POIs from operator dialogue (“Mark this table as ‘assembly table’”).
- Tools/products/workflows: Interactive map editors with language input; validation protocols; versioned map releases.
- Assumptions/dependencies: Operator training; anti-hallucination checks; rollback mechanisms.
- Sector: Global Operations — Cross-lingual natural-language control
- Use case: Multi-language support beyond Indonesian for multicultural deployments.
- Tools/products/workflows: Language-specific prompt packs; POI name localization; tokenizer/encoding evaluation.
- Assumptions/dependencies: LLM language coverage quality; cultural and signage differences; translation consistency.
- Sector: Commercialization — LLM Navigation Server (SaaS) for robotics vendors
- Use case: Hosted planning service that converts natural-language tasks to ROS action plans for diverse robot hardware (beyond Jueying Lite 3).
- Tools/products/workflows: Hardware-agnostic adapters; API SLAs; customer onboarding (mapping/POI setup).
- Assumptions/dependencies: Vendor integrations; pricing viability; security and uptime guarantees.
Glossary
- Action Primitives: Basic atomic robot behaviors used to structure LLM outputs. "Action Primitives: A defined list of valid robot behaviors (navigation, exploration, halting)."
- Contextual Constraints: Rules that prevent unsafe or hallucinated outputs from the LLM. "Contextual Constraints: Rules preventing the generation of hallucinated or unsafe waypoints."
- DeepRobotics Jueying Lite 3: A commercially available quadruped robot platform used in the experiments. "DeepRobotics Jueying Lite 3 platform"
- Development host: The computing unit that handles LLM requests and hosts the web interface. "the development host is responsible for handling LLM requests."
- Distributed architecture: A system design where computation is spread across multiple machines, with heavy tasks offloaded. "We propose a distributed architecture where high-level instruction processing is offloaded to an external server"
- Flask-based web server: A Python web server (Flask) providing the robot’s natural language interface. "Flask-based web server hosted by the robot."
- Global planning algorithms: Path-planning methods that operate over the entire map to generate routes. "global planning algorithms"
- Grounding: Linking language instructions to executable actions and environmental affordances. "capable of "grounding" abstract instructions into actionable robotic sequences"
- HDL-Localization: A 3D LiDAR-based SLAM algorithm for mapping and localization. "We utilize HDL-Localization, a 3D LiDAR-based SLAM technique"
- IMU: Inertial Measurement Unit; a sensor for acceleration and rotation used in localization. "IMU sensor"
- LiDAR: Light Detection and Ranging; a laser-based distance sensor for mapping and navigation. "particularly the LiDAR and IMU"
- LLM API: A cloud-hosted interface to call a LLM. "cloud-hosted LLM API"
- LLM inference: The runtime computation performed by an LLM to produce outputs. "offloads the computationally intensive LLM inference to an external server"
- LLMs: Foundation models that process natural language and act as high-level planners. "LLMs to enable intuitive, natural language-based navigation."
- Map frame: The global coordinate frame of the map used by ROS for navigation. "associated with a global coordinate in the map frame"
- Motion host: The on-robot computer interfacing with actuators and low-level sensors. "The motion host is responsible as the main connection to the robot motion actuator and sensor fleet"
- move_base: A ROS navigation component/topic for sending goals and executing paths. "ROS move_base topic"
- NVIDIA Jetson Xavier NX: An embedded GPU computing module used for real-time perception tasks. "The perception host utilizes an NVIDIA Jetson Xavier NX"
- Odometry: Estimation of robot motion over time from sensor data. "(LiDAR, IMU, and Odometry)"
- Perception host: The on-robot computer handling localization, sensor fusion, and planning. "All the sensor fusion and processing used for localization and planning are running inside the perception host."
- Points of Interest (POIs): Semantically labeled locations used as navigation targets. "points of interest such as laboratories, pantries, and elevators"
- ROS: Robot Operating System; middleware for robot software integration and communication. "ROS-compatible SLAM tools"
- ROS Master: The central ROS process that coordinates nodes and topics. "Once the sensor data is available to the ROS Master"
- ROS navigation stack: A set of ROS packages for mapping, planning, and control. "the user launches the ROS navigation stack"
- ROS topics: Publish/subscribe communication channels in ROS. "via ROS topics"
- RViz: A ROS visualization tool for maps, localization, and sensor data. "using RViz"
- SayCan: A framework connecting language to robot actions based on affordances. ""SayCan" framework"
- Semantic Waypoints: Labeled map points representing meaningful locations for navigation. "semantic waypoints representing key points of interest "
- Sensor fusion: Combining multiple sensor modalities to improve state estimation. "real-time sensor fusion (LiDAR, IMU, and Odometry)"
- SLAM: Simultaneous Localization and Mapping; building a map while localizing within it. "SLAM technique"
- System prompt: The initial instruction that configures the LLM’s role and output format. "We employ a carefully engineered system prompt that instructs the LLM (Vertex AI Gemini) to function as a motion planner."
- Vertex AI Gemini: Google’s LLM platform used for motion planning. "Vertex AI Gemini"
- Visual LLM: A model that integrates vision and language for perception-informed planning. "Visual LLM"
Collections
Sign up for free to add this paper to one or more collections.