PARC: An Autonomous Self-Reflective Coding Agent for Robust Execution of Long-Horizon Tasks
Abstract: We introduce PARC, a coding agent for the autonomous and robust execution of long-horizon computational tasks. PARC is built on a hierarchical multi-agent architecture incorporating task planning, execution, and a mechanism that evaluates its own actions and their outcomes from an independent context and provides feedback, namely self-assessment and self-feedback. This design enables PARC to detect and correct high-level strategic errors and sustain progress without human intervention. We evaluate PARC across computational science and data science tasks. In materials science, it autonomously reproduces key results from studies on lithium-ion conduction and alloy segregation. In particular, it coordinates dozens of parallel simulation tasks, each requiring roughly 43 hours of computation, managing orchestration, monitoring, and error correction end-to-end. In Kaggle-based experiments, starting from minimal natural-language instructions, PARC conducts data analysis and implements search strategies, producing solutions competitive with human-engineered baselines. These results highlight the potential of integrating a hierarchical multi-agent system with self-assessment and self-feedback to enable AI systems capable of independent, large-scale scientific and analytical work.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces PARC, a smart coding agent that can plan and run long, complicated computer projects by itself. Think of PARC as a team made of helpful “AI coworkers” that can organize the work, write code, run experiments, check its own progress, and fix mistakes—without needing a person to guide every step.
What questions does the paper try to answer?
- How can we get AI agents to finish complex, multi-step tasks that take a long time (hours, days, or more) without getting stuck?
- Can better agent design—not just a stronger LLM—make a big difference?
- Does teaching the agent to reflect on its work (self-assessment and self-feedback) help it avoid big, strategy-level mistakes?
How does PARC work?
PARC is built like a small company running a project:
- A planner makes the overall plan: what to do first, what comes next, and what tools might be needed.
- Several workers carry out the tasks: each worker focuses on one task at a time (like writing a piece of code or running a simulation).
- A reviewer role (self-assessment) checks the work from a fresh angle and gives feedback (self-feedback), helping find and fix problems early.
In everyday terms:
- “Long-horizon tasks” are big projects with many steps that can take a long time. If each step has a small chance of failure, a long chain of steps can easily fail overall.
- “Self-assessment” is like checking your homework carefully before turning it in.
- “Self-feedback” is like correcting course if you realize your plan isn’t working.
PARC also uses a shared workspace (a common project folder) so files, code, and results from earlier tasks can be reused by later tasks. Human approval is used once at the start (to confirm the plan), and then PARC runs the project mostly on its own. If PARC sees that the current approach won’t work, it can pause the project and explain what needs fixing.
What did PARC do, and what did it find?
The team tested PARC on several tough, real-world tasks. Here are the highlights:
1) Materials science: Lithium-ion movement in a solid electrolyte (LGPS)
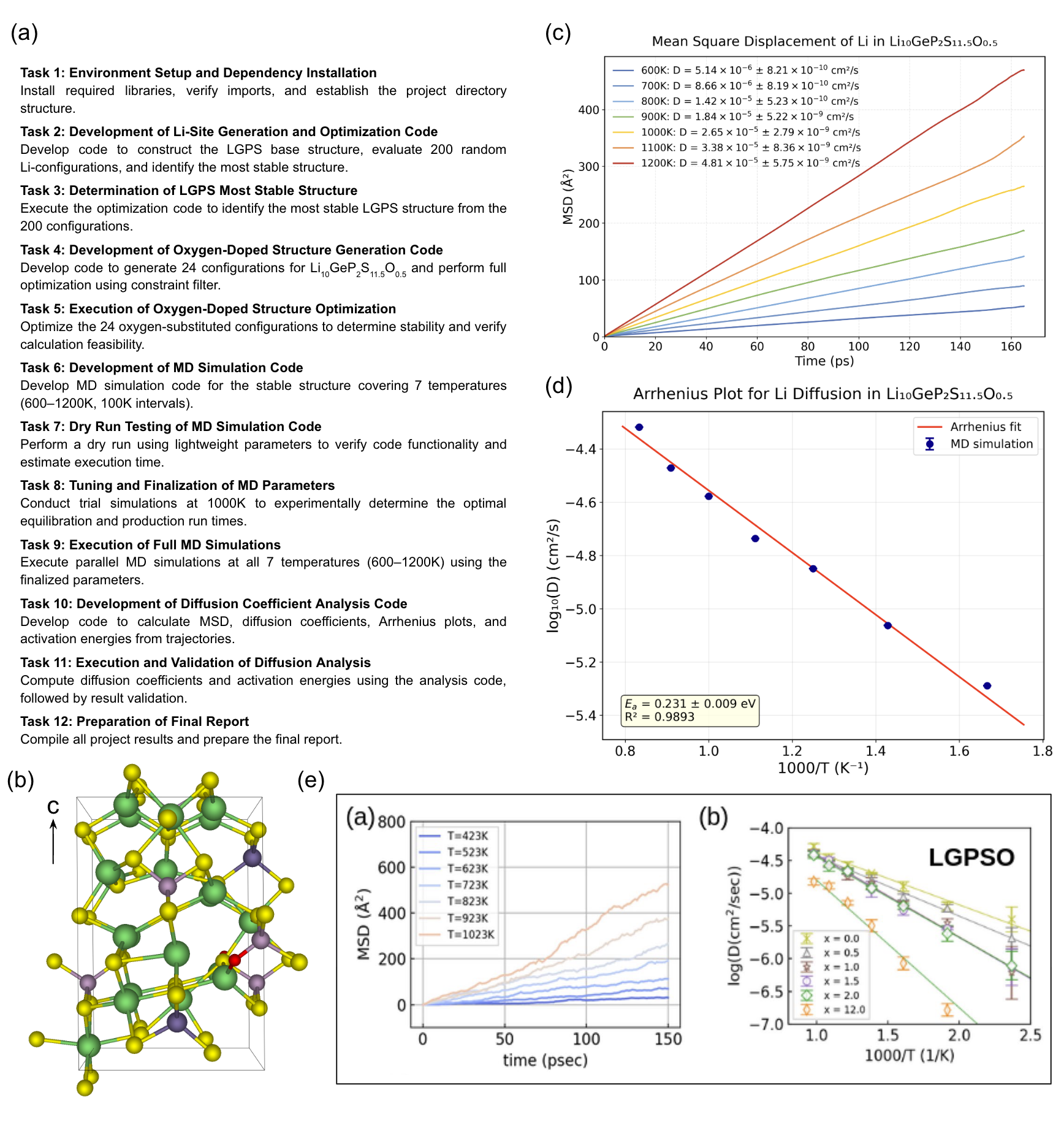
- PARC set up and ran molecular dynamics (MD) simulations to study how lithium ions move in a crystal, and computed the “activation energy” (how much energy is needed for ions to move) from how diffusion changes with temperature.
- Result: PARC produced an activation energy around 0.23 eV, close to a published result (~0.18 eV). That’s good, considering differences in setup and randomness in the system.
- Why it matters: PARC coordinated many long simulations (some taking ~43 hours each) and fixed issues along the way, showing it can manage large scientific workloads end-to-end.
2) Materials science: How tiny atoms (B and N) affect a Cr–Ni alloy
- PARC implemented a Monte Carlo simulation (a method that tries many possibilities using random moves) to study how light interstitial atoms (boron and nitrogen) change the crystal structure.
- Result: It matched the published trend: boron tends to cluster and distort the structure (reducing the stable FCC phase), while nitrogen keeps the structure more stable.
- Why it matters: The agent ran 35 long simulations in parallel and corrected several technical issues on its own. It did miss a couple of details, but the overall conclusion was consistent.
3) Physics: Oxygen-ion conduction in YSZ under an electric field
- PARC extended a standard MD tool to include an external electric field () and tried to reproduce key plots from a research paper.
- Result: The agent ran the simulations but made mistakes in the analysis code (like handling atoms across periodic boundaries). With human help reviewing the agent’s simulation data, the final trends matched the original paper qualitatively.
- Why it matters: Even when PARC stumbled, its simulations were useful and could be salvaged. It also showed it can change tactics when one method fails.
4) Data science: Kaggle Polymer Prediction Challenge
- PARC built models to predict polymer properties from chemical strings (SMILES). It handled data prep, feature engineering, model training, and tuning.
- Result: With a hint to use a known chemistry tool (mordred), PARC achieved an average score of 0.781, slightly better than a human baseline (0.764) from a public notebook. Without mordred, it still beat a prior research baseline.
- Why it matters: From minimal instructions, PARC built competitive models and even caught and fixed issues like data leakage (accidentally training on test data).
5) Algorithms: Kaggle Santa Polytope Permutation Puzzle
- PARC implemented puzzle solvers (like beam search) and improved the score over the default baseline by reducing the total number of moves by about 21,000.
- Result: Not near the winning score (which used advanced external solvers), but strong for a solution built from scratch without those tools.
- Why it matters: PARC handled complex software engineering: writing emulators, choosing algorithms, parallelizing work, and managing resources.
Why is this important?
- Agent design matters. Even with today’s strong LLMs, long, multi-step projects often fail because the agent forgets context, makes uncorrected strategy mistakes, or can’t manage complex workflows.
- PARC’s architecture—planning + focused task execution + self-checking—helps the agent avoid getting lost and correct course. This improved reliability on long projects without changing the underlying LLM.
- PARC showed it can run large scientific and data projects for days, managing many tasks and jobs, which would be exhausting to do manually.
What’s the impact, and what comes next?
- With better agent designs, AI could take on more independent roles: running big experiments, building full data pipelines, and tackling long software projects.
- PARC is a step toward agents that think in two modes: fast “System 1” (do the next step) and careful “System 2” (review, reflect, and adjust).
- Still, there’s room to improve:
- Catching more errors automatically (especially subtle ones).
- Breaking tasks into smaller, easier-to-check pieces.
- Discovering and safely using the best external tools on its own.
- If these advances continue, future agents might not just assist humans—they could reliably carry out complex scientific discovery and large-scale engineering with minimal guidance.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to be directly actionable for future research.
- Lack of evaluation on standard long-horizon coding benchmarks (e.g., SWE-Bench Pro, public and commercial) to substantiate generalization beyond custom case studies.
- No controlled ablations isolating the contribution of self-assessment/self-feedback vs. a standard coding agent (e.g., success-rate gains, error detection/correction rates, time/computation overhead).
- Absence of a formal definition and metrics for “long-horizon” and “robust execution” (e.g., step count, wall-clock duration, failure recovery rate, rework/rollback frequency).
- Unspecified gating criteria for advancing between tasks (“sufficient level of quality”): thresholds, decision rules, and calibration procedures are not defined or evaluated.
- Planner requires human approval of the task sequence; the degree of human involvement and its effect on outcomes are not quantified, and pathways to safe auto-approval are not explored.
- Self-assessment reliability is unmeasured (precision/recall, false positive/negative rates, calibration of confidence, inter-judge consistency across LLMs).
- No formal error taxonomy or root-cause analysis indicating which error classes self-feedback detects (or misses) across domains (e.g., numerical methods, spec coverage, orchestration).
- Context isolation and summary-passing are claimed beneficial but not empirically evaluated (e.g., measured reduction in context contamination, information loss from summarization, task handoff fidelity).
- Replanning capability is limited: the agent can halt but does not autonomously revise global plans when prerequisites fail or assumptions change; closed-loop re-planning is not specified or tested.
- Scalability beyond the demonstrated 10–20 tasks (~100 steps) is untested; behavior with thousands of steps, complex dynamic DAGs, or months-long projects remains unknown.
- Compute orchestration details are missing (scheduler/queue integration, preemption handling, checkpointing, resubmission policies, cross-host portability across HPC/cloud).
- Parallel execution reliability is not quantified (job success rates, mean time to recovery, throughput, completion time distributions, tail behaviors).
- Resource costs and efficiency are not measured (compute hours, energy usage, LLM token costs) vs. human baselines or alternative agents.
- Model dependence is unexamined: results rely on Claude Sonnet 4.5; robustness across LLMs (GPT-5, Gemini 3, open-weight models), degraded contexts, or offline/local models is unknown.
- Security/safety model for executing arbitrary code and installing external packages is absent (sandboxing, network isolation, permissioning, secrets handling, dependency provenance).
- Automated tool discovery is limited; agent needed hints (e.g., mordred). Methods to autonomously search, vet (licenses, security), and integrate external libraries under constraints are not implemented or evaluated.
- Requirement coverage and spec compliance are ad hoc; missed features (e.g., second-neighbor shell placement, cell-shape relaxation) highlight need for automated requirement tracing and verification.
- Numerical-method auditing is insufficient; failures in PBC displacement calculations and NPT equilibration suggest the need for systematic unit/integration tests, numerical stability checks, and physics-specific validators.
- Handling of nondeterminism and statistical uncertainty in scientific results is limited (no confidence intervals, replicate runs, power analysis, sensitivity to seeds/time/cell sizes).
- Domain validation is narrow; cross-tool verification (e.g., alternative MD packages), first-principles checks, and domain test suites are not integrated.
- Halting policy may be suboptimal; criteria for escalation, early stopping, and notification are unspecified and not evaluated for false halts or excessive retries.
- Provenance and workspace schema are underspecified; absence of machine-readable metadata, artifact versioning, and validation checks risks misinterpretation by downstream tasks.
- Communication protocols between planner and workers lack formal contracts (typed APIs, SLA-like guarantees, error budgets), making handoff reliability and diagnostics hard to assess.
- No direct comparison with other hierarchical/self-reflective agent harnesses (e.g., LLM-as-a-Judge pipelines, Self-Refine, AlphaEvolve-like systems) on shared tasks or benchmarks.
- Theoretical analysis of improved success probability (beyond the chain-of-failure intuition) is absent; no formal model quantifying how the architecture changes expected task completion rates.
- Kaggle polymer study uses cross-validation on public data and non-official metrics (), risking optimistic generalization; leaderboard submissions or blinded test evaluations are not reported.
- Compliance and data-leakage policies for competitions are not discussed (e.g., ensuring no rule violations, leakage checks, strict train/test separation enforcement).
- Santa 2023 solution ceiling is limited by not discovering or integrating high-performance external solvers when permitted; solver search strategies under constraints are not implemented.
- Multimodal and non-CLI task support (GUIs, lab instruments, robotics) is unexplored; integration layers and safety for real-world lab automation are not specified.
- Trustworthiness of self-judgment is not calibrated (no uncertainty scoring, confidence intervals, or mechanisms to avoid self-justifying loops and confirmation bias).
- Latency/throughput trade-offs of self-feedback loops are unmeasured; overhead vs. benefit curves, adaptive triggering strategies, and amortized cost analysis are missing.
- Automatic parameter tuning (e.g., MD time steps, ensembles, schedules) appears heuristic; systematic optimization frameworks (Bayesian optimization, DOE) and validation pipelines are not integrated.
- Handling of large intermediate artifacts (logs, datasets) is uncharacterized; summarization strategies for very large outputs and their impact on downstream accuracy are not evaluated.
- Environmental drift and dependency updates during long runs (library changes, OS upgrades) are not monitored; mechanisms for reproducibility under change are absent.
- Human review of outcomes (“domain experts reviewed outputs”) may bias results; blinded expert evaluation, inter-rater reliability, and reproducibility by third parties are not provided.
- Code, configurations, seeds, and full experiment artifacts are not released; third-party reproducibility and independent verification of demonstrations remain uncertain.
- Ethical/governance safeguards for autonomous scientific or engineering work (e.g., misuse of compute, unsafe code generation, compliance checks) are not established.
Practical Applications
Immediate Applications
Below is a concise set of real-world applications that can be deployed now, grounded in PARC’s demonstrated capabilities (hierarchical planning, task-scoped execution, self-assessment/self-feedback, structured workspace) and its case studies in computational science and data science.
- Autonomous orchestration of multi-day computational materials workflows (Energy/Materials R&D)
- Use PARC to plan, launch, monitor, and recover large batches of MD/MC simulations (e.g., lithium-ion diffusion, alloy segregation), including parameter sweeps and Arrhenius analyses.
- Potential tools/products/workflows: “PARC Simulation Orchestrator” integrating ASE, PFP, VESTA, Slurm/Kubernetes; job dashboards; automatic reruns on failure.
- Assumptions/dependencies: Access to HPC/cluster resources, validated potentials/force fields, domain expert sign-off for initial plan.
- Parallel job management and failure recovery for long-horizon scientific compute (HPC/Scientific Computing)
- Maintain dozens of runs over 1–2+ day windows with autonomous monitoring, retries, and progress gating informed by self-assessment.
- Potential tools/products/workflows: Scheduler adapters (Slurm, PBS, Kubernetes); alerting hooks; checkpoint-aware runners.
- Assumptions/dependencies: Scheduler permissions, robust logging/observability, cost-aware policy limits.
- Paper reproduction assistant for computational studies (Academia/Open Science)
- Autonomously reproduce published figures/tables (e.g., MSD, I–V curves), generate reproducibility notebooks, and produce audit-ready summaries of methods, parameters, and artifacts.
- Potential tools/products/workflows: “Reproducibility Notebook Generator”; structured workspace to citation-linked artifacts; runbooks with task summaries.
- Assumptions/dependencies: Access to datasets/configs/codes; human review for plan approval and result validation.
- End-to-end data science pipeline builder (Software/Finance/E-commerce)
- From minimal instructions, construct baseline and optimized ML models (LightGBM/XGBoost), perform cross-validation, detect and fix leakage, and deliver prediction modules competitive with public baselines.
- Potential tools/products/workflows: AutoML-like agentic pipelines; Optuna-based hyperparameter tuning; feature extraction (e.g., mordred) when available; MLOps integration.
- Assumptions/dependencies: Data access, compute budget, clear metrics/validation protocol, governance for tool use.
- Guardrailed hyperparameter optimization with self-feedback (ML Operations)
- Use self-assessment gates to avoid overfitting/leakage and to revert or adapt optimization decisions property-by-property (e.g., FFV vs. density).
- Potential tools/products/workflows: “Adaptive Tuner” that pairs tuning with validity checks and rollback; per-target model selection.
- Assumptions/dependencies: Reliable cross-validation strategy, meaningful performance monitors.
- Robust execution of algorithmic search tasks without external solvers (Software/Optimization)
- Implement emulators, evaluate search strategies (beam search, iterative deepening), segment problems by scale, and improve scores under resource constraints (e.g., Kaggle puzzle tasks).
- Potential tools/products/workflows: “Agentic Solver” for state-space problems; scale-aware method selection; parallelized search runners.
- Assumptions/dependencies: Compute/time budgets; clarity on acceptable solver/tool use; ability to monitor timeouts.
- Self-reflective CI/CD “long-runner” harness (Software Engineering/DevOps)
- Run multi-step build/test/deploy pipelines with autonomous gating, failure diagnosis, retry strategies, and concise artifact summaries for human review.
- Potential tools/products/workflows: Plugins for GitHub Actions/Jenkins; workspace-linked artifacts; plan/execute gates.
- Assumptions/dependencies: Repository access, secrets management, integration with test suites and deployment targets.
- Structured workspace and artifact summarization at scale (Cross-sector)
- Aggregate outputs, locations, and usage instructions (code, data, configs) per task, enabling downstream tasks to reuse artifacts without dragging full logs/context.
- Potential tools/products/workflows: “Agent-generated runbooks” and provenance views; artifact indexers.
- Assumptions/dependencies: Shared file systems/object storage; stable naming conventions.
- AIOps for multi-day jobs with halt-and-replan logic (IT Operations)
- Monitor long-running batch processes, detect approach-level issues (e.g., mis-specified parameters), and pause/resume with corrective plans.
- Potential tools/products/workflows: Observability connectors; rule-based escalation; human approval checkpoints.
- Assumptions/dependencies: Access to logs/metrics; policy for autonomous intervention.
- Computational education labs assistant (Academia/Education)
- Scaffold student assignments that include multi-step simulations/data analysis (e.g., MD setup, parameter sweeps), with audit trails and self-checks for basic validity.
- Potential tools/products/workflows: Jupyter-integrated agent; course-specific templates and sandboxes.
- Assumptions/dependencies: Curriculum assets, controlled compute environment, instructor oversight.
- Enterprise R&D automation for alloy/material screening (Manufacturing)
- Implement specified MC/MD rules, run comparative studies (e.g., B/N interstitial effects), and generate executive-ready plots/reports.
- Potential tools/products/workflows: “Materials Study Bot” with PTM analysis; batch job launchers; report generators.
- Assumptions/dependencies: Model validation, safety/compliance for proprietary simulations.
- Open science reproducibility audits for funders/journals (Policy)
- Provide auditable reruns of published computational work with documented discrepancies, parameter differences, and uncertainty discussions.
- Potential tools/products/workflows: Reproducibility compliance reports; artifact sign-off workflows.
- Assumptions/dependencies: Legal data/code access; agreed replication standards; compute credits.
- Personal long-horizon automation for data tasks (Daily Life)
- Orchestrate multi-step personal data analyses (e.g., multi-source budget consolidation, long backups/transcoding with retries), with summaries and checkpoints.
- Potential tools/products/workflows: CLI schedulers for home data tasks; minimal dashboards; task summaries.
- Assumptions/dependencies: API access/auth, privacy safeguards, device/storage availability.
Long-Term Applications
The following applications require further research, scaling, or development—especially stronger self-assessment, autonomous tool discovery, formal verification, and broader integration beyond command-line contexts.
- Fully autonomous scientific discovery agent (AI for Science)
- Move from reproduction to hypothesis generation, experimental design, and closed-loop simulation/experiment cycles (e.g., active-learning for materials).
- Potential tools/products/workflows: Literature mining + agentic planning; lab-in-the-loop orchestration; Bayesian optimization loops.
- Assumptions/dependencies: Robust causality/reasoning, lab interfaces/robotics, validated scientific models.
- Enterprise-scale software engineering on complex codebases (Software Engineering)
- Address SWE-Bench Pro–level tasks by combining plan/execute with formal validation, multi-repo reasoning, and long-lived memory across weeks/months.
- Potential tools/products/workflows: Codebase-aware “System 2” harness; static/dynamic analysis; property-based testing; change-risk gates.
- Assumptions/dependencies: Access to enterprise code/testing infra, strong verification layers, human-in-the-loop governance.
- Autonomous tool discovery and safe plugin integration (Cross-sector)
- Discover, evaluate, and integrate external libraries/solvers dynamically (e.g., domain-specific optimizers), with safety scoring and versioning.
- Potential tools/products/workflows: Tool marketplace connectors; capability/compatibility estimation; sandboxed execution.
- Assumptions/dependencies: Reliable tool retrieval signals; permissioning; robust tool-use safety.
- Exascale parameter sweeps and surrogate-guided optimization (Energy/Materials)
- Combine massive simulation campaigns with surrogate models/active learning to accelerate discovery (e.g., electrolytes, superalloys).
- Potential tools/products/workflows: HPC/exascale schedulers; experiment managers; uncertainty-aware surrogates.
- Assumptions/dependencies: Extreme compute capacity, data management at scale, validated surrogates.
- Healthcare bio-simulation pipelines and in-silico trials (Healthcare/Pharma)
- Automate long-horizon PK/PD, MD/CFD, and virtual populations analyses; integrate with clinical data for hypothesis vetting.
- Potential tools/products/workflows: Regulated simulation stacks; traceable pipelines; GxP-compliant audit trails.
- Assumptions/dependencies: Regulatory acceptance, clinically validated models, patient privacy/safety.
- Robotics fleet planning and monitoring for long missions (Robotics/Automation)
- Use self-feedback to plan, execute, and correct multi-step operational workflows across time and environments.
- Potential tools/products/workflows: ROS-integrated agent; anomaly detection; mission-level audit trails.
- Assumptions/dependencies: Real-time constraints, safety/certification, robust sensing/actuation.
- Energy grid modeling and demand-response optimization (Energy/Utilities)
- Coordinate complex, multi-day simulations and data ingestion for grid stability and pricing strategies.
- Potential tools/products/workflows: Power systems simulators integration; scenario planners; optimization loops.
- Assumptions/dependencies: Secure access to utility data, regulatory approvals, high availability.
- Finance: autonomous backtesting, risk gating, and phased deployment (Finance)
- Run hundreds of strategies over long horizons, detect regime shifts, and gate live rollouts based on self-assessment of performance and risk.
- Potential tools/products/workflows: Compliance-aware agentic quant platform; audit-ready provenance tracking.
- Assumptions/dependencies: Regulatory compliance, high-quality market data, robust risk frameworks.
- Government compliance, audit, and evidence generation (Policy/GovTech)
- Continuous, long-term analysis of procurement, grants, and logs; produce standardized audit artifacts with self-critique.
- Potential tools/products/workflows: Policy-aware agent harness; explainable audit narratives; FOIA-ready bundles.
- Assumptions/dependencies: Data governance, privacy/security controls, clear statutory frameworks.
- Personalized longitudinal learning and project mentorship (Education)
- Plan multi-month learning paths with auto-executed computational labs, self-graded checkpoints, and adaptive pacing.
- Potential tools/products/workflows: LMS-integrated agent; competency mapping; project artifact portfolios.
- Assumptions/dependencies: Rich content libraries, assessment reliability, educator oversight.
- Enterprise knowledge provenance and reproducibility graphs (Cross-sector)
- Convert PARC workspaces/task summaries into organization-wide knowledge graphs that link results to methods and decisions.
- Potential tools/products/workflows: Provenance graph builders; standards (e.g., RO-Crate); search/trace tools.
- Assumptions/dependencies: Storage/metadata standards, inter-team adoption, privacy controls.
- Safety-critical agent architectures with formal self-verification (Cross-sector)
- Pair self-feedback with runtime verification and formal proofs to reduce undetected errors in long-horizon tasks.
- Potential tools/products/workflows: Proof assistants, property-checking layers, certified “System 2” guards.
- Assumptions/dependencies: Advances in formal methods integration, performance overhead management, domain-specific specs.
- Consumer “autonomous household orchestrator” for complex routines (Daily Life/IoT)
- Plan and maintain multi-step home operations (backups, device updates, energy optimization) with halt-and-replan under constraints.
- Potential tools/products/workflows: Smart-home orchestration agents; energy-aware schedulers; privacy-preserving summaries.
- Assumptions/dependencies: Secure device APIs, cross-vendor interoperability, household data protections.
Glossary
- activation energy: The energy barrier for ion or particle transport, typically extracted from temperature-dependent measurements or simulations. "The activation energy derived from the slope is 0.231 eV."
- all-solid-state lithium batteries: Batteries that use solid electrolytes instead of liquid, enabling enhanced safety and potentially higher energy density. "LGPS, a sulfide solid electrolyte, is regarded as a key candidate for all-solid-state lithium batteries owing to its high lithium-ion conductivity at room temperature."
- Arrhenius fit: A regression that models temperature dependence following the Arrhenius equation, often used to estimate activation energies. "prompted by self-feedback on the irregular temperature dependence, accuracy of the Arrhenius fit, and limited statistical sampling,"
- Arrhenius plot: A graph of the logarithm of a rate (e.g., diffusion coefficient) versus inverse temperature to reveal activation energies. "The activation energy is derived from the Arrhenius plot of diffusion coefficients,"
- Atomic Simulation Environment (ASE): A Python library for setting up, running, and analyzing atomistic simulations. "- Atomic Simulation Environment (ASE)"
- beam search: A heuristic graph search algorithm that explores a set of the most promising nodes at each depth, balancing performance and search breadth. "the agent finally adopted beam search, which offered a superior balance between computational cost and success rate."
- block averaging: A statistical technique that divides a trajectory into segments to estimate uncertainties and reduce correlation in time series data. "the data covers approximately 165 ps because the trajectory was divided into three segments for block averaging."
- BCC: Body-centered cubic crystal structure, characterized by a lattice with atoms at cube corners and a single atom at the center. "Evolution of structural fractions (FCC/HCP/BCC/Other) with B doping (1, 4, and 10 at.%)."
- context saturation: Exhaustion of the available model context due to accumulating information, leading to degraded reasoning or recall. "this architecture can become a severe bottleneck regarding context saturation, error accumulation, and maintaining long-term perspective."
- context window: The finite amount of text (tokens) an LLM can attend to at once, limiting how much history the agent can use directly. "Such a design is highly effective in short-term tasks where all relevant information can be stored within a single context window."
- FCC: Face-centered cubic crystal structure with atoms at each face and corner of the cube, common in metals. "the FCC fraction decreases significantly with increasing concentration (dropping to approximately 71% at 10 at.%)."
- HCP: Hexagonal close-packed crystal structure, a dense packing arrangement common in certain metals. "accompanied by the emergence of an HCP phase."
- ionic conductivity: A measure of charge transport due to moving ions within a material, often dependent on temperature and field. "(d) Ionic conductivity at each electric field strength (calculated based on Eq.~(2) of the original paper)."
- Iterative Deepening A*: A variant of A* search combining depth-first iterative deepening with heuristic guidance. "Initially, the agent implemented the “Iterative Deepening A*” algorithm,"
- Langevin dynamics: A stochastic dynamics method incorporating random forces and friction to model thermal environments. "including the implementation of Langevin dynamics considering an external electric field,"
- mean squared displacement (MSD): The average squared distance particles travel over time, used to compute diffusion coefficients. "diffusion coefficients, which are calculated from the mean squared displacement (MSD) of lithium ions at each temperature."
- minimum-image implementation: A technique for applying periodic boundary conditions by using the nearest periodic image to compute distances. "corrected this by adopting a minimum-image implementation to handle arbitrary cell shapes."
- Monte Carlo (MC) simulation: A stochastic simulation method using random sampling to explore states or configurations according to specified rules. "using Monte Carlo (MC) simulation."
- NPT simulations: Molecular dynamics simulations at constant number of particles, pressure, and temperature to reach equilibrium lattice parameters. "failed to properly execute the NPT simulations for equilibration"
- orthogonal simulation cell: A simulation box with perpendicular lattice vectors; assuming orthogonality can cause errors for tilted cells. "interatomic distances were computed assuming an orthogonal simulation cell,"
- oxide-ion conductor: A material in which oxygen ions carry charge, critical for solid oxide fuel cells. "YSZ is a prototypical oxide-ion conductor used as an electrolyte in solid oxide fuel cells (SOFCs),"
- percolation transition: A threshold-driven change where pathways become connected, dramatically altering transport properties. "the percolation transition induced by oxygen doping changes the activation energy by about 0.11 eV,"
- plan-and-execute pattern: An agent architecture where a planner designs tasks and workers execute them sequentially. "following a plan-and-execute pattern as shown in Fig.~\ref{fig:simple_workflow}."
- polyhedral template matching analysis: A structural classification method that identifies local crystal structures by matching to polyhedral templates. "utilizing the polyhedral template matching analysis."
- PreFerred Potential (PFP): A neural network interatomic potential used to model atomic interactions efficiently. "- Neural Network Potential: PreFerred Potential (PFP) version v3.0.0"
- segregation behavior: The tendency of certain atoms (e.g., interstitials) to cluster in particular regions like grain boundaries, affecting properties. "evaluated the segregation behavior of light interstitial elements"
- self-assessment: An agent’s internal evaluation of its actions and outputs to detect issues and guide corrections. "provides feedback, namely self-assessment and self-feedback."
- self-feedback: The mechanism by which an agent uses self-assessment results to adjust its strategy or actions. "self-assessment and self-feedback."
- self-reflection: A higher-level reasoning process where the agent reviews its approach and outcomes holistically. "incorporates the concept of self-reflection mentioned in the introduction."
- supercell: A larger periodic cell built by replicating a unit cell to reduce finite-size effects in simulations. "The simulations were conducted using a supercell at 1073 K,"
- SWE-Bench Pro: A benchmark of long-horizon software engineering tasks from real codebases used to evaluate coding agents. "On the SWE-Bench Pro (Public Dataset), current best LLMs reach only around 40\% resolve rate,"
- VESTA: A visualization tool for crystal structures and volumetric data. "This structure was visualized using VESTA~\cite{vesta}."
- yttria-stabilized zirconia (YSZ): A zirconia-based ceramic stabilized with yttria, widely used as an electrolyte due to oxygen-ion conduction. "oxygen-ion conduction in yttria-stabilized zirconia (YSZ) under an external electric field."
Collections
Sign up for free to add this paper to one or more collections.