SSA: Sparse Sparse Attention by Aligning Full and Sparse Attention Outputs in Feature Space
Abstract: The quadratic complexity of full attention limits efficient long-context processing in LLMs. Sparse attention mitigates this cost by restricting each query to attend to a subset of previous tokens; however, training-free approaches often lead to severe performance degradation. Native sparse-attention methods (e.g., NSA, MoBA) alleviate this issue, yet exhibit a critical paradox: they produce lower attention sparsity than full-attention models, despite aiming to approximate full attention, which may constrain their effectiveness. We attribute this paradox to gradient update deficiency: low-ranked key-value pairs excluded during sparse training receive neither forward contribution nor backward gradients, and thus never learn proper suppression. To overcome this limitation, we propose SSA (Sparse Sparse Attention), a unified training framework that considers both sparse and full attention and enforces bidirectional alignment at every layer. This design preserves gradient flow to all tokens while explicitly encouraging sparse-attention outputs to align with their full-attention counterparts, thereby promoting stronger sparsity. As a result, SSA achieves state-of-the-art performance under both sparse and full attention inference across multiple commonsense benchmarks. Furthermore, SSA enables models to adapt smoothly to varying sparsity budgets; performance improves consistently as more tokens are allowed to attend, supporting flexible compute-performance trade-offs at inference time. Finally, we show that native sparse-attention training surprisingly improves long-context extrapolation by mitigating the over-allocation of attention values in sink areas, with SSA demonstrating the strongest extrapolation capability.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making LLMs handle long texts more efficiently without losing accuracy. The authors introduce a new training method called SSA (Sparse Sparse Attention). It helps a model focus on the most important parts of a long input while still learning from everything, so it works well whether you give it limited computing power or let it use full power.
Key Questions
The paper looks at these simple questions:
- How can we make LLMs read long texts faster without checking every single word?
- Why do some “sparse” (more selective) models still end up spreading attention too widely?
- Can we train a model so that its “sparse attention” behaves more like full attention, staying accurate but cheaper to run?
- Will this approach also help the model work better on very long contexts it wasn’t trained on?
How It Works (Methods Explained Simply)
First, some basics with a real-world analogy:
- Think of reading a long book. “Full attention” means carefully checking every sentence you’ve read so far whenever you see a new sentence—very accurate but slow.
- “Sparse attention” means you only look back at the most relevant pages (like your highlighted notes). This is faster but might miss something.
The problem with current sparse attention:
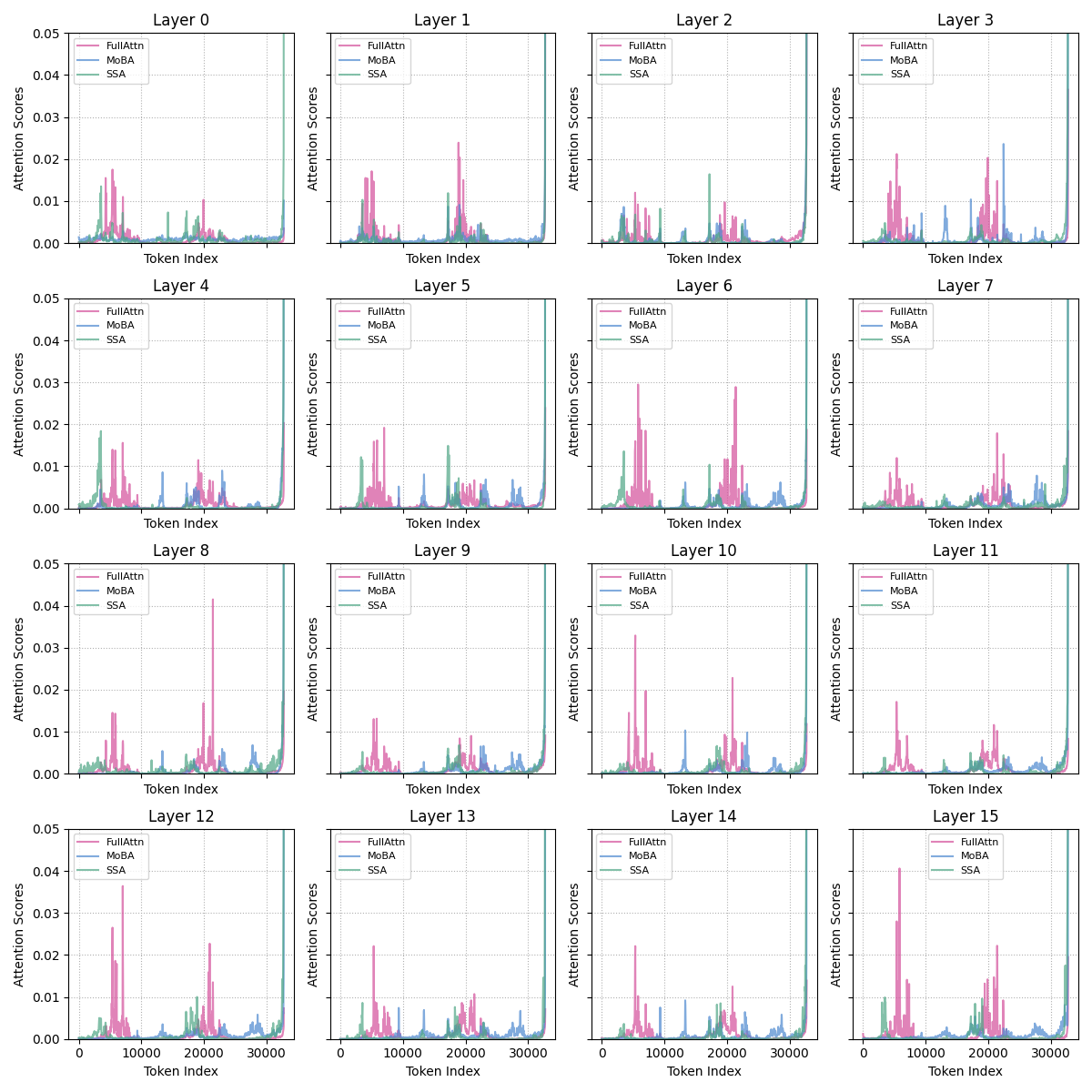
- When training only with sparse attention, the model never sees the unselected words (the ones it didn’t look back to), so it never learns to properly ignore them. Later, if you switch to full attention, the model may spread its focus too widely because it never learned to downweight the unimportant stuff. This weirdly makes “sparse-trained” models less naturally sparse than “full-trained” ones.
What SSA does:
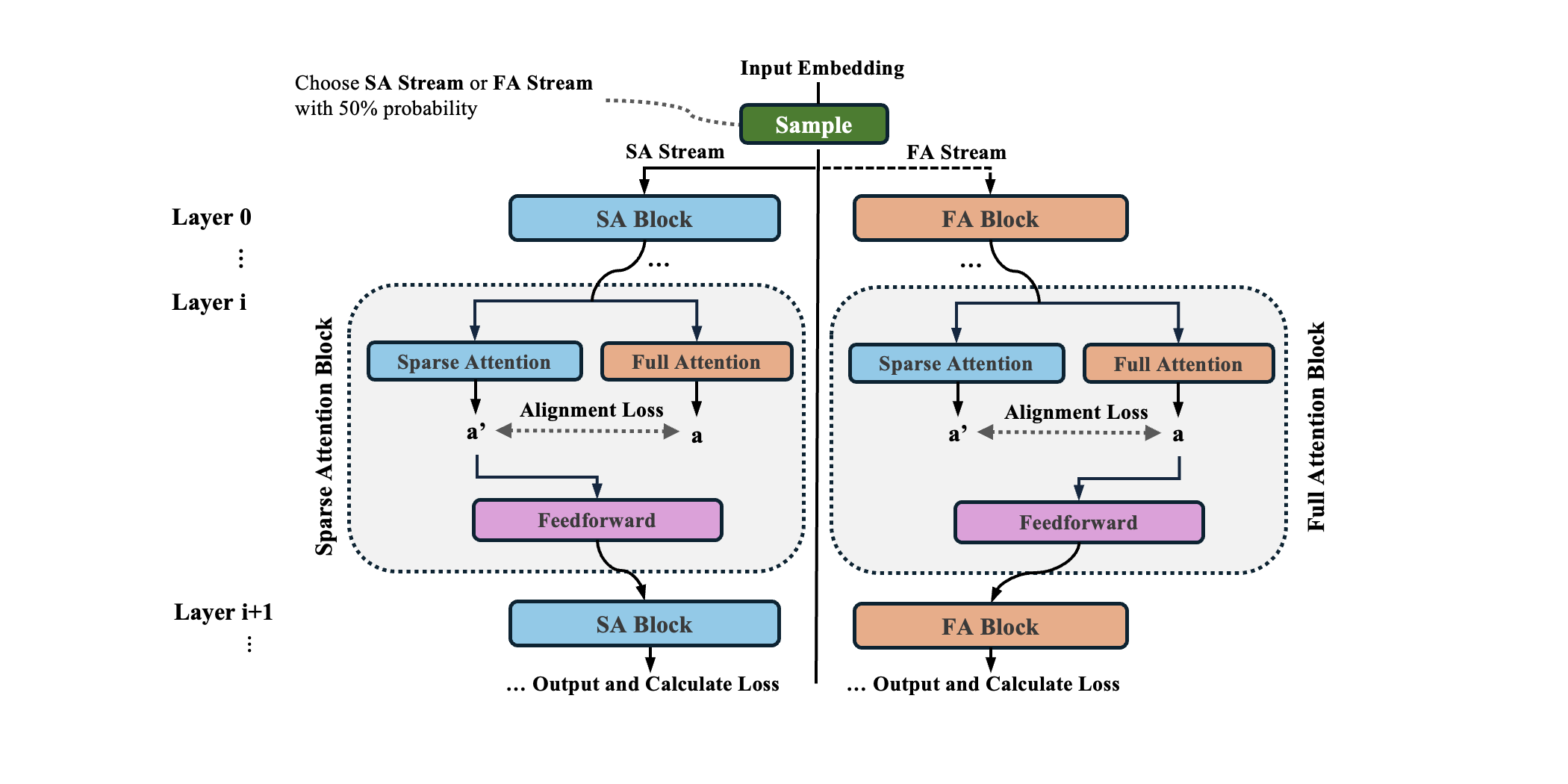
- The model trains in two modes, randomly alternating:
- Full mode: it looks at everything (slow but thorough).
- Sparse mode: it looks at only the top, most relevant chunks (fast and focused).
- At every layer, SSA adds a small “alignment” step:
- In full mode, the model’s output is gently pulled toward what it would have produced using sparse attention.
- In sparse mode, the output is nudged toward what full attention would produce.
- This mutual alignment is like practicing with both the whole textbook and your summary notes, then making sure the two ways of studying agree. The model learns to ignore unimportant tokens while still understanding the big picture.
A bit about “blocks”:
- Instead of picking individual words, the model chunks the text into blocks (like paragraphs).
- It measures how relevant each block is and picks the top-k blocks to attend to.
- This makes selection fast and still captures the most important parts.
Key terms in everyday language:
- Attention: the model’s “focus” on past words.
- Sparsity: keeping that focus tight on a few important places rather than everywhere.
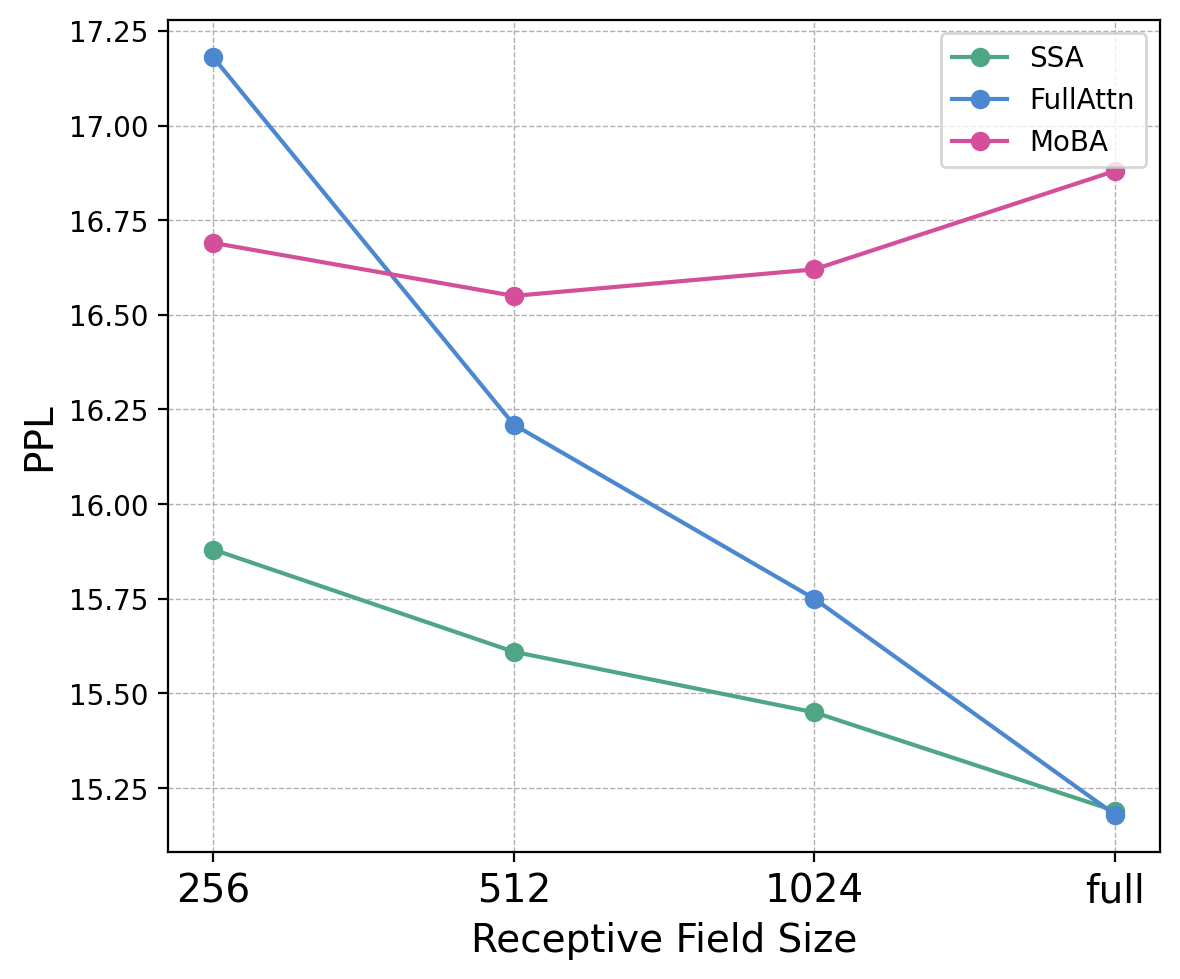
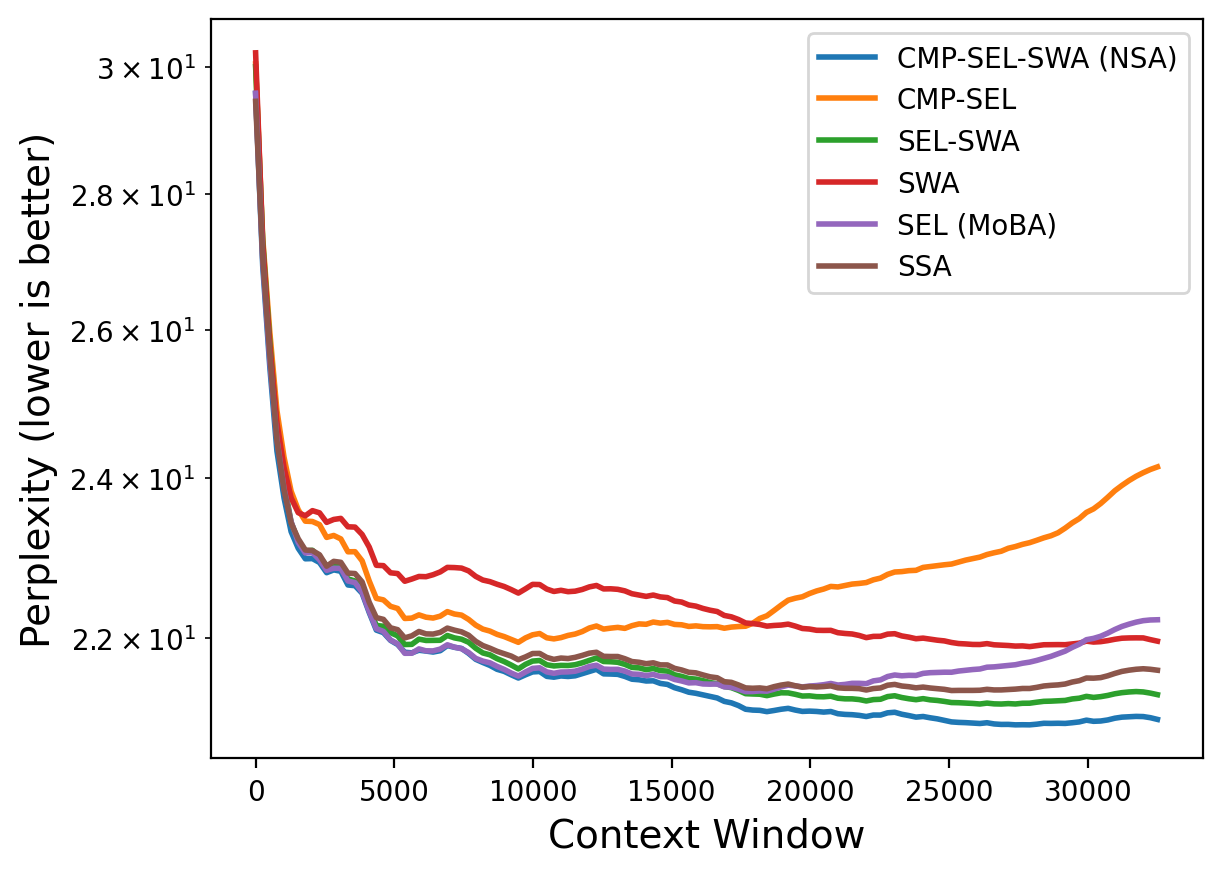
- Perplexity: how “surprised” the model is by the next word; lower is better.
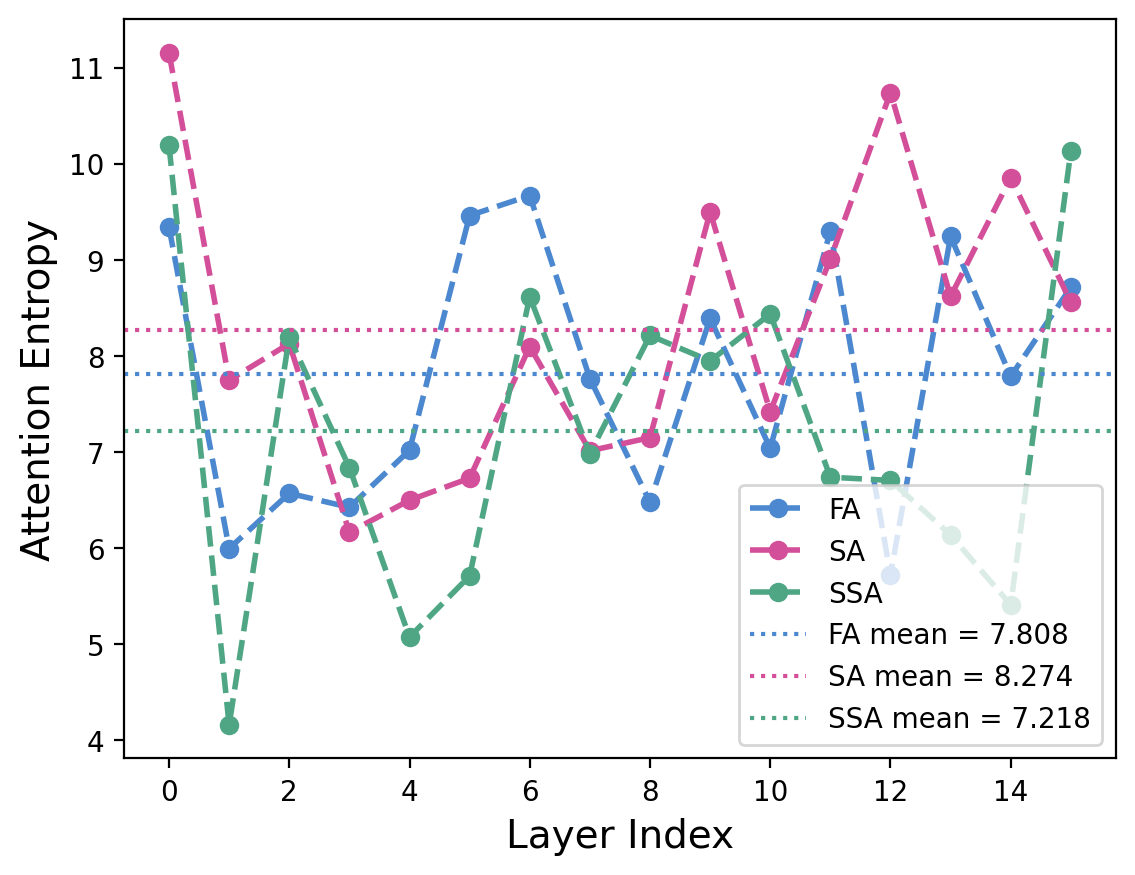
- Entropy: how spread out the attention is; lower means attention is more concentrated.
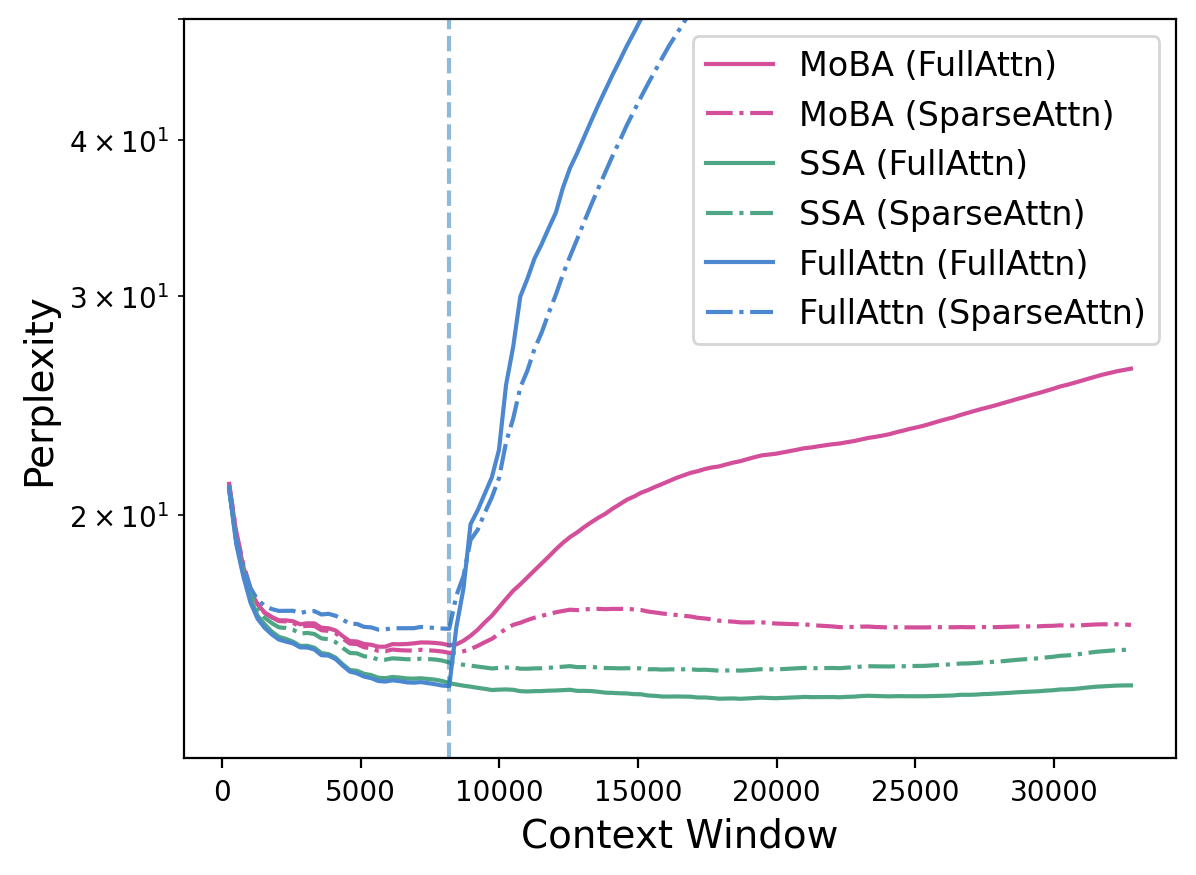
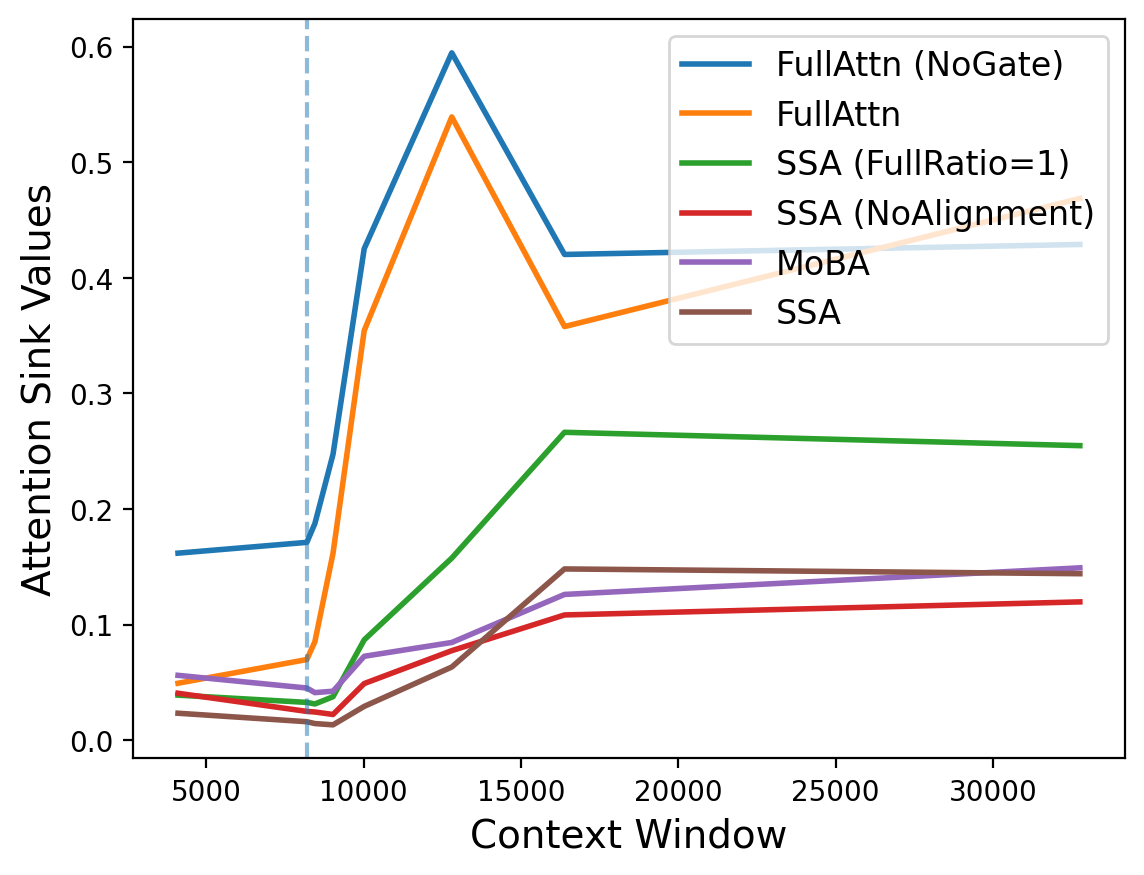
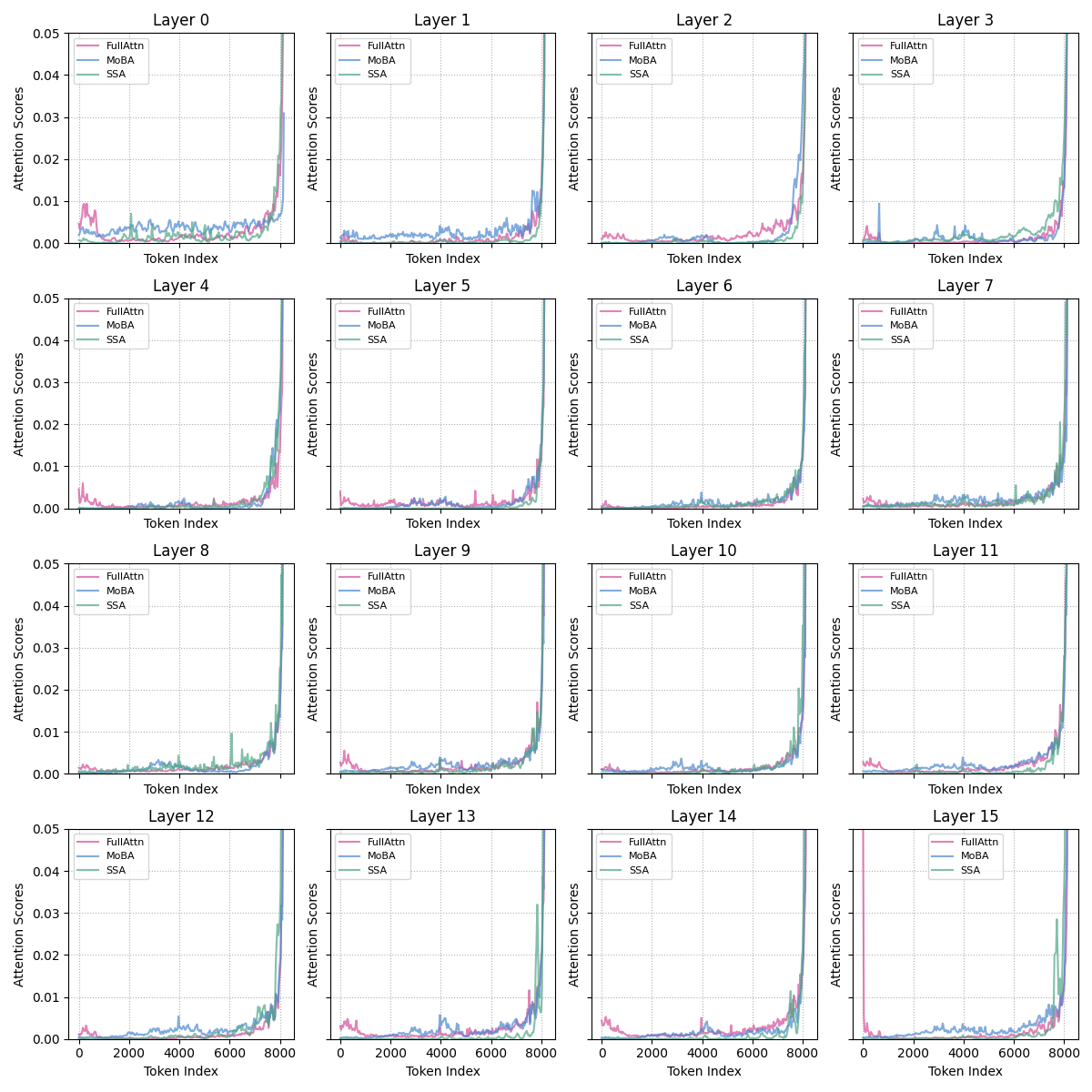
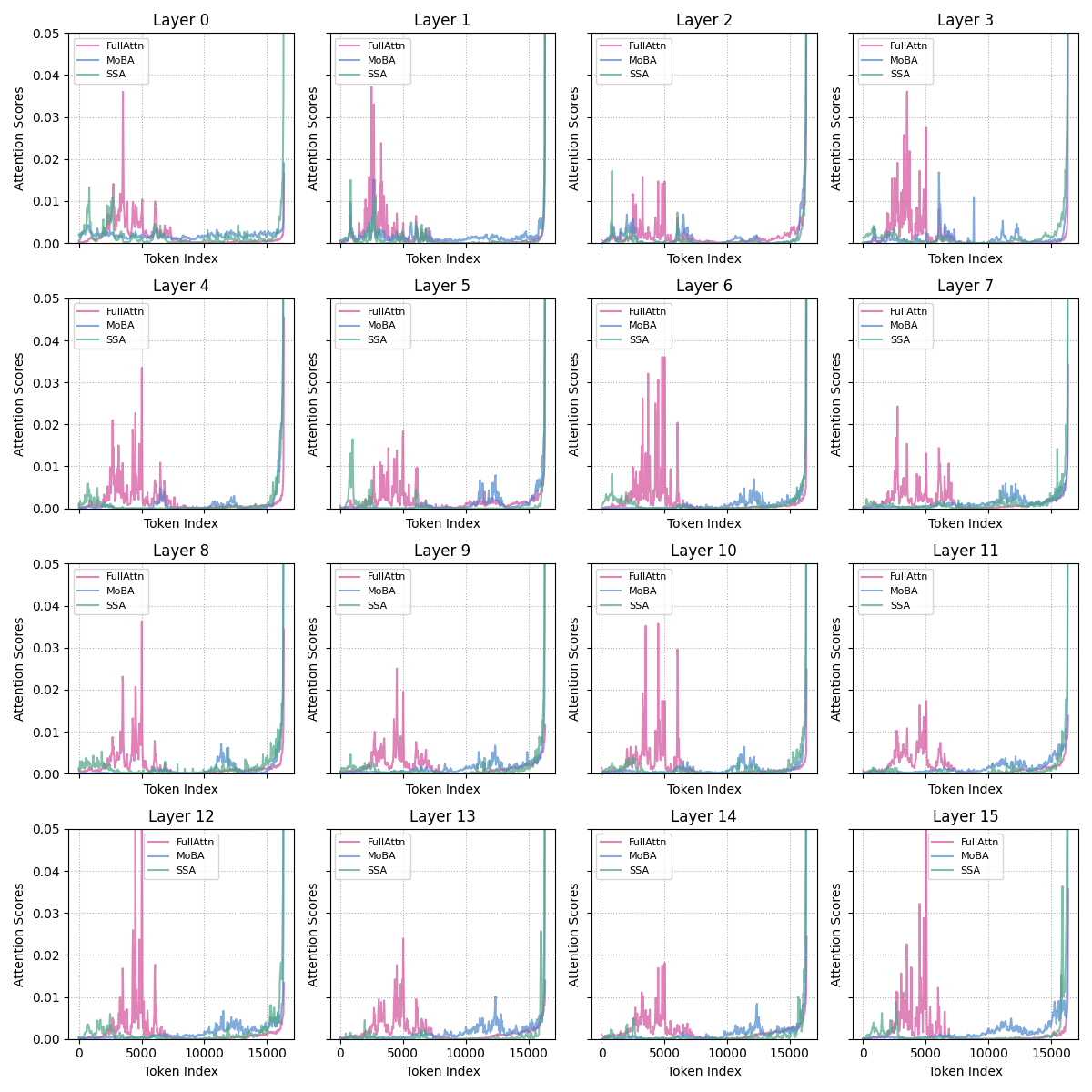
- “Attention sink”: the model over-obsesses over early tokens (like always staring at the first chapter), which hurts it on very long texts.
Main Findings and Why They Matter
What the authors found:
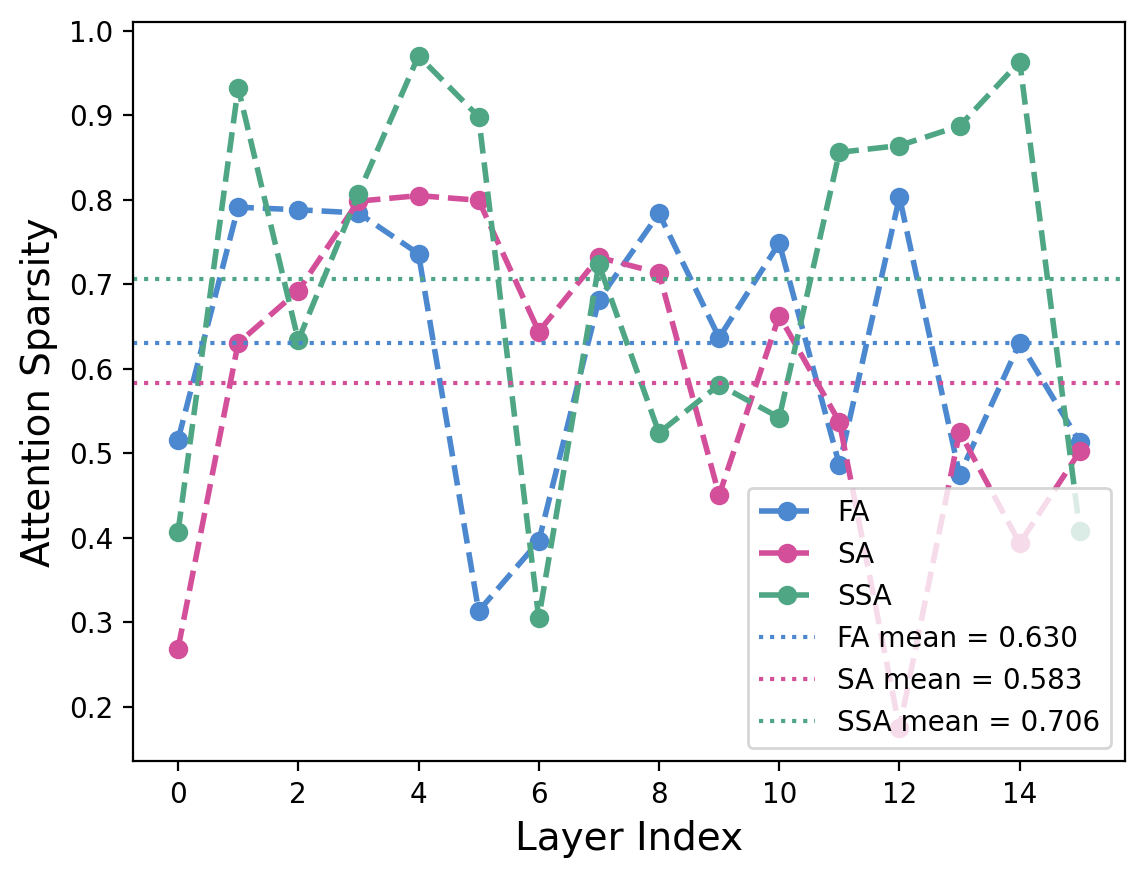
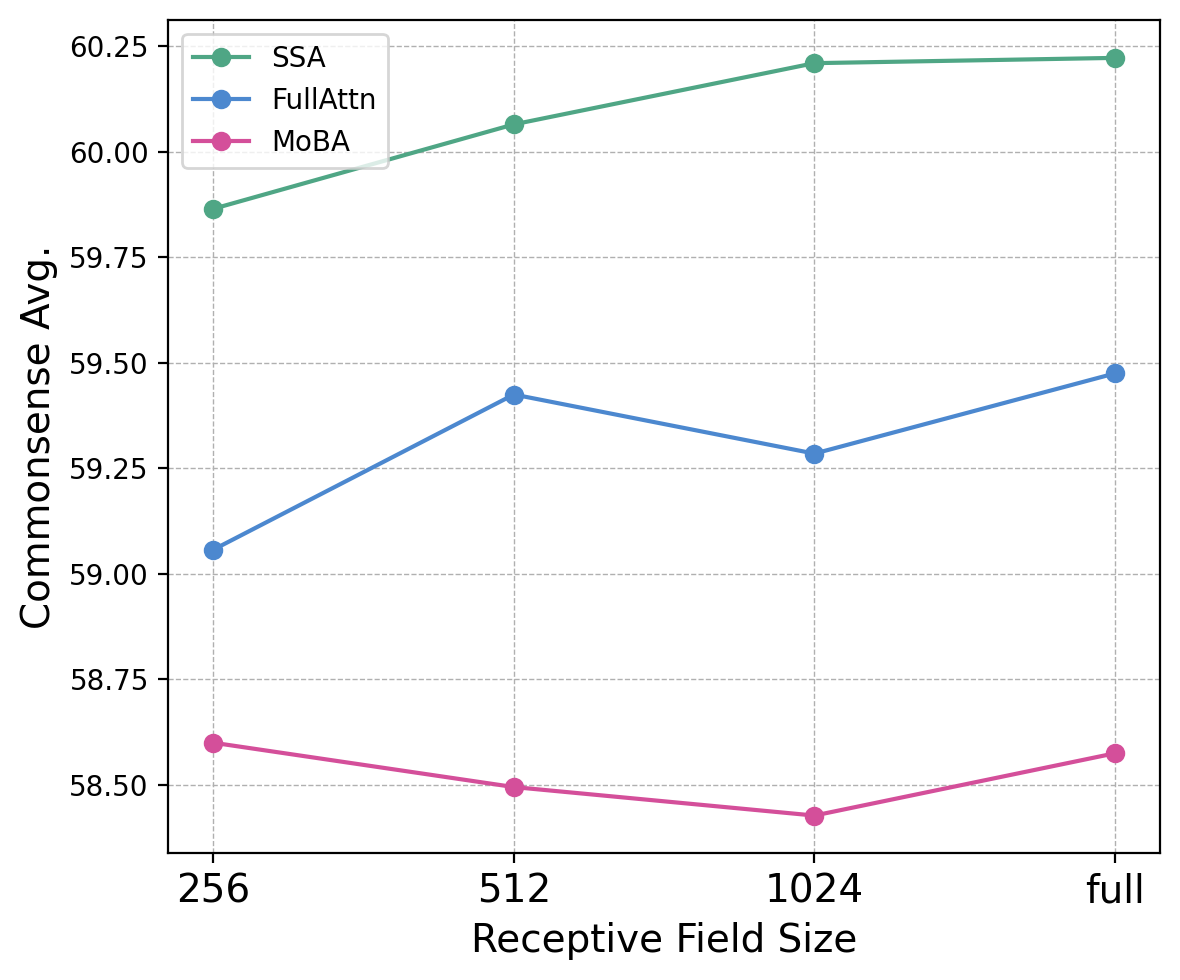
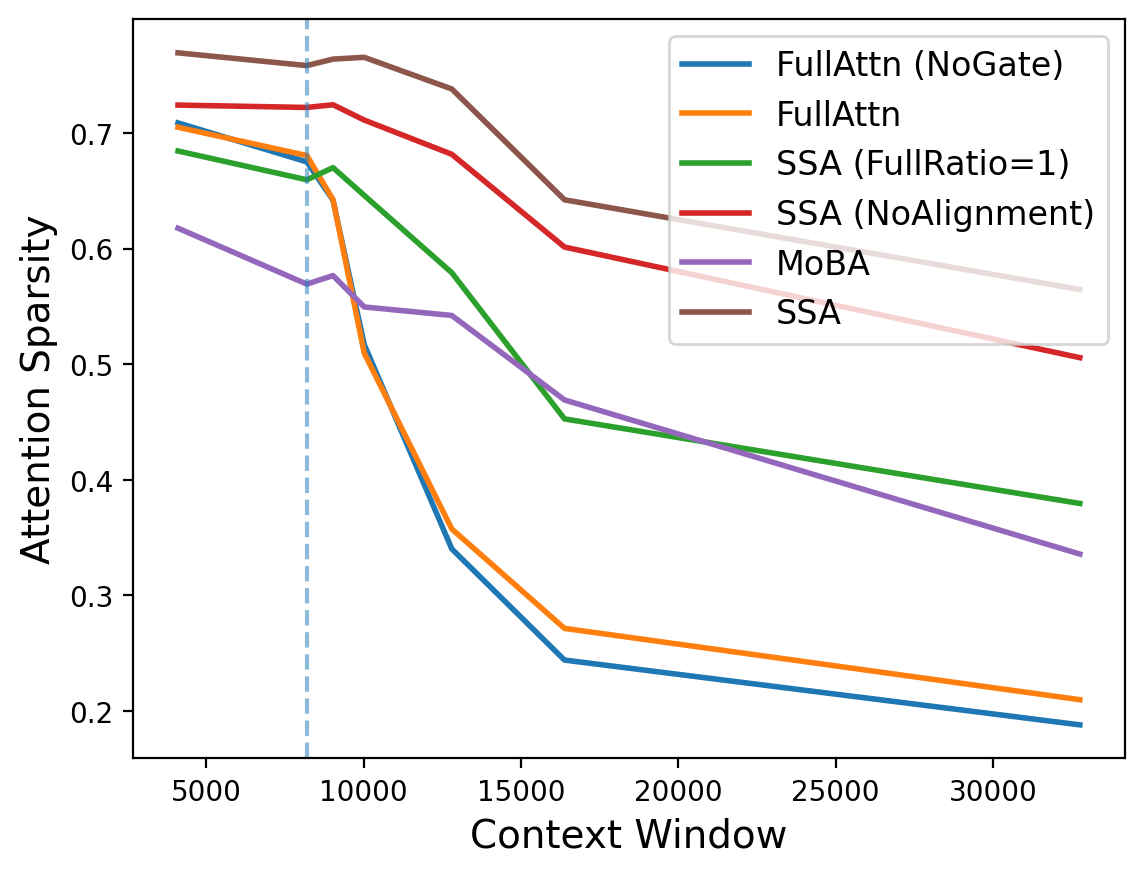
- SSA makes attention genuinely sparser than both standard full attention and other sparse methods. In plain terms: the model focuses better on what matters.
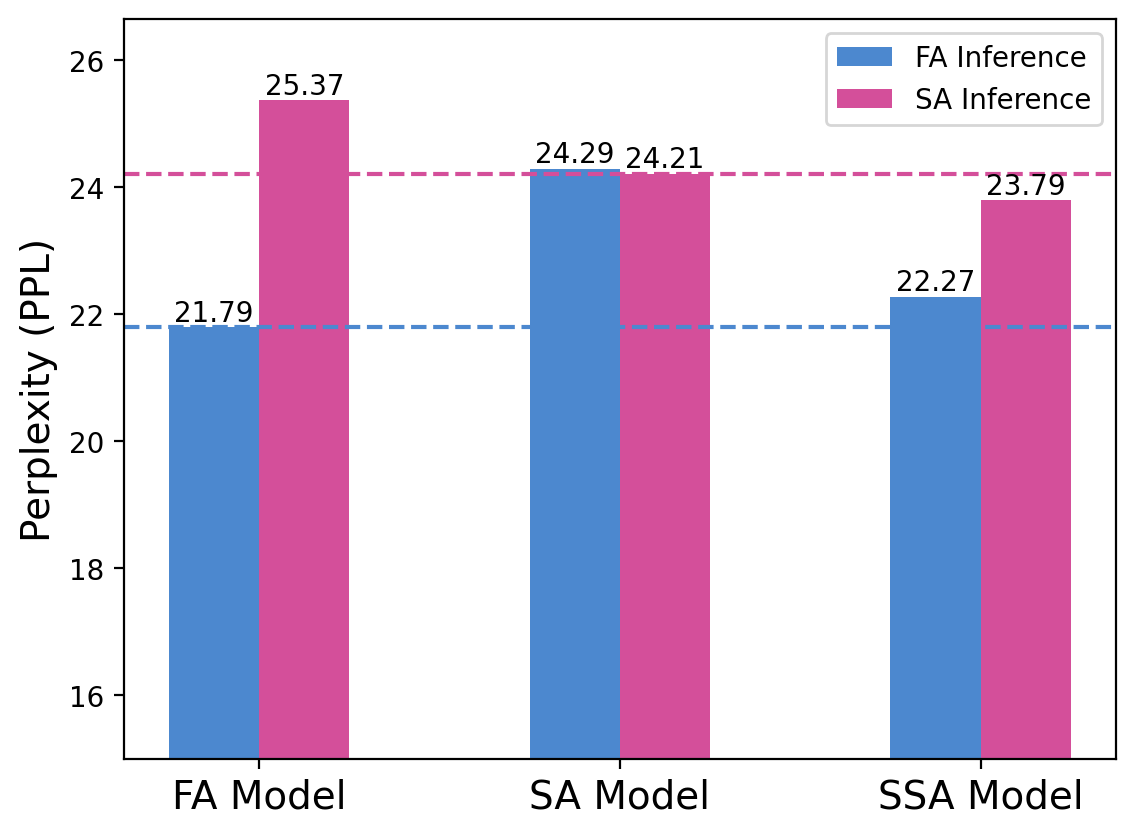
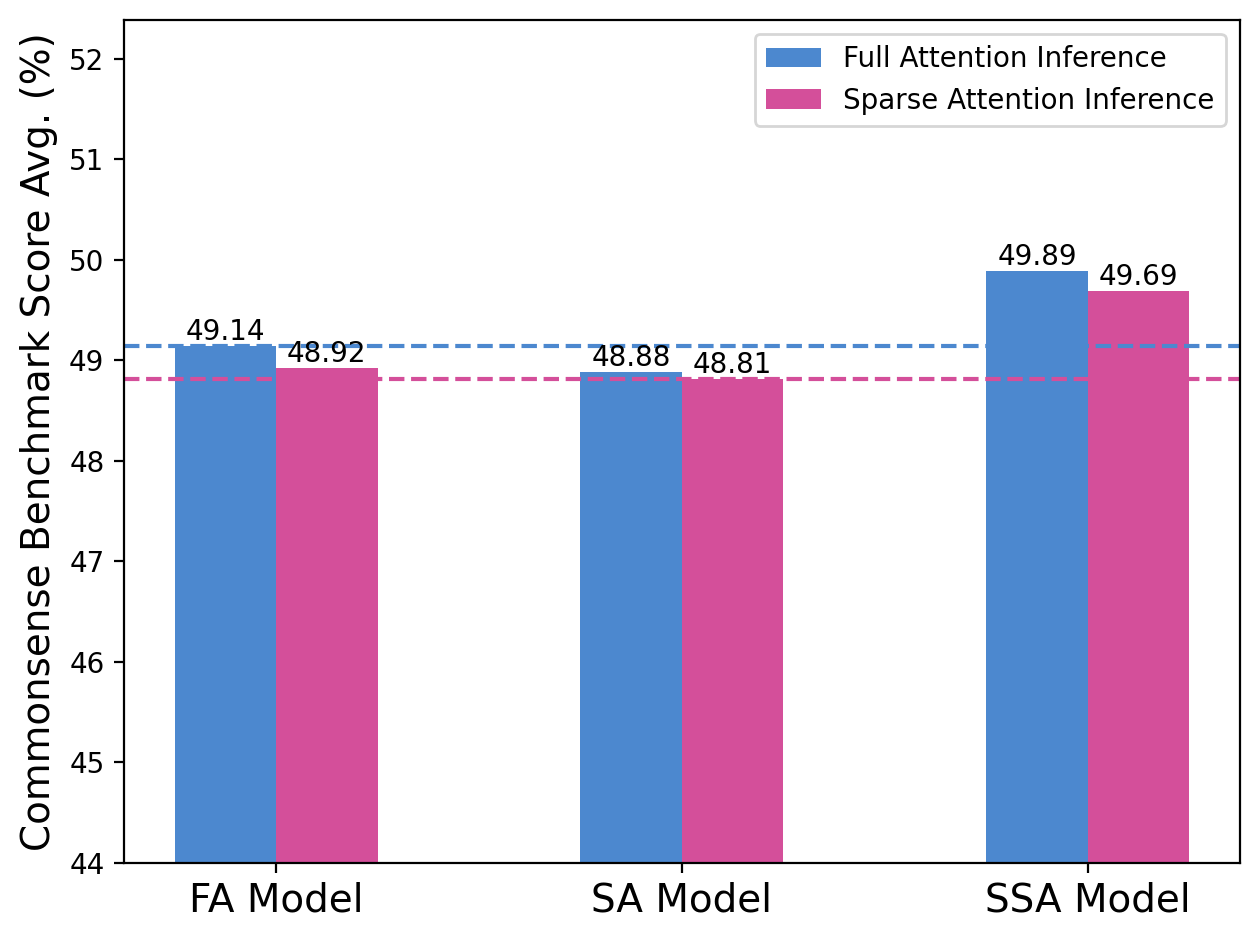
- SSA matches or beats other models on commonsense tasks and text prediction, whether you use full attention or sparse attention during inference.
- SSA adapts smoothly to different “budgets” at test time. If you allow it to attend to more tokens, performance improves steadily—no surprises or sudden drops.
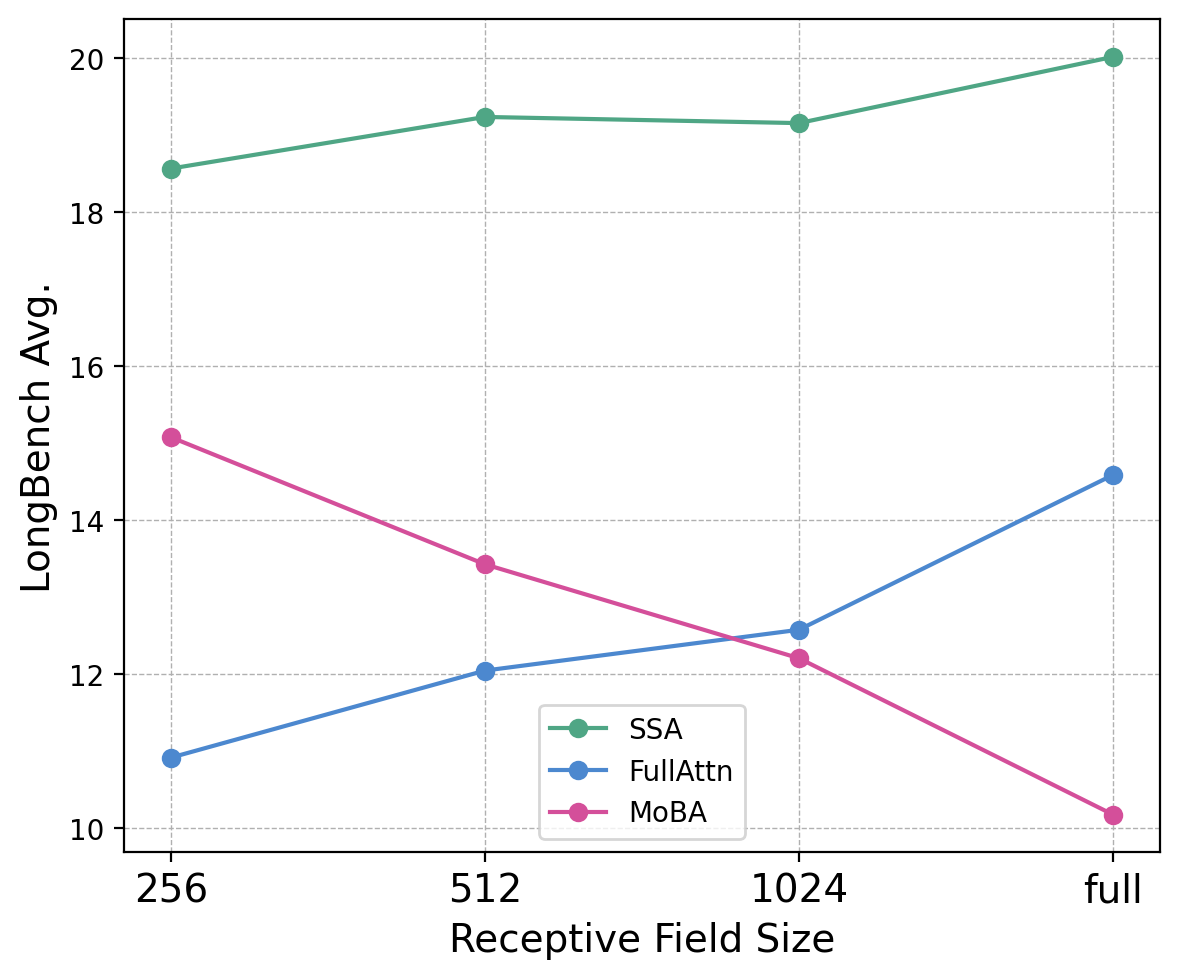
- SSA helps with long texts (long-context extrapolation). Even when you test the model on contexts longer than it was trained on, SSA stays stable and accurate. It reduces the “attention sink” problem where models over-focus on the first part of the text.
- Across various benchmarks (like “Needle-in-a-Haystack” retrieval, LongBench long-context understanding, and perplexity on long books), SSA is consistently strong and often the best among the compared methods.
Why this is important:
- LLMs are being used for long documents, extended reasoning, and research workflows. Handling long context efficiently and accurately is crucial.
- SSA lets you trade speed for accuracy in a controlled way: if you have limited compute, run sparse; if you have more compute, allow more attention; the model benefits either way.
Implications and Impact
This research suggests a practical path forward for building LLMs that:
- Are faster and cheaper to run on long inputs because they don’t waste time on irrelevant tokens.
- Still perform well under full attention, keeping high accuracy.
- Stay robust when asked to read much longer texts than they were trained on.
- Offer flexible “knobs” for real-world use: you can adjust how many tokens the model attends to depending on your hardware and time.
In short, SSA teaches models to focus smarter. By aligning what the model learns in both “full” and “sparse” modes, it becomes efficient without becoming careless, and accurate without becoming slow. This makes LLMs more useful for long, complex tasks in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and unresolved questions that future researchers could address.
- Scalability to frontier regimes: Does SSA’s dual-stream training and per-layer alignment remain effective and stable for 7B–70B+ parameter models and ultra-long contexts (128k–1M), and what are the compute, memory, and wall-clock implications at that scale?
- Training cost and efficiency: What is the exact training overhead (FLOPs, step time, memory peak) of SSA’s auxiliary attention computations per layer compared to FullAttn, MoBA, and NSA, and how can it be reduced (e.g., selective-layer alignment, lower-precision aux paths)?
- Inference speed and memory savings: How much end-to-end latency and memory reduction does SSA deliver on real hardware (A100/H100/TPUv5), including KV cache footprints and kernel-level efficiency, versus training-free and native sparse baselines?
- Architectural generality: Does SSA’s effectiveness hold without modifying
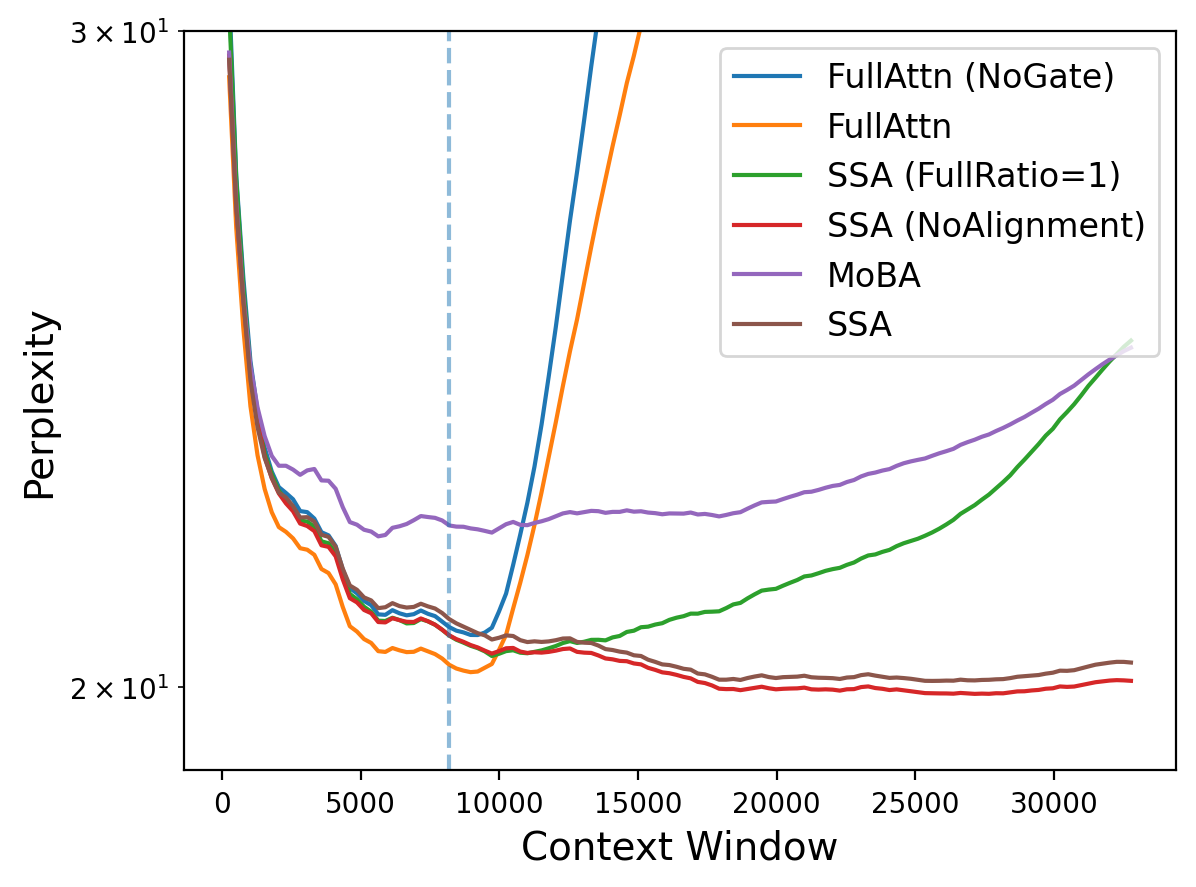
num_head_kv(kept at 2 here), under standard multi-head/GQA settings, encoder–decoder Transformers, MoE layers, or alternative normalization schemes? - Alignment target choice: How do different alignment targets (attention logits, normalized attention distributions, per-head outputs, Q/K/V projections, or residuals) affect sparsity, stability, and task performance relative to the current “attention output” SmoothL1 choice?
- Hyperparameter sensitivity and scheduling: Can curriculum schedules (e.g., annealing
alpha, dynamicFullRatio, layer-wise weights) outperform the fixed 50/50 stream mix; what principled tuning strategies yield robust gains across tasks? - Training stability: Why do one-directional alignment and per-layer random stream routing produce NaNs, and what changes (optimizer, clipping, normalization, gradient scaling, layer selection) prevent these failures?
- Block representation design: The mean-pooling justification for preserving block-level ranking is assumed; how do alternative pooling (max, learned pooling, attention within blocks) or token-level selection affect accuracy, sparsity, and cost?
- Token-level vs block-level sparsity: What is the performance/efficiency frontier when moving from block-sparse to token-sparse selection (e.g., DSA-style top-k tokens), and can SSA’s alignment be extended to token-level retrieval without prohibitive cost?
- Metric validity: Do
AttnEntropyand block-levelAttnSparsity(k)reliably predict downstream quality across tasks and model sizes; can more principled, layer/head-aware sparsity metrics improve diagnosis and tuning? - Causality of sparsity benefits: To what extent do improvements stem from increased inherent sparsity versus confounds (e.g., Gated Attention, multitask dual streams); can matched-entropy baselines or sparsity-only regularizers isolate causal contributions?
- Attention sink mechanism: The explanation is speculative; can we provide formal or empirical causal analyses (per-head RoPE bands, norm dynamics, softmax constraints) and test interventions beyond SSA (positional encoding variants, normalization changes)?
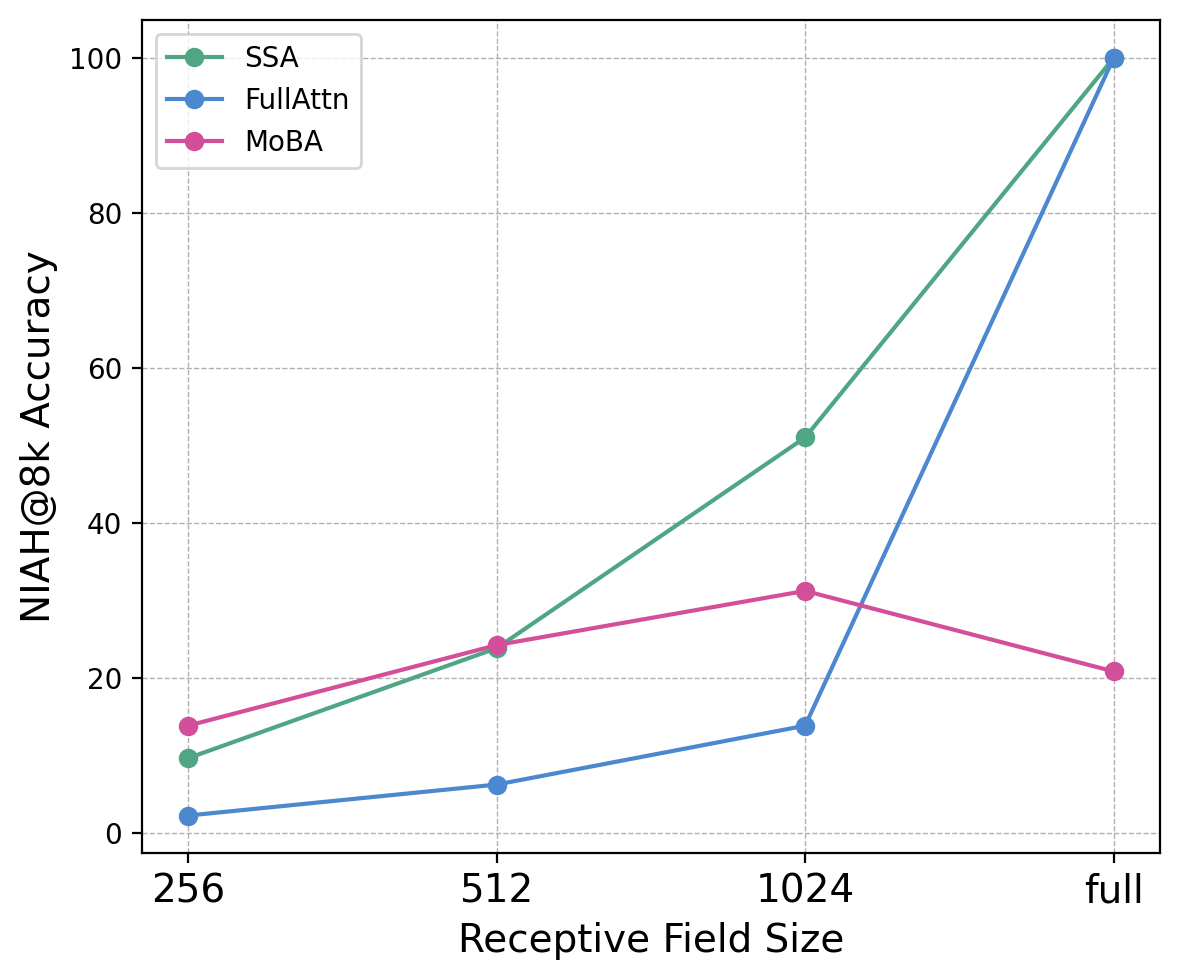
- Length extrapolation limits: SSA’s full-attention NIAH accuracy remains sub-100% beyond 8k (e.g., 31.6% at 32k); what failure modes drive these misses, and can targeted training (variable budgets, synthetic curricula) close the gap?
- Benchmark breadth: How does SSA affect instruction-following, code generation, summarization, multi-hop QA, multilingual tasks, and safety/hallucination metrics; do sparsity gains transfer uniformly across application domains?
- Comparative coverage: How does SSA fare against newer sparse methods (e.g., DSA, InfLLM-v2, xAttention, hierarchical selectors) under matched receptive fields and architectural constraints in both sparse and full inference modes?
- Adaptive sparsity at training: SSA trains with a fixed receptive field; can training with variable, per-layer, or per-head budgets (learned controllers/gates) improve generalization and compute–quality trade-offs?
- Theory of gradient flow: Can we formally characterize gradient coverage to excluded KV pairs in SA vs SSA, the convergence properties of bidirectional alignment, and bounds on approximation error accumulation across layers?
- Robustness under shift/noise: How does SSA perform under domain shifts, noisy or adversarial contexts, highly repetitive sequences, or atypical document structures; does increased sparsity help or hurt robustness?
- Memory footprint and precision: What is the peak memory cost of per-layer auxiliary attention under FlashAttention v2/v3 and mixed precision (BF16/FP8), and are there numerical stability risks at scale?
- KV cache management in systems: How well does SSA integrate with paged attention, streaming decoding, and cache eviction strategies; does it retain quality under aggressive KV dropping in real deployments?
- Interactions with other techniques: Does SSA complement or conflict with retrieval-augmented generation, external memory, speculative decoding, mixture-of-depth, or test-time scaling methods?
- Layer/head-wise heterogeneity: Which layers/heads benefit most from alignment; can limiting alignment to specific strata preserve gains while cutting training cost?
- Degenerate sparsity risks: Could SmoothL1 alignment on attention outputs incentivize collapse or over-pruning; how can we monitor and prevent degeneracy (e.g., diversity constraints, entropy floors)?
- Receptive-field “sweet spot”: The optimal budget is found empirically; can we devise a principled selection method (e.g., validation-guided, sparsity–entropy curves, task-aware objectives) or adaptive scheduling during training?
- Hardware-aware optimization: What specialized kernels and caching strategies (block splitting, gather/scatter) are needed to realize SSA’s theoretical efficiency gains across GPUs/TPUs?
- Data dependence: Trained on SmolLM; do results hold under different data mixtures and scales (web-scale curated datasets, code-heavy corpora), and how does data quality influence sparsity formation?
- Energy and cost reporting: What are the energy savings or costs of SSA versus baselines for both training and inference; can sparsity be tied to sustainability metrics?
- Reproducibility: Are full configs, seeds, and code available; can others replicate the alignment-induced sparsity and extrapolation effects across frameworks and hardware?
Glossary
- Alignment loss (bi-directional): A training objective that enforces consistency between sparse- and full-attention outputs at each layer in both directions. "the second is a bi-directional alignment loss that enforces consistency between the sparse-attention and full-attention outputs at each layer"
- Attention entropy: A metric quantifying how dispersed attention weights are; lower entropy means more concentrated (sparser) attention. "Attention entropy measures the dispersion of attention weights via Shannon entropy"
- Attention sink: A phenomenon where excessive attention mass is allocated to early tokens, harming long-context performance. "StreamingLLM further observes an 'attention sink' phenomenon, where substantial attention mass is placed on the initial tokens"
- Attention sparsity: A measure of how much attention mass is concentrated in the selected top positions; higher values indicate better sparse approximation to full attention. "Attention sparsity provides a more direct measure by computing the fraction of total attention mass contained within the top- tokens selected by the block-sparse mechanism"
- Block-sparse attention: An attention mechanism that partitions the sequence into blocks and computes attention over a selected subset of blocks to reduce cost. "A common approach is block-sparse attention, which partitions the context into blocks, estimates block importance, and selects the top- blocks for computation"
- Bright-band pattern: A manifestation of attention sink where certain rotary frequency bands acquire abnormally large norms, drawing attention to early tokens. "also referred to as the 'bright-band' pattern"
- Commitment loss: A regularizer that keeps sparse-attention outputs close to full-attention outputs to stabilize training. "The second component is a commitment loss, which regularizes the sparse-attention outputs to remain close to the full-attention outputs"
- FlashAttention: An optimized, memory-efficient implementation of attention softmax that enables fast, fused GPU computation. "which are incompatible with online softmax implementations such as FlashAttention"
- Gated Attention: A mechanism that modulates attention outputs via a learned gate, helping mitigate attention sink and improve performance. "we adopt Gated Attention, which effectively mitigates the attention-sink phenomenon, particularly detrimental to training-free sparse-attention methods, and improves overall performance"
- Gradient update deficiency: A training issue where excluded low-ranked key–value pairs receive no gradients and never learn to be properly suppressed. "We attribute this paradox to gradient update deficiency: low-ranked key–value pairs excluded during sparse training receive neither forward contribution nor backward gradients"
- Key–Value (KV) cache: The stored keys and values from previous tokens used to compute attention, often managed and pruned for efficiency. "The only extra cost comes from splitting the original KV cache into blocks"
- KL divergence: A measure of divergence between probability distributions, used to quantify how close sparse and full outputs or logits are. "analogous to the KL-divergence term used in RLHF"
- Needle-in-a-Haystack (NIAH): A long-context retrieval benchmark evaluating whether a model can find a single target item in a large sequence. "Needle-in-A-Haystack from RULER"
- Online softmax: A fused, streaming computation of softmax attention that avoids materializing dense attention matrices. "Compared to directly aligning full attention distributions, it is substantially more efficient: the latter requires materializing dense attention maps, which are incompatible with online softmax implementations such as FlashAttention"
- Receptive field: The maximum number of keys visible to a query under sparse attention, determined by block size and number of selected blocks. "We define the Receptive Field of a sparse model as the maximum number of keys available for attention"
- RLHF (Reinforcement Learning from Human Feedback): A training paradigm where models are fine-tuned using human preference signals, often with KL regularization. "analogous to the KL-divergence term used in RLHF"
- Sliding-window attention: A sparse pattern that restricts attention to a local neighborhood of tokens for efficiency. "A widely used form is sliding-window attention, which restricts each token to attend only to its local neighborhood"
- SmoothL1 loss: A robust regression loss combining L1 and L2 behaviors, used here for aligning attention outputs. "In practice, we use the SmoothL1 loss"
- Softmax attention: The standard transformer mechanism where attention weights are computed via softmax over dot-product scores. "In the standard softmax attention mechanism, each token attends to all preceding tokens through a learned, token-specific weighted aggregation"
- Stop-gradient operator: An operation that prevents gradients from flowing through a tensor during backpropagation, used to stabilize alignment. "where denotes the stop-gradient operator"
- Top-k blocks: The subset of blocks with highest relevance scores selected for sparse attention computation. "select the top- blocks for computation"
- VQ-VAE (Vector-Quantized Variational Autoencoder): A discrete representation learning method whose commitment loss inspires the sparse–full alignment regularization. "This objective is also conceptually similar to the commitment loss in VQ-VAE"
Practical Applications
Immediate Applications
Below are actionable, deployable-now use cases that follow directly from the paper’s SSA training framework and its demonstrated improvements in sparsity, inference flexibility, and long‑context extrapolation.
- Adjustable-sparsity LLM serving for tiered latency/cost (Software; Cloud/Platforms)
- Offer “compute–performance knobs” that adjust the receptive field per request (e.g., top‑k blocks), enabling SLO-aware routing: low-latency mode for most queries, expanded context for complex ones.
- Tools/products/workflows: SSA-aware inference engine integration in vLLM/TGI; an API parameter for receptive-field size; autoscaling policies that raise/lower sparsity based on current load.
- Assumptions/dependencies: Block-sparse attention kernel availability; compatibility with FlashAttention; moderate training overhead from dual-stream alignment.
- Long-document question answering and summarization at lower cost (Legal, Finance, Media; Enterprise NLP)
- Use SSA-trained models to process contracts, filings, reports, and transcripts with high retrieval accuracy and stable perplexity at 16k–32k contexts without retraining on those lengths.
- Tools/products/workflows: Document ingestion pipeline that chunked by block, top‑k selection per query token; “budget-aware” QA agents that expand receptive field only when retrieval confidence drops.
- Assumptions/dependencies: Quality chunking and block pooling; tested domain prompts; guardrails for confidentiality.
- Conversation memory management with graceful degradation (Customer Support, CRM; Software)
- Maintain long chat histories using sparse attention, increasing receptive field on demand (e.g., when referencing older turns) while keeping typical responses fast and cheap.
- Tools/products/workflows: Chat orchestration with dynamic sparsity; KV-cache block manager that drops low-importance blocks first.
- Assumptions/dependencies: Stable top‑k block scoring; policy for CX quality vs cost; logging and privacy controls.
- On-device assistants with constrained compute (Mobile, Embedded; Daily Life)
- Deploy SSA-inferred sparse attention to run usable LLMs on laptops/phones, enabling offline note summarization and personal knowledge search with energy savings.
- Tools/products/workflows: Configurable receptive-field presets (battery saver, balanced, max quality); edge inference SDK support for block-sparse ops.
- Assumptions/dependencies: Efficient kernels on mobile GPU/Neural Engine; model quantization; privacy-first data handling.
- Code assistants for extended reasoning traces (Software Engineering)
- Reduce inference cost during multi-step code reasoning, expanding sparsity budget only for complex steps (e.g., long context diffs or multi-file analysis).
- Tools/products/workflows: IDE plugin with per-step adaptive sparsity; “reasoning budget controller” that tunes receptive field based on task difficulty.
- Assumptions/dependencies: Calibrated signals for difficulty; robust top‑k block ranking across code tokens.
- Log/telemetry search (“needle-in-a-haystack”) at scale (Security Ops, DevOps; Energy/Industrial Ops)
- Exploit SSA’s improved long-context retrieval to scan large logs for anomalies or compliance markers with lower perplexity drift beyond training length.
- Tools/products/workflows: Streaming block-sparse retrieval over rolling logs; alerting agent that boosts receptive field when anomaly signals arise.
- Assumptions/dependencies: Reliable chunk boundaries for temporal data; domain-tuned retrieval prompts.
- Research reading and synthesis with long context (Academia; Education; Daily Life)
- Summarize, compare, and cite across entire papers/books using sparse inference; increase receptive field on sections that require deeper cross-referencing.
- Tools/products/workflows: Study assistant with “focus expansion” control; attention-sparsity/entropy monitoring for quality gating.
- Assumptions/dependencies: Citation-aware prompts; human-in-the-loop validation; academic integrity considerations.
- Cost-optimized LLM product tiers (Product Management; Policy—Access Equity)
- Introduce pricing tiers mapped to sparsity budgets (Basic: small receptive field; Pro: larger; Enterprise: full attention), letting users choose quality vs cost.
- Tools/products/workflows: Tier design with clear SLAs; usage analytics; customer education on trade-offs.
- Assumptions/dependencies: Transparent performance metrics; fair billing; governance for accurate disclosure.
- Training recipe to reduce attention sink and improve length generalization (ML Engineering; Academia)
- Adopt dual-stream (full+sparse) training with bidirectional alignment to mitigate bright-band attention and stabilize perplexity at longer contexts.
- Tools/products/workflows: SSA training plugin (SmoothL1 alignment with stop-gradient; 50/50 stream sampling); metrics dashboards (entropy, sparsity).
- Assumptions/dependencies: Gated attention (as used in paper) recommended; hyperparameter tuning (alpha, stream ratio); training compute headroom.
- Environmental and cost reporting (Policy—Green AI; Corporate Sustainability)
- Quantify energy savings from SSA-based sparse inference vs full attention; use as evidence for sustainable AI deployment in procurement.
- Tools/products/workflows: Carbon calculators integrated with sparsity logs; policy briefs highlighting performance parity at reduced compute.
- Assumptions/dependencies: Accurate energy telemetry; standardized benchmarks; stakeholder buy-in.
Long-Term Applications
These opportunities leverage SSA’s method to scale capabilities, integrate across modalities, or co-design with hardware. They require further research, engineering, or standards.
- Frontier LLMs with 128k–1M effective contexts and dynamic sparsity (Software; Cloud/Platforms)
- Train larger models with SSA to maintain stability at extreme lengths while enabling runtime knob-based compute/performance trade-offs per user/session.
- Tools/products/workflows: Hierarchical block selection; curriculum for gradually increasing receptive field during pretraining; SLA-aware inference orchestration.
- Assumptions/dependencies: Robust positional encodings; scalable kernels; distributed KV-cache management; broader validation beyond commonsense tasks.
- Sector-specific long-context agents (Healthcare, Legal, Finance, Education)
- Build domain agents that ingest entire EHR timelines, case law corpora, risk reports, or textbooks; expand context only when necessary for clinical/legal/financial reasoning.
- Tools/products/workflows: Domain-tuned block pooling; trust & safety with human review; compliance logging; retrieval calibration over years of records.
- Assumptions/dependencies: Strong governance and data privacy; regulatory approvals; auditability; domain benchmarks beyond general commonsense.
- Hardware–software co-design for sparse attention (Semiconductors; Energy Efficiency)
- Develop accelerators and memory hierarchies optimized for block-sparse KV access and top‑k selection, reducing bandwidth and power.
- Tools/products/workflows: ISA extensions for block scoring; on-chip top‑k units; KV-cache tiling strategies; compiler passes for SSA patterns.
- Assumptions/dependencies: Vendor support; open kernel standards; workload characterization; cost-benefit vs dense attention.
- Autopilot “budget controllers” for inference (ML Ops; Cloud)
- Real-time controllers that adjust receptive field per step, guided by uncertainty, retrieval signals, or latency budgets; integrate with orchestration and billing.
- Tools/products/workflows: Policy engine that reads entropy/sparsity metrics; reinforcement learning for knob tuning; user-facing quality indicators.
- Assumptions/dependencies: Reliable proxies for output quality; guardrails to prevent oscillation; fairness and transparency commitments.
- Cross-modal sparse alignment (Multimodal AI; Robotics)
- Extend SSA concepts to vision/audio/video transformers and long-horizon robot planning, where sparse views can align with full views to keep compute tractable as sequences grow.
- Tools/products/workflows: Block-sparse attention over frame patches; hierarchical top‑k for spatiotemporal data; planning agents with adaptive context windows.
- Assumptions/dependencies: New block semantics (spatiotemporal); datasets for long-horizon evaluation; safety validation for autonomy.
- Compliance-grade audit trails with full-length retention (Policy; Governance; Enterprise)
- Maintain full transcripts for audits while using sparse inference for day-to-day operations; expand receptive field only for investigations or legal holds.
- Tools/products/workflows: Retention policies tied to sparsity budgets; compliant replay tools that switch to full attention on-demand; explainability for attention selection.
- Assumptions/dependencies: Legal frameworks; secure storage; explainable selection mechanisms; stakeholder requirements.
- Standardization of sparsity metrics and disclosures (Policy; Standards Bodies; Academia)
- Define norms for reporting attention entropy/sparsity, extrapolation behavior, and “sink” mitigation; enable comparable “green performance” labels for models.
- Tools/products/workflows: Benchmark suites (LongBench+ sector tasks); metric registries; certification processes.
- Assumptions/dependencies: Community consensus; reproducible evaluations; independent testing labs.
- Data-centric curricula for sparsity (Academia; ML Research)
- Develop training curricula that expose models to variable sparsity budgets and synthetic long-context tasks, improving alignment and extrapolation.
- Tools/products/workflows: Curriculum generators; adaptive sampling of full vs sparse streams; ablation repositories.
- Assumptions/dependencies: Scalable pretraining infrastructure; robust ablation protocols; open-source datasets with long-range dependencies.
- Privacy-first personal knowledge bases (Daily Life; Consumer Software)
- On-device SSA LLMs that index and retrieve across entire personal archives (notes, emails, documents) with adjustable compute; full-context expansion only locally.
- Tools/products/workflows: Secure block indexers; user knobs for energy/performance; transparent attention-selection visualization.
- Assumptions/dependencies: Efficient local kernels; privacy guarantees; opt-in data governance.
- Safety and reliability improvements via sparse alignment (AI Safety; Risk Management)
- Investigate whether higher attention sparsity reduces spurious correlations/hallucinations by prioritizing informative tokens; build safety tooling that monitors sparsity/entropy in production.
- Tools/products/workflows: Safety dashboards; alarms for “sink-like” patterns; controlled experiments in RLHF/instruction-tuned phases.
- Assumptions/dependencies: Empirical verification across tasks; interplay with RLHF/finetuning; careful measurement design.
Notes on feasibility
- SSA’s benefits were demonstrated on small-to-mid models (300M–1B) and pretraining-only setups; effects should be validated at larger scales and after instruction tuning/RLHF.
- Gated attention was used in all methods for fairness and sink mitigation; similar gains may depend on gate usage.
- Integration requires block-sparse kernels and efficient top‑k selection; production-grade inference libraries must support these primitives.
- Hyperparameters (alignment weight α, stream ratios, receptive field) require tuning; ablations suggest bidirectional alignment is necessary for stability.
Collections
Sign up for free to add this paper to one or more collections.

