- The paper presents NSA, a novel attention mechanism that integrates a hierarchical sparse strategy with three parallel branches for efficient long-context processing.
- NSA employs blockwise token compression and selective token retention to optimize Tensor Core usage and ensure contiguous memory access on modern GPUs.
- Experimental results reveal substantial speedups in training and inference, with NSA matching or exceeding full attention models on various benchmarks.
Native Sparse Attention for Efficient Long-Context Modeling
This paper introduces Native Sparse Attention (NSA), a novel attention mechanism designed to enhance the efficiency of long-context modeling in LLMs. NSA integrates algorithmic innovations with hardware-aligned optimizations to achieve substantial speedups during both training and inference, while maintaining or exceeding the performance of full attention models across a range of benchmarks. The key contributions of this work lie in its hierarchical sparse strategy, arithmetic intensity-balanced algorithm design, and end-to-end training capabilities.
Algorithmic Innovations
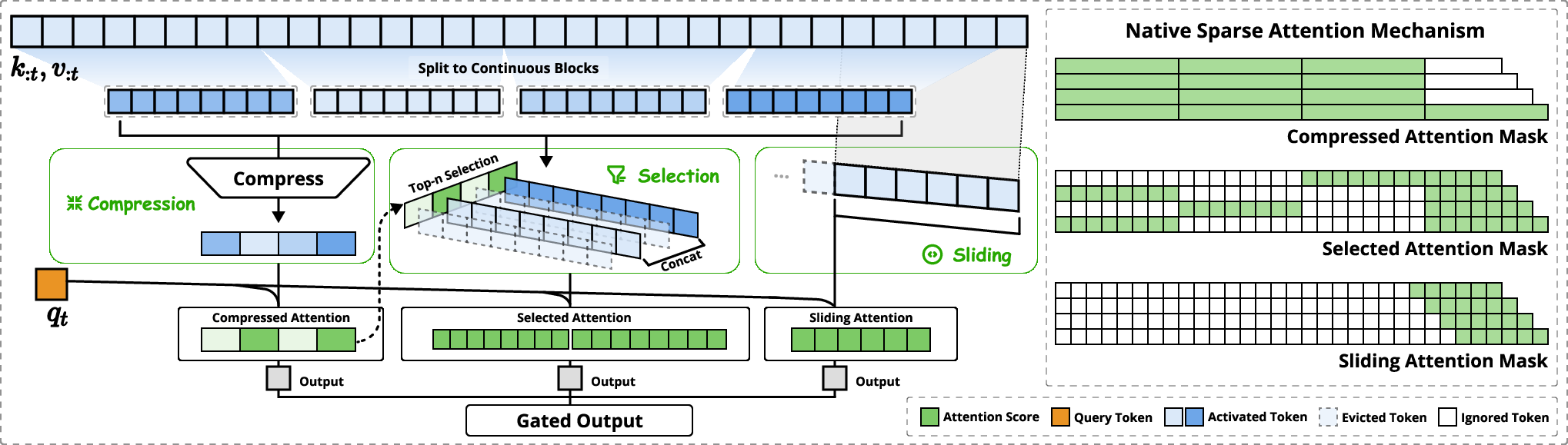
Figure 1: Overview of NSA's architecture, illustrating the parallel attention branches for coarse-grained patterns, important token blocks, and local context.
NSA's architecture (Figure 1) employs a dynamic hierarchical sparse strategy that combines coarse-grained token compression with fine-grained token selection. Input sequences are processed through three parallel attention branches: compressed attention, selected attention, and sliding attention. This design enables the model to capture both global context awareness and local precision, while significantly reducing computational overhead.
Token compression aggregates sequential blocks of keys and values into block-level representations, capturing higher-level semantic information. Token selection selectively preserves individual keys and values based on their importance scores, which are derived from the attention computation of compression tokens. This blockwise selection strategy is crucial for achieving efficient computation on modern GPUs, as it enables optimal utilization of Tensor Cores and contiguous memory access. The sliding window branch explicitly handles local context, preventing the model from being shortcutted by local patterns and allowing the other branches to focus on learning their respective features. A learned gating mechanism aggregates the outputs of these three branches, providing a flexible way to combine different sources of information.
Hardware-Aligned System
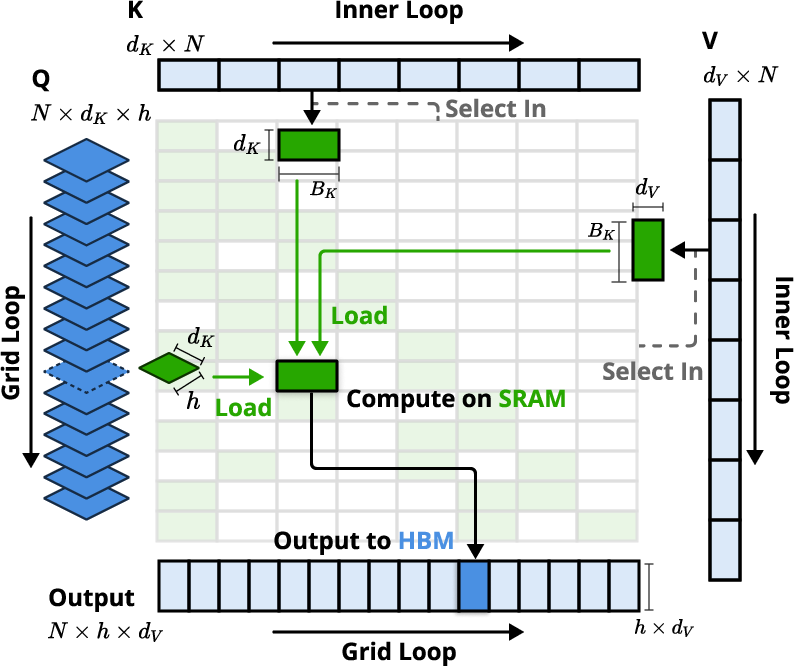
Figure 2: Kernel design for NSA, showcasing the loading of queries by GQA groups, fetching of sparse KV blocks, and attention computation on SRAM.
One of the key innovations of NSA is its hardware-aligned system, which optimizes blockwise sparse attention for Tensor Core utilization and memory access. The paper emphasizes the importance of balancing arithmetic intensity, which is the ratio of compute operations to memory accesses, to maximize hardware efficiency. The kernel design (Figure 2) involves loading queries by GQA groups, fetching corresponding sparse KV blocks, and performing attention computation on SRAM. This design achieves near-optimal arithmetic intensity by eliminating redundant KV transfers through group-wise sharing and balancing compute workloads across GPU streaming multiprocessors.
Training-Aware Design
The paper addresses the limitations of existing sparse attention methods that primarily focus on inference-time speedups. NSA enables stable end-to-end training through efficient algorithms and backward operators, reducing training costs without sacrificing model performance. The training-aware design of NSA allows the model to learn optimal sparse patterns, which can further enhance its performance and efficiency. The paper demonstrates that pretraining with NSA results in comparable or superior performance to full attention baselines across general language evaluations, long-context evaluations, and chain-of-thought reasoning evaluations.
Experimental Results
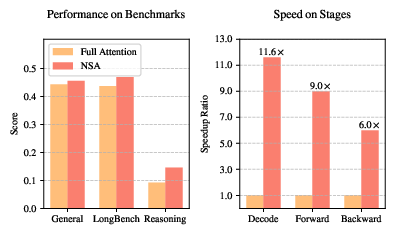
Figure 3: A comparison of performance and efficiency between the Full Attention model and NSA, highlighting NSA's superior performance and computational speedup.
The paper presents extensive experimental results to validate the effectiveness of NSA. Pretraining on a 27B-parameter transformer backbone with 260B tokens, NSA achieves comparable or superior performance to full attention baselines on general language benchmarks. In long-context evaluations, NSA demonstrates perfect retrieval accuracy on the needle-in-a-haystack test and outperforms state-of-the-art sparse attention methods on LongBench. Furthermore, NSA exhibits enhanced reasoning ability in chain-of-thought reasoning evaluations. The paper also reports substantial speedups across decoding, forward, and backward stages compared to full attention, with the speedup ratio increasing for longer sequences (Figure 3).
Implications and Future Directions
The development of NSA has significant implications for the field of long-context modeling. By addressing the computational challenges associated with standard attention mechanisms, NSA enables the creation of more efficient and scalable LLMs. The hardware-aligned design and end-to-end training capabilities of NSA make it a promising approach for real-world applications that require fast long-context inference or training.
The paper also discusses the challenges encountered with alternative token selection strategies and provides visualizations that offer insights into attention distribution patterns. These insights can inform future research directions in sparse attention mechanisms. Future work could explore adaptive sparsity patterns, dynamic adjustment of compression ratios, and integration with other efficient attention techniques.
Conclusion
NSA represents a significant advancement in the field of sparse attention. Its hierarchical token compression, blockwise token selection, hardware-aligned design, and end-to-end training capabilities make it a highly effective approach for efficient long-context modeling. The experimental results demonstrate that NSA achieves substantial speedups while maintaining or exceeding the performance of full attention models across a range of benchmarks. This work paves the way for the development of more scalable and efficient LLMs that can handle increasingly long contexts.

