vAttention: Verified Sparse Attention
Abstract: State-of-the-art sparse attention methods for reducing decoding latency fall into two main categories: approximate top-$k$ (and its extension, top-$p$) and recently introduced sampling-based estimation. However, these approaches are fundamentally limited in their ability to approximate full attention: they fail to provide consistent approximations across heads and query vectors and, most critically, lack guarantees on approximation quality, limiting their practical deployment. We observe that top-$k$ and random sampling are complementary: top-$k$ performs well when attention scores are dominated by a few tokens, whereas random sampling provides better estimates when attention scores are relatively uniform. Building on this insight and leveraging the statistical guarantees of sampling, we introduce vAttention, the first practical sparse attention mechanism with user-specified $(\epsilon, \delta)$ guarantees on approximation accuracy (thus, verified). These guarantees make vAttention a compelling step toward practical, reliable deployment of sparse attention at scale. By unifying top-k and sampling, vAttention outperforms both individually, delivering a superior quality-efficiency trade-off. Our experiments show that vAttention significantly improves the quality of sparse attention (e.g., $\sim$4.5 percentage points for Llama-3.1-8B-Inst and Deepseek-R1-Distill-Llama-8B on RULER-HARD), and effectively bridges the gap between full and sparse attention (e.g., across datasets, it matches full model quality with upto 20x sparsity). We also demonstrate that it can be deployed in reasoning scenarios to achieve fast decoding without compromising model quality (e.g., vAttention achieves full model quality on AIME2024 at 10x sparsity with up to 32K token generations). Code is open-sourced at https://github.com/xAlg-ai/sparse-attention-hub.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
vAttention: Verified Sparse Attention — A Simple Explanation
What is this paper about?
This paper is about making LLMs faster and more efficient when they read and write long texts. The authors introduce a new method called vAttention that lets the model “pay attention” to fewer, smarter pieces of information without losing accuracy. Most importantly, vAttention gives users a dial to set how close to exact the result should be and how confident the method should be in that accuracy.
What questions were the researchers asking?
They focused on a few key questions:
- Can we safely skip looking at many tokens (pieces of text) during attention and still get almost the same result as full attention?
- Can we do this in a way that works well across different parts of the model and different inputs (not just sometimes)?
- Can we give users clear, reliable guarantees about how accurate the result will be?
How did they try to solve it? (Methods in everyday language)
First, here’s a quick idea of how attention works:
- In an LLM, attention decides which earlier words matter most for predicting the next word. This requires checking all previous tokens, which can be very slow and memory-heavy for long contexts.
Traditional shortcuts:
- Top-k: Only look at the k tokens that seem most important (the “loudest” signals).
- Top-p: Look at enough top tokens to cover a chosen portion “p” of the total importance.
- Sampling: Randomly pick some tokens and estimate the result.
The problem:
- Top-k works well when a few tokens really stand out, but fails when importance is spread evenly.
- Random sampling works well when importance is spread out, but not when a few tokens dominate.
- None of these give solid guarantees about how close they are to full attention.
The vAttention idea (a hybrid with guarantees):
- Think of attention like adding up many contributions from tokens.
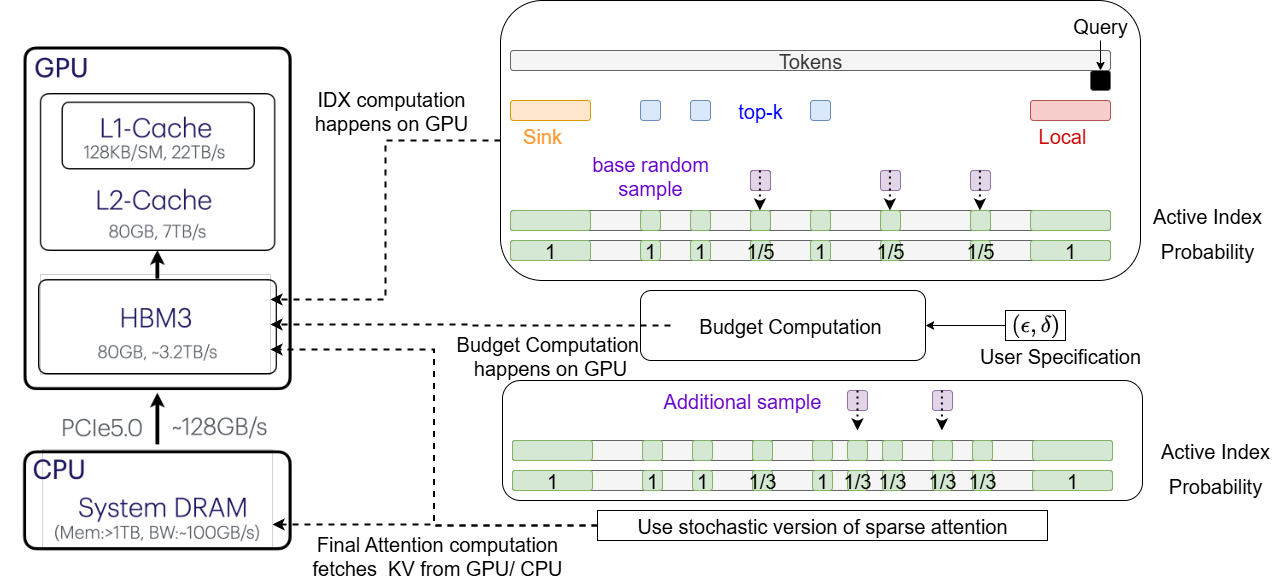
- Step 1: Grab the “heavy hitters” — the most likely important tokens — using a few simple rules:
- Always include some early “anchor” tokens (called sinks).
- Always include a sliding window of the most recent tokens (because recent context matters).
- Include predicted top tokens from a fast top-k helper (like HashAttention).
- Step 2: For the remaining “long tail” of tokens (many with similar importance), pick a random sample. Use basic statistics to estimate how many samples you need so the final answer is within your chosen accuracy.
What makes it “verified”?
- vAttention lets you set two numbers:
- ε (epsilon): how close you want the result to be to full attention (smaller means more accurate).
- δ (delta): how confident you want to be in that accuracy (smaller means more confidence).
- vAttention then calculates how many “long tail” tokens to sample so that, with probability at least 1−δ, the attention result is within ε of the full attention result.
- This gives you a clear accuracy–speed control: tighter ε/δ means more tokens and higher accuracy; looser ε/δ means fewer tokens and faster speed.
A practical tweak:
- To keep things fast, they often “verify” the most critical part of the calculation (the denominator in attention) because that controls overall bias. This still correlates extremely well with final accuracy in practice, and keeps compute costs low.
What did they find, and why is it important?
In tests across several models and benchmarks, vAttention:
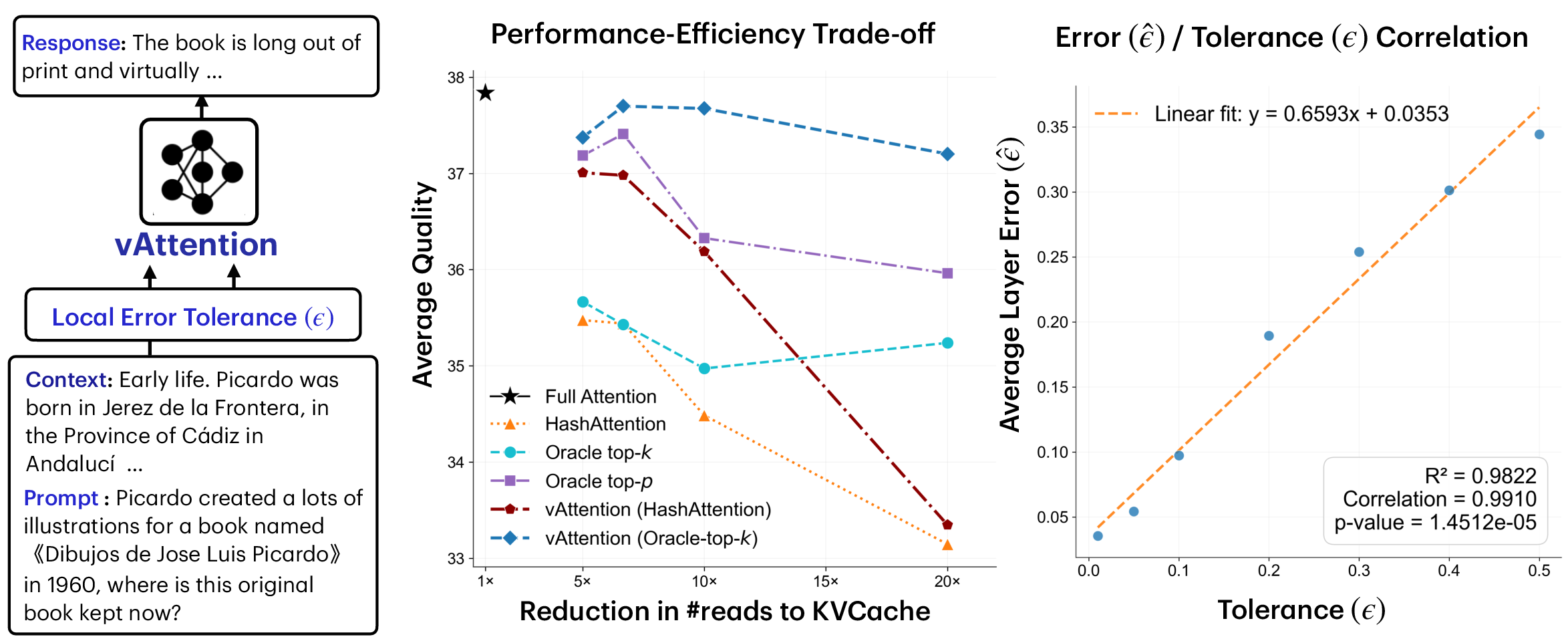
- Outperforms top-k and top-p approaches on the quality–efficiency trade-off. In plain terms: it gets better accuracy while using fewer tokens.
- Matches full attention quality at high sparsity (using far fewer tokens), sometimes up to about 20× fewer tokens across datasets.
- Improves accuracy by around 4.5 percentage points on challenging long-context tasks at only 10% token usage (for models like Llama-3.1-8B-Instruct and DeepSeek-R1-Distill-Llama-8B on the RULER-HARD suite).
- Handles long reasoning tasks well. For example, on the AIME 2024 benchmark, it matched the full model’s quality with about 10× sparsity even when generating up to 32,000 tokens.
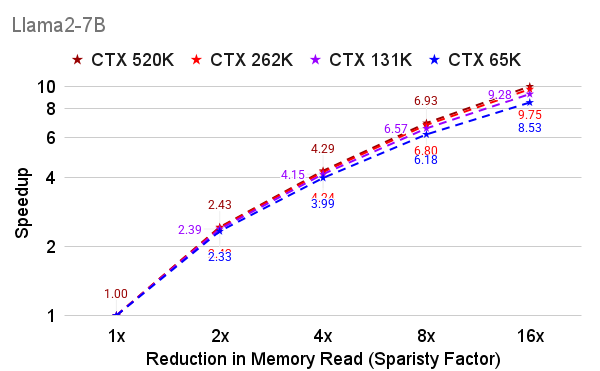
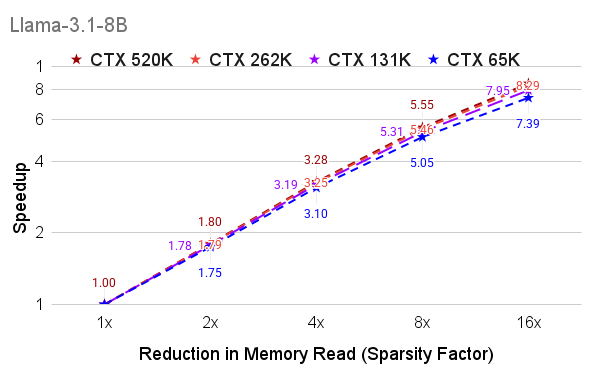
- Delivers near-linear speedups when the model’s memory is on the CPU (where moving data is often the slowest part).
This matters because it means we can make LLMs faster, cheaper, and better at handling long inputs without sacrificing reliability.
What’s the impact of this research?
- Reliable speed-ups: vAttention brings trustworthy accuracy guarantees to sparse attention, making it safer to use in real systems.
- User control: Developers can directly set how accurate and how confident they want the result to be via ε and δ.
- Works with existing tools: vAttention plays nicely with fast top-k helpers (like HashAttention), so you can stack their benefits.
- Better long-context reasoning: It enables quick, accurate generation over very long sequences, which is crucial for tasks like coding help, document analysis, and step-by-step math or science reasoning.
- A path to practical deployment: Because it offers verified accuracy and strong performance, it’s a realistic option for speeding up large models in the real world.
In short, vAttention is like a smart, trustworthy shortcut that knows when to look closely and when a good estimate is enough—letting LLMs work faster while staying accurate, and giving you the controls to choose the balance you need.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues, assumptions, and unexplored directions that future work could address to strengthen, generalize, and operationalize vAttention.
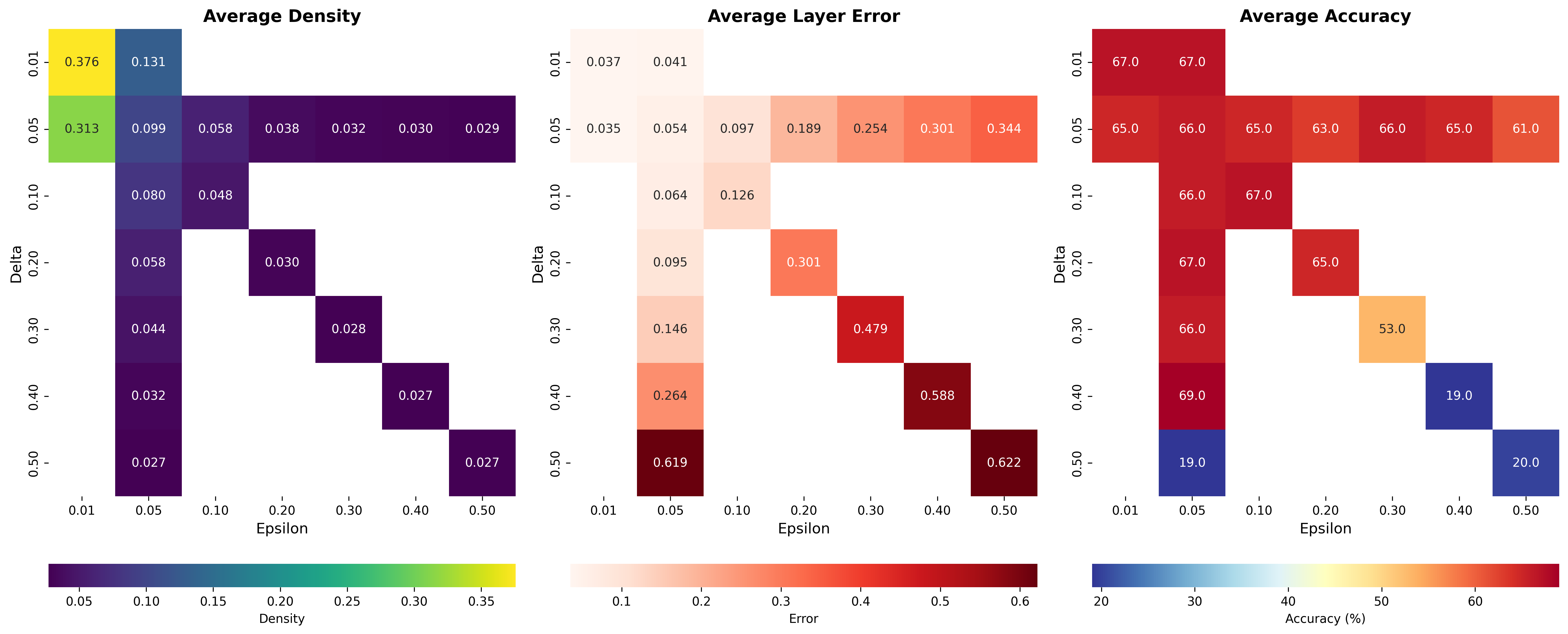
- End-to-end guarantees across layers and time: Formalize how per-head, per-layer guarantees compose over layers and decoding steps; derive failure probability accumulation (union bounds or tighter martingale bounds), and provide practical δ-scheduling to meet global reliability targets.
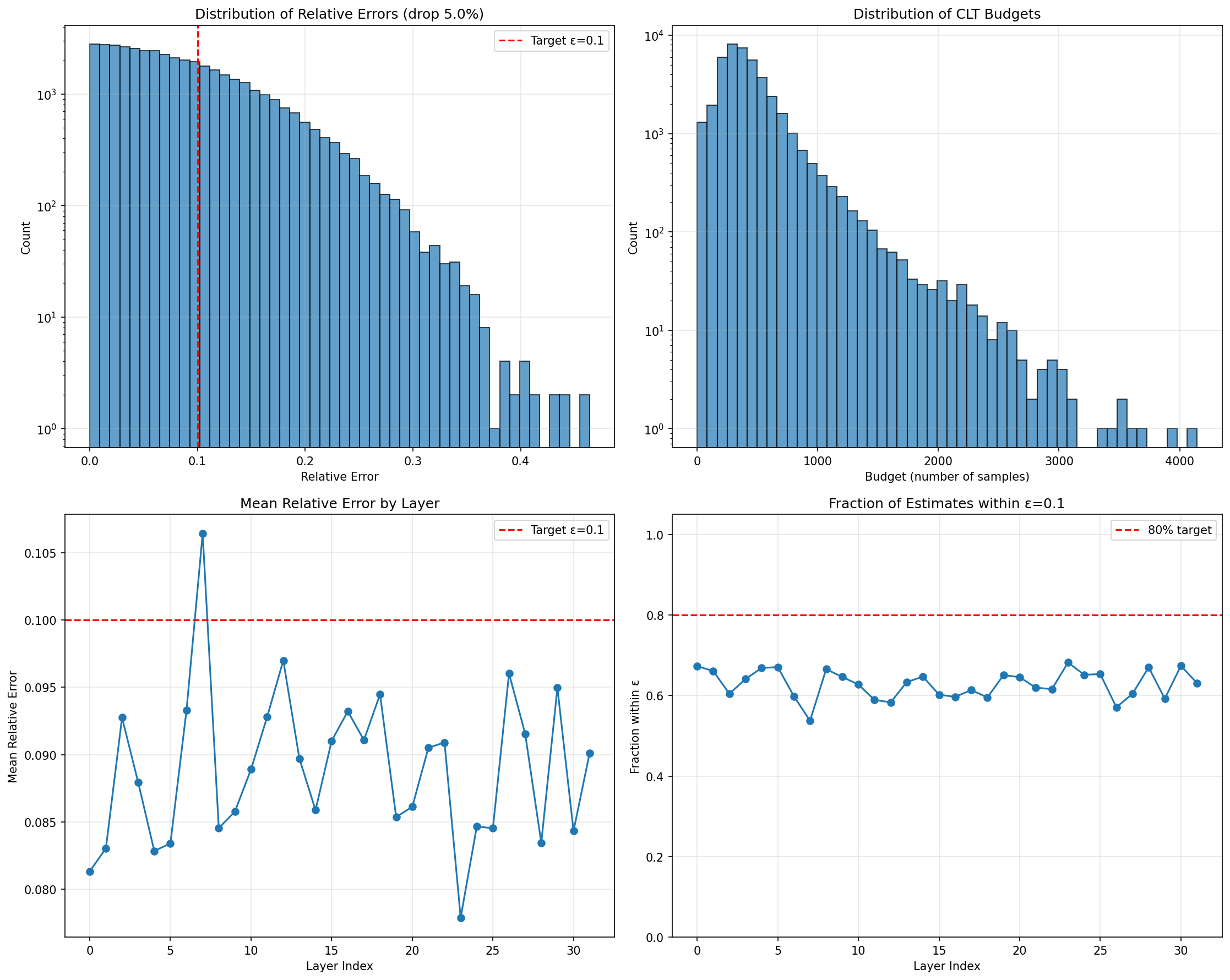
- CLT reliance and distributional robustness: Replace or rigorously validate the optimistic CLT-based budget choice under finite, dependent, heavy-tailed KV populations; compare and calibrate distribution-free bounds (Hoeffding, Bernstein, Serfling finite-population CLT) and quantify coverage under real attention score distributions.
- Verified numerator approximation: The experiments use denominator-only verification; develop efficient, low-overhead methods (e.g., control variates, stratified/importance sampling, low-rank projections) to verify the numerator with and measure the added cost vs. quality gains.
- Residual heavy-hitter detection: Introduce tests in the base sample to detect missed heavy hitters in the residual set and adapt (e.g., expand
f_t, switch sampling distribution, or escalate budget) to guarantee the tail is sufficiently “flat” for uniform sampling to be effective. - Alternative sampling strategies: Evaluate importance sampling, stratified sampling, or LSH-informed sampling over residual tokens (instead of uniform) to reduce variance and budgets; derive verified bounds under these samplers.
- Sensitivity to top-k predictor quality: Quantify how errors in approximate top-k (e.g., HashAttention misses) affect vAttention’s budgets and final attention error; design robust fallback mechanisms when top-k fails, including adaptive reallocation from sampling to deterministic selection.
- Adaptive parameterization beyond grid search: Replace heuristic
f_s,f_l,f_t,f_bwith online optimization or learned policies that allocate budgets per head/query given a global sparsity target and downstream quality objective; provide algorithms for real-time parameter tuning. - Cross-head and cross-query budget allocation: Develop principled allocation of sample tokens across heads and queries under a global token budget, using estimated marginal utility or error gradients to maximize overall quality.
- Task-level error translation: The paper empirically correlates with attention error; derive theoretical bounds mapping attention output error to logit perturbation and task metrics (accuracy, BLEU, pass@k), enabling users to choose to meet target performance.
- Numerical stability under mixed precision: Analyze how denominator-only approximation affects softmax normalization in FP16/FP8 or quantized KV caches; propose safeguards (e.g., log-sum-exp stabilization, dynamic scaling) with verified error control.
- Randomness management and reproducibility: Study run-to-run variance induced by sampling; propose seeded sampling, variance-reduction techniques (antithetic sampling, control variates), and confidence interval reporting for practitioners.
- Implementation overhead and cost model: Provide optimized CUDA kernels for budget computation and sampling on GPU; quantify added memory traffic (including base sampling) and end-to-end latency on GPU-hosted KV caches; present a cost model separating index selection, budget estimation, and attention compute.
- CPU offload specifics: When KV is on CPU, detail how the “small random cache” is built/updated without costly PCIe transfers; quantify its size, refresh policy, and accuracy impact; measure CPU-GPU bandwidth savings and limits.
- Scaling to large models and contexts: Evaluate vAttention on larger LLMs (e.g., 34B/70B, MoE), multi-query attention, distributed KV across multi-GPU/multi-node setups, and much longer contexts (≥128K–1M), including throughput and memory implications.
- Training-time applicability: Investigate using vAttention during training/fine-tuning (forward and backward); assess gradient estimator bias/variance, convergence behavior, and whether verified bounds can guide curriculum or regularization.
- Integration with KV compression and block-sparse ops: Study joint use with SnapKV, H2O, ScissorHands, and block-sparse matmuls; define combined guarantees and interactions (e.g., how compression errors interact with sampling errors).
- Fair benchmarking vs. alternative methods: Re-run MagicPig and top-p approximations in their recommended pipelines (e.g., sparse context processing if applicable); include efficient non-oracle top-p approximations (e.g., Tactic configurations) for apples-to-apples comparisons.
- Multi-turn dialogue and retrieval dynamics: Evaluate and adapt sink/local window strategies for shifting relevance across turns; design dynamic sink management and retrieval-aware budgets that react to conversation state.
- Failure mode characterization: Identify conditions under which δ violations lead to large attention/output errors; create monitoring to detect and recover from such events (e.g., fallback to denser attention or budget boosts).
- Data-dependent calibration: Provide procedures to calibrate on small validation traces per model/task, linking desired task-level outcomes to budget choices and offering default settings for common workloads.
- Tighter high-dimensional bounds: Replace the trace-based vector CLT with matrix concentration (e.g., Hanson–Wright, matrix Bernstein) or self-normalized bounds to tighten budgets when is large; validate tightness empirically.
- Parameter ablations and reporting granularity: Include per-layer/head sparsity and error breakdowns, sensitivity to sinks/local window sizes, and results when sparse attention is also used during context processing, not just decoding.
- Streaming/incremental statistics: Explore amortizing budget computation along the sequence (e.g., rolling estimates of , ) to reduce per-step overhead while maintaining guarantees.
- Guidance on choosing : Provide actionable recommendations for selecting based on model size, task type (reasoning vs. generation), context length, and latency constraints, with associated expected quality bands.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging the open-source implementation and demonstrated performance characteristics of vAttention.
- Bold LLM inference acceleration with tunable, verified quality
- Sectors: software, cloud platforms, customer support, legal, finance, healthcare, education
- What: Introduce a “Verified Speed Mode” in LLM inference services, allowing operators to set
epsilon/deltato control accuracy–latency trade-offs per request, head, and query. Use vAttention to reduce KV-cache reads and memory transfers while maintaining full-attention quality at up to 10–20x sparsity (as shown across RULER, LongBench, Loogle, AIME). - Tools/workflows: Integrate vAttention into serving stacks (e.g., vLLM/TGI, Triton, Ray Serve). Offer API parameters for
epsilon,delta,f_t,f_b, sinks and local windows; expose dashboards of observed attention error vs targetepsilonfor SLA and compliance monitoring. - Assumptions/dependencies: CLT-based budget estimates and denominator-only approximation are used; requires a reliable approximate top-k component (e.g., HashAttention). Gains depend on attention score distributions; GPU-side kernels for index computation further improve throughput.
- Bold Long-context RAG and document QA at reduced cost
- Sectors: legal, regulatory, finance research, scientific literature review
- What: Enable verified sparse attention for retrieval-augmented generation over 16–32K contexts, maintaining quality while lowering latency/cost. Use hybrid heavy-hitter selection plus sampling to capture both sharp and flat attention distributions.
- Tools/workflows: “Verified Long-Context Mode” that keeps sinks, local windows, and predicted top-k while sampling tails; per-request quality knobs for compliance-sensitive use cases; automatic parameter selection based on desired coverage and latency budget.
- Assumptions/dependencies: Proper handling of sinks and local windows; top-k prediction accuracy influences residual sampling efficiency; large-context data pipelines must support dynamic budget allocation per head.
- Bold CPU-hosted KV cache offload with near-linear speedups
- Sectors: cloud inference, cost optimization, MLOps
- What: Offload KV caches to CPU RAM and apply vAttention to minimize CPU–GPU transfers during decoding (memory-bound scenario), achieving near-linear latency reduction with sparsity.
- Tools/workflows: Adopt CPU-offload policies for long sequences; use vAttention GPU-side index computation and partial random cache to compute budgets; integrate with scheduler for cross-node inference.
- Assumptions/dependencies: A performant GPU kernel for budget computation improves results beyond naïve PyTorch; latency gains rely on memory-bound workloads and robust CPU–GPU bandwidth.
- Bold Long chain-of-thought reasoning at scale
- Sectors: education (tutoring and exam prep), finance (quant analysis), software (theorem/proof assistance), operations research
- What: Deploy vAttention for 32K-token reasoning tasks without quality loss (AIME2024 demonstration), enabling deep multi-step problem solving while meeting compute budgets.
- Tools/workflows: “Reasoning Turbo” profiles selecting
epsilon/deltabased on desired reasoning depth; monitoring sequence-level error accumulation and dynamic budgets by layer/head. - Assumptions/dependencies: Denominator-first approximation reduces bias accumulation, but tasks with highly irregular attention distributions may require tighter
epsilon, larger base samples, or better top-k.
- Bold Energy and cost reductions in data centers
- Sectors: energy/ESG, cloud providers
- What: Reduce memory I/O and compute through verified sparse attention, lowering power consumption and inference costs while preserving accuracy targets.
- Tools/workflows: Integrate
epsilonas a cost dial in autoscaling policies; attach metered savings to quality targets for sustainability reporting. - Assumptions/dependencies: Actual savings depend on deployment architecture (CPU offload vs GPU-only), kernel optimization quality, and workload attention profiles.
- Bold MLOps observability: attention-error SLAs
- Sectors: software (platform engineering), compliance
- What: Establish quality gates based on the strong correlation between user-defined
epsilonand observed attention errors; build dashboards and alerts tracking approximation error per head/layer. - Tools/workflows: “Attention Quality Monitor” that logs theoretical
(epsilon, delta)and empirical error; automatic fallback to denser modes if error exceeds bounds. - Assumptions/dependencies: Empirical correlation depends on denominator-only relaxation; some tasks may need numerator verification or more conservative budgets.
- Bold Academic experimentation in sparse attention
- Sectors: academia, research labs
- What: Use vAttention as a reproducible baseline with explicit accuracy guarantees to study sparse attention dynamics, error accumulation, and heavy-hitter vs sampling strategies.
- Tools/workflows: Open-source code from the Sparse Attention Hub; standardized benchmarking across RULER/LongBench/Loogle; controlled ablations on sinks, windows, and sampling rates.
- Assumptions/dependencies: Requires careful selection of datasets and attention layers; results can vary with model architecture and context distributions.
- Bold On-device assistants with limited memory
- Sectors: consumer devices, daily life
- What: Run 7–8B models with long-context features on limited GPUs/CPUs, using verified sparse attention to stay within memory and latency constraints.
- Tools/workflows: Integrations with lightweight runtimes (e.g., llama.cpp, GGML variants); profiles for personal journaling, note-taking, and code browsing on prosumer hardware.
- Assumptions/dependencies: Performance gated by kernel optimization and platform support; extreme low-power environments may need further quantization and KV compression.
Long-Term Applications
These applications require further research, engineering, or validation (e.g., optimized kernels, training-time integration, or regulatory acceptance).
- Bold Hardware/kernel co-design for verified sparse attention
- Sectors: semiconductors, AI accelerators
- What: Native GPU/TPU support for vAttention’s hybrid heavy-hitter detection, per-head dynamic budgets, and sampling; memory controllers that minimize KV-cache movement under verified bounds.
- Tools/products: CUDA/HIP kernels, specialized instructions for sampling/bit-cache ops, accelerator IP blocks supporting verified attention.
- Assumptions/dependencies: Vendor adoption; standardized APIs; demonstration of consistent gains across diverse models and workloads.
- Bold Regulated deployments with audited guarantees
- Sectors: healthcare (clinical NLP), legal (contract review), public policy (statute analysis), finance (regulatory filings)
- What: “Certified Sparse Attention” services that provide auditable
(epsilon, delta)logs for each generation and head/layer, suitable for compliance workflows and risk-sensitive applications. - Tools/workflows: Audit trails, conformance tests, worst-case bounds beyond CLT (e.g., Hoeffding-style guarantees), domain-specific verification suites.
- Assumptions/dependencies: Stronger theoretical guarantees (numerator+denominator), domain validation, and regulatory acceptance beyond current CLT approximations.
- Bold Training-time integration to shape attention distributions
- Sectors: AI model training
- What: Fine-tune or pretrain models with attention-aware regularization to make attention more tail-smooth and heavy-hitter identifiable, reducing required budgets at inference.
- Tools/workflows: Loss terms that penalize distributions requiring large budgets; curriculum strategies; teacher–student distillation to align attention behavior with vAttention.
- Assumptions/dependencies: Research to quantify trade-offs between training stability, generalization, and runtime sparsity; potential impact on downstream tasks.
- Bold Distributed KV-cache virtualization and networking
- Sectors: cloud providers, HPC
- What: Spread KV caches across nodes and apply verified sparse attention to minimize network reads; dynamically sample from remote shards with guaranteed error bounds.
- Tools/workflows: “KV Fabric” orchestration layer with attention-aware routing; network-aware budget allocation; cross-node consistency monitoring.
- Assumptions/dependencies: Reliable low-latency networking; schedulers that co-optimize memory movement and verified bounds; multi-tenant fairness.
- Bold Safety-critical robotics and real-time systems
- Sectors: robotics, autonomous systems
- What: Use verified sparse attention to manage long-horizon planning contexts under real-time constraints, balancing latency with guaranteed approximation quality.
- Tools/workflows: Real-time schedulers that adjust
epsilon/deltabased on control loop deadlines; verification of attention-induced errors on control tasks. - Assumptions/dependencies: Additional latency reductions via optimized kernels; domain-specific safety certifications; robust behavior under distribution shifts.
- Bold Quality-tiered LLM APIs with dynamic pricing and SLAs
- Sectors: finance/economics of AI services, cloud marketplaces
- What: Offer pricing tiers tied to guaranteed approximation quality (e.g., “Gold” at
epsilon=0.02, “Silver” atepsilon=0.05) with transparent error bounds and performance targets. - Tools/workflows: Billing integrated with measured attention error; customer-facing dashboards; automated parameter selection by task type.
- Assumptions/dependencies: Customer education on probabilistic guarantees; accurate real-time error estimation; trust and transparency frameworks.
- Bold Personalized education platforms at low compute footprints
- Sectors: education, daily life
- What: On-device or low-cost cloud tutors with long-context memory (course history, student notes) using verified sparse attention to meet budget and responsiveness goals.
- Tools/workflows: Learning management system plugins; adaptive
epsilonschedules during quizzes vs feedback; privacy-preserving deployments. - Assumptions/dependencies: Further kernel optimization and memory compression; user acceptance of probabilistic guarantees.
- Bold Explainability and audit tools for attention approximation
- Sectors: policy/regulatory, enterprise risk
- What: Translate budgets, sampling statistics, and error bounds into interpretable reports explaining where approximations occur and how they affect outputs.
- Tools/workflows: “Attention Audit” reports per interaction; heatmaps of heavy-hitter coverage vs sampled tails; risk scores for approximation-induced variance/bias.
- Assumptions/dependencies: Methods to map technical metrics to human-understandable compliance artifacts; standardized reporting formats.
Notes on core dependencies across applications:
- vAttention relies on combining deterministic heavy-hitter selection (sinks, local window, approximate top-k) with uniform sampling of residual attention; accuracy depends on the quality of heavy-hitter prediction.
- Verified guarantees in practice use CLT-based budget estimation and a denominator-only relaxation; stronger guarantees may require numerator verification and conservative bounds (Hoeffding), potentially at higher cost.
- Maximum gains occur in memory-bound decoding, especially with CPU-hosted KV caches; optimized CUDA kernels for budget computation and sampling will further improve performance.
- Attention distributions vary across heads, queries, layers, and tasks; dynamic per-head budgeting is central to maintaining quality while achieving sparsity.
Glossary
- Adaptive sampling: A strategy that dynamically adjusts sample sizes to meet accuracy constraints based on observed statistics. "adaptive sampling module which ensures user specified guarantees hold for each attention head every layer."
- Approximate nearest neighbor (ANN): Algorithms that quickly find vectors close to a query in high-dimensional space without exact search. "many methods adapt approximate nearest neighbor (ANN) techniques"
- Approximate top-: Methods that estimate the most relevant items (e.g., tokens) without exact computation to reduce cost. "Approximate top- based Sparse Attention"
- Attention sinks: Early tokens designated to always receive attention due to their stabilizing effect on generation. "StreamingLLM attends to “attention sinks” (early tokens) and a sliding window of recent tokens."
- Autoregressive models: Models that generate outputs token-by-token, conditioning each token on previously generated ones. "in autoregressive models, these caches must be repeatedly read for every new token prediction."
- Bit signatures: Compact binary encodings of vectors used to speed up similarity or inner-product searches. "HashAttention encodes queries and keys as bit signatures."
- Central Limit Theorem (CLT): A statistical theorem stating that sums of many random variables tend toward a normal distribution. "We leverage the Central Limit Theorem (CLT) to approximate the sum using a sufficiently large sample."
- Covariance matrix: A matrix capturing variances and pairwise covariances among components of random vectors. "Let be the covariance matrix for the population ."
- Decoding latency: The time delay incurred during token generation, often dominated by memory and computation bottlenecks. "State-of-the-art sparse attention methods for reducing decoding latency fall into two main categories"
- Denominator-only approximation: An algorithmic relaxation that guarantees accuracy by approximating only the attention denominator. "we adopt a relaxation that uses an -approximation of the denominator alone."
- Graph-based ANN search: Approximate nearest neighbor methods that traverse graph structures to find similar items efficiently. "adopts graph-based ANN search"
- Heavy-hitter tokens: Tokens that contribute disproportionately large weight or influence to the attention output. "identifying outlier or heavy-hitter tokens"
- Hierarchical clustering: A clustering technique that builds a tree of groups, often used to organize tokens for efficient search. "employs hierarchical clustering"
- Hoeffding's method: A concentration inequality-based approach providing conservative bounds for sums of bounded random variables. "optimistic CLT and conservative Hoeffding's method for budget computation"
- Importance sampling: A variance-reduction technique that samples more frequently from important regions of the distribution. "MagicPig, though based on importance sampling, also fails to outperform other methods consistently."
- Inner product search: The problem of finding items with the largest dot product with a given query vector. "As top- identification is essentially an inner product search problem"
- KV cache: The stored key–value embeddings for past tokens that attention reads repeatedly during generation. "Large contexts produce massive key–value (KV) embedding caches"
- Locality Sensitive Hashing (LSH): A randomized hashing technique that increases the chance similar items collide, enabling efficient approximate search. "It employs Locality Sensitive Hashing (LSH) to select tokens for attention computation."
- Long tail: The portion of a distribution consisting of many small contributions that collectively matter. "residual long tail of tokens with similar attention scores"
- Memory-bound: A regime where performance is limited mainly by memory access rather than compute. "This makes the decoding step inherently memory-bound and time-consuming"
- Oracle top-: An idealized baseline that knows the exact top- items under full attention for comparison purposes. "oracle-top- as a baseline, which serves as the theoretical gold standard"
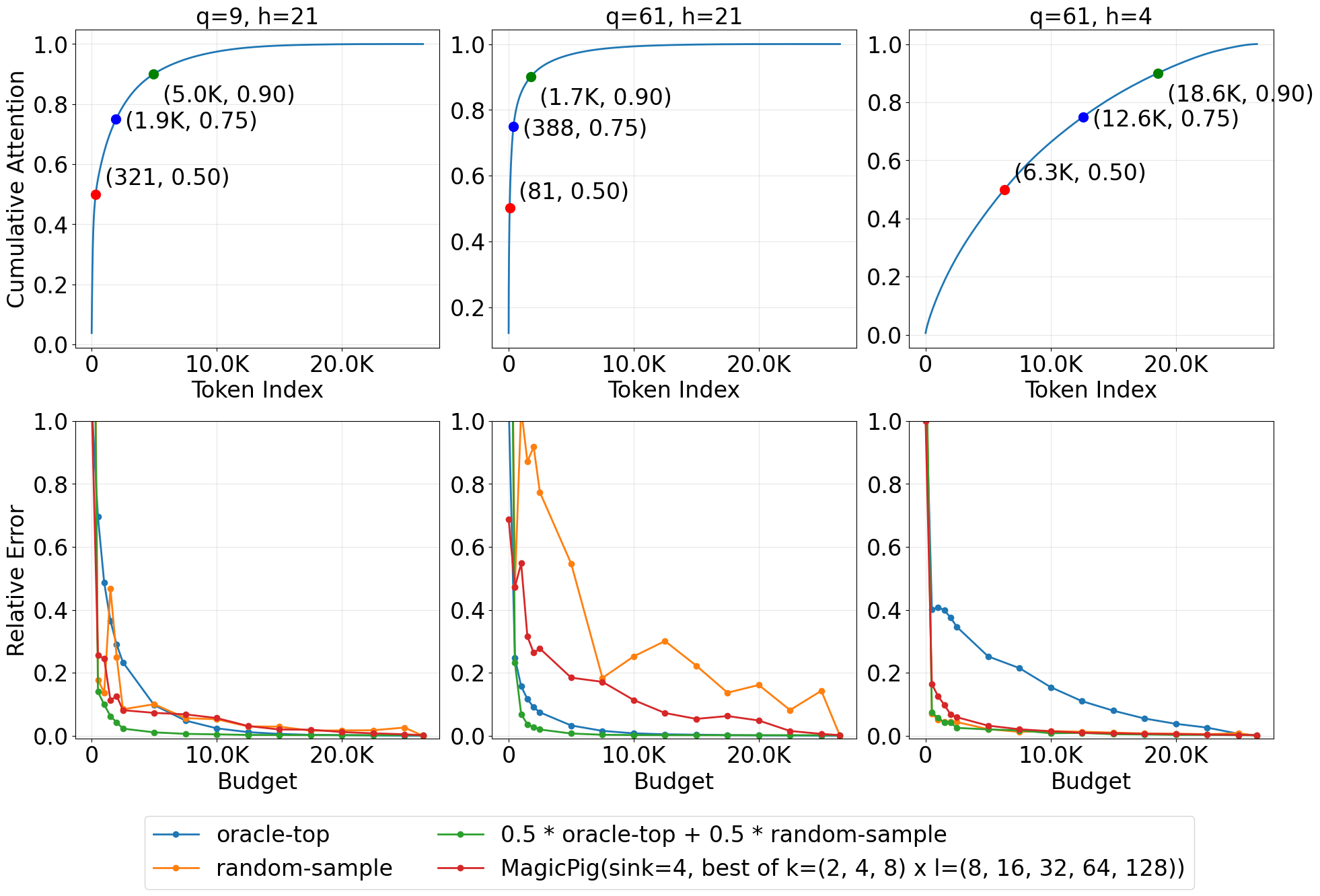
- Oracle top-: An idealized baseline selecting a variable number of tokens to cover a target cumulative attention mass . "Oracle top-, representing the best achievable top- approximation, does not always reach full model quality"
- Pareto curves: Plots showing trade-offs between two objectives (e.g., accuracy and sparsity) across configurations. "Pareto curves (Quality and Error vs. Density) for different baselines and their combination with vAttention"
- Power-law distribution: A heavy-tailed distribution where large values are rare but influential, often used to model attention decay. "models attention decay with a power-law distribution to estimate the required number of tokens."
- Product quantization: A vector compression method that quantizes subspaces independently to enable fast approximate search. "leverages product quantization"
- Relative error: The error normalized by the magnitude of the true quantity, expressing proportional deviation. "incurs at most an relative error with probability "
- Scaled Dot Product Attention (SDPA): The core transformer operation computing weighted sums of values based on softmaxed dot products of queries and keys. "Scaled Dot Product Attention (SDPA) operator, the core operation behind the success of transformer architectures"
- Sliding window: A fixed-size window of most recent tokens included in attention to capture local context efficiently. "a sliding window of recent tokens."
- Sparse attention: An approach that computes attention over a subset of tokens to reduce memory and compute costs. "A mitigation strategy is sparse attention, which reduces memory movement by attending only to a subset of tokens in the KV cache."
- Top-: Selecting the highest-scoring items (e.g., tokens) under a relevance measure like dot-product. "top- approach (top-, its extension, chooses budgets per head)."
- Top- coverage: Selecting a variable number of tokens whose cumulative attention scores exceed a threshold . "Top-p coverage, selecting a variable number of tokens whose cumulative attention scores exceed a threshold "
- Uniform random sampling: Sampling each item with equal probability, used to estimate sums or expectations reliably. "approximating the residual long tail of tokens with similar attention scores using uniform random sampling."
- User-specified guarantees: Probabilistic accuracy bounds chosen by users, ensuring error below with probability at least . "user-specified guarantees on approximation accuracy"
- Variance: A measure of dispersion that affects the randomness of estimation error; contrasted with bias in long sequences. "Unlike variance, bias compounds across sequence length"
- Verified sparse attention: A sparse attention mechanism that provides formal probabilistic guarantees on approximation accuracy. "vAttention, the first practical sparse attention mechanism with user-specified guarantees on approximation accuracy (thus, “verified”)."
Collections
Sign up for free to add this paper to one or more collections.