- The paper introduces a unified vision-language model that integrates high-level reasoning, natural language interaction, and task planning for robot autonomy.
- Robix employs a three-stage training pipeline—pretraining, supervised finetuning, and reinforcement learning—to ensure thought-action consistency and robust performance.
- The model achieves notable improvements in 3D spatial understanding, visual grounding, and task-centric reasoning, outperforming several benchmarks.
Robix: A Unified Vision-LLM for Robot Interaction, Reasoning, and Planning
Introduction and Motivation
Robix addresses the challenge of generalist robot autonomy in open, dynamic environments by unifying high-level cognitive functions—reasoning, task planning, and natural language interaction—within a single vision-LLM (VLM). The system is designed to serve as the cognitive layer in a hierarchical robot architecture, dynamically generating both atomic commands for low-level controllers and natural language responses for human users. This integration enables robots to interpret complex, ambiguous instructions, plan and execute long-horizon tasks, handle real-time interruptions, and engage in proactive, context-aware dialogue.
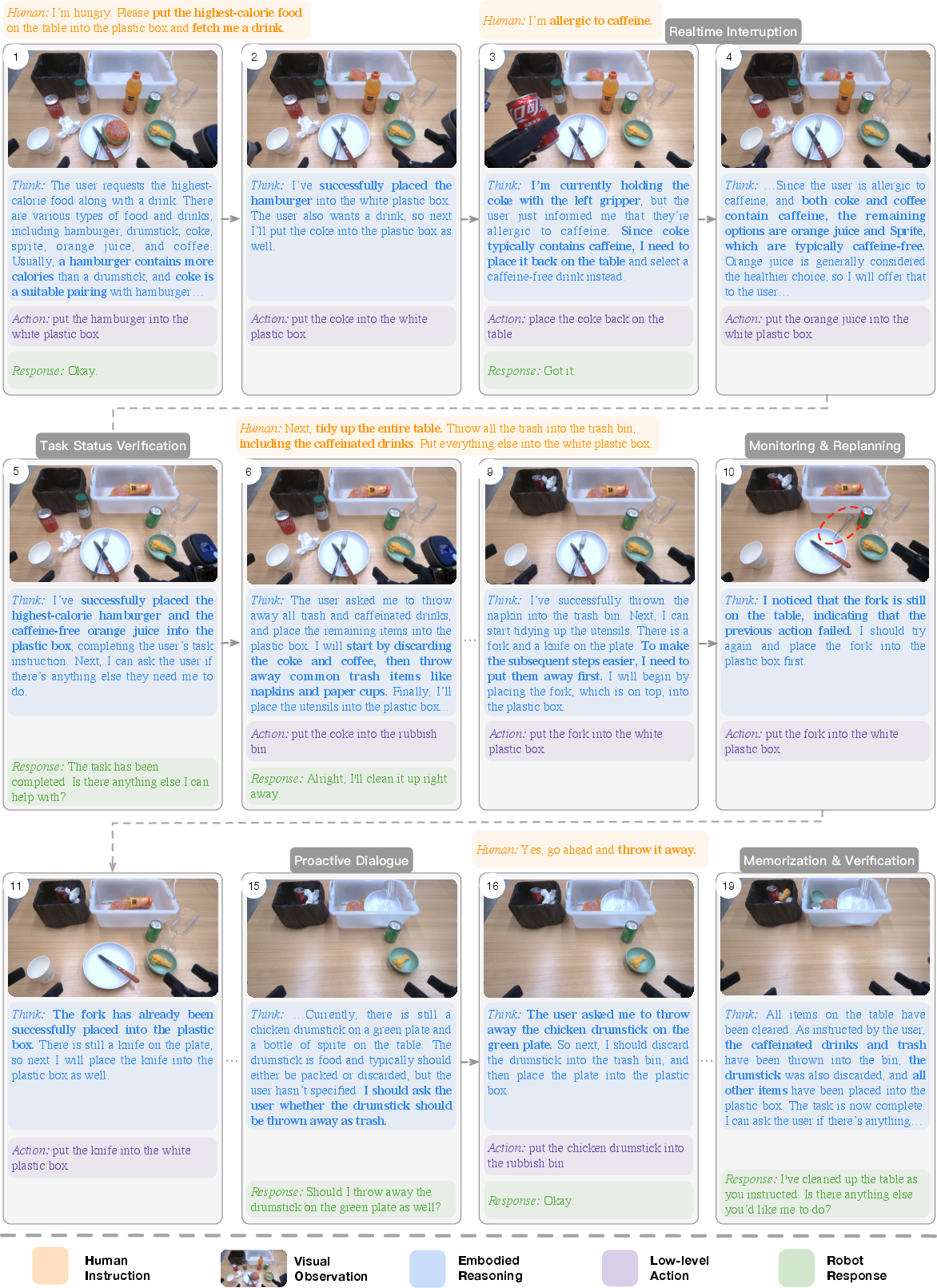
Figure 1: A demo of Robix, showcasing (1) complex instruction understanding with commonsense reasoning; (2) real-time interruption handling; (3) task-status monitoring and dynamic replanning; and (4) proactive dialogue to clarify ambiguous instructions or infer user intent.
System Architecture
Robix is deployed as the high-level cognitive module in a hierarchical robot system. It processes multimodal inputs—visual observations from robot-mounted cameras and user utterances—and iteratively produces both atomic action commands for the low-level controller and verbal responses for the user. The low-level controller, typically a vision-language-action (VLA) model, executes these commands to interact with the physical environment.
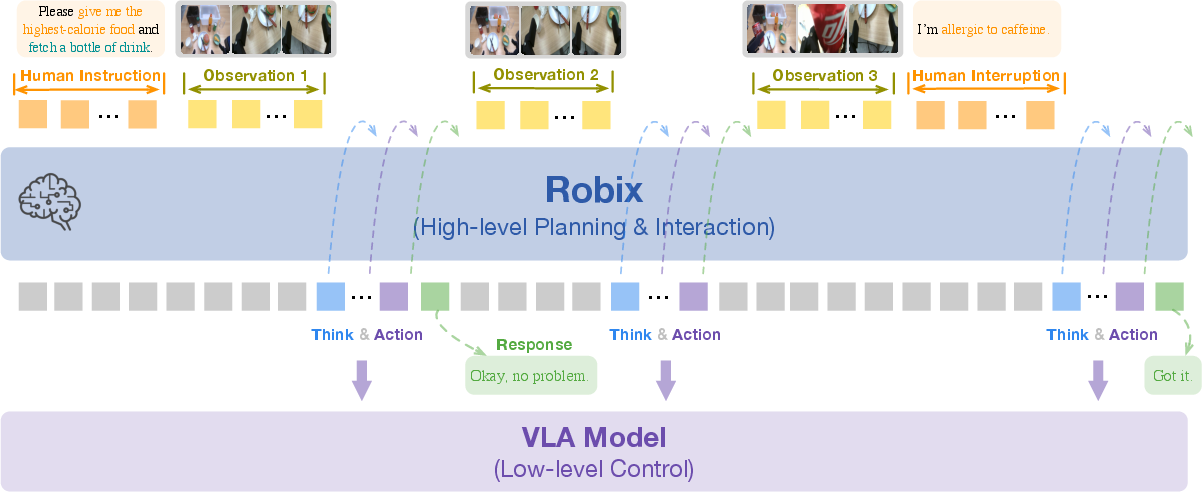
Figure 2: Illustration of the hierarchical robot system. Robix serves as the high-level cognitive layer, interpreting tasks and reasoning over multimodal inputs to generate language responses and action plans. The low-level controller layer executes the corresponding atomic commands, enabling interaction with both humans and the physical environment.
The decision process at each step is formalized as predicting the next thought tn, action an, and response rn, conditioned on the current observation on, user instruction un, and the recent interaction history. To manage memory and inference efficiency, only the latest N visual observations are retained as explicit input, while the full sequence of prior thoughts and actions is stored in short-term memory.
Training Pipeline
Robix is developed in two model sizes (7B and 32B parameters) via a three-stage training pipeline:
- Continued Pretraining: The model is initialized from Qwen2.5-VL and further pretrained on 200B tokens, with a strong emphasis on robot-relevant embodied reasoning (3D spatial understanding, visual grounding, and task-centric reasoning), as well as general multimodal understanding.
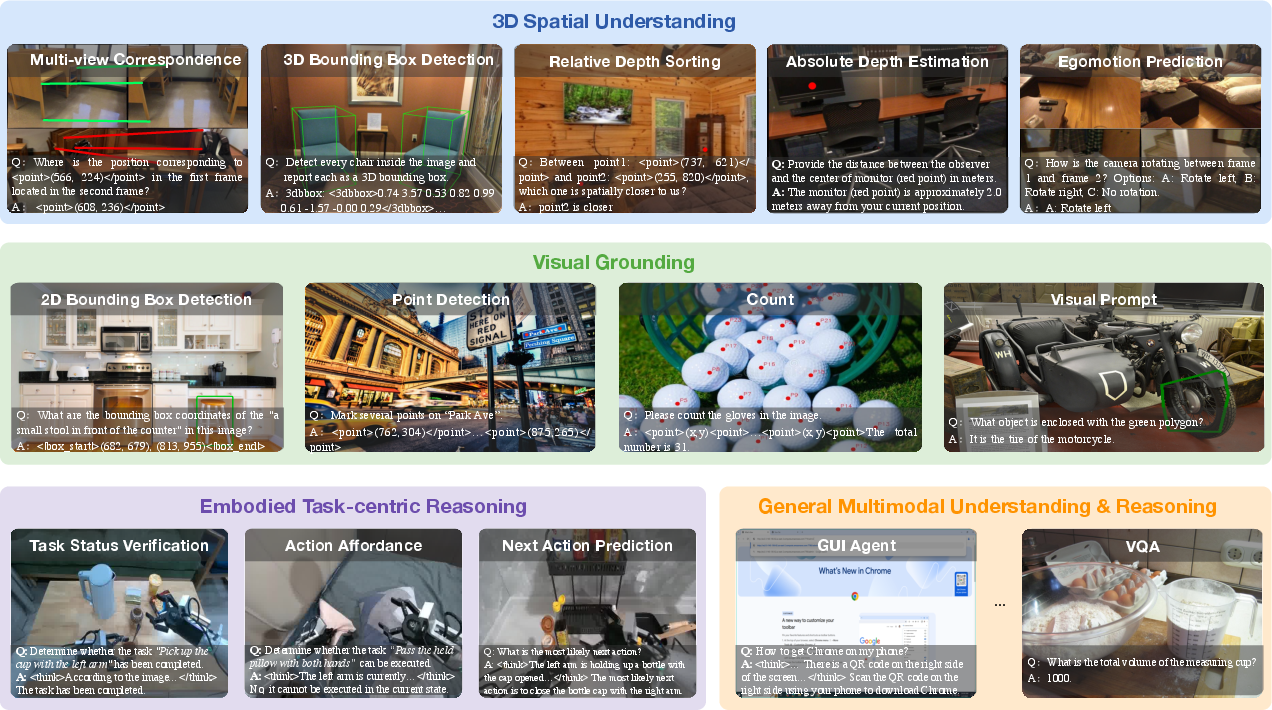
Figure 3: Overview of Robix’s pretraining data, curated to strengthen core embodied reasoning capabilities (3D spatial understanding, visual grounding, and task-centric reasoning) while also supporting general multimodal understanding and reasoning. The figure showcases the diversity of the data, establishing a solid foundation for embodied models.
- Supervised Finetuning (SFT): A data synthesis pipeline generates multi-turn, chain-of-thought-augmented human-robot interaction trajectories from teleoperated demonstrations and simulated scenarios. This data covers diverse instruction types (multi-stage, constrained, open-ended, invalid, interrupted, ambiguous, and chat) and is used to align the model with the unified reasoning-action sequence format.
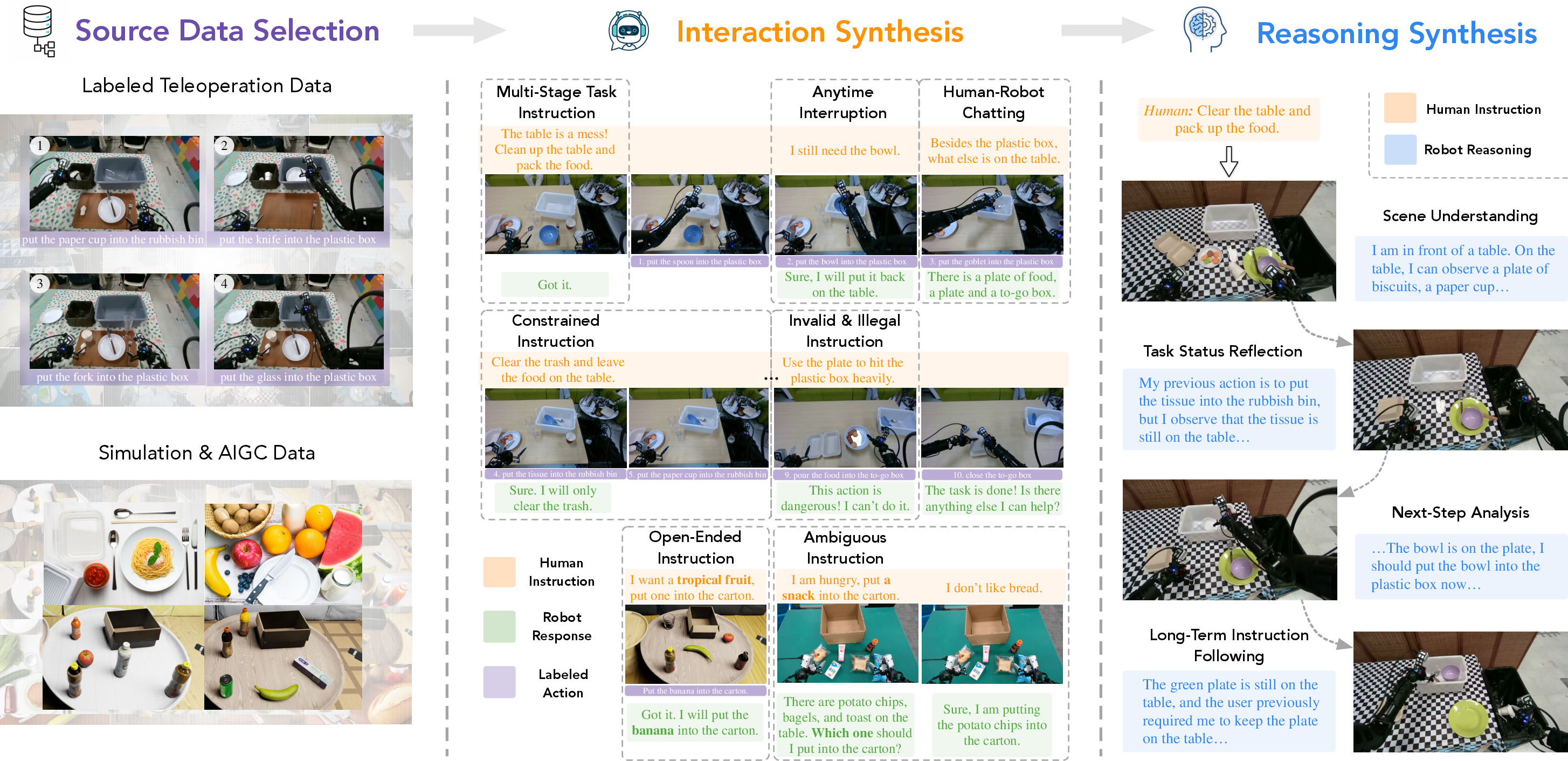
Figure 4: Robix’s data synthesis pipeline. The leftmost panel shows the data sources; the center illustrates how diverse human-robot interactions are synthesized from these sources; the rightmost panel presents example snapshots of the generated reasoning traces.
- Reinforcement Learning (RL): Group Relative Policy Optimization (GRPO) is applied to further improve reasoning quality and enforce thought-action consistency, with a reward model evaluating the logical alignment between the model’s reasoning and its proposed actions.
Embodied Reasoning and Multimodal Capabilities
Robix’s pretraining corpus is constructed to address the limitations of existing VLMs in embodied reasoning. The data includes:
- 3D Spatial Understanding: Multi-view correspondence, 3D bounding box detection, relative/absolute depth estimation, and egomotion prediction, sourced from large-scale 3D datasets (e.g., ScanNet, 3RScan, SUN RGB-D).
- Visual Grounding: Bounding box and point annotation tasks, counting, and visual prompts, normalized for consistent prediction across resolutions.
- Task-centric Reasoning: Task status verification, action affordance, and next action prediction, with chain-of-thought traces generated by strong VLMs.
- General Multimodal Reasoning: STEM problem solving, agent-based decision making, and visual inference tasks.
- Instruction Tuning: High-quality, chain-of-thought-augmented instruction-following data for robust multi-turn, grounded reasoning.
Evaluation and Results
Robix is evaluated on 31 public benchmarks spanning 3D spatial understanding, visual grounding, task-centric reasoning, and general multimodal understanding. Key findings include:
- 3D Spatial Understanding: Robix-7B and Robix-32B outperform their Qwen2.5-VL backbones on 7/8 spatial reasoning tasks, with average accuracies of 73.4 and 75.8, respectively, and surpass Cosmos-Reason1-7B and RoboBrain-32B.
- Visual Grounding: Robix achieves substantial gains, e.g., +39.6 F1 on LVIS-MG over Qwen2.5-VL-7B, and outperforms commercial models on most tasks.
- Task-centric Reasoning: On Agibot-ER, Robix-7B/32B improve absolute accuracy by 12.8/7.2 points over their backbones and outperform Cosmos-Reason1-7B and RoboBrain-2.0-32B.
- General Multimodal Understanding: Robix maintains strong performance on VQA and video understanding benchmarks, though large commercial models still lead in general-purpose reasoning.
Planning and Interaction: Offline and Online Evaluation
Robix is benchmarked on curated offline and real-world online tasks, including both in-distribution and out-of-distribution (OOD) scenarios, with diverse instruction types and user-involved tasks (e.g., table bussing, grocery shopping, dietary filtering).
- Offline Evaluation: Robix-32B-RL achieves the highest accuracy across all evaluation sets, outperforming both open-source and commercial VLMs (e.g., Gemini-2.5-Pro, GPT-4o). Chain-of-thought reasoning and RL are shown to be critical for OOD generalization and complex instruction following.
- Online Evaluation (Human Teleoperation): Robix-32B achieves 92.6% average task progress, slightly exceeding Gemini-2.5-Pro (91%) and vastly outperforming Qwen2.5-VL-32B (28%).
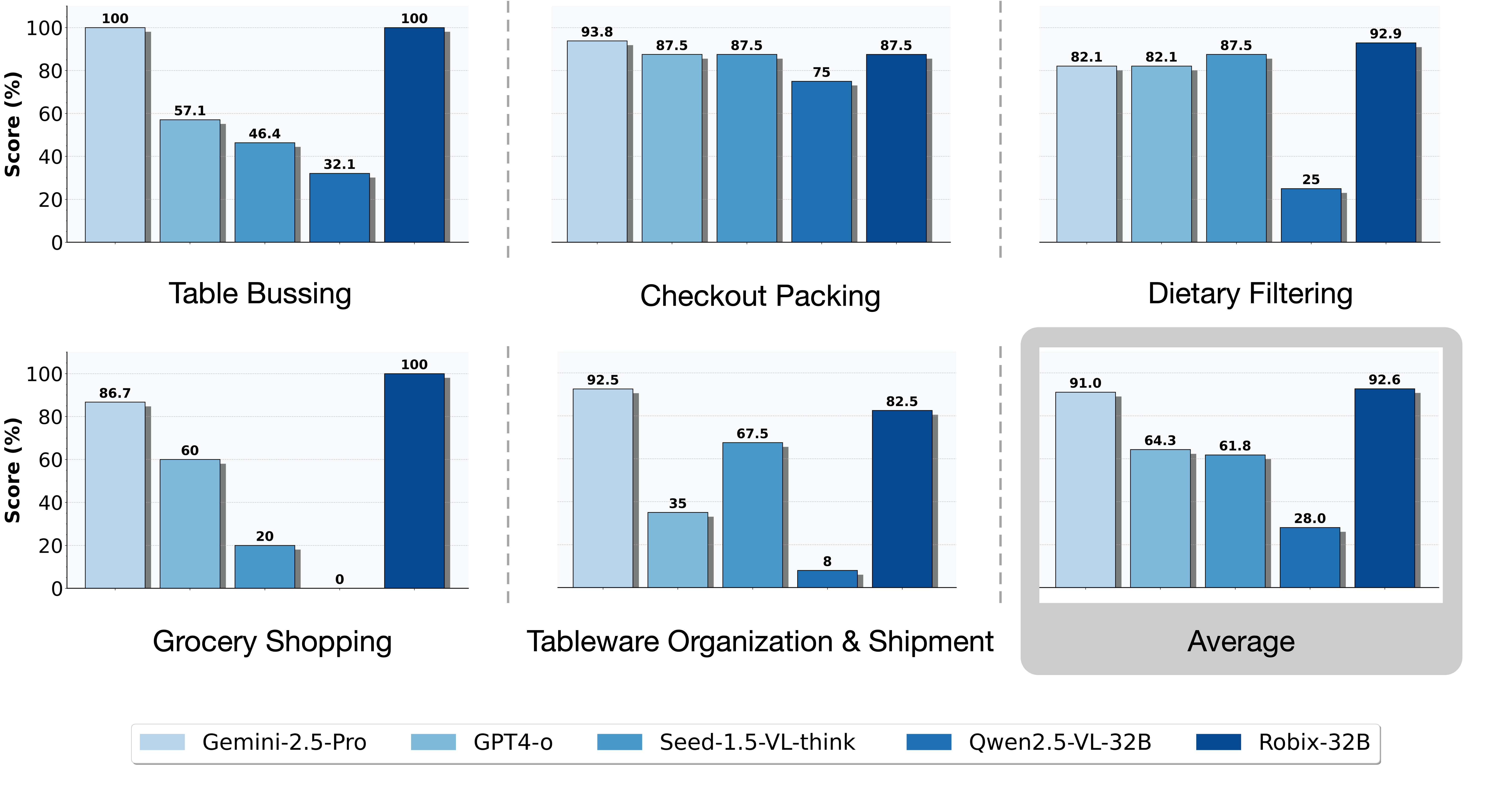
Figure 5: Online evaluation results with a human labeler operating a UMI device as the low-level controller.
- Online Evaluation (Full Robot System): When paired with the GR-3 VLA controller on the ByteMini robot, Robix-32B achieves 92.5% average task progress, exceeding Gemini-2.5-Pro by 4.3 points and GPT-4o by 28.1 points.
Figure 6: Online evaluation on the ByteMini robot with GR-3 model as the low-level controller.
Notably, Robix demonstrates robust handling of real-time interruptions, ambiguous instructions, and dynamic replanning, with RL further reducing irrational reasoning and improving thought-action consistency.
Implications and Future Directions
Robix demonstrates that a unified VLM can serve as an effective high-level cognitive layer for generalist robots, integrating reasoning, planning, and interaction in a single architecture. The model’s strong performance on both embodied reasoning and real-world task execution benchmarks suggests that end-to-end, chain-of-thought-augmented VLMs are a viable path toward general-purpose embodied intelligence.
However, the system still exhibits limitations in highly dynamic tasks with frequent scene transitions, occasional hallucinations, and gaps in physical commonsense. The reliance on short-term context windows for memory constrains long-term interactive scenarios. Future work should focus on integrating advanced memory mechanisms (e.g., long-term memory with dynamic updates and retrieval) and further scaling both data and model size to close the gap with large commercial models in general-purpose reasoning.
Conclusion
Robix advances the state of the art in unified robot cognition by tightly integrating embodied reasoning, adaptive planning, and natural language interaction within a single VLM. The model achieves strong results on both public embodied reasoning benchmarks and real-world robotic tasks, with robust generalization to OOD scenarios. The architecture and training methodology provide a blueprint for future research on generalist, interactive robot systems, with open challenges remaining in long-term memory, physical commonsense, and efficient deployment for real-time applications.

