SIMA 2: A Generalist Embodied Agent for Virtual Worlds
Abstract: We introduce SIMA 2, a generalist embodied agent that understands and acts in a wide variety of 3D virtual worlds. Built upon a Gemini foundation model, SIMA 2 represents a significant step toward active, goal-directed interaction within an embodied environment. Unlike prior work (e.g., SIMA 1) limited to simple language commands, SIMA 2 acts as an interactive partner, capable of reasoning about high-level goals, conversing with the user, and handling complex instructions given through language and images. Across a diverse portfolio of games, SIMA 2 substantially closes the gap with human performance and demonstrates robust generalization to previously unseen environments, all while retaining the base model's core reasoning capabilities. Furthermore, we demonstrate a capacity for open-ended self-improvement: by leveraging Gemini to generate tasks and provide rewards, SIMA 2 can autonomously learn new skills from scratch in a new environment. This work validates a path toward creating versatile and continuously learning agents for both virtual and, eventually, physical worlds.











Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces SIMA 2, a smart “agent” that can see, think, talk, and act inside many different 3D video games. It’s built on top of Google’s Gemini model, so it understands language and images, but SIMA 2 goes further: it uses that understanding to press keys and move the mouse like a human player. The goal is to move beyond chatbots that only talk, and create an active helper that can plan, follow complex instructions, learn new skills, and work across lots of virtual worlds.
Goals and Questions
The researchers wanted to know, in simple terms:
- Can one agent handle many different 3D games instead of just one?
- Can it understand complex instructions (even pictures or sketches) and explain its plan while it acts?
- Will it generalize to brand-new worlds it has never seen?
- Can it learn new skills by itself, without being told exactly what to do?
- Can it get close to human performance while still keeping strong reasoning abilities?
How SIMA 2 Works (Methods)
What is an “embodied agent”?
Imagine a friend sitting at a computer, looking at the game screen and using the keyboard and mouse to control a character. An “embodied agent” is like that friend: it doesn’t get secret game data. It only sees what’s on the screen and acts through the same controls a person would use. This makes its learning more realistic and more likely to transfer to other worlds (and eventually, real robots).
The agent’s interface
- Input: a stream of video frames from the game (like watching a live video at 720p).
- Output: a structured text format that gets turned into actual keyboard keys, mouse clicks, and mouse movements. It can also produce language for dialogue or “thinking out loud.”
- No cheats: it does not receive hidden game state. It acts only on what it can see and what the user tells it.
Training data (how it learns)
SIMA 2 is trained with a mix of gameplay data and regular Gemini pretraining (like language and image understanding) so it keeps strong reasoning and vision skills.
The gameplay data comes from:
- Human gameplay demonstrations:
- One-player, later-annotated runs: someone plays freely, then writes what they did afterward.
- Two-player “Setter–Solver” runs: one person gives live instructions (the Setter), and another controls the game (the Solver). This ties instructions directly to actions.
- Task-specific episodes: players start from a known game state and try to complete a particular instruction (like “Craft a stone axe”) within a time limit.
- Human ratings: judges watch videos and mark whether the task was completed successfully. These ratings help train and calibrate automatic reward checks.
Before training, the team cleans and filters the data, splits long recordings into shorter “spans” centered on single instructions, and sometimes uses Gemini to add helpful text labels.
Bridge data (linking thought, talk, and action)
Human gameplay rarely includes the agent’s inner thoughts or back-and-forth dialogue. To teach this, the team created “bridge” examples:
- They took high-quality gameplay clips and asked Gemini to add realistic, step-by-step internal reasoning (“thought bubbles”) and dialogue (“speech bubbles”) that match what’s on screen and what the agent does next.
- This teaches SIMA 2 how to connect high-level thinking and talking with low-level actions, so it can explain itself and adjust its behavior mid-task.
Reinforcement learning (practice with rewards)
After supervised training, SIMA 2 practices online with “verifiable tasks”:
- Each task has a starting point, a written instruction, and a check that can confirm success. Sometimes success is detected by reading on-screen text using OCR (a tool that reads words in images), sometimes by looking at pixel colors or specific actions.
- The agent tries, gets rewards when it succeeds or answers grounded questions correctly, and improves its policy.
- This practice phase uses the training environments (not the held-out, brand-new ones).
Environments (where it trains and tests)
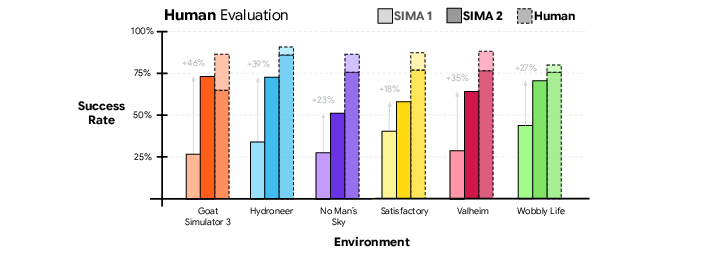
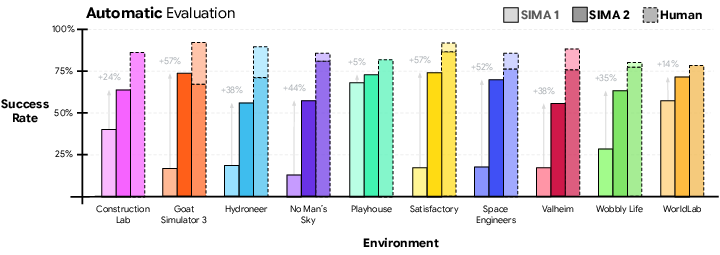
SIMA 2 learns in a mix of research worlds and popular open-world games (like No Man’s Sky, Valheim, Satisfactory, Space Engineers, and more). It’s tested on:
- Held-out games it hasn’t trained on (e.g., ASKA and Minecraft tasks from MineDojo).
- A story game (The Gunk).
- Photorealistic worlds created on-the-fly by Genie 3, a “world model” that can generate new environments from text prompts or images.
Main Findings
SIMA 2 shows a big jump in skill compared to the earlier SIMA 1:
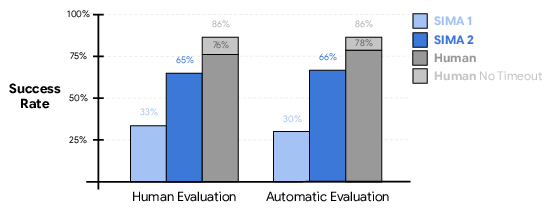
- Stronger performance: Across many embodied tasks, SIMA 2 roughly doubles the success rate of SIMA 1 and comes close to human-level performance. This holds for both automatically scored tasks and those judged by humans.
- Better generalization: It performs well in games it wasn’t trained on and even in realistic, newly generated worlds from Genie 3. That means it uses general world knowledge, not just memorized patterns.
- New capabilities that feel more “human”:
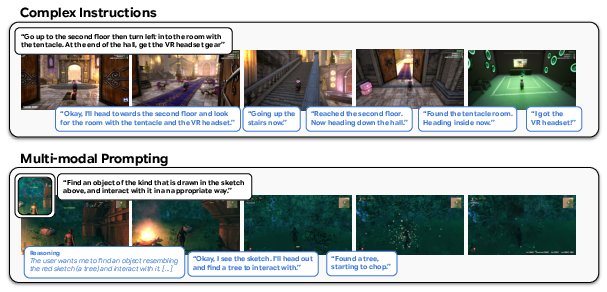
- Embodied dialogue: It can talk to you while acting. For example, if you ask it to check an object, it will walk over, read the on-screen info, and tell you what it found.
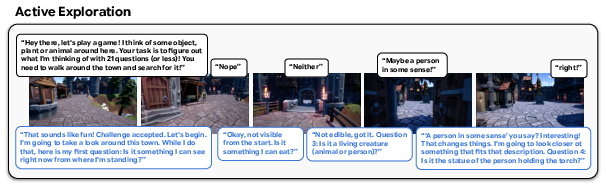
- Internal reasoning: It can think through indirect instructions, like “Go to the house colored like a ripe tomato,” and choose the right place (the red house).
- Complex instructions: It follows multi-step directions, can chain tasks, and even understands emojis or other languages (thanks to Gemini).
- Multi-modal prompting: You can include pictures or quick sketches to point out paths or objects, and it will use those to act appropriately.
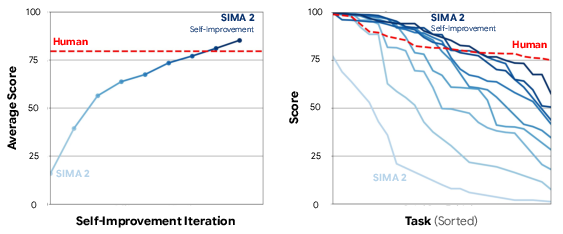
- Self-improvement: Using Gemini to suggest tasks and reward rules, SIMA 2 can teach itself new skills from scratch in a new environment. This shows a path to open-ended learning, where the agent keeps getting better without needing constant human labels.
Why It Matters (Implications)
This work suggests a clear path toward general-purpose agents that aren’t just smart in conversation but also capable in action:
- From passive AI to active partners: SIMA 2 doesn’t just describe what to do—it does it, explains its plan, and adapts as it goes.
- Safer, scalable training: Complex video games and generated worlds serve as rich, diverse practice grounds, building “spatial” and motor skills in a controlled setting.
- Toward robotics: Skills learned in virtual worlds—seeing, planning, acting, and improving—could transfer to physical tasks, making future robots more capable and easier to instruct.
- Open-ended learning: Combining agents like SIMA 2 with world models like Genie hints at infinite training spaces where agents can learn forever, inventing new tasks and mastering them over time.
In short, SIMA 2 brings us closer to AI that can understand, communicate, and take meaningful action in the world—first in virtual spaces, and eventually in the real one.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves several aspects missing, uncertain, or unexplored. Below is a concise, concrete list of gaps that future work could address:
- Architecture transparency: Specify the exact SIMA 2 model architecture (Gemini Flash‑Lite variant), video tokenization, action token schema, how vision/language/action tokens are interleaved, sequence length/context window, and memory mechanisms used for long-horizon tasks.
- Structured action format: Publish the formal grammar for the “structured text output” mapped to keyboard/mouse; detail ambiguity resolution, error handling, and parser robustness to malformed outputs and near-boundary cases.
- Interface constraints: Quantify the impact of 720p input, frame rate, and discretized mouse movements on fine-motor tasks (aiming, menu precision, six‑DOF flight); evaluate whether continuous mouse control or higher-frequency action emission improves performance.
- Real-time performance: Report end-to-end latency, achievable FPS, compute footprint, and hardware requirements; analyze the relationship between latency and task success.
- Training data composition: Provide quantitative breakdowns and ablations of human gameplay vs Gemini pretraining vs synthetic bridge data; measure sensitivity to mixture ratios and their effects on action quality, dialogue, and reasoning.
- Bridge data validity: Assess the causal consistency of Gemini-generated reasoning/dialogue with visual frames and actions; estimate hallucination rates; compare to human-authored reasoning; ablate bridge data to isolate its contribution.
- RL effects and overfitting: Perform ablations of SFT-only vs SFT+RL; quantify which skills improve under RL, whether gains generalize to held-out environments, and the risk of overfitting to programmatically verifiable tasks.
- Reward verification scalability: Characterize false positive/negative rates of OCR- and pixel-heuristic-based verifiers across diverse UIs, fonts, languages, and lighting; develop automated, maintainable verifier construction methods for new games.
- Held-out generalization rigor: Provide full quantitative results for ASKA, MineDojo (per category and seed), The Gunk, and Genie 3; include confidence intervals, task definitions, and standardized seeds to ensure reproducibility.
- Photorealistic generalization: Establish standardized, reproducible task suites in Genie 3 photorealistic scenes; audit for training-data leakage; analyze failure modes unique to generative artifacts and domain gaps vs video games.
- Multilingual and emoji prompting: Quantify success across languages (incl. non-Latin scripts, code-switching) and emoji prompts; measure degradation relative to English and identify failure patterns.
- Multi-modal prompting robustness: Systematically evaluate image/sketch prompts varying in quality, scale, and occlusions; test generalization to prompts from external sources (wikis, generative images) and across environments.
- Embodied dialogue grounding: Create benchmarks for embodied question-answering that require action to obtain evidence; report correctness, grounding fidelity, latency, and hallucination rates.
- Internal reasoning efficacy: Test whether internal reasoning text causally improves action success; measure contradictions between reasoning and actions; study optimal reasoning length/structure and when to suppress or expand it.
- Long-horizon chaining: Evaluate sequential task chains beyond short sequences; measure persistence, plan repair after errors, and ability to pause/continue; report post-completion stability and unintended actions.
- Partial observability and exploration: Describe and evaluate mechanisms for memory, map-building, re-localization, and exploration strategies under occlusion and large environments.
- Skill gaps analysis: Provide error taxonomies for categories with remaining gaps (resource gathering, combat), e.g., aiming inaccuracies, timing failures, inventory management, camera control; target training data accordingly.
- Safety and alignment: Detail guardrails for embodied action (preventing griefing, unintended purchases/interactions, hazardous behaviors) and dialogue safety; report safety incident rates and mitigation effectiveness.
- Data governance and leakage: Audit and report potential overlap between Gemini’s pretraining corpus and evaluation/training environments; perform deduplication and leakage checks; clarify licensing and plans for dataset release.
- Human baseline validity: Address biases from experienced vs novice baselines; report inter-rater reliability for human evaluations, confidence intervals, and the impact of timeouts on human vs agent comparisons.
- Robustness to environment drift: Test resilience to game patches, UI changes, resolution/HUD toggles, and mods; evaluate cross-platform differences and controller input substitution.
- Physical-world transfer: Provide empirical studies or simulation-to-real proxies showing transferability of video-game-acquired skills to robotics; identify required action-space and sensory adaptations; quantify domain gap effects.
- Open-ended self-improvement details: Describe task proposal policies, curriculum criteria, diversity metrics, stopping rules, and mechanisms to avoid trivial or repetitive tasks; report compute and sample efficiency.
- Continual learning stability: Implement and evaluate mechanisms to prevent catastrophic forgetting during self-improvement; track performance over time on a fixed benchmark suite; detail versioning and rollback strategies.
- Tool/model orchestration: Explain how SIMA 2 “interfaces with more powerful Gemini models,” including decision policies for escalation, latency/cost trade-offs, and failure recovery when tools return low-confidence outputs.
- Error recovery: Quantify the agent’s ability to detect mistakes, undo wrong actions, and re-plan; introduce metrics for recovery speed and success after deviations.
- Metrics beyond success rates: Report time-to-success, action efficiency, smoothness, post-success inactivity compliance, and unintended action counts; standardize metric definitions across environments.
- Parser/environment integration testing: Stress-test deterministic parsing under adversarial outputs; instrument environment-side safeguards against malformed commands; publish test suites.
- Memory architecture specification: Detail how frame and text histories are encoded and retrieved, context window limits, and any external memory modules; evaluate their impact on long-horizon tasks.
- Learning from human feedback: Incorporate preference learning or rater signals into training; report sample efficiency and generalization of learned reward models across tasks and environments.
- Reproducibility: Release evaluation task lists, verifiers, seeds, interface code, and hyperparameters to enable third-party validation; clarify what can be open-sourced given licensing constraints.
Practical Applications
Immediate Applications
Below is a set of concrete use cases that can be deployed now, derived from SIMA 2’s embodied capabilities, training methods, and evaluation infrastructure.
- Game QA and playtesting automation in open-world titles (sector: software/gaming; tools: SIMA 2-style keyboard/mouse action generation, OCR-based programmatic verifiers, sequential task chains with “persist-and-stop” checks; assumptions/dependencies: studio EULA compliance, screen-capture access, robust OCR on diverse HUDs/menus, latency and compute budget, fallback human review)
- In-game AI companion/co-pilot for players (sector: gaming/consumer software; tools: embodied dialogue, multi-step planning, clarifying questions, multi-modal prompts including sketches and emoji; assumptions/dependencies: safe-action gating, session-level guardrails, minimal impact on game balance/economies, on-device or low-latency inference)
- Accessibility co-pilot that maps natural language to keyboard/mouse actions (sector: accessibility/consumer software; tools: “Keyboard-Mouse Agent SDK” wrapping SIMA 2-style structured action format; assumptions/dependencies: OS-level permissions for input control, reliable perception across variable UI themes, explicit consent and privacy safeguards)
- GUI automation for complex desktop applications beyond web (e.g., CAD, GIS, 3D editors) (sector: software/RPA; tools: structured text-to-actions, internal reasoning traces, image-conditioned prompts/sketches; assumptions/dependencies: app-specific safety constraints, auditable action logs, domain-specific vocabularies, “no privileged state” requirement may need robust visual understanding)
- Simulation-based training assistants in virtual labs and educational games (sector: education/training; tools: embodied dialogue with progress reporting, sequential task curricula, internal reasoning exposure for reflection; assumptions/dependencies: curated tasks aligned to learning goals, instructor dashboards, predictable UI layouts)
- Synthetic data generation for embodied tasks and reward model calibration (sector: AI tooling; tools: “bridge data” authoring via Gemini Pro, task setter + reward model + agent loop, human quality filters; assumptions/dependencies: scalable filtering for causally consistent annotations, domain coverage across environments, budget for human validation)
- Safety evaluation sandbox for embodied AI (sector: policy/safety; tools: SIMA Evaluation Suite 2.0, programmatic verifiers (OCR/pixel heuristics), human raters, stricter persistence/“no further actions” constraints; assumptions/dependencies: diverse testbeds, standardized reporting, incident triage workflows)
- Benchmarking and research platform for generalist agents (sector: academia/AI research; tools: held-out environments (ASKA, MineDojo subset), open-ended tasks, verifiable rewards, internal reasoning traces; assumptions/dependencies: access to licensed environments or analogous open equivalents, repeatable spans/task chains, compute and logging infrastructure)
- Content creation workflows in games (sector: media/creator tools; tools: multi-modal prompting (sketch-over-screenshots), embodied information seeking (Q&A grounded in in-game UI text), automatic narration of strategy; assumptions/dependencies: recording permissions, brand/IP guidelines, configurable verbosity)
Long-Term Applications
The following opportunities require further research, scaling, integration with physical systems, or maturation of governance and tooling.
- Robotics pretraining and sim-to-real transfer for general household or warehouse skills (sector: robotics; tools/products: VLA-based “foundation agent” pretraining in diverse virtual and Genie 3 photorealistic worlds, action-to-actuator mapping, domain randomization; assumptions/dependencies: accurate physics and dynamics, sensor-action alignment, safety certification, robust sim-to-real bridging)
- Autonomous enterprise copilots operating in 3D digital twins of plants, factories, and construction sites (sector: energy/industrial/AECO; tools: embodied planning in complex UIs, verifiable rewards for procedural steps, sequential task chaining; assumptions/dependencies: integration with industrial simulators and SCADA-like UIs, strict authorization and human-in-the-loop approvals, fail-safe stopping conditions)
- Open-ended self-improving agents combining Genie 3 world generation with task/reward models (sector: AI platforms; tools: lifelong learning loops (task setter + agent + reward model + world model), curriculum pacing at the “capability frontier”; assumptions/dependencies: compute scaling, safety constraints on exploration, reliable automated verifiers, catastrophic-behavior mitigation)
- XR/AR embodied assistants that perceive the user’s environment and act via overlays (sector: XR/AR/consumer; tools: on-device multimodal perception, gaze/gesture + language + sketch prompting, structured action plans; assumptions/dependencies: privacy-preserving capture, OS-level interface hooks, robust scene understanding under motion/occlusion)
- Healthcare and emergency response training in high-fidelity simulators (sector: healthcare/public safety; tools: embodied scenario execution, multi-step procedural guidance, grounded Q&A in simulated environments; assumptions/dependencies: clinically accurate simulators, domain-specific reward verifiers, expert oversight and credentialing)
- Finance and energy operations assistants for complex terminals (sector: finance/energy; tools: cautious GUI automation with “verify-before-act” loops, persistent success detection, internal reasoning audit trails; assumptions/dependencies: strict compliance/regulatory guardrails, read-only phases before actuation, kill-switches and approvals to prevent high-stakes errors)
- Education at scale via embodied curricula and automated grading (sector: education; tools: sequential task chains, reasoning diaries, programmatic grading via OCR/pixel heuristics; assumptions/dependencies: alignment of tasks to standards, robustness across student device variability, plagiarism/misuse safeguards)
- Policy and governance frameworks for embodied agents (sector: policy/regulation; tools: standardized safety tests (persistence constraints, stop-on-complete), internal reasoning logging for audit, disclosure of automation in consumer contexts; assumptions/dependencies: cross-industry agreement on test suites, incident reporting standards, mechanisms to prevent misuse (e.g., botting in online economies))
- Desktop “screenshot-and-sketch to macro” assistants for everyday tasks (sector: daily life/consumer software; tools: multi-modal prompting, structured keyboard/mouse outputs, step-by-step confirmation; assumptions/dependencies: OS permission models, privacy-preserving screen handling, robust generalization to diverse app UIs)
Notes on key cross-cutting assumptions and dependencies:
- Access to a capable VLA (Gemini-like) model and sufficient compute/latency budgets for interactive control.
- Legal and ethical compliance: environment licenses, EULA adherence, user consent for input control and screen capture, auditability of actions and reasoning.
- Reliable evaluation functions: OCR/pixel heuristics or domain-specific verifiers to detect success, plus human-in-the-loop review for edge cases.
- Safety guardrails: stop conditions, action whitelists/blacklists, explicit confirmation for risky steps, and comprehensive logging.
- Domain transfer considerations: sim-to-real gap for robotics; UI variability for desktop/RPA; physics fidelity and scene diversity for world-model-based training.
Glossary
- Action space: The set of possible low-level controls an agent can issue to interact with an environment; "The environmental action space emulates a standard human-computer interface, encompassing 96 standard keyboard keys, mouse clicks, and discretized mouse movements representing relative (x, y) position changes."
- Agent-Environment Interface: The system that mediates perception and action between the agent and the environment; "Agent-Environment Interface. The agent receives a prompt that includes the current instruction."
- Agentic: Exhibiting goal-oriented autonomy and decision-making rather than reactive behavior; "This shifts SIMA 2 from reactive or low-level behavior to agentic, goal-oriented reasoning that is critical to more human-like forms of behavior and intelligence."
- Bridge data: Synthetic multimodal training data that interleaves reasoning, dialogue, and actions to connect high-level instructions to low-level behavior; "Bridge data (Section \ref{sec:bridge_data}) contain extra high-level interaction data between the user and the agent, such as dialogue and reasoning."
- Conditional world model: A generative model of environments that can be conditioned on text or observations to produce novel worlds; "Genie \citep{bruce2024genie, parkerholder2024genie2} introduced a conditional world model."
- Contrastive pretraining: A representation learning technique that trains models to distinguish between similar and dissimilar pairs; "or contrastive pretraining \citep{shridhar2022cliport, nair2022r3m, simateam2024scaling}."
- Ego-centric perspective: Viewing and reasoning from the agent’s own point of view within the environment; "with internal reasoning and dialogue in a manner that is causally consistent with the observable scene from the agent's ego-centric perspective and embodied behavior."
- Embodied agent: An AI system that perceives and acts within an environment through physical or simulated controls; "We introduce SIMA 2, a generalist embodied agent that understands and acts in a wide variety of 3D virtual worlds."
- Embodied dialogue: Interactive conversation where the agent can both communicate and take actions grounded in the environment; "Embodied Dialogue {paper_content} Basic Reasoning."
- Embodied performance: The effectiveness of an agent in physically grounded tasks requiring perception and action; "As compared with SIMA 1, SIMA 2 is a step-change improvement in embodied performance, and it is even capable of self-improving in previously unseen environments."
- Embodied question-answering: Answering questions by acting in the environment to gather information and respond in language; "One particularly unique form of interaction is embodied question-answering, in which a user asks or instructs the agent to find some piece of information, to which SIMA 2 must take embodied actions to determine the answer and respond in natural language."
- Foundation agents: Agents built on top of large pretrained foundation models and extended for action; "to create foundation agents that can operate within the embodied 3D worlds with a sense of agency."
- Foundation models: Large pretrained models (often multimodal) that provide general reasoning and understanding capabilities; "Foundation models have achieved remarkable success in recent years."
- Generative world model: A model that generates interactive, dynamic environments for agents to explore and learn in; "Genie 3 \citep{genie3} is a generative world model, enabling real-time interaction (via keyboard and mouse controls) with an endless number of newly-created environments."
- Genie 3: A specific generative world model that produces photorealistic, interactive environments; "Genie 3 \citep{genie3} is a generative world model, enabling real-time interaction (via keyboard and mouse controls) with an endless number of newly-created environments."
- Ground-Truth Evaluation: Assessment of task success using privileged environment state rather than visual heuristics; "Ground-Truth Evaluation: These evaluations use ground-truth state information from the environment to assess task success."
- Held-Out Environments: Entirely novel environments excluded from training used to test generalization; "we also evaluate agents in entirely held-out environments, where agents encounter new visuals, menus, and game mechanics."
- Held-out states: Unseen starting configurations within known environments used to test generalization; "the evaluations for all of our environments start from held-out states (i.e., saved checkpoints) that are not present in the training data."
- Human Evaluation: Task success judged by human raters when automatic functions are unavailable; "Human Evaluation: For tasks where no ground-truth or programmatic task function can easily be written, we rely on human raters to assess task completion by observing the video of the agent's trajectory."
- Internal reasoning: Textual thought generated by the agent to plan and adapt its actions; "By generating and conditioning on internal reasoning, SIMA 2 can use internal inferences to modify its own behavior."
- Long-horizon goals: Objectives that require extended sequences of actions and planning; "various works have explored the pursuit of long-horizon goals, such as completing entire MS-DOS and Game Boy games."
- MineDojo: A benchmark suite of language-conditioned tasks in Minecraft for evaluating embodied agents; "MineDojo \citep{fan2022minedojo} is a benchmark suite of language-conditional tasks in Minecraft built on the Malmo platform \citep{johnson2016malmo}."
- Moravec’s Paradox: The observation that high-level cognition is easier for machines than low-level sensorimotor skills; "They face a modern instantiation of Moravecâs Paradox: high-level cognitive tasks, such as playing chess or summarizing law, have proven easier to achieve than the low-level sensorimotor skills required to clear a dinner table or navigate a cluttered room."
- MuJoCo: A physics engine widely used for simulation in robotics and agent research; "In the realm of simulation, physics engines like MuJoCo \citep{todorov2012mujoco} and other simulators \citep{coumans2016, beattie2016deepmind, kolve2017ai2, savva2019habitat, abramson2020imitating, makoviychuk2021isaac, deitke2022procthor} have been instrumental in driving progress in agents and robotics research."
- Multi-modal prompting: Supplying non-text inputs (e.g., images, sketches) along with text to direct agent behavior; "SIMA 2 thus inherits multi-modal prompting capabilities, allowing us to instruct the agent in novel ways."
- Optical character recognition (OCR): Automated detection of on-screen text from images to infer state changes and success; "we use optical character recognition (OCR) to detect this on-screen text to determine task success."
- Open-ended algorithms: Learning processes that continually generate new tasks and skills without a predefined endpoint; "a grand challenge of computer science is creating open-ended algorithms \citep{stanley2015greatness, stanley2017open, clune2019aigas}, which produce never-ending innovation and learning."
- Open-world: Environments without fixed objectives that demand broad skills and exploration; "Of particular interest are open-world games, like Minecraft, which require a broad range of skills."
- Photorealistic environments: High-fidelity visual scenes resembling real-world imagery used for embodied evaluation; "including photorealistic environments generated by Genie 3."
- Policy: The agent’s decision-making function mapping observations to actions; "We then generate agent trajectories on these tasks in order to improve the policy."
- Pretrained visual representations: Visual features learned on large datasets used to improve generalization in embodied agents; "researchers adopted pretrained visual representations, such as those derived from object classification."
- Pretrained word embeddings: Vector representations of words from large corpora used to condition language-driven agents; "researchers began adopting pretrained word embeddings \citep{anderson2018vision} and sentence embeddings \citep{lynch2020grounding, shridhar2022cliport} to enable broader generalization to new instructions."
- Programmatic Evaluation: Automated evaluation using heuristics over pixels, OCR, and logged actions when ground truth state is unavailable; "Programmatic Evaluation: For commercial video games, which do not generally expose ground-truth state information, we define programmatic evaluations based on the game screen and the agent's keyboard-and-mouse actions."
- Programmatic rewards: Automatically computed reward signals defined by rules or scripts rather than human judgment; "programmatic rewards \citep{ma2023eureka, yu2023language, zhang2023omni}"
- Promptability: The capacity of a model to reliably respond to diverse instructions and prompts; "We found this mixture crucial to maintain the original capabilities of the base model, such as vision understanding, dialogue, reasoning, and promptability."
- Reinforcement learning: Learning to act via trial-and-error with rewards signaling success; "Learning from experience has traditionally been the domain of reinforcement learning \citep{sutton1998reinforcement}."
- Reinforcement learning from verifiable rewards: RL where rewards are based on objective, checkable signals of task completion; "the agent is further trained using online reinforcement learning from verifiable rewards (c.f., \cite{wen2025rlvr, mankowitz2023alphadev})."
- Reward model: A model used to score trajectories or infer task success for learning and evaluation; "By using three foundation models (task setter, agent, reward model), as well as a general world model, we demonstrate an open-ended self-improvement process."
- Sentence embeddings: Vector representations of whole sentences used to condition language-conditional agents; "researchers began adopting pretrained word embeddings \citep{anderson2018vision} and sentence embeddings \citep{lynch2020grounding, shridhar2022cliport} to enable broader generalization to new instructions."
- Shaped rewards: Auxiliary reward signals added to guide learning toward desired behaviors; "Some tasks contain additional shaped rewards to improve the instruction-following capabilities and controllability of the agent."
- Stream of tokens: A unified sequence containing multimodal inputs and outputs that the model processes; "As vision, language, and action now occupy a single stream of tokens, we can lift the input and output constraints on the agent to enable new forms of interaction."
- Supervised Fine-Tuning (SFT): Training a pretrained model on labeled data to adapt it to specific tasks; "the agent is trained via Supervised Fine-Tuning (SFT) to generate a structured text output."
- Verification function: A procedure that checks whether the agent has completed a task or achieved a goal; "a tuple of an initial game state, a text instruction, and a verification function."
- Vision-LLMs (VLM): Models that jointly process visual and textual inputs to understand and reason; "This is natively challenging for LLMs or vision-LLMs (VLM), as they were not trained to perform actions or understand the consequences of actions."
- Vision-language-action (VLA): Models that integrate perception, language understanding, and action generation; "Such ``vision-language-action'' (VLA) models \citep{brohan2023rt2} incorporate the benefits of large-scale internet pretraining into embodied agents, enabling generalization to novel objects and scenes."
- World models: Predictive models of environment dynamics used for planning, exploration, and learning; "others have focused on learning virtual worlds, sometimes referred to as world models."
- Zero-shot multilingual capabilities: The ability to perform tasks in languages never seen during the specific task training; "by leveraging the zero-shot multilingual capabilities inherited from the base model, SIMA 2 can readily perform tasks when instructed in French, German, Mandarin Chinese, etc."
Collections
Sign up for free to add this paper to one or more collections.