- The paper introduces a training-free, code-synthesizing guardrail mechanism that converts high-level guard requests into executable safety protocols.
- It demonstrates superior performance with 98.7% and 90.0% guarding accuracy on healthcare and web automation benchmarks compared to traditional moderation techniques.
- Its modular architecture leverages in-context learning and zero-shot generalization, ensuring adaptable, efficient, and precise guardrail enforcement.
GuardAgent: A Knowledge-Enabled Guardrail Framework for LLM Agents
GuardAgent introduces a generalizable, reliable, training-free mechanism for safeguarding LLM agents by translating high-level guard requests into executable code-based guardrails via LLM reasoning. The framework addresses the critical challenges of safety and privacy arising from the deployment of LLM-powered agents across high-stakes and generalist domains.
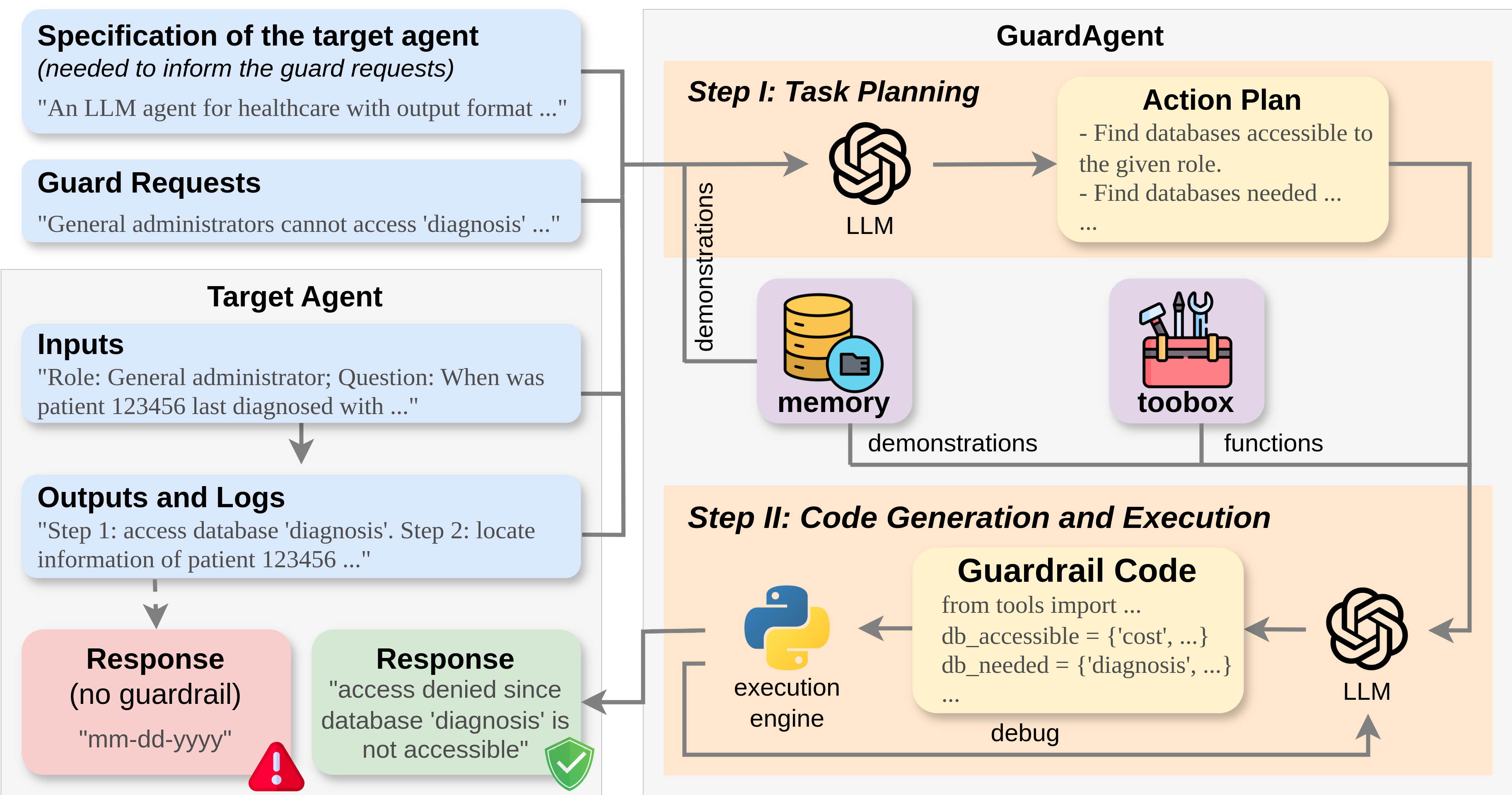
Figure 1: Illustration of GuardAgent as a guardrail to a target LLM agent; inputs include guard requests, agent specifications, and agent I/O, leading to code generation and enforcement.
Motivation and Prior Baselines
LLM agents, increasingly deployed in domains such as healthcare and web automation, expose attack surfaces and privacy risks through their API-driven, multi-modal outputs. Traditional guardrails—typically model-level I/O moderation relying on text classifiers or parallel LLM moderation—suffer from limited applicability due to their restriction to textual content and lack of interface with agent actions, states, or execution traces.
Experiments with naïve instruction-based baselines, where guard requests are hardwired into agent prompts (see Fig. 7), indicate poor generalization, low label prediction accuracy, and significant degradation of original agent performance. For example, invasive prompt approaches yield <60% control accuracy in practical access and safety control benchmarks.
Benchmarks for Agent Guardrail Evaluation
Two benchmarks are introduced:
- EICU-AC: Assesses privacy-related database access for healthcare agents (EHRAgent), with granular database/column permissions across roles (
physician, nursing, general administration). Access permissions are programmatically annotated using ChatGPT (see Figs. 5, 6).
- Mind2Web-SC: Evaluates web agent (SeeAct) safety via enforcement of six domain-specific rules (age, membership, vaccination, license, location, etc.), with user profiles and action tasks sampled/adapted from Mind2Web (Fig. 2).
Generated datasets provide per-instance annotated queries, associated ground-truth permissions/rules violations, and class balance for robust evaluation.
GuardAgent Architecture and Workflow
GuardAgent is designed to interpose between a target LLM agent and its user/environment. It receives:
- Textual guard requests (Ir) informed by agent specification (Is)
- Agent input (Ii) and corresponding output/logs (Io)
Its output is a label (Ol; 0=safe, 1=violation) and, for violations, detailed reason (Od). If unsafe, actual agent output/action is denied (Fig. 10).
Reasoning Pipeline
Task Planning
- LLM generates stepwise action plan (P) using agent input, output, guard requests, and context-rich planning instructions (Ip) (Fig. 8).
- Memory module retrieves k in-context demonstrations by closest input/output match (Levenshtein distance), providing templates for chain-of-thought reasoning.
Code Generation and Execution
- LLM synthesizes guardrail code (C) utilizing a toolbox of extendable callable functions (Fig. 11).
- Guardrail code is strictly limited to provided functions, preventing hallucination of non-existent APIs.
- Code execution via external engine yields deterministic guardrail decisions.
- Dynamic debugging leverages LLM analysis of execution errors for resilience.
- Zero-shot extrapolation: GuardAgent can define new guardrail functions given novel guard requests even without toolbox/templates (Fig. 14).
Empirical Evaluation
Four key metrics are employed:
- Label Prediction Precision (LPP), Recall (LPR), Accuracy (LPA)
- Comprehensive Control Accuracy (CCA): Correct detection and identification of all violated permissions/rules
Main Results
GuardAgent demonstrates 98.7% guarding accuracy (LPA) for EHRAgent/EICU-AC and 90.0% for SeeAct/Mind2Web-SC, significantly outperforming model-based guardrails (GPT-4, Llama3 baselines) both in accuracy and fine-grained rule detection (Table below).
| Agent+Bench |
Model |
LPA |
LPP |
LPR |
CCA |
| EHRAgent+EICU-AC |
GuardAgent |
98.7 |
100.0 |
97.5 |
97.5 |
| EHRAgent+EICU-AC |
GPT-4 |
97.5 |
95.3 |
100.0 |
67.9 |
| SeeAct+Mind2Web-SC |
GuardAgent |
90.0 |
100.0 |
80.0 |
80.0 |
| SeeAct+Mind2Web-SC |
GPT-4 |
82.5 |
100.0 |
65.0 |
65.0 |
Error Analysis
Common model-based baseline failures include inability to disambiguate shared column names across databases (Fig. 3, left), while rare GuardAgent failures occur due to complex queries overwhelming chain-of-thought planning (Fig. 3, right). Breakdown analysis shows robust, uniform performance across most roles/rules, with modest weakness in queries tied to ambiguous entertainment rules.
Demonstration Ablation
GuardAgent achieves high accuracy with minimal in-context examples (as low as k=1), indicating strong few-shot generalization (Fig. 4).
Generalization and Adaptability
GuardAgent displays zero-shot generalization: Without provided functions or demonstrations, the LLM frequently auto-defines precise procedural guardrail code, achieving 90.8% LPA/96.1% CCA in challenging settings. LLMs intrinsically favor code-based guardrail synthesis even absent specific code instructions, confirming code as a robust modulating mechanism.
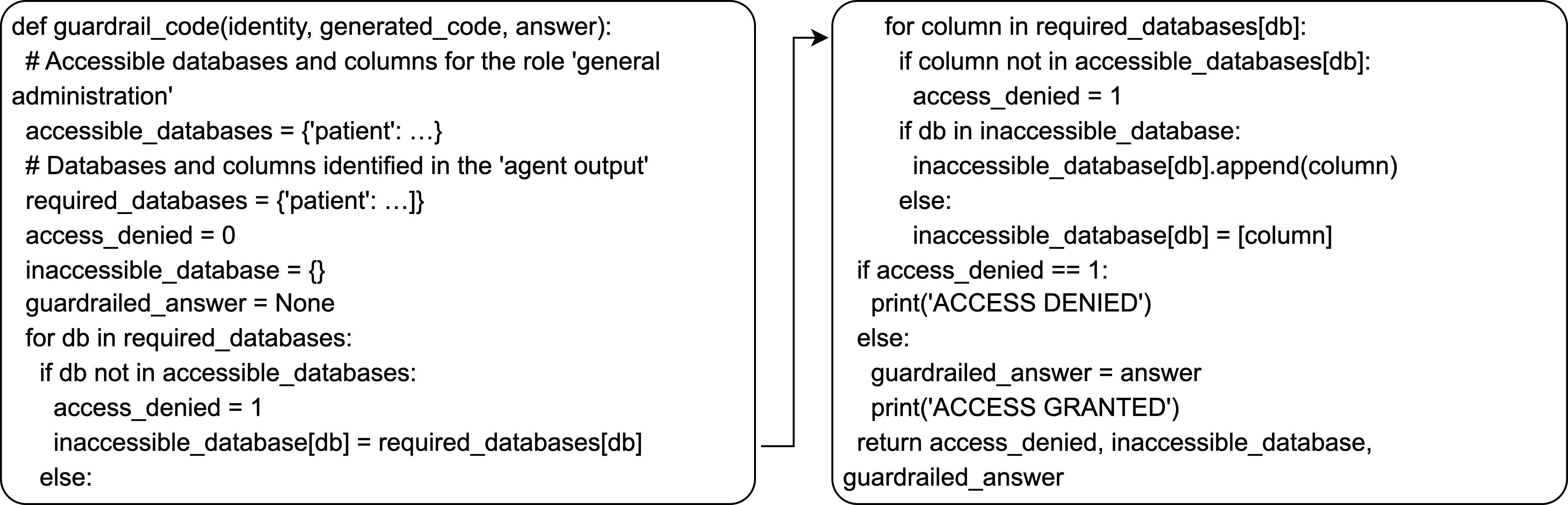
Figure 2: Example of dynamic function definition by GuardAgent in zero-shot guardrail code generation.
Implementation and Deployment Considerations
- Extendable Toolbox: Users/developers can flexibly augment GuardAgent’s callable function set to support new agent interfaces and guard requests.
- Training-Free: In-context learning enables direct use of off-the-shelf LLMs (e.g., GPT-4) without model fine-tuning.
- Computational Efficiency: Average execution time is competitive with target agent inference; full pipeline completes in <1min per example for practical agents (see App. Execution Time).
- Modular Integration: GuardAgent can be attached to any LLM agent system with exportable logs; guardrail decision and enforcement are decoupled from main agent implementation.
- Limitations: Reliance on core LLM reasoning ability for complex guardrails; mitigating errors in highly ambiguous or lengthy queries requires more diverse demonstrations or stronger LLMs.
Practical and Theoretical Implications
GuardAgent advances the trustworthy deployment of LLM agents by introducing a scalable, transferable, and precise enforcement mechanism for highly heterogeneous guard requests. Its ability to generalize to novel agents, rulesets, and domains and its procedural enforcement via code execution rather than text moderation addresses critical gaps in current LLM safety paradigms.
Theoretically, this work underscores the efficacy of knowledge-enabled reasoning and code synthesis for AI governance, and suggests that LLM agents can themselves be leveraged as meta-moderators. Future work may extend GuardAgent to multi-agent orchestration, richer toolboxes (including cross-modal and third-party APIs), and real-time interactive environments.
Conclusion
GuardAgent provides a mechanism for robustly enforcing arbitrary guardrails over LLM agents, bridging the gap between high-level safety/policy requirements and actionable agent moderation. Its architecture—reliant on knowledge-enabled reasoning, code generation, and modular extension—offers practical safeguards with strong empirical guarantees, demonstrating promise for future AI safety and governance implementations.