- The paper introduces a systematic error taxonomy (AgentErrorTaxonomy) to classify failure modes in planning, action, reflection, memory, and system modules.
- It presents the AgentDebug framework that pinpoints root-cause errors and provides iterative, actionable feedback to enhance LLM agent performance.
- Experimental results demonstrate up to a 26% improvement in task success rates across environments like ALFWorld, GAIA, and WebShop.
Where LLM Agents Fail and How They Can Learn From Failures
This paper focuses on the vulnerabilities of LLM agents in complex tasks and introduces a methodology to address these challenges. LLM agents have shown potential in integrating planning, memory, reflection, and tool-use modules to solve complex tasks. However, these sophisticated architectures are prone to cascading failures where a single error propagates through decision-making steps leading to task failure. This paper provides solutions through the introduction of the [AgentErrorTaxonomy](https://www.emergentmind.com/topics/agenterrortaxonomy), [AgentErrorBench](https://www.emergentmind.com/topics/agenterrorbench), and AgentDebug.
Introduction
LLM agents have become critical in diverse fields such as scientific discovery, web interaction, and research support. Despite their potential, they face robustness challenges, often making errors in reasoning, tool use, and instruction interpretation. Prior research has focused on qualitatively enumerating error types without systematic mechanisms to trace and fix these failures. This paper addresses this gap by offering a systematic approach to error diagnosis and correction.

Figure 1: Motivation for {AgentDebug: A single root-cause failure (b) can propagate through subsequent steps (c), compounding errors and leading to task failure. {AgentDebug (d) addresses this bottleneck by tracing failures back to their source and providing actionable feedback that enables agents to evolve into more robust versions.
AgentErrorTaxonomy and AgentErrorBench
AgentErrorTaxonomy
An extensive collection of failure modes is categorized into five main modules: Planning, Action, Reflection, Memory, and System. These modules help in pinpointing where errors occur and how they contribute to overall failure. Memory errors, like false recall, distort later reasoning; reflection failures block course adjustments; and planning errors often lead to logically unsound strategies.

Figure 2: Pipeline of proposed {AgentErrorTaxonomy and {AgentErrorBench. Failed trajectories are collected, analyzed to develop a taxonomy of errors, and then annotated with root causes and actionable feedback to form the benchmark.
AgentErrorBench
This is the first systematically annotated failure trajectory dataset derived from ALFWorld, GAIA, and WebShop environments. The benchmark facilitates the comparison and study of agent debugging methods by providing a structured testbed for error analysis.
AgentDebug Framework
AgentDebug serves as a debugging framework that identifies root-cause failures and provides corrective feedback, enabling LLM agents to recover and improve iteratively. It operates in three stages:
- Fine-Grained Analysis - Errors are categorized based on the AgentErrorTaxonomy.
- Critical Error Detection - Pinpoints the root-cause error that directly leads to task failure.
- Iterative Debugging - Provides feedback and allows the agent to iterate through the task again with corrections applied.
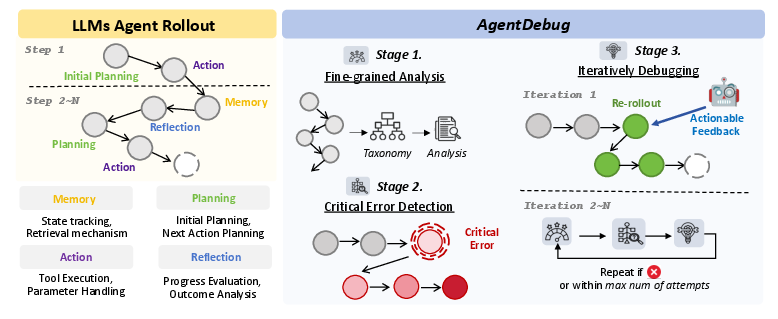
Figure 3: Overview of {AgentDebug. (Left) LLM agent rollouts alternate between memory, planning, reflection, and action. (Right) {AgentDebug debugs trajectories in three stages: (1) fine-grained analysis across steps and modules, (2) detection of the critical error that triggers failure, and (3) iterative re-rollouts with actionable feedback to turn failures into successes.
Experimental Results
Experiments demonstrate that AgentDebug achieves significantly higher accuracy in root-cause error detection and improves task success rates by up to 26% across ALFWorld, GAIA, and WebShop. The framework outperforms previous baselines by emphasizing root-cause errors rather than attempting to fix every surface-level issue.
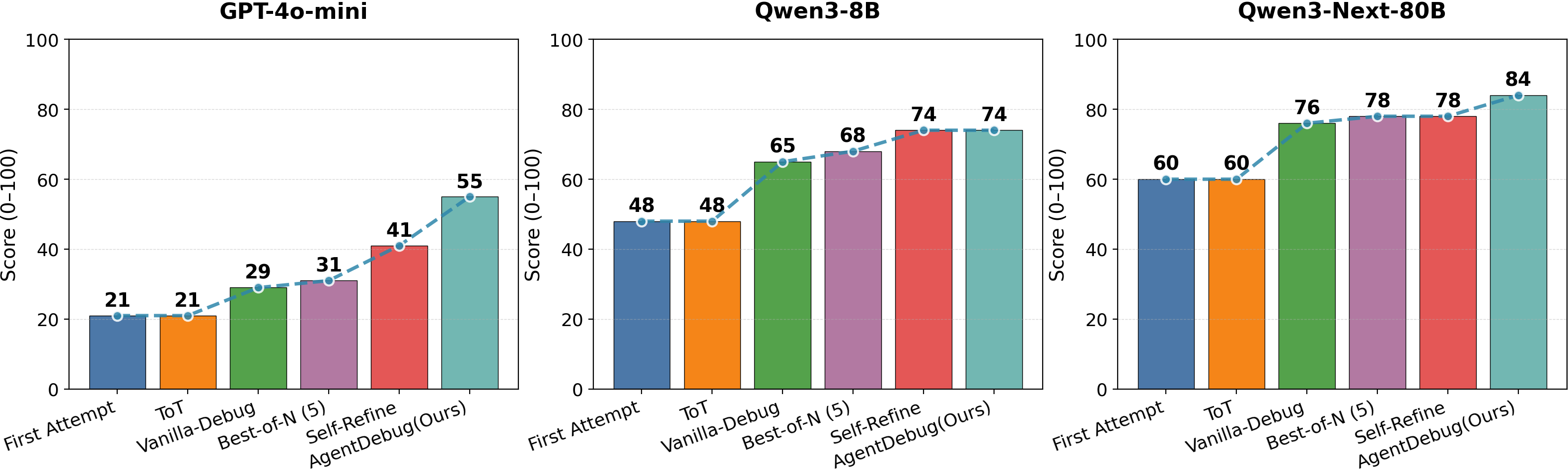
Figure 4: Downstream debugging performance on ALFWorld. Results are shown across three backbone models (GPT-4o-mini, Qwen3-8B, Qwen3-Next-80B) and different methods. {AgentDebug consistently outperforms strong baselines.
Conclusion
The proposed framework successfully addresses the challenge of cascading failures in LLM agents by providing a systematic approach to error identification and correction. This work paves the way for the development of more reliable and adaptive LLM agents by enabling them to learn and evolve from their failures, ultimately enhancing their robustness in real-world applications.

