DoVer: Intervention-Driven Auto Debugging for LLM Multi-Agent Systems
Abstract: LLM-based multi-agent systems are challenging to debug because failures often arise from long, branching interaction traces. The prevailing practice is to leverage LLMs for log-based failure localization, attributing errors to a specific agent and step. However, this paradigm has two key limitations: (i) log-only debugging lacks validation, producing untested hypotheses, and (ii) single-step or single-agent attribution is often ill-posed, as we find that multiple distinct interventions can independently repair the failed task. To address the first limitation, we introduce DoVer, an intervention-driven debugging framework, which augments hypothesis generation with active verification through targeted interventions (e.g., editing messages, altering plans). For the second limitation, rather than evaluating on attribution accuracy, we focus on measuring whether the system resolves the failure or makes quantifiable progress toward task success, reflecting a more outcome-oriented view of debugging. Within the Magnetic-One agent framework, on the datasets derived from GAIA and AssistantBench, DoVer flips 18-28% of failed trials into successes, achieves up to 16% milestone progress, and validates or refutes 30-60% of failure hypotheses. DoVer also performs effectively on a different dataset (GSMPlus) and agent framework (AG2), where it recovers 49% of failed trials. These results highlight intervention as a practical mechanism for improving reliability in agentic systems and open opportunities for more robust, scalable debugging methods for LLM-based multi-agent systems. Project website and code will be available at https://aka.ms/DoVer.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces DoVer, a new way to “auto-debug” teams of AI assistants (called multi-agent systems) that use LLMs. Instead of only guessing where things went wrong by reading long chat logs, DoVer actually tries out fixes in the middle of a run and checks whether they help. Think of it like pausing a game when a team is losing, changing a play, and then resuming to see if the team can still win.
What questions did the researchers ask?
The paper looks at two main questions:
- How can we reliably figure out what went wrong in a complex AI team, where many messages and steps happen?
- If we make a targeted change (an “intervention”) at the suspected mistake, does the system improve or even succeed?
They also ask a practical question: is it better to focus on getting the task to work (outcomes) rather than trying to perfectly blame a single step or agent for the failure?
How did they study the problem?
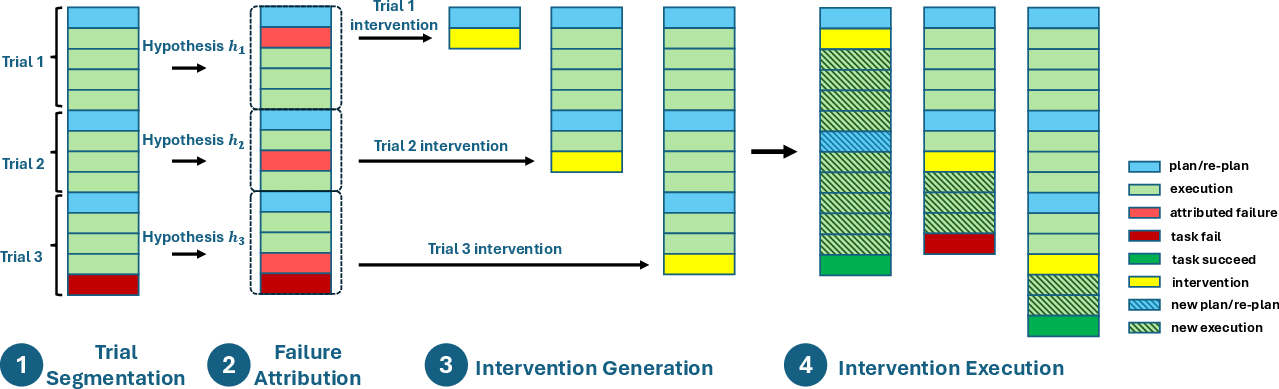
The researchers created DoVer, a four-step “do-then-verify” debugging process. Here’s how it works, using everyday analogies:
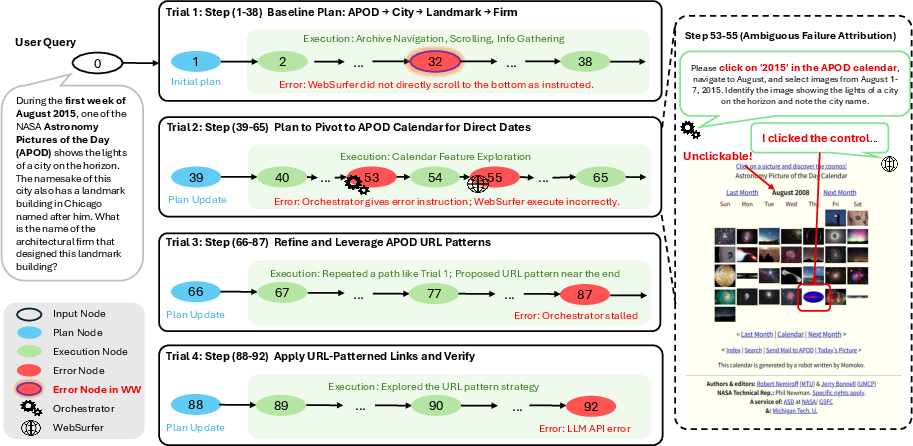
- Trial segmentation: Break a long conversation into smaller “trials,” each like a mini attempt with a plan and actions. This makes it easier to see one chain of cause and effect at a time.
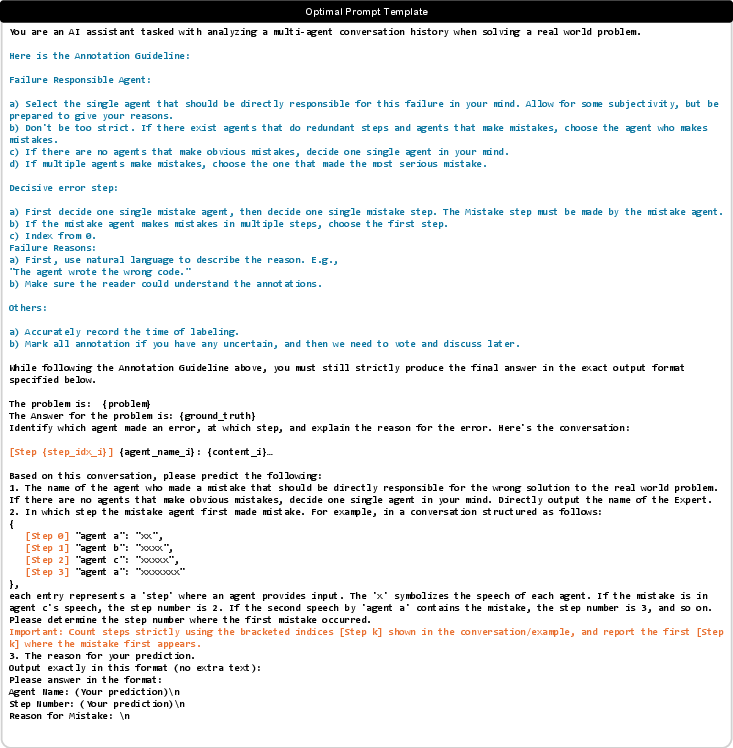
- Hypothesis generation: For each trial, the system guesses where and who caused the problem, and explains why. This is like saying, “We think the mistake happened here because…”
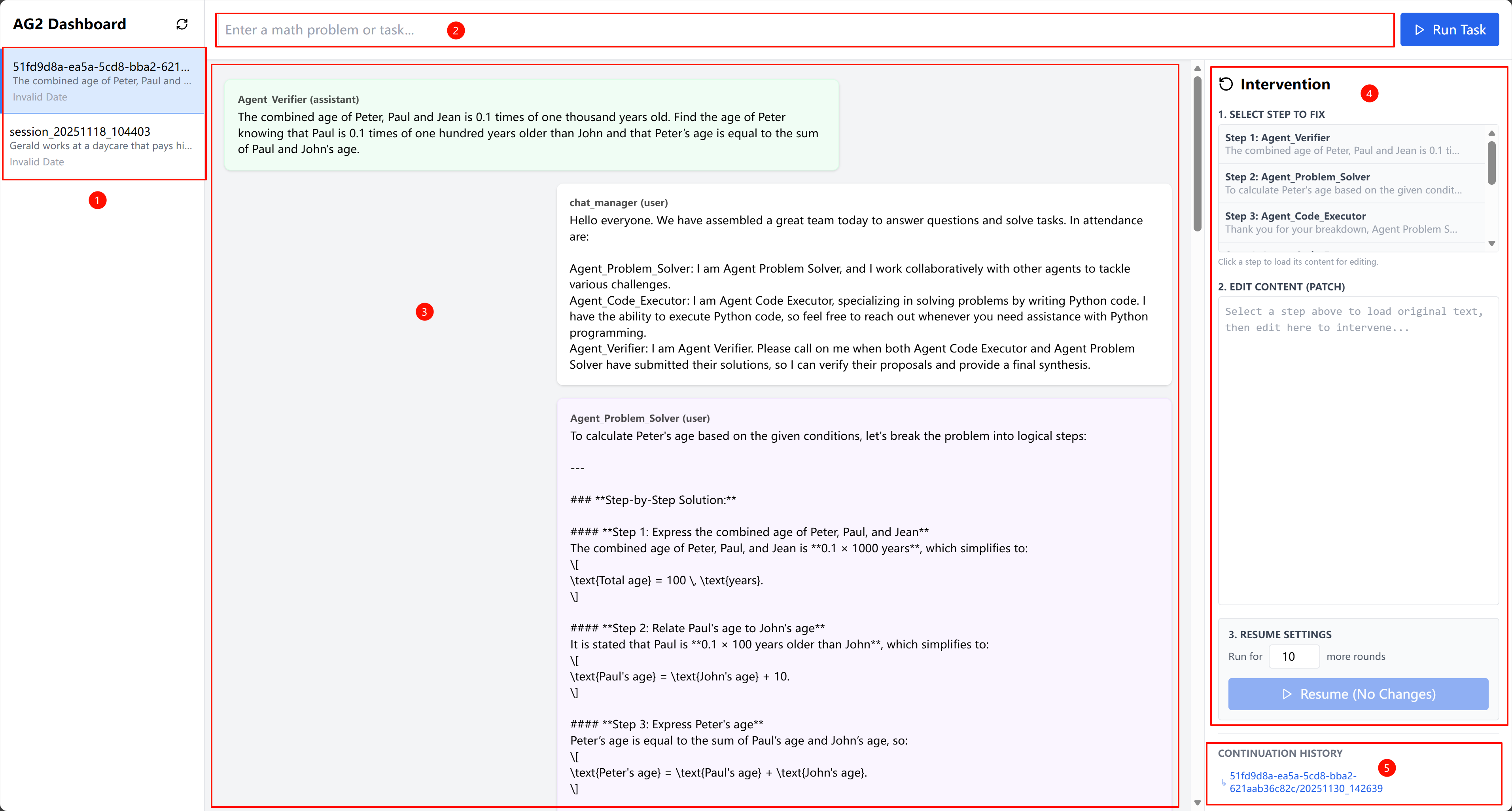
- Intervention generation: Turn that guess into a concrete fix. For example, the “coach” (orchestrator agent) might rewrite instructions to teammates (sub-agents) or adjust the high-level plan. These are small edits, like telling a browser agent to click the right button or to search differently.
- Intervention execution: Replay from the edited point to see if the change helps. This is the “proof” step: run the new version and measure the outcome.
To measure results, they looked at:
- Trial Success Rate: How often the fix turned a failed attempt into a success.
- Progress Made: Even if it didn’t fully succeed, did the edit move closer to the solution (like reaching key milestones)?
- Hypothesis validation: Did the fix confirm the original guess (validated), partly help (partially validated), clearly not help (refuted), or was it unclear because tools couldn’t follow the edit (inconclusive)?
They tested DoVer on several datasets and systems, including web tasks (GAIA and AssistantBench) and math problems (GSMPlus), and tried different LLMs (both proprietary and open-source).
What did they find?
The main results show that interventions help in a real, measurable way:
- On web task datasets (GAIA and AssistantBench) using one agent framework (Magnetic-One), DoVer turned 18–28% of failed trials into successes and achieved up to 16% milestone progress.
- On math problems (GSMPlus) using a different agent framework (AutoGen2/AG2), DoVer recovered 49% of failed trials.
- DoVer could validate or refute 30–60% of the “what went wrong” guesses. This reduces guesswork by testing ideas directly.
- It worked with open-source models too (not just top proprietary ones), and simple prompt improvements (few-shot examples) helped smaller models perform better.
- Methods that only critique the final answer (without editing earlier steps) did not flip failures to successes. Targeted, in-context fixes were key.
They also found that sometimes failures come from missing abilities in sub-agents (like not having a “scroll-to-bottom” action in a web browser agent). DoVer helped reveal these gaps so developers could add the missing tools, after which the same interventions started to work.
Why does it matter?
LLM-based multi-agent systems are complex—many messages, roles, and plans—and it’s hard to blame one exact step or agent when things go wrong. This paper shows:
- Debugging should focus on fixing outcomes, not just assigning blame.
- Trying out small, precise edits and checking if they help is more reliable than only reading logs.
- DoVer makes these systems more dependable and helps engineers quickly identify real weaknesses (like missing actions or unclear instructions).
Final thoughts and impact
DoVer is a practical way to make AI teams more robust:
- It scales better than manual log-reading because it automates both the “guess” and the “try-a-fix” steps.
- It works across different tasks and frameworks.
- It encourages an outcome-first mindset: if a change helps, it’s a good fix, regardless of who “caused” the failure.
In the future, this approach could enable self-improving AI systems that:
- Automatically test multiple fixes,
- Learn which interventions work,
- And suggest or implement new tools when current ones are too limited.
This moves AI teams closer to being reliable problem-solvers in the real world, especially for complex, multi-step tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper advances intervention-driven debugging for LLM multi-agent systems, but several important aspects remain underexplored or unresolved. Future work could address the following gaps:
- Generalization across architectures: DoVer is tested on two centrally orchestrated, synchronous frameworks (M1 and AG2). It remains unclear how to adapt and evaluate DoVer for decentralized, asynchronous, event-driven, or black-box orchestrators without explicit checkpoints or deterministic replay.
- Instrumentation requirements: The approach presupposes rich logs and checkpoint/replay interfaces. Methods to add lightweight, portable instrumentation (or higher-level abstractions over interaction histories) for systems lacking these facilities are not developed.
- Sub-agent capability interventions: DoVer restricts interventions to orchestrator-level message edits; it does not directly modify sub-agent code, tools, or skills. A systematic framework for automatic capability augmentation (e.g., synthesizing new tools, extending action primitives, or skill learning) is missing.
- Intervention fidelity guarantees: Many outcomes are “Inconclusive” because agents fail to execute the intended intervention. Techniques to enforce or verify intervention compliance at the tool/action level (e.g., action constraints, tool wrappers, controllable APIs) are not provided.
- Progress measurement without human steps: The milestone-based progress metric relies on human-annotated solution steps (available in GAIA). A general, robust, domain-agnostic progress metric that works without human annotations (and reduces reliance on LLM-as-a-judge) is left for future work.
- LLM-as-a-judge reliability: Judgments of progress and “intervention fulfilled” may be biased. Calibration protocols, inter-judge agreement analyses, cross-model adjudication, or human-grounded validation to mitigate judge bias are not explored.
- Statistical rigor: The evaluation uses three independent runs to tame stochasticity but lacks confidence intervals, variance analyses, or statistical significance testing to quantify reliability of success and progress estimates.
- Cost and scalability: Token/compute costs, latency impacts, and throughput under large-scale or production constraints are not measured. Strategies for cost-aware intervention selection, early stopping, or budgeted debugging are absent.
- Trial selection and prioritization: The system intervenes on each segmented trial. Methods to prioritize trials or hypotheses (e.g., value-of-information, causal salience, expected repair gain) to reduce costs and focus on high-yield interventions are not studied.
- Multi-point and sequential interventions: While multi-step edits are supported, there is no algorithmic framework for coordinated, multi-point intervention planning (e.g., searching minimal repair sets, sequential intervention policies, or compounding effects across trials).
- Minimality and causal validity: “Decisive error” and “minimal intervention” are used operationally but not formalized. A causal framework to identify sufficient causes, measure intervention minimality, and reason about confounders (LLM stochasticity, environment dynamics) is needed.
- Robust replay in dynamic environments: External environments (e.g., web pages) can change between runs. Mechanisms for state capture, environment virtualization, or controlled replays that ensure counterfactual validity are not detailed.
- Comparative baselines: The paper compares to Self-Refine and CRITIC but does not benchmark against recent intervention-driven or causal-attribution methods (e.g., RAFFLES, Abduct–Act–Predict, spectrum- or graph-based attributions). Head-to-head comparisons would clarify relative advantages.
- Component ablations: There is no systematic ablation of trial segmentation accuracy, attribution prompt variants, intervention-generation strategies, or judge prompts to quantify each component’s contribution and sensitivity.
- Domain breadth: Evaluations cover web-based information seeking and math problem solving. Open questions remain for domains like code agents, robotics/embodied tasks, multimodal agents, long-running workflows, and safety-critical applications.
- Safety and risk management: Interventions might trigger unintended tool actions or side effects. Policies for safe intervention (e.g., sandboxing, dry-run validation, guardrails, rollback protocols) are not addressed.
- Handling asynchronous/multi-threaded traces: The framework explicitly excludes asynchronous logs. Methods for segmenting and debugging overlapping or concurrent agent threads remain open.
- Learning-based intervention generation: Interventions are generated via prompting. Training specialized models (supervised or RL) for intervention proposal, selection, and sequencing—possibly using data from validated/refuted cases—is not explored.
- Judge-model independence: The system mixes GPT-4o for generation and GPT-5 for judging. The impact of judge–actor dependence and the benefits of independent, ensemble, or audited judges are not evaluated.
- Threshold choices: The 20% progress threshold for partial validation is heuristic. Sensitivity analyses or principled thresholding (e.g., utility-weighted criteria) are missing.
- Data release for reproducibility: While code is promised, a curated dataset of traces, hypotheses, interventions, and outcomes (including “intervention fulfilled” labels and milestone annotations) is not provided to enable community benchmarking.
- Automated sub-agent improvement loop: The paper demonstrates manual tool enhancements (e.g., scroll-to-bottom, PDF handling) after DoVer diagnostics. A fully automated loop—translating diagnostics into code/tool changes via software agents—remains an open design challenge.
- Cross-lingual and multilingual settings: All tasks are in English. The behavior of DoVer in multilingual logs, cross-lingual agent coordination, and non-English environments is untested.
- Attribution vs responsibility: DoVer emphasizes outcome-oriented repair rather than normative responsibility. Integrating causal responsibility or credit assignment in multi-agent coordination (especially under misalignment) is an open question.
Practical Applications
Immediate Applications
Below are practical, deployable use cases that build directly on DoVer’s intervention-driven debugging, trial segmentation, and checkpoint/replay methodology. Each item notes target sectors, likely product/workflow shapes, and key dependencies that affect feasibility.
- Automatic triage and repair of failing agent runs in CI/CD for AI agents (software, MLOps, AIOps)
- What: Add a DoVer stage to CI that segments failed multi-agent traces into trials, proposes hypotheses, injects minimal plan/instruction edits, replays from checkpoints, and reports flip/progress metrics.
- Product/workflow: “Agent CI” job with Trial Segmenter, Hypothesis Generator, Intervention Generator, Replay Orchestrator, and a Milestone-based progress report. Gate releases on recovery rate or progress.
- Dependencies/assumptions: Requires agent frameworks with checkpoint/replay APIs and message-level editability (e.g., LangGraph, AutoGen2, Magentic-One). LLM budget for multi-run replay; reliable logging; non-sensitive test data or privacy controls.
- Agent reliability dashboards in observability platforms (software tooling/DevTools)
- What: Track Trial Success Rate, milestone progress, and hypothesis validation/refutation over time to quantify reliability improvements.
- Product/workflow: Integrate with LangSmith/W&B-like dashboards; expose “flip rate,” “inconclusive rate,” and “tool-gap detections.”
- Dependencies/assumptions: LLM-as-a-judge modules for milestone extraction/verification; consistent tagging of plans and agents; access to logs and outcomes.
- Automated root-cause queue for human debuggers (software, enterprise ops)
- What: Convert failed runs into a ranked queue of validated/partially validated hypotheses, with replayable checkpoints and edit diffs.
- Product/workflow: “Agent Postmortem Queue” where engineers click to replay from the intervention step, see outcome deltas, and accept fixes.
- Dependencies/assumptions: Checkpointing, deterministic or multi-run statistics to smooth stochasticity; secure PII handling for production logs.
- Detecting and prioritizing tool gaps in sub-agents (software, RPA, web automation)
- What: Inconclusive cases (faithful interventions not executed) are flagged as capability gaps (e.g., missing “scroll-to-bottom”, PDF handling).
- Product/workflow: “Tool Backlog Generator” that clusters inconclusive trials by missing capability and creates tickets/specs for tool additions.
- Dependencies/assumptions: Clear taxonomy of interventions; ability to inspect tool call failures; stakeholder loop to implement tools.
- Self-correcting customer support agents and task bots by in-situ plan edits (customer service, e-commerce, enterprise assistants)
- What: On failure signals (thumbs-down), automatically try trial-level plan/instruction edits and re-execute to recover session.
- Product/workflow: Runtime “Do-then-Verify Retry” that preserves pre-failure context and branches new trial attempts.
- Dependencies/assumptions: Cost/latency budgets for alternate runs; safe rollback mechanisms; strong guardrails to avoid unsafe tool use.
- Classroom and research benchmarking for agent debugging (education, academia)
- What: Use DoVer to teach causal debugging of multi-agent traces and to create reproducible homework/exams with replayable failures and interventions.
- Product/workflow: Courseware bundles with traces, checkpoints, and standard prompts/scripts for trial segmentation and hypothesis validation.
- Dependencies/assumptions: Access to supporting agent frameworks and compute; institutional policies for LLM use.
- Safer release gates via outcome-oriented evaluation (policy/compliance inside organizations)
- What: Replace ambiguous log-only attribution with do-then-verify evidence of repairs before deployment of assistants that operate on customer data or external tools.
- Product/workflow: Internal governance checklist requiring intervention-validated fixes and milestone progress reports.
- Dependencies/assumptions: Audit logging, reproducible replays; privacy/legal review for replaying sensitive workflows.
- Math tutoring or study assistants that retry with targeted edits (daily life, education software)
- What: For incorrect steps in math tutoring chats, segment the reasoning into trials, intervene on the faulty step, replay, and present corrected path.
- Product/workflow: “Explain and correct” mode that shows the intervention and side-by-side improved reasoning.
- Dependencies/assumptions: Reasoning traces and checkpointing in the tutoring agent; tolerance for extra latency/cost during correction.
- Agent A/B tests for plan strategies (software/product analytics)
- What: Compare plan variants created by DoVer interventions within the same context to identify robust strategies without re-running from scratch.
- Product/workflow: A/B harness tied to replay checkpoints; outcome metrics include success and milestone delta.
- Dependencies/assumptions: Deterministic state restore; consistent tool environments; statistical logging.
- Data generation for fine-tuning failure tracers and judges (academia, software)
- What: Use validated/refuted hypotheses and outcome deltas to create high-quality supervised data for training specialized failure attribution models.
- Product/workflow: “Intervention-to-label” pipeline feeding new models for attribution and progress judgment.
- Dependencies/assumptions: License to store/share logs; quality control over LLM-judged labels.
Long-Term Applications
These opportunities require additional research, scaling, or platform evolution (e.g., richer tool APIs, automated code synthesis, standardized observability).
- Automated sub-agent capability repair via code synthesis (software, RPA, robotics)
- What: When DoVer flags a capability gap (e.g., missing action), automatically generate or patch tools/code and re-test within the loop.
- Product/workflow: “Auto Toolsmith” that converts inconclusive cases into tool specs, generates code, runs tests, and validates with DoVer.
- Dependencies/assumptions: Safe code execution sandboxes; permissions and CI pipelines for deploying new tools; robust unit/integration tests.
- Standardized checkpoint/replay and intervention APIs across agent frameworks (software ecosystem)
- What: Vendor-neutral APIs for trial segmentation, state capture, and in-place message edits to enable DoVer-like debugging anywhere.
- Product/workflow: Open standard or SDK (“Agent Replay API”) adopted by LangGraph, AutoGen, smolagents, etc.
- Dependencies/assumptions: Community alignment; updates to existing frameworks; backward compatibility.
- Real-time closed-loop debugging in production (enterprise apps, operations)
- What: Agents detect imminent failure, generate micro-interventions on the fly, and branch/retry without user-visible failure.
- Product/workflow: Streaming “just-in-time” DoVer with budget-aware retry policies and progressive milestones as stop conditions.
- Dependencies/assumptions: Strong latency controls; safety policies; reliable online state restore; cost-aware orchestration.
- Causal evaluation and formal assurance for agentic systems (safety-critical sectors: healthcare, finance, autonomy)
- What: Use intervention outcomes as empirical causal evidence for risk models and move toward formal guarantees on specific workflows.
- Product/workflow: Audit trails that tie claims (e.g., “this step is decisive”) to validated counterfactual runs; formal verification pilots in bounded domains.
- Dependencies/assumptions: Domain-specific guardrails; curated scenarios; regulator engagement; robust trace semantics.
- Cross-agent coordination optimization and accountability (multi-team enterprise agents)
- What: Learn patterns where orchestrator/sub-agent misalignment arises and auto-rewrite coordination protocols or role prompts.
- Product/workflow: “Coordination Optimizer” that proposes handshake patterns, capability declarations, and role contracts based on DoVer logs.
- Dependencies/assumptions: Stable organizational agent roles; access to many traces; change management for prompt/role updates.
- Intervention-aware training of agent models (academia, foundation model R&D)
- What: Train LLMs to propose and execute high-quality interventions and to judge progress robustly, reducing reliance on frontier models.
- Product/workflow: Datasets from validated interventions; finetuned “Fixer LLMs” and “Judge LLMs”; benchmarks with multi-trial ground truth.
- Dependencies/assumptions: Large, diverse training corpora; evaluation protocols beyond LLM-as-judge; compute resources.
- Application to asynchronous, distributed, or long-horizon agents (robotics, logistics, energy/grid ops)
- What: Extend trial segmentation and replay to event-driven/asynchronous settings (e.g., multi-robot teams), enabling intervention-based debugging.
- Product/workflow: Event-sourced state capture; temporal trial segmentation; simulator-in-the-loop counterfactuals.
- Dependencies/assumptions: High-fidelity simulators; consistent clock/state snapshots; stronger engineering of replay infrastructure.
- Regulatory reporting and third-party audits of AI agents (policy, compliance)
- What: Require do-then-verify evidence for safety/risk attestations; standardize “intervention-validated root cause” reports.
- Product/workflow: Compliance templates and APIs to export intervention logs, progress metrics, and flip rates for external auditors.
- Dependencies/assumptions: Legal frameworks recognizing counterfactual testing; privacy-preserving logging; industry standards.
- Personalized assistants that learn preferred recovery strategies (daily life, consumer AI)
- What: Over time, assistants remember which interventions reliably fix a user’s repeated failure patterns and apply them proactively.
- Product/workflow: Personal “repair memory” keyed by task archetypes and tools; opt-in user profiles for recovery preferences.
- Dependencies/assumptions: On-device or private storage of traces; user consent; efficient local models or edge inference.
- Multi-modal and cross-domain debugging (healthcare clinical assistants, scientific workflows)
- What: Extend interventions to data modalities (e.g., images, PDFs, EHR snippets) and to domain-specific toolchains; debug end-to-end pipelines.
- Product/workflow: Domain packs that include milestone templates, tool adapters (e.g., PDF parsers, medical ontologies), and replay harnesses.
- Dependencies/assumptions: Domain data access/compliance (HIPAA, GDPR); expert-defined milestones; validated tool adapters.
In all cases, DoVer’s core dependencies—rich logging, checkpoint/replay capability, and the ability to edit and re-run from specific steps—are pivotal. Effectiveness also depends on model quality, prompt design, tool availability, and cost/latency budgets. Where LLM-as-a-judge is used for progress scoring, organizations should consider human spot-checks or alternative evaluators to mitigate bias.
Glossary
- abduct–act–predict: A reasoning scaffold that combines abduction with action and prediction to attribute failures via counterfactuals; "abductâactâpredict counterfactual scaffolding~\cite{westAbductActPredict2025}"
- Aegis: A specialized failure-tracer model trained on success/failure trajectories to analyze agent errors; "specialized failure-tracer models trained on curated success/failure trajectories~\cite{AgentTracer, Aegis}"
- AgentDebug: An intervention-driven system for debugging LLM agents through edits and replays; "The recent AgentDebug~\cite{zhuWhereLLMAgents2025} work employs an intervention-driven methodology similar to DoVer, although it does not place particular emphasis on multi-agent settings."
- AGDebugger: A human-in-the-loop debugging tool that supports rewinding, editing, and re-executing agent traces; "Human-in-the-loop tools such as AGDebugger~\cite{AGDebuger} enable rewind/edit/re-execute with trace visualization,"
- AgentEval: An evaluation framework that moves beyond binary pass/fail to assess progress via requirements or utility; "evaluation frameworks~\cite{DevAI,AgentEval} argue that end-to-end pass/fail is too coarse and introduce requirement graphs or task-utility criteria that reveal where progress stalls."
- AgentIssue-Bench: A benchmark packaging real agent-system issues into executable failing tests for repair evaluation; "package real agent-system issues into executable environments with failing tests (AgentIssue-Bench) and find low resolution rates for current software engineering agents,"
- AgentTracer: A learned failure-tracer model that diagnoses where agent trajectories go wrong; "specialized failure-tracer models trained on curated success/failure trajectories~\cite{AgentTracer, Aegis}"
- All-at-Once prompt: A single LLM call over the full session log used for attribution; "adopting the All-at-Once prompt (a single LLM call over the full session log)"
- AssistantBench: A benchmark dataset of assistant tasks used to evaluate multi-agent systems; "on the datasets derived from GAIA and AssistantBench,"
- AutoGen2 (AG2): A multi-agent framework enabling conversation-based agent orchestration; "we further construct a MathChat multi-agent system using a second framework, AutoGen2 (AG2)~\cite{autogen02, wu2023mathchat}."
- black-box orchestrators: Agent controllers whose internal state and interfaces are hidden, complicating instrumentation; "asynchronous or black-box orchestrators"
- causal-inference formulations: Approaches that frame failure attribution using causal reasoning methods; "causal-inference formulations~\cite{maAutomaticFailureAttribution2025}"
- checkpoint/replay interface: A runtime capability to save and reload state for targeted re-execution; "must expose sufficiently rich interaction logs and a checkpoint/replay interface"
- counterfactual trace: A re-executed trajectory after an intervention to test a hypothesis; "yielding a counterfactual trace ."
- decisive error: The earliest step whose correction would make the trajectory succeed; "A failure step is defined as a decisive error: if one were to replace the agentâs incorrect action at that step with a correct one, the trajectory would subsequently succeed."
- DoVer: An intervention-driven debugging framework that validates attribution by editing and re-running; "we introduce DoVer, an intervention-driven debugging framework,"
- failure attribution: Identifying the agent/step responsible for causing the failure; "A parallel line of work seeks failure attribution: identifying the earliest decisive step or agent that is responsible for the earliest sufficient cause of failure"
- failure-flipping: Metrics and methods focused on turning failed trials into successes; "we introduce two failure-flipping related metrics: Trial Success Rate and Progress Made."
- few-shot examples: Small curated demonstrations added to prompts to guide model behavior; "adding three manually curated few-shot examples,"
- GAIA: A multi-level benchmark for information-seeking tasks used to evaluate agents; "on the datasets derived from GAIA and AssistantBench,"
- GSMPlus: A math problem dataset used to test agent frameworks and interventions; "a different dataset (GSMPlus) and agent framework (AG2), where it recovers 49\% of failed trials."
- ground-truth annotations: Human labels designating the correct failure agent/step, often uncertain; "log-based failure attribution is fundamentally limited by the uncertainty of ground-truth annotations."
- Inter-Agent Misalignment: Failure mode where agents’ instructions and actions are misaligned; "failures often stem from Inter-Agent Misalignment~\cite{MAST}."
- intervention-driven debugging: Debugging methodology that validates hypotheses through targeted edits and re-execution; "we introduce DoVer, an intervention-driven debugging framework,"
- is_intervention_fulfilled: A boolean indicator that the agent faithfully executed the intended intervention; "resulting in a boolean metric ``is_intervention_fulfilled'' for each trial run."
- LangGraph: A graph-based runtime offering checkpoints, interrupts, and branching for agent traces; "graph runtimes like LangGraph~\cite{langgraph-time-travel} provide checkpoints, interrupts, and ``time-travel'' branching."
- LLM-as-a-judge: Using an LLM to evaluate and compare execution traces; "compare execution traces before and after intervention with LLM-as-a-judge."
- LLM stochasticity: The randomness inherent in LLM outputs affecting repeatability; "To reduce the impact of execution randomness (e.g., LLM stochasticity), we perform three independent runs for each intervention."
- Magentic-One (M1): A popular LLM-based multi-agent framework used to collect and replay traces; "we begin by conducting experiments using Magentic-One (M1)~\cite{Magentic-One}, a popular LLM-based multi-agent framework"
- MathChat: A multi-agent system design for math problem solving; "we further construct a MathChat multi-agent system using a second framework, AutoGen2 (AG2)~\cite{autogen02, wu2023mathchat}."
- milestone achievement count: The number of key steps completed in a trace relative to a reference; "We then define the milestone achievement count for a trace as:"
- milestone progress: A measure of partial task advancement via milestones after intervention; "achieves up to 16\% milestone progress,"
- orchestrator: The central agent coordinating sub-agents by planning and issuing instructions; "ambiguity may arise in attributing responsibility between the orchestrator and its sub-agents."
- planning–execution cycles: Iterative loops where plans are made and executed, often repeatedly; "repeated planningâexecution cycles,"
- prompt refinements: Targeted changes to prompts that improve attribution accuracy; "two minimal, non-invasive prompt refinements that consistently improve accuracy:"
- Reflexion: A mechanism enabling agents’ self-reflection to improve subsequent steps; "have the self-reflection capabilities~\cite{React, Reflexion},"
- ReAct: An agent pattern that interleaves reasoning and actions during execution; "ReAct-style~\cite{React} loop."
- requirement graphs: Structured representations of task requirements to assess where progress stalls; "introduce requirement graphs or task-utility criteria that reveal where progress stalls."
- spectrum-based failure attribution: An attribution method inspired by spectrum-based fault localization; "spectrum-based failure attribution approach~\cite{geWhoIntroducingFailure2025},"
- state restore and replay: Restoring saved state to re-execute from a chosen step; "stateful information that is necessary for state restore and replay."
- sub-agent: A specialized agent operating under an orchestrator’s guidance; "ambiguity may arise in attributing responsibility between the orchestrator and its sub-agents."
- time-travel branching: Runtime support to branch and explore alternative executions in traces; "``time-travel'' branching."
- TRAIL: A framework that builds turn-level traces with a reasoning/planning/execution taxonomy; "TRAIL~\cite{TRAIL} creates turn-level traces and a fine-grained taxonomy (reasoning, planning, execution),"
- trajectory-aware evaluation: Assessment that considers entire execution trajectories rather than only final outcomes; "is consistent with trajectory-aware evaluation advocated in~\cite{AgentEval,TRAIL}."
- trial segmentation: Splitting long logs into trials using re-plan steps to localize interventions; "Trial segmentation: split the failed session log into trials using re-plan steps as cut points."
- Trial Success Rate: The share of intervened trial runs that complete the task successfully; "The Trial Success Rate is defined as the ratio of trial runs that successfully complete the task after intervention."
- turn-level traces: Logs organized by conversational turns to analyze fine-grained agent behavior; "TRAIL~\cite{TRAIL} creates turn-level traces"
- Who{paper_content}When (WW): A dataset for step/agent failure attribution from multi-agent logs; "the Who{paper_content}When (WW) dataset was introduced in~\cite{whoandwhen}."
- WW-HC: The Hand Crafted subset of the WW dataset used in evaluations; "on the Hand Crafted category of WW (WW-HC) with the setting of including ground-truth answers and adopting the All-at-Once prompt"
Collections
Sign up for free to add this paper to one or more collections.