- The paper's main contribution is the design of VIGIL, an external reflective runtime that autonomously diagnoses and repairs LLM agents using affective and event analysis.
- It employs a layered pipeline—covering observation, reflection, diagnosis, and adaptation—to achieve significant reductions in errors and operational latency.
- Empirical results demonstrate dropped premature notifications, reduced mean event latency, and elimination of high-intensity frustration signals, confirming robust self-healing performance.
VIGIL: A Reflective Runtime for Self-Healing LLM Agents
Motivation and Conceptual Underpinnings
VIGIL (Verifiable Inspection and Guarded Iterative Learning) addresses a persistent challenge in agentic LLM frameworks: operational brittleness and lack of runtime adaptability. While many LLM agents claim autonomy through iterative planning, tool use, and memory, in deployment they often manifest as fragile, templated chains of LLM calls lacking any substantive mechanism for introspection, diagnostics, or self-directed repair. Existing stacks are limited by their inability to remember or analyze past failures without ongoing human intervention; consequently, maintenance defaults to ad hoc prompt modification or manual code debugging.
VIGIL abstains from augmenting the agent’s “intelligence” directly. Instead, it introduces a dedicated, external reflective runtime tasked exclusively with the autonomous oversight and healing of sibling agents. This separation of concerns decouples task-level problem-solving from system-level self-maintenance, a crucial distinction for scalable and robust agent deployment.
System Architecture and Workflow
VIGIL’s runtime is architected as a layered stage-gated pipeline, incorporating the following tightly coupled modules: Observation, Reflection, Diagnosis, Adaptation, and Orchestration. The runtime is external to the agent, passively monitoring event logs, synthesizing affective state, and managing adaptation artifacts.
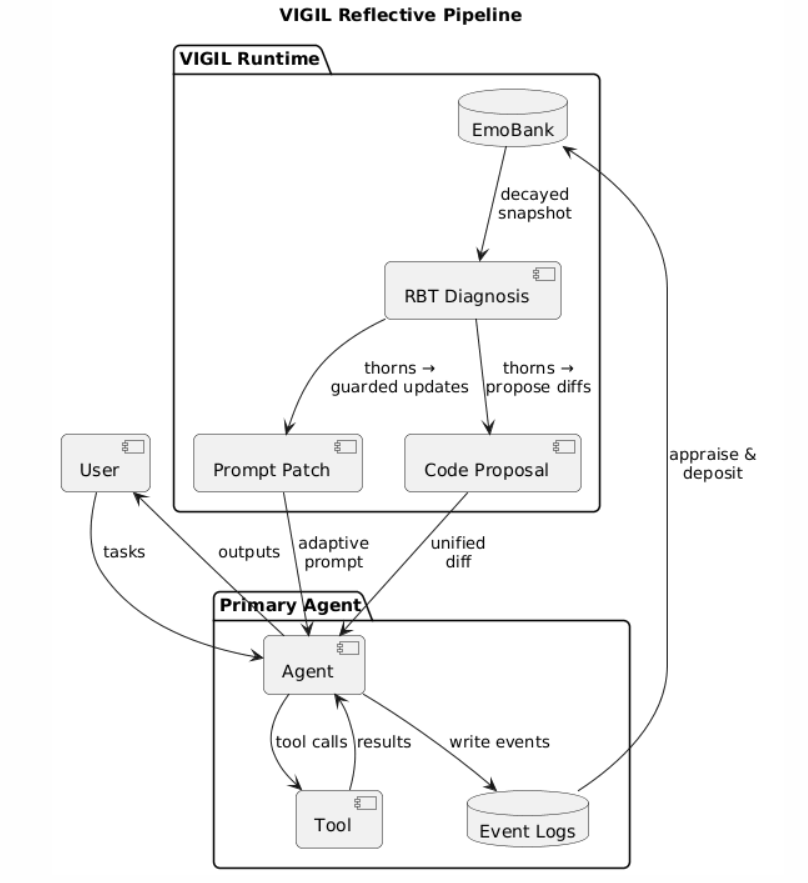
Figure 1: The VIGIL system architecture mediates log ingestion, appraisal, diagnosis, and adaptation, producing prompt and code diffs as external artifacts.
Observation and Affective Appraisal
Behavioral logs from the target agent serve as the substrate for all analysis, providing structured event streams amenable to temporal windowing and semantic inspection. VIGIL’s deterministic appraisal engine transforms events into affective representations—discrete emotions (e.g., frustration, joy), valence, and intensity—encoded in EmoBank, a decaying, episodically indexed emotional memory.
The affective memory model incorporates decay and coalescence to prioritize salient, recent events while smoothing noise and tracking emotional “rebound” following set-backs. Composite contextual signals (e.g., stress, focus) are derived from these affective aggregates, informing diagnosis and adaptation.
Reflective Diagnosis and RBT Schema
The core diagnostic engine collates affective and behavioral traces into a Roses-Buds-Thorns (RBT) schema:
- Roses: High-valence, high-intensity successes to reinforce.
- Buds: Latent opportunities or promising patterns.
- Thorns: Critical failures that demand remediation.
This schema not only structures the system’s reflective output but serves as a deterministic mapping from experience to adaptation, thus separating introspection from adaptation logic.
Adaptation: Prompt and Code Proposal
Adaptations are produced at two levels:
- Prompt adaptation involves surgical updates to a delimited adaptive prompt section, under strict immutability guardrails that maintain the agent’s core-identity.
- Code proposals are generated as unified diffs, localizing remediations to code “hotspots” as identified by strategy modules operating over recent logs and event history.
All outputs are emitted as versioned artifacts, creating a forensic audit trail for inspection, rollback, and integration into deployment workflows. The system’s orchestrator enforces legal transitions between pipeline stages, aborting or erroring out-of-order tool invocation, thereby constraining the LLM to productive states and minimizing undesired improvisation.
A controlled evaluation with the testbed agent Robin-A reveals VIGIL’s reflective strengths. In routine operation, Robin-A failed to gate “success” notifications on true backend receipt, introduced inconsistent timestamp formats, and demonstrated silent behavioral degradation undetectable by superficial status checks.
VIGIL’s EmoBank surfaced repeated, high-intensity negative affect tied to these defects—frustration and anxiety—allowing the diagnosis and prioritization of thorns even when no hard failures (exceptions, crashes) were present. The reflective loop produced minimal, actionable prompt and code proposals, including receipt-based toast gating, UTC timestamp normalization, and robust retry logic for tool invocation.
Of particular interest, VIGIL’s own diagnostic toolchain experienced a schema mismatch. The runtime parsed and interpreted its own diagnostic traceback, surfaced a structured repair suggestion for itself, and proceeded via fallback logic until patched. Upon reinvocation post-fix, the pipeline resumed normal operation. This demonstrates not only standard agentic adaptation but meta-procedural self-healing: the reflective layer supervises, repairs, and validates its own introspective machinery, ensuring liveness and correctness of the oversight process itself.
Quantitative Results
- Premature notifications dropped from 100% (12/12) to 0%.
- Mean event latency fell from 97s to 8s.
- High-intensity frustration signals reduced to zero.
- Consistent UTC timestamping and enforced receipt-gating were achieved.
VIGIL’s interventions eliminated silent failures and operationalized affective recovery, evidenced by EmoBank’s shift toward positive or neutral emotional aggregates. The system thus achieves not only behavioral repair but also affective closure, and confirms patch effectiveness through a repeatable, artifact-first process.
Theoretical and Practical Implications
VIGIL reframes agentic maintenance as an external, modular concern. This out-of-band reflection permits more robust cross-sectional oversight, enabling the detection of soft failures—subtleties invisible in stateless logs—via affective trend analysis. The architecture contrasts sharply with in-prompt, in-context approaches to self-reflection, favoring persistent stateful monitoring and artifactable adaptation.
The demonstrated metacognitive capabilities—runtime self-diagnosis and self-remediation—portend a shift toward agent swarms overseen by shared reflective cores, rather than individually instrumented agents. The possibility of population-level supervision via affective telemetry and distributed RBT diagnoses is implied, with extensions to real-time operation, cross-agent causal inference, and learned (rather than rule-driven) appraisal mechanisms.
Practically, VIGIL offers a pathway to deployable, safe, self-healing agents able to maintain autonomy over long time horizons with reduced developer burden. Its artifact-based adaptation loop aligns well with modern CI/CD pipelines and layered governance models, supporting enforced policy and post-hoc audit without constraining agent cognition or work output.
Limitations and Future Directions
VIGIL currently operates episodically on log windows, rather than as a live runtime. While the architecture supports streaming operation, there are open engineering questions regarding real-time adaptation, conflict resolution, and on-the-fly code mutation in safety-critical contexts.
Potential research expansions include:
- Streaming, online affective monitoring and instant adaptation.
- Multi-agent reflective overlays and population-level diagnosis.
- Domain-general affective appraisal (leveraging learned models).
- Integration with empirical tool behavior profiling to anticipate regressions.
Conclusion
VIGIL establishes a new paradigm for agentic self-maintenance: a structurally independent, externalized reflective runtime capable of affectively-driven diagnosis, actionable proposal emission, and meta-procedural self-repair. Its architectural division of task and maintenance enables interpretable, reproducible adaptation cycles, and the system empirically demonstrates strong gains in reliability and robustness. VIGIL’s framework positions reflection not as static self-critique, but as a persistent, system-level substrate for resilient, self-healing agent operation—a foundation for trustworthy and autonomous agentic infrastructures.

