D2E: Scaling Vision-Action Pretraining on Desktop Data for Transfer to Embodied AI (2510.05684v1)
Abstract: LLMs leverage internet-scale text data, yet embodied AI remains constrained by the prohibitive costs of physical trajectory collection. Desktop environments -- particularly gaming -- offer a compelling alternative: they provide rich sensorimotor interactions at scale while maintaining the structured observation-action coupling essential for embodied learning. We present D2E (Desktop to Embodied AI), a framework that demonstrates desktop interactions can serve as an effective pretraining substrate for robotics embodied AI tasks. Unlike prior work that remained domain-specific (e.g., VPT for Minecraft) or kept data proprietary (e.g., SIMA), D2E establishes a complete pipeline from scalable desktop data collection to verified transfer in embodied domains. Our framework comprises three components: (1) the OWA Toolkit that unifies diverse desktop interactions into a standardized format with 152x compression, (2) the Generalist-IDM that achieves strong zero-shot generalization across unseen games through timestamp-based event prediction, enabling internet-scale pseudo-labeling, and (3) VAPT that transfers desktop-pretrained representations to physical manipulation and navigation. Using 1.3K+ hours of data (259 hours of human demonstrations, and 1K+ hours of pseudo-labeled gameplay), we achieve a total of 96.6% success rate on LIBERO manipulation and 83.3% on CANVAS navigation benchmarks. This validates that sensorimotor primitives in digital interactions exhibit sufficient invariance to transfer meaningfully to physical embodied tasks, establishing desktop pretraining as a practical paradigm for robotics. We will make all our work public, including the OWA toolkit, datasets of human-collected and pseudo-labeled, and VAPT-trained models available at https://worv-ai.github.io/d2e/
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
D2E: Using Desktop Games to Train Robots
What is this paper about?
This paper shows a clever way to teach robots using data from desktop computers—especially video games—instead of relying only on expensive real-world robot data. The idea is simple: watching how people move a mouse and press keys to control things on a screen can teach an AI many of the same “see-and-act” skills robots need in the physical world.
What big questions are the authors asking?
Here are the main questions the paper tries to answer:
- Can we use large amounts of desktop interaction data (like screen, mouse, and keyboard) to pretrain AI that later helps robots act in the real world?
- How can we collect that desktop data in a clean, standardized, and storage-friendly way?
- Can an AI learn to guess what actions a person took in a video (like a YouTube game stream) and use that to create training labels automatically?
- Does pretraining on this desktop data actually improve robot performance on real tasks like picking objects up or navigating?
How did they do it?
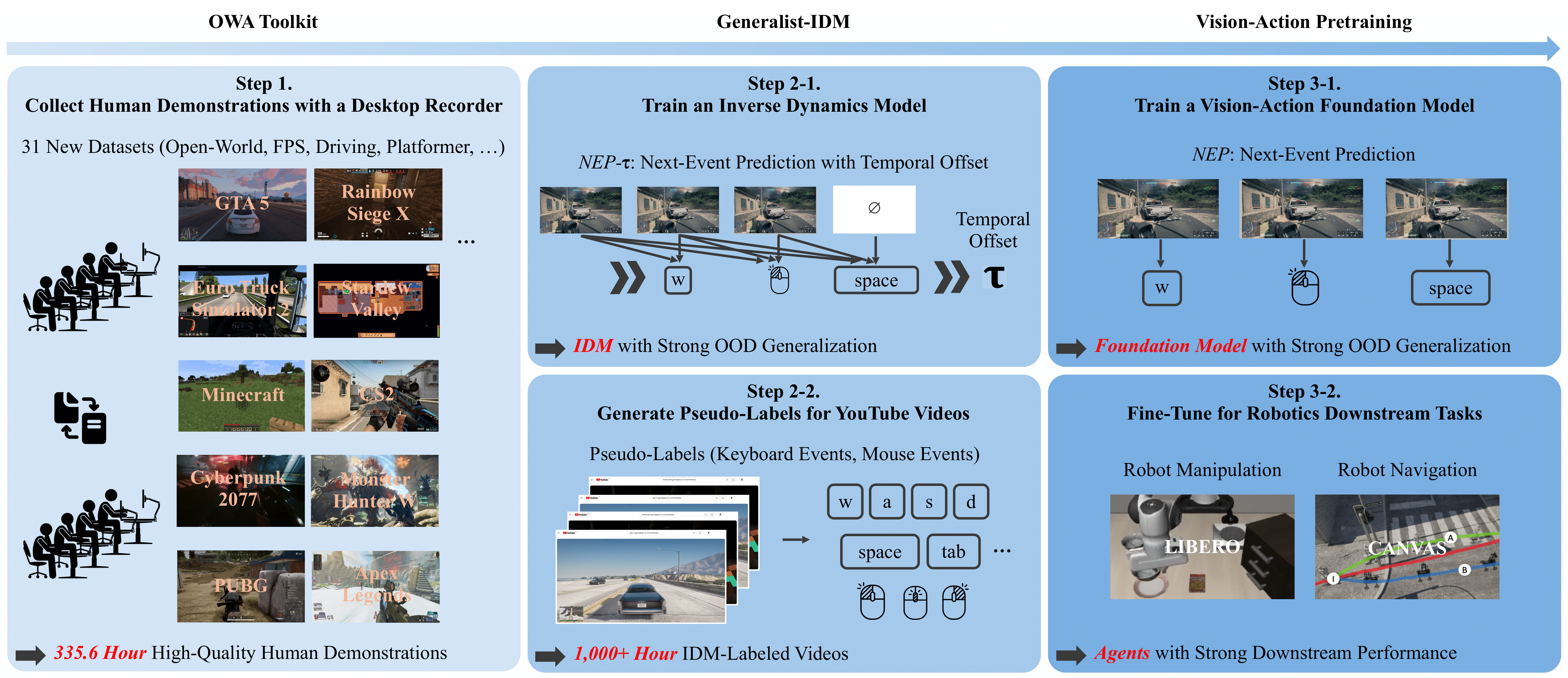
To tackle these questions, the authors built a three-part system called D2E (Desktop to Embodied AI).
They introduce three pieces. Each piece solves a different problem:
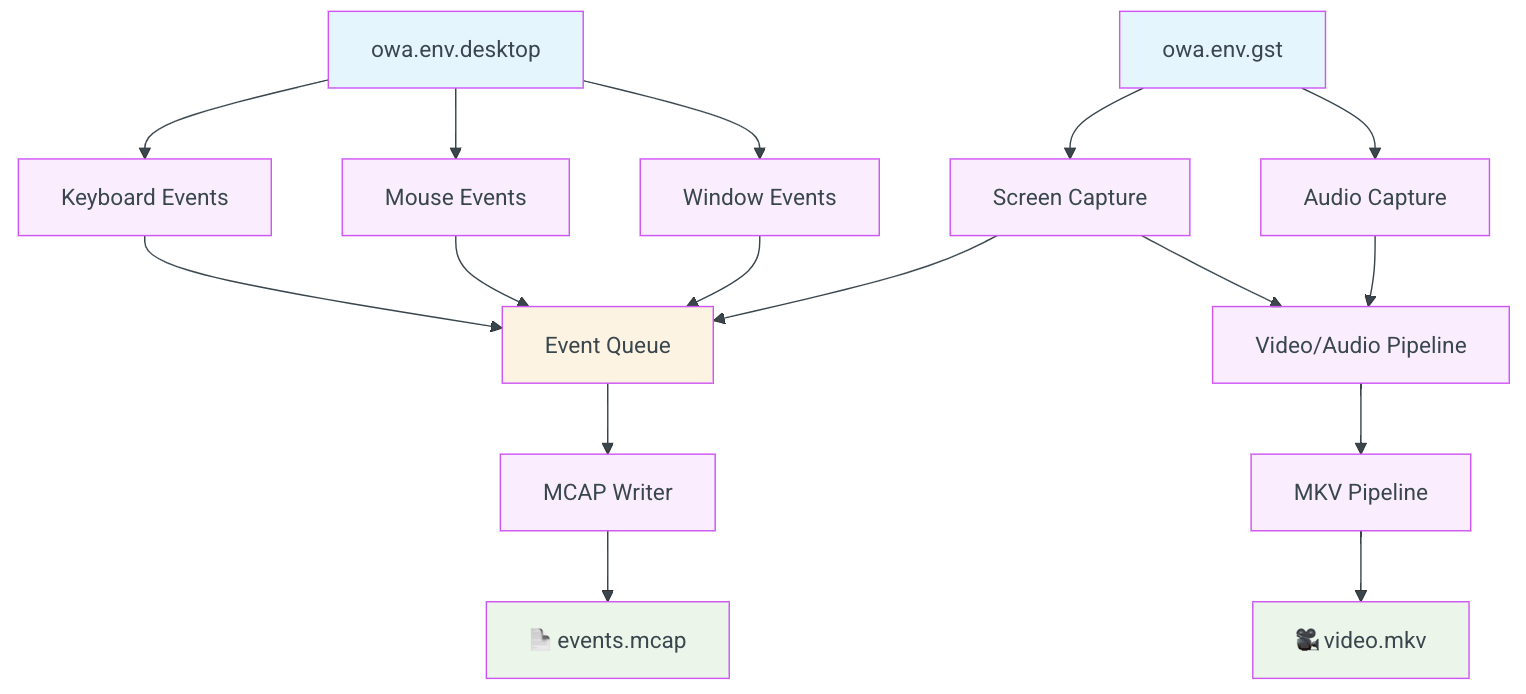
1) OWA Toolkit: collecting and organizing desktop data
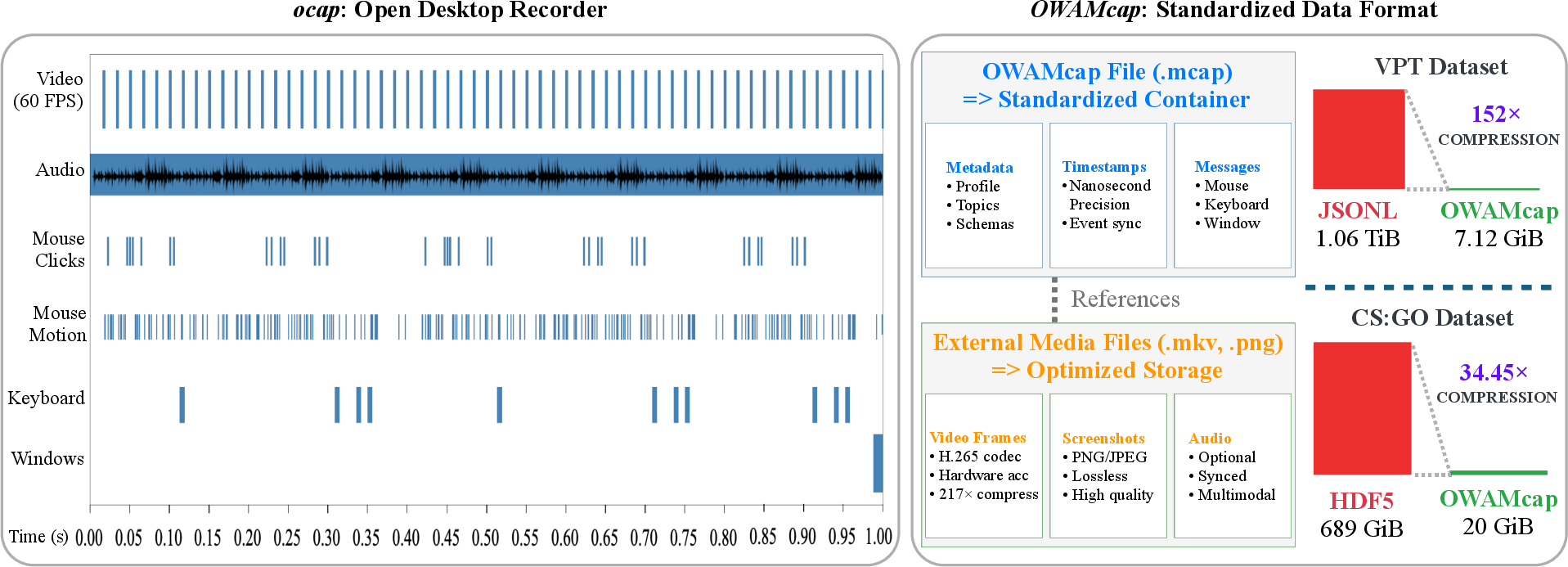
- What it is: A tool that records everything happening on a PC at the same time—screen video, mouse movements/clicks, keyboard presses, and even window info—with precise timestamps so it all lines up correctly.
- Why it matters: Data is only useful if it’s synchronized and easy to store and read. Their format compresses the data by over 100×, making big datasets practical.
- What they collected: 335 hours of human gameplay across 31 different games (first-person, third-person, and 2D). This gives a lot of variety in visuals and actions.
2) Generalist-IDM: learning to infer actions from videos
- “IDM” stands for Inverse Dynamics Model. Think of it like this: you see two frames of a game (before and after), and you try to guess which mouse or keyboard actions happened in between to cause the change.
- What’s special:
- It predicts the next event and when it happens (the timestamp), not just at fixed time ticks. That means it focuses on meaningful moments (like a click or turn) instead of wasting effort checking every tiny time slice when nothing happens.
- It generalizes across many different games, not just one.
- Why this helps: With this model, you can take unlabeled gameplay videos from YouTube and automatically create the missing “action labels” (what keys were pressed, how the mouse moved). This is called pseudo-labeling. They added 1,000+ hours of such pseudo-labeled gameplay on top of their human-collected data.
3) VAPT: Vision-Action PreTraining for robots
- After training on all this desktop data, they transfer the learned “see-and-act” skills to embodied AI tasks—like robot manipulation (moving and placing objects) and navigation (getting around spaces).
- Analogy: It’s like practicing coordination and timing in a video game and then applying that feel to a real sport—some of the patterns carry over.
A few helpful translations of technical terms
- Embodied AI: AI that can act in the physical world (like a robot), not just talk or recognize images.
- Inverse Dynamics Model (IDM): A model that looks at what changed on screen and guesses what action made it happen.
- Pseudo-labeling: Using a trained model to add labels (like actions) to unlabeled videos, so you can train on much more data.
- Zero-shot generalization: Performing well on new games or tasks the model hasn’t been trained on directly.
- Event-driven vs. tick-based: Event-driven means “predict only when something actually happens,” like checking your phone only when you expect a message; tick-based means “check every few milliseconds,” even if nothing changed.
What did they find, and why does it matter?
The authors report strong, practical results:
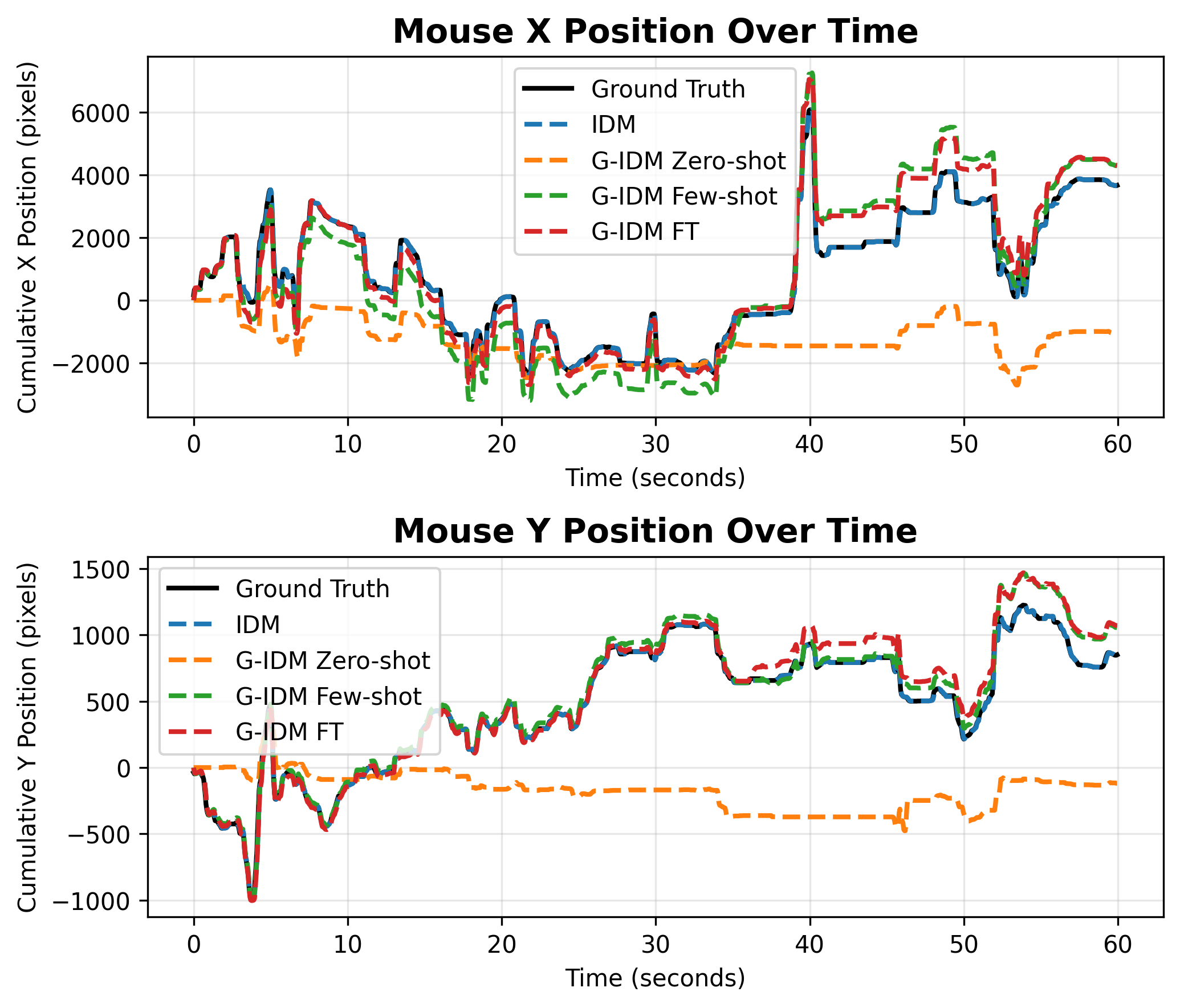
- The Generalist-IDM worked across many different games (not just one), and even handled new, unseen games surprisingly well. It could also adjust “in context”—for example, it could adapt to different mouse sensitivities after seeing a short sample.
- Using the OWA Toolkit, they recorded high-quality, synced desktop data and stored it efficiently (over 100× compression), making large datasets manageable and fast to train on.
- Most importantly, desktop pretraining transferred to real robot-style tasks:
- On robot manipulation (LIBERO benchmark): 96.6% success rate using desktop pretraining (with just the human-collected portion).
- On navigation (CANVAS benchmark): 83.3% success rate when adding the large pseudo-labeled YouTube data.
- Interesting pattern:
- Manipulation (precise hand-like control): Benefited a lot from the clean, human-collected data; the pseudo-labeled data did not add extra gains.
- Navigation (higher-level planning and movement): Benefited from the scale of pseudo-labeled data, improving performance notably.
Why this matters: Collecting real robot data is slow, expensive, and complicated. Desktop data is abundant and easy to share. Showing that desktop pretraining boosts real robotics means we can grow better robot brains without needing thousands of hours of physical robot trials.
What’s the bigger impact?
- Lower cost, faster progress: If we can pretrain using massive amounts of desktop interactions (especially public gameplay videos), we can speed up robot learning without costly hardware time.
- A practical recipe the community can use: They’re releasing tools, data, and models so others can build on this.
- Towards general-purpose agents: The more broadly an AI learns “see-and-act” patterns (moving, aiming, clicking, navigating), the better it can transfer those skills to new, real-world jobs.
- Future possibilities: This desktop-first approach could become a standard pretraining step for many robot systems, much like how LLMs are trained on internet text before doing specific tasks.
In short, this paper shows that everyday digital actions—especially in games—teach useful “sensorimotor” skills. Those skills can then help robots succeed in the real world. That’s a big step toward smarter, more capable embodied AI.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list captures what remains missing, uncertain, or unexplored in the paper, framed as concrete gaps future researchers can act on:
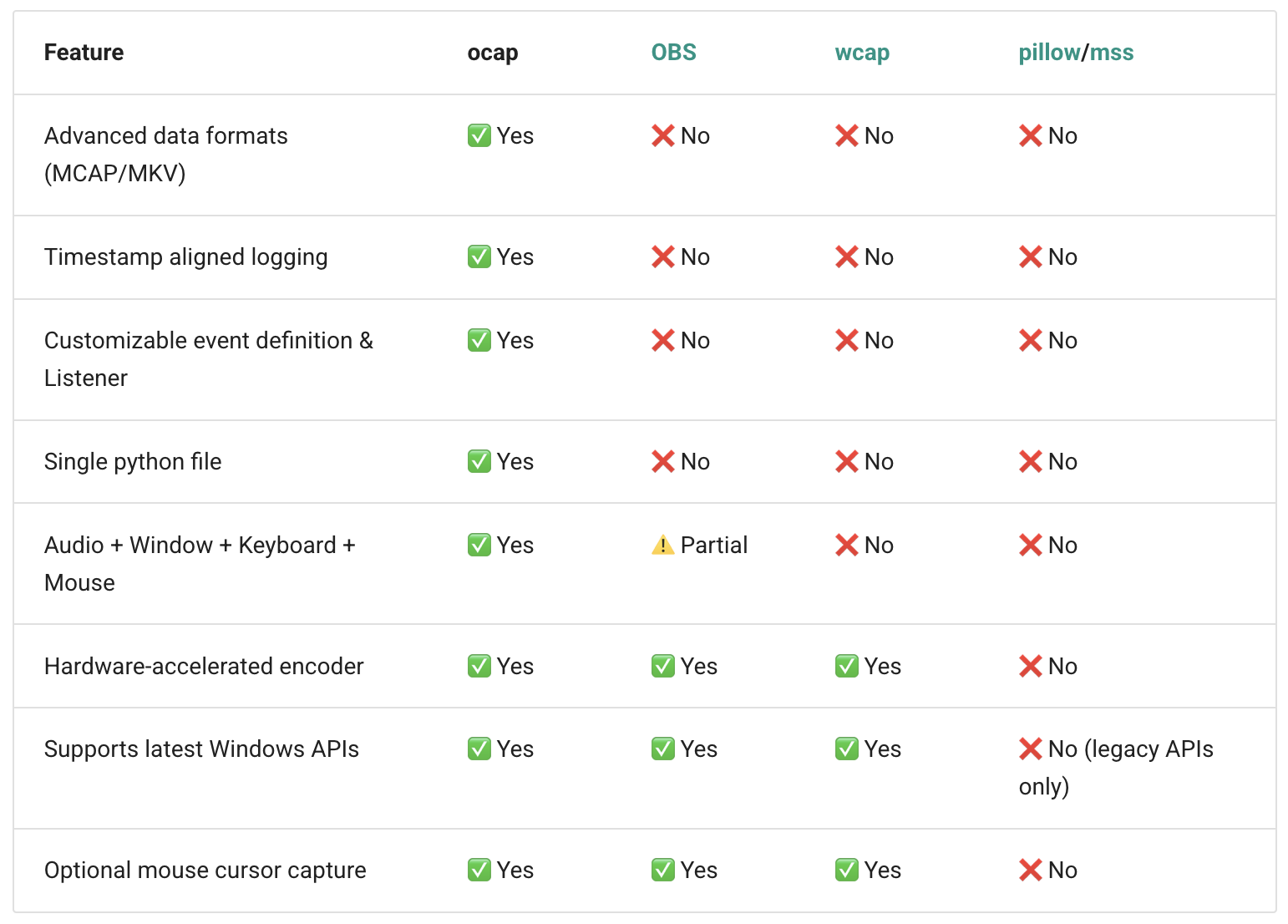
- Cross-platform capture gap: OWA is Windows-specific; no support, validation, or API parity for macOS/Linux capture pipelines and non-DirectX rendering stacks.
- Controller input coverage: YouTube gameplay often uses gamepads; OWA and tokenization focus on keyboard/mouse. There is no support for or evaluation of controller inputs (e.g., gamepad axes, buttons) and their impact on IDM generalization.
- Audio modality underuse: OWA records audio but the IDM/VAPT ignore it; the role of audio cues in action inference and robotics transfer is not ablated or quantified.
- Compression–fidelity trade-offs: H.265-based 152–217× compression is benchmarked for throughput, but the downstream effect on action inference accuracy and representation quality (e.g., small HUD text, motion blur artifacts) is not measured.
- Timestamp-based NEP-τ ablations: There is no τ sensitivity paper, comparison against tick-based IDMs under identical compute, or analysis of event sparsity regimes where NEP-τ could break down.
- Event-token schema robustness: The standardized event schema (screen, keyboard, mouse) lacks evaluation on edge cases (multi-window focus changes, cursor lock/unlock, DPI scaling, variable polling rates, frame-time jitter).
- Pseudo-label quality verification: There is no quantitative assessment of Generalist-IDM pseudo-label accuracy on internet videos (e.g., via controlled experiments with ground-truth logs or synthetic environments).
- Handling edited content: YouTube videos can include cuts, overlays, slow motion, and non-game scenes; the pseudo-label pipeline lacks detection/handling for edits that break temporal alignment.
- Frame rate mismatches: Pseudo-labeling at 20 Hz may undersample 60+ Hz gameplay; the impact of downsampling on action reconstruction quality is untested.
- Mouse sensitivity calibration: In-context “scale ratio” adaptation is observed anecdotally; there is no systematic procedure or evaluation for robust, automatic sensitivity calibration across titles.
- Domain-specific UI modes: Inventory/menus/maps are included without heuristics; no analysis of how non-embodied interactions (e.g., drag-to-sort inventory) affect representations and downstream robotics.
- Dataset licensing/compliance: The paper claims use of permissive licenses, but does not provide a reproducible curation protocol, license audit results, or mitigation plan for copyrighted assets in released datasets/models.
- Privacy and PII: Gameplay videos can contain usernames, chat overlays, or watermarks; no anonymization policy, detection pipeline, or audit results are presented.
- Scaling laws: There is no paper quantifying performance as a function of desktop data scale/quality (human vs. pseudo-labeled), model size, or training compute analogous to LLM scaling laws.
- Backbone dependence: All results use InternVL3-1B; there are no architecture ablations (e.g., ViT, Mamba, RNN-T) or tests of portability to other backbones common in robotics.
- Objective diversity: VAPT relies on vision–action pretraining; there are no comparisons to self-supervised objectives (contrastive, masked modeling, predictive coding) or multi-task mixtures including language grounding.
- Transfer mechanism analysis: The claim that “sensorimotor primitives” transfer is not substantiated with representational analyses (e.g., probing, CKA, t-SNE of action-relevant features) or causal tests.
- Task coverage gap: Games used may poorly represent manipulation-specific contact dynamics (friction, compliance); no targeted desktop tasks designed to mimic robotic manipulation primitives.
- Real-world deployment: LIBERO and CANVAS evaluations do not demonstrate closed-loop control on physical robots; sim-to-real performance, latency, and safety under real sensors/actuators remain untested.
- Generalization breadth: OOD evaluation spans only two unseen games; no systematic stress tests across genres (e.g., racing, flight sims, RTS, 2D platformers) or non-gaming desktop tasks (GUI automation, office apps).
- Label noise mitigation: Pseudo-labels hurt manipulation but help navigation; there is no data selection, filtering, or confidence-weighting strategy to reduce harmful pseudo-label noise for fine-grained control tasks.
- Instruction grounding: VAPT is vision–action; robotics baselines include VLA models. The effect of adding language conditioning to desktop pretraining (and its contribution to downstream generalization) is unexplored.
- Action-space alignment: The mapping from desktop action tokens to robotic control spaces is unspecified; no paper of which desktop action categories (e.g., cursor motion) most benefit particular robot action primitives.
- Sample efficiency: The paper reports final success rates but does not quantify improvements in data or compute efficiency (e.g., fewer robot episodes to reach a target success rate) due to desktop pretraining.
- Robustness and safety: There is no evaluation under visual perturbations (lighting, occlusions), adversarial HUD changes, or safety constraints for robot deployment after desktop pretraining.
- Temporal context limits: Event-driven tokenization may lengthen sequences; there is no exploration of memory mechanisms (e.g., recurrence, external memory) or context-length effects on IDM/VAPT performance.
- Multi-OS/window manager artifacts: Window focus changes, background notifications, and OS overlays may corrupt recordings; detection and filtering strategies are not described or evaluated.
- Data conversion fidelity: The reported 2.3K hours converted to OWAMcap lack a validation paper ensuring event/timestamp integrity across conversion paths and codecs.
- Navigation benchmark scope: CANVAS improvements are promising, but there is no testing on embodied navigation in photorealistic simulators or real environments with noisy odometry and sensor failures.
- Ethical release risks: Releasing models trained on game assets may implicate content licensing; downstream restrictions, model cards, and risk disclosures are not provided.
- Reproducibility of pseudo-labeling: The paper omits end-to-end scripts and settings for YouTube scraping, content filtering, de-duplication, and versioned lists, hindering exact reproduction of the pseudo-labeled corpus.
- Failure mode taxonomy: No qualitative/quantitative catalog of where Generalist-IDM fails (e.g., fast camera pans, HUD transitions, particle effects) to guide targeted model or data pipeline improvements.
- Multi-agent/strategic behavior: Games include strategy/planning beyond reactive control; the framework does not model or evaluate long-horizon decision-making (credit assignment) from desktop trajectories.
- Legal and platform policy alignment: Compliance with platform terms of service (e.g., YouTube data usage) and data governance constraints for released artifacts is not addressed.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be implemented now by leveraging the paper’s tools (OWA Toolkit, Generalist-IDM, VAPT) and findings.
- Desktop interaction logging and replay for GUI agents and RPA
- Sectors: software, enterprise IT, RPA, customer support
- Tools/Workflow: Use ocap to record synchronized screen/keyboard/mouse; store in OWAMcap; build supervised datasets for GUI action models; replay traces for regression tests and workflow automation
- Assumptions/Dependencies: Windows API access; adherence to organizational privacy policies; redaction/anonymization of sensitive apps
- Low-cost, at-scale collection of diverse sensorimotor trajectories
- Sectors: robotics, HCI/UX research, game analytics
- Tools/Workflow: Deploy OWA across lab/office machines or gameplay rigs; crowdsource recordings; aggregate in OWAMcap for training VLA/VAPT models
- Assumptions/Dependencies: Participant consent; data governance; storage budget (mitigated by 152× compression)
- High-throughput video/data pipelines for training multimodal models
- Sectors: ML infrastructure, MLOps, cloud providers
- Tools/Workflow: Adopt FSLDataset packing + adaptive batch decoding; transcode with optimized x264/x265; integrate into PyTorch/HF Datasets to lift training throughput and reduce I/O
- Assumptions/Dependencies: Codec licensing (H.264/H.265); conversion of existing corpora; compatibility with existing dataloaders
- Pseudo-labeling gameplay videos to create action datasets
- Sectors: gaming, e-sports analytics, platform ML
- Tools/Workflow: Run Generalist-IDM (NEP-τ) on YouTube/Twitch gameplay to generate keyboard/mouse labels; filter with simple consistency checks; use for pretraining or coach-AI tools
- Assumptions/Dependencies: Video licensing/ToS compliance; model zero-shot performance per title; occasional light finetuning for niche UIs
- Robotics lab acceleration via desktop-pretrained VAPT checkpoints
- Sectors: robotics (manipulation/navigation), academia, startups
- Tools/Workflow: Initialize policies with VAPT; finetune on small in-domain robot datasets (e.g., LIBERO-like tasks, CANVAS-like nav); integrate with LeRobot/ROS pipelines
- Assumptions/Dependencies: Camera/action interface mapping; control-rate alignment; safety envelopes for on-robot testing
- Unified logging format for multimodal telemetry and analysis
- Sectors: autonomy, AR/VR, UX research
- Tools/Workflow: Adopt OWAMcap schemas for synchronized video+event logs; enable crash-safe indexing and random access; replace bespoke CSV/JSONL pipelines
- Assumptions/Dependencies: Minor schema extensions for non-desktop sensors; internal toolchain updates
- Curriculum and teaching resources for embodied AI
- Sectors: education, workforce upskilling
- Tools/Workflow: Classroom labs using released datasets, code, and pretrained weights; assignments on inverse dynamics, event tokenization, transfer learning
- Assumptions/Dependencies: GPU access (modest for inference/finetuning); dataset mirrors for classrooms
- Cost-optimized storage and analytics for large user-interaction corpora
- Sectors: product analytics, digital forensics, QA
- Tools/Workflow: Replace PNG/RAW logs with OWAMcap MediaRef (H.265); leverage indexing for fast slice-and-query; enable scalable auditing and A/B test analysis
- Assumptions/Dependencies: Acceptable visual fidelity for downstream tasks; retention policies aligned with compliance
Long-Term Applications
These opportunities are enabled by the paper’s paradigm but require further research, scaling, or ecosystem development.
- Internet-scale “desktop-to-robot” pretraining services
- Sectors: robotics platforms, cloud AI
- Tools/Workflow: Cloud ingestion of millions of gameplay/desktop hours; generalized NEP-τ IDMs for pseudo-labeling; VAPT-style pretraining for foundation robot policies
- Assumptions/Dependencies: Substantial compute; robust domain generalization; data licensing and provenance infrastructure
- Cross-device OS agents that operate full workflows safely
- Sectors: productivity, enterprise ops, IT automation
- Tools/Workflow: Event-tokenized GUI agents that plan, act, and recover across apps; sandboxed execution; policy constraints and human-in-the-loop verification
- Assumptions/Dependencies: Safety/permission models; OS diversity (beyond Windows); privacy-preserving capture
- Sim-to-real bridging via game-derived curricula for robots
- Sectors: robotics for logistics, household, retail
- Tools/Workflow: Map gameplay primitives (navigation, manipulation) to physical skills; staged curricula; multi-view perception alignment; domain randomization with event timing
- Assumptions/Dependencies: Sensor/action homology; robust calibration; benchmarking beyond LIBERO/CANVAS
- Standards for multimodal action-logging and responsible data use
- Sectors: policy, standards bodies, legal/compliance
- Tools/Workflow: Extend OWAMcap-like schemas into cross-platform standards; dataset provenance, consent metadata, machine-readable licenses; audit toolkits
- Assumptions/Dependencies: Multi-stakeholder coordination; alignment with platform ToS and copyright law
- Autonomous UX testing and software QA at scale
- Sectors: enterprise software, consumer apps, gaming QA
- Tools/Workflow: Generalist-IDM/VAPT agents replay and mutate flows; auto-detect UI regressions; learn from production telemetry
- Assumptions/Dependencies: Deterministic replays; robust UI element grounding; safe test environments
- Federated, privacy-preserving interaction learning on edge devices
- Sectors: consumer OS, browsers, productivity suites
- Tools/Workflow: On-device ocap capture with local training; federated aggregation of event-token models; differential privacy and secure enclaves
- Assumptions/Dependencies: On-device compute; strong privacy guarantees; incentives for participation
- Assistive tech that transfers digital sensorimotor skills to physical aids
- Sectors: healthcare, rehabilitation, accessibility
- Tools/Workflow: Train assistive robots/exoskeletons using desktop-derived sensorimotor patterns; adapt to user-specific “mouse sensitivity” equivalents via in-context calibration
- Assumptions/Dependencies: Clinical validation; user safety; personalized adaptation
- Regulatory-grade dataset governance and copyright auditing
- Sectors: legal tech, compliance, content platforms
- Tools/Workflow: Provenance tracking for pseudo-labeled gameplay; automated license checks; opt-out/enforcement mechanisms; synthetic-to-real label lineage
- Assumptions/Dependencies: Platform APIs; standardized metadata; evolving copyright doctrines
- AR/VR embodied agents using timestamp-based event modeling
- Sectors: AR/VR, telepresence, training simulators
- Tools/Workflow: Extend event tokenization to controllers/hand tracking; learn inverse dynamics for immersive interactions; pretrain agents that assist or coach users
- Assumptions/Dependencies: High-fidelity multimodal capture; low-latency inference; domain calibration
- Sustainability and cost optimization for video-centric ML
- Sectors: cloud/edge ML, media tech, autonomous systems
- Tools/Workflow: Repurpose OWAMcap + adaptive decoding to other domains (egocentric/robotics video); reduce energy and storage per training token
- Assumptions/Dependencies: Generalization of compression gains; acceptable quality for control tasks
Notes on feasibility and cross-cutting assumptions
- Transfer invariance: The core premise is that desktop sensorimotor primitives transfer to physical tasks; effectiveness varies by task (navigation benefited from scale/pseudo-labels; fine manipulation favored high-quality human data).
- Licensing and privacy: Pseudo-labeling public gameplay depends on platform ToS, creator licenses, and privacy considerations; enterprises need robust governance.
- Platform constraints: Current tooling is Windows-centric; cross-OS support and mobile/tablet platforms will broaden applicability.
- Compute and engineering: While training costs reported are moderate, internet-scale deployment needs robust, cost-aware data and training infrastructure.
- Safety: For any physical deployment, additional layers for safety, supervision, and verification are required beyond benchmark success rates.
Glossary
- Adaptive batch decoding: A decoding approach that batches frame retrieval to reduce random access overhead and improve throughput for compressed video during training. "Our adaptive batch decoding algorithm (1) seeks to the target frame; (2) demuxes and decodes until a keyframe is encountered; (3) upon hitting a keyframe, resumes seeking to the target frame."
- Autoregressive inference: An inference procedure that generates the next action by conditioning on previously observed states and actions in sequence. "We employ an autoregressive inference pipeline to generate actions and evaluate model performance across multiple metrics."
- CANVAS (benchmark): A robot navigation benchmark designed to test instruction-following robustness across diverse environments. "we achieve a total of 96.6\% success rate on LIBERO manipulation and 83.3\% on CANVAS navigation benchmarks."
- Demuxing: The process of separating multiplexed data streams (e.g., audio/video) from a container during decoding. "demuxes and decodes until a keyframe is encountered"
- Embodied AI: AI systems that perceive and act in environments via sensorimotor interactions, often in robotics or simulation. "LLMs leverage internet-scale text data, yet embodied AI remains constrained by the prohibitive costs of physical trajectory collection."
- Event-driven modeling: Modeling that predicts and processes only discrete, meaningful events rather than fixed time ticks, improving efficiency in sparse-event regimes. "enabling event-driven modeling that avoids âno-opâ ticks and makes more efficient use of inference context."
- Event tokenization: The serialization of discrete interaction events (screen updates, keyboard, mouse) into token sequences for transformer training. "A detailed specification of the event tokenization process is provided in Appendix~\ref{app:tokenization_details}."
- Few-shot prefix: A short conditioning sequence provided at inference time that helps a model adapt to a new context without parameter updates. "when provided with a few-shot prefix that fills the first 2048 tokens in our streaming inference, the predicted scale ratio improves significantly"
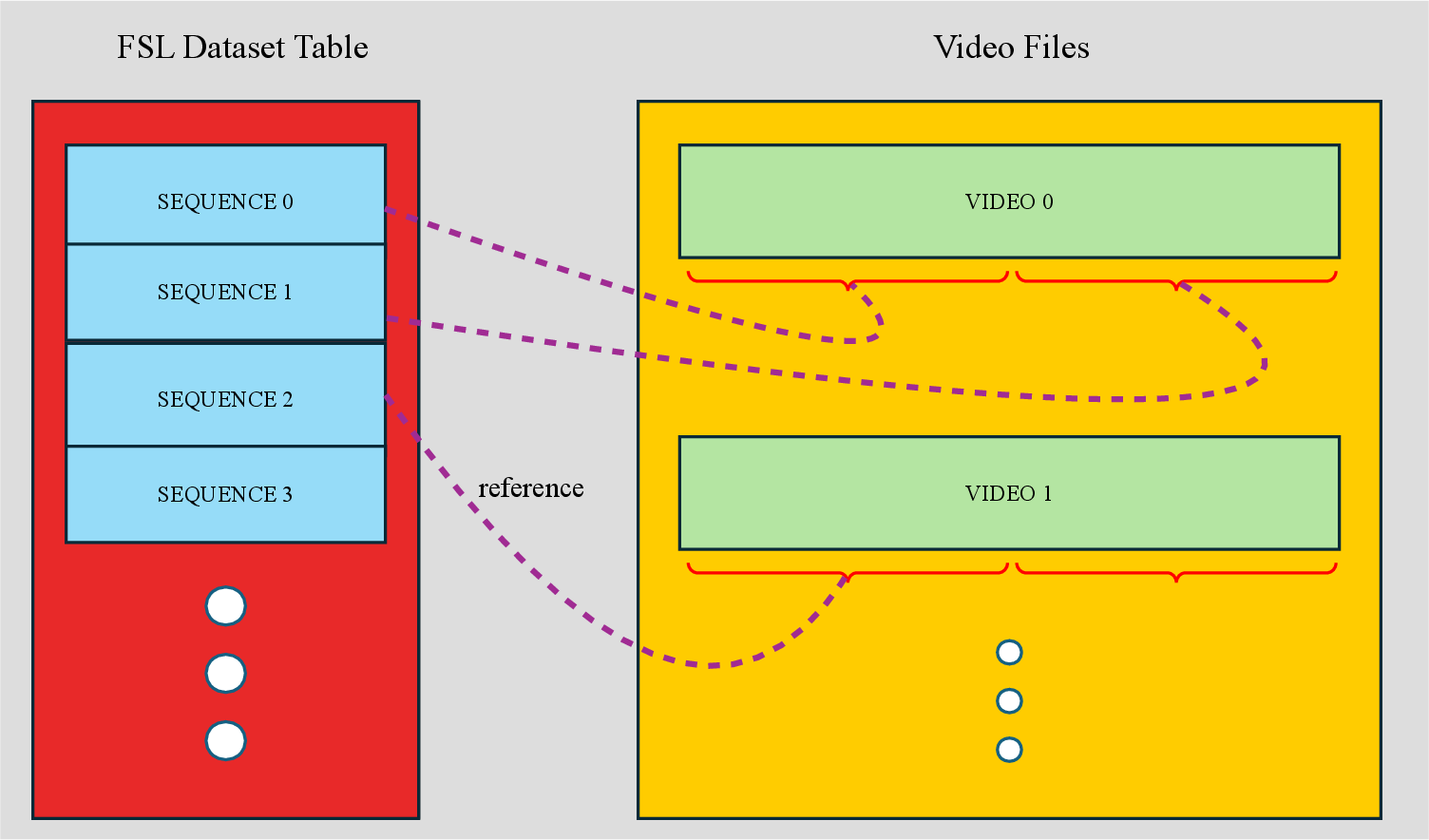
- Fixed Sequence Length Dataset (FSLDataset): A data format that packs event sequences into uniform lengths while preserving episode boundaries to improve training throughput. "To optimize training throughput, we introduce FSLDataset that packs sequences to uniform lengths while preserving episode structure."
- Generalist Inverse Dynamics Model (Generalist-IDM): A multi-domain IDM that predicts actions across diverse desktop environments and unseen games using timestamp-aware event prediction. "the Generalist-IDM that achieves strong zero-shot generalization across unseen games through timestamp-based event prediction"
- GStreamer: A multimedia framework used to build pipelines for capturing, processing, and streaming audio/video. "Built on Windows APIs and GStreamer~\citep{microsoft2024dxgi, gstreamer2024framework}, OWA's ocap recorder synchronizes multimodal streams"
- Heads-Up Display (HUD): On-screen overlays (e.g., health bars, minimaps) in games that provide information to the user. "YouTube gameplay footage also exhibits consistent HUD layouts and frame rates, which align well with the OWA Toolkit's event schema."
- H.265 codec: A high-efficiency video compression standard used to reduce storage and bandwidth for recorded screen data. "optimized video storage using H.265 codec (217Ã compression)."
- In-context adaptation: A model’s ability to adjust its behavior to new settings based on input context alone, without changing parameters. "indicating that the Generalist-IDM exhibits in-context ability to adapt to mouse sensitivity."
- InternVL3-1B: A multimodal transformer architecture used as the backbone for the Generalist-IDM and VAPT models. "we train the Generalist-IDM using the InternVL3-1B~\citep{zhu2025internvl3} architecture with the objective."
- Inverse Dynamics Model (IDM): A model that infers the action taken given observations before and after the action, often used to label actions from video. "Inverse Dynamics Models (IDMs) condition on surrounding statesâpast and futureâto infer the action taken at time ."
- Keyframe: A frame in compressed video from which decoding can begin; non-keyframes depend on preceding frames. "Video decoding requires seeking to keyframes and then sequentially decoding frames, as compressed video formats cannot decode arbitrary frames independently."
- LIBERO (benchmark): A standardized robotics manipulation benchmark evaluating task success across spatial, object, and goal categories. "we achieve a total of 96.6\% success rate on LIBERO manipulation and 83.3\% on CANVAS navigation benchmarks."
- MCAP: An industry-standard, serialization-agnostic container format for logging multimodal sensor data with indexing and crash-safety. "extends the industry-standard MCAP format~\citep{foxglove2022mcap}âwidely adopted in robotics for multimodal sensor logging and providing efficient indexing, crash-safe writes, and broad ecosystem supportâwith two key desktop-specific additions."
- MediaRef: An extension mechanism that stores compressed media externally while keeping metadata and events in MCAP for efficient access. "Second, MediaRef enables efficient video storage while maintaining MCAP compatibility."
- Next-Event Prediction with Temporal Offset (NEP-τ): A training objective that predicts the next event and its timestamp while conditioning on a limited window of future observations offset by τ. "we adopt , a temporal-offset variant of NEP."
- ocap (Omnimodal CAPture): A synchronized desktop recorder that logs video, audio, mouse, and keyboard events with precise timing. "The ocap (Omnimodal CAPture) tool addresses this gap by capturing desktop signals in a synchronized manner, recording video, audio, keyboard, and mouse interactions with high temporal precision."
- Open-World Agents (OWA) Toolkit: An open toolkit for standardized, synchronized capture and storage of desktop interaction data at scale. "We introduce the Open-World Agents (OWA) Toolkit alongside large-scale desktop data, establishing both the infrastructure and data foundation for embodied AI research."
- Out-of-Distribution (OOD) generalization: A model’s ability to perform well on data from domains not seen during training. "NEP-Ï) to achieve OOD generalization, enabling pseudo-labeling of 1K+ hours of YouTube gameplay."
- Pseudo-labeling: Automatically generating labels (e.g., actions) for unlabeled data using a trained model to expand training datasets. "enabling pseudo-labeling of 1K+ hours of YouTube gameplay."
- Scale ratio: A calibration factor relating predicted and actual mouse movement scales (e.g., sensitivity) across environments. "the predicted scale ratio improves significantly"
- Streaming inference: Running inference continuously over long sequences, often processing tokens/events as a stream. "when provided with a few-shot prefix that fills the first 2048 tokens in our streaming inference, the predicted scale ratio improves significantly"
- Timestamp-based prediction: Modeling that predicts both the content and exact time of the next event rather than operating on fixed ticks. "While most existing IDMs adopt a tick-based predictionâpredicting actions at fixed intervalsâour design employs timestamp-based prediction."
- TorchCodec: A video I/O library baseline used for comparison in decoding throughput and I/O efficiency benchmarks. "41Ã less than TorchCodec~\citep{torchcodec2024}"
- Vision-Action PreTraining (VAPT): Pretraining models on paired visual observations and actions to learn transferable control representations. "We demonstrate that desktop-pretrained representations transfer meaningfully to physical robotics through Vision-Action PreTraining (VAPT)."
- Vision–Language–Action (VLA): A family of models trained jointly on visual, textual, and action modalities to enable grounded decision-making. "Large-scale vision-action (or vision-language-action) pretraining depends on multimodal corpora that pair perception with grounded actions across diverse tasks"
- Zero-shot generalization: Performance on novel tasks or environments without any additional task-specific training. "achieves strong zero-shot generalization across unseen games through timestamp-based event prediction"
Collections
Sign up for free to add this paper to one or more collections.