- The paper presents a unified world model framework that uses synthetic data generation for Vision-Language-Action policy training in embodied AI.
- It details dual modules for photorealistic video generation and physically plausible 3D scene simulation to ensure multi-view and temporal consistency.
- The framework achieves high task success and zero-shot generalization in real-world robot deployments by addressing sim2real gaps with efficient augmentation.
GigaWorld-0: Unified World Models as Synthetic Data Engines for Embodied AI
Introduction
The GigaWorld-0 framework (2511.19861) advances the paradigm of world models as scalable synthetic data engines specifically structured for Vision-Language-Action (VLA) policy learning in embodied AI domains. By integrating large-scale photorealistic video generation with physically grounded 3D scene simulation, GigaWorld-0 addresses critical bottlenecks in real-world data collection and offers instruction-aligned, diverse training signals for robot learning across manipulation, locomotion, and multi-modal environments.
Framework Overview
GigaWorld-0 combines two synergistic modules:
- GigaWorld-0-Video facilitates the generation of temporally consistent, texture-rich, and controllable videos, enabling manipulation of scene appearance, camera viewpoints, and action semantics.
- GigaWorld-0-3D enforces geometric and physical realism via 3D asset generation, scene reconstruction using 3D Gaussian Splatting, differentiable system identification, and executable, collision-free motion planning.
This unified architecture enables joint synthesis of spatially coherent, physically plausible, and visually diverse datasets suitable for training VLA models without extensive real-world robot interaction.
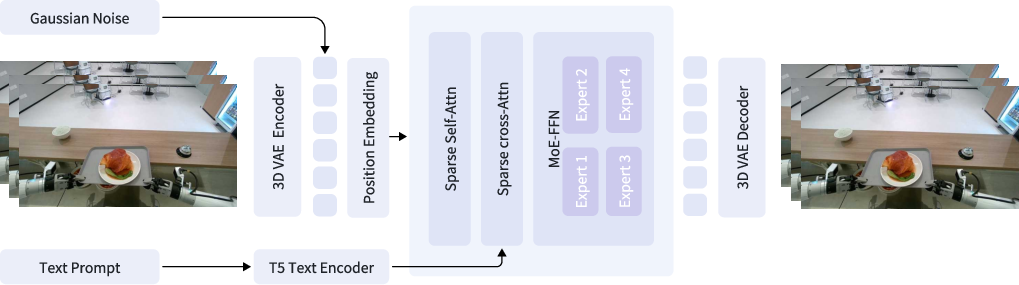
Figure 1: The framework of GigaWorld-0-Video-Dreamer.
Video Foundation Models and Controllable Augmentation
GigaWorld-0-Video-Dreamer
The flagship model, GigaWorld-0-Video-Dreamer, achieves image-text-to-video (IT2V) generation using a sparse-attention DiT backbone with MoE FFN blocks and FP8-precision training. The architecture leverages a flow-matching generative process with 3D-VAE video latents, T5-based text conditioning, and loss-balanced expert routing to dynamically specialize video regions. This design yields superior capacity-to-efficiency trade-offs compared to parameter-heavy baselines.
GigaWorld-0-Video-Dreamer enables high-throughput generation of synthetic embodied trajectories, which are temporally aligned with predicted joint actions inferred via the GigaWorld-0-IDM inverse dynamics network. Masked training over arm regions mitigates background clutter, boosting robustness and alignment fidelity.
Figure 2: Qualitative comparison of action inference on the test set.
Controllable Post-Training: Appearance, Viewpoint, and Embodiment Transfer
Three dedicated post-trained branches facilitate further domain augmentation:
These data engines enable large-scale, diverse augmentation across appearance, viewpoint, and embodiment, directly boosting generalization and policy robustness.
Multi-View Consistency and Generation Acceleration
GigaWorld-0-Video supports multi-view generation by panoramic concatenation and in-context learning, facilitating robust geometric and spatial reasoning during VLA training. Denoising step distillation and FP8 inference enable 50× speedup over standard diffusion models, supporting real-time synthesis.

Figure 5: GigaWorld can generate multi-view consistent videos, thereby enabling 3D-aware training and improving spatial reasoning in downstream tasks.
Quality control pipelines score each video for geometric consistency, coherence, instruction alignment, and physical plausibility, gating suitability for downstream pre-training or fine-tuning.
Physically Realistic 3D Scene Construction
Foreground and Background Generation
GigaWorld-0-3D-FG synthesizes high-quality manipulable assets using state-of-the-art generative 3D models (Trellis, Clay), enhanced by aesthetic and segmentation quality control. Only assets passing MeshGeoChecker validation enter the URDF catalog.
GigaWorld-0-3D-BG leverages 3DGS/3DGRUT for scene reconstruction, augmented by generative view restoration to mitigate sparse-view artifacts. Poisson-based meshing yields watertight, simulation-ready backgrounds.

Figure 6: Overall pipeline of GigaWorld-0-3D-FG.

Figure 7: Visualization of novel view synthesis before and after view restoration.
Differentiable Physics and Action Synthesis
GigaWorld-0-3D-Phys employs PINN-based differentiable system identification for robot arms (friction, stiffness, damping), optimizing physical parameters via surrogate MSE minimization. For objects, Qwen3-VL-based agents infer modal properties from multi-view orthographic projections, supporting both rigid and deformable asset simulation.
GigaWorld-0-3D-Act generates manipulation trajectories via MimicGen-based geometric augmentation for simple scenarios and RL-based policy bootstrapping for complex tasks.
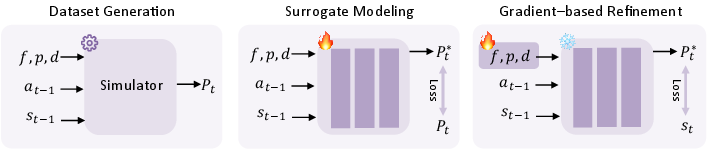
Figure 8: The learning pipeline of the differentiable physics network in GigaWorld-0-3D-Phys.
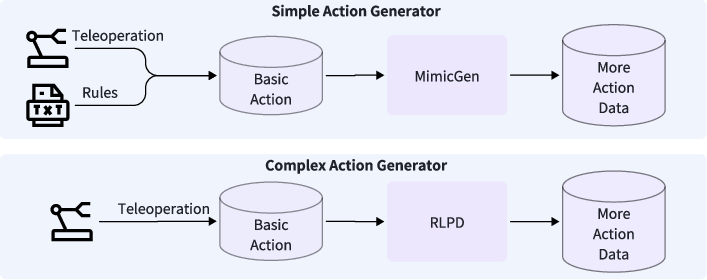
Figure 9: The overall pipeline of GigaWorld-0-3D-Act.
Integration of 3D asset generation, physically plausible dynamics, and scalable action synthesis forms a robust, simulation-ready platform for embodied policy training.
Experimental Results and Evaluation
Quantitative Benchmarks
GigaWorld-0-Video-Dreamer achieves the highest overall scores on both PBench and DreamGen Bench, outperforming Cosmos-Predict2, Wan2.2, and other large-scale video generation models—even when activating only 2B parameters. Metrics span background/object/behavior instruction-following fidelity (Qwen-IF, GPT-IF), physical authenticity (PA), and domain generalization, reflecting strong multi-dimensional performance.
Qualitative Visualization
Generated trajectories demonstrate semantic diversity and instruction adherence (Figure 10), multi-view spatial coherence (Figure 11), and high-fidelity appearance transfer across real and simulated domains (Figure 12). ViewTransfer outputs produce physically consistent action adaptation under novel viewpoints (Figure 13), while MimicTransfer enables accurate cross-embodiment translation from human to robot trajectories (Figure 14). 3D-generated scenes display geometric and dynamic realism (Figure 15).

Figure 10: Visualization results of GigaWorld-0-Video-Dreamer conditioned on the same initial frame but different text prompts, demonstrating its ability to produce diverse, semantically consistent future trajectories.

Figure 11: Multi-view visualization results of GigaWorld-0-Video-Dreamer conditioned on the same initial frame but different text prompts.

Figure 12: Visualization results of GigaWorld-0-Video-AppearanceTransfer, which enables photorealistic editing of texture, material, and lighting in real-world or simulation-acquired videos while preserving scene geometry, object semantics, and temporal coherence.

Figure 13: Visualization results of GigaWorld-0-Video-ViewTransfer, which synthesizes photorealistic videos from arbitrary camera viewpoints while simultaneously adapting robot arm trajectories to maintain physical plausibility and action consistency, enabling the generation of diverse embodied manipulation data.

Figure 14: Visualization results of GigaWorld-0-Video-MimicTransfer, which translates first-person human demonstration videos into robot-executable manipulation trajectories, enabling scalable synthesis of cross-embodiment training data for VLA models.

Figure 15: Visualization results of GigaWorld-0-3D, showcasing geometrically consistent rendering and physically realistic robot actions.
Policies trained solely on GigaWorld-0-generated data with the GigaBrain-0 VLA model achieve high task success rates in real robot deployments across laundry folding, paper towel preparation, table bussing, juice preparation, basket and box movement (Figures 17–22). This demonstrates cross-domain, zero-shot generalization and robust performance without real-world interaction during training.

Figure 16: Deployment of GigaBrain-0 on the G1 humanoid robot for real-world laundry folding.

Figure 17: Deployment of GigaBrain-0 on the PiPER arms for real-world paper towel preparation.

Figure 18: Deployment of GigaBrain-0 on PiPER arms for real-world table bussing.

Figure 19: Deployment of GigaBrain-0 on G1 humanoid robot for real-world juice preparation.

Figure 20: Deployment of GigaBrain-0 on the G1 humanoid robot for real-world paper towel preparation.

Figure 21: Deployment of GigaBrain-0 on the PiPER arms for real-world laundry baskets moving.
Implications and Future Directions
GigaWorld-0 establishes world models as core data infrastructure for embodied AI, enabling high-throughput generation of instruction-aligned, physically realistic, and geometrically coherent synthetic datasets. The capacity for appearance, viewpoint, and embodiment generalization addresses longstanding sim2real transfer challenges and enables scalable policy training for heterogeneous robotic platforms.
Potential future avenues include deployment of GigaWorld-0 as an interactive policy environment for closed-loop model-based RL, leveraging learned physical and semantic priors for active policy proposal and task decomposition, and enabling self-improving pipelines through continual real-world and synthetic data co-training.
Conclusion
GigaWorld-0 demonstrates state-of-the-art performance in synthetic data generation for embodied AI and VLA policy training, with empirically validated improvements in generalization, robustness, and scalability. Its unified modeling and large-scale training infrastructure provide a solid foundation for advancing universal robot learning and embodied intelligence research, moving toward integrated simulation-policy loops and lifelong adaptation via synthetic world models.



