- The paper demonstrates that a two-stage approach, combining Embodied Prior Learning (EPL) and online reinforcement learning (RL), effectively equips compact VLMs with robust reasoning and control in interactive environments.
- EPL enriches small VLMs with structured perceptual and reasoning priors from curated trajectory, environment, and external data, laying a strong foundation for high-level planning and low-level control.
- Online RL with turn-level policy optimization and self-summarization enhances action precision and overall performance, outperforming larger models on challenging simulated benchmarks.
Motivation and Problem Setting
The paper addresses the challenge of equipping compact vision-LLMs (VLMs) with robust embodied reasoning and control capabilities, enabling them to function as agents in interactive environments. While large-scale VLMs can be prompted to perform complex embodied tasks, their computational cost and inefficiency hinder practical deployment. In contrast, smaller VLMs lack the necessary embodied priors and reasoning skills, resulting in a significant performance gap. The core problem is to bridge this gap by developing a scalable, data- and compute-efficient training framework that enables small VLMs to generalize across both high-level planning and low-level control tasks in embodied environments.
ERA Framework Overview
ERA (Embodied Reasoning Agent) is a two-stage training pipeline designed to endow compact VLMs with generalizable embodied intelligence. The first stage, Embodied Prior Learning (EPL), injects structured perception and reasoning priors via supervised finetuning on curated datasets. The second stage applies online reinforcement learning (RL) to further refine the agent's policy through interactive environment rollouts, leveraging process-level rewards and turn-level policy optimization.
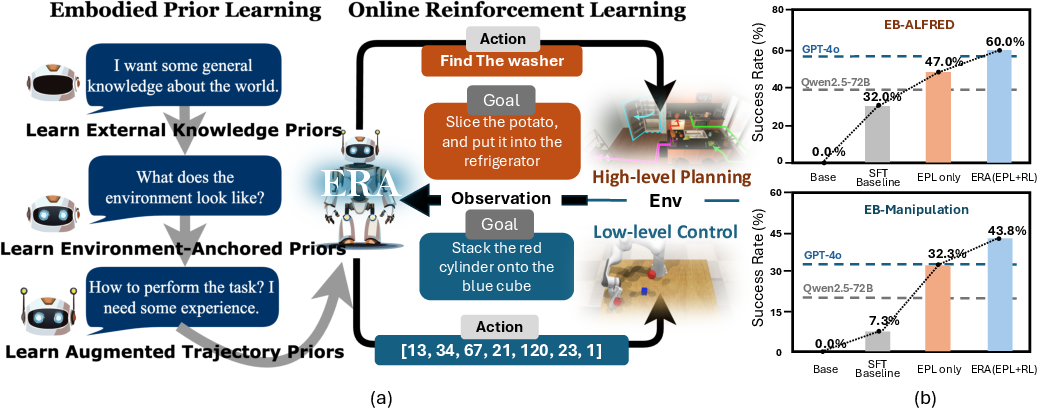
Figure 1: (a) Overview of the ERA framework: EPL finetunes on diverse data sources to provide foundational knowledge, and online RL further improves the agent. (b) ERA (EPL+RL) boosts a 3B base model to surpass GPT-4o on hold-out evaluation sets.
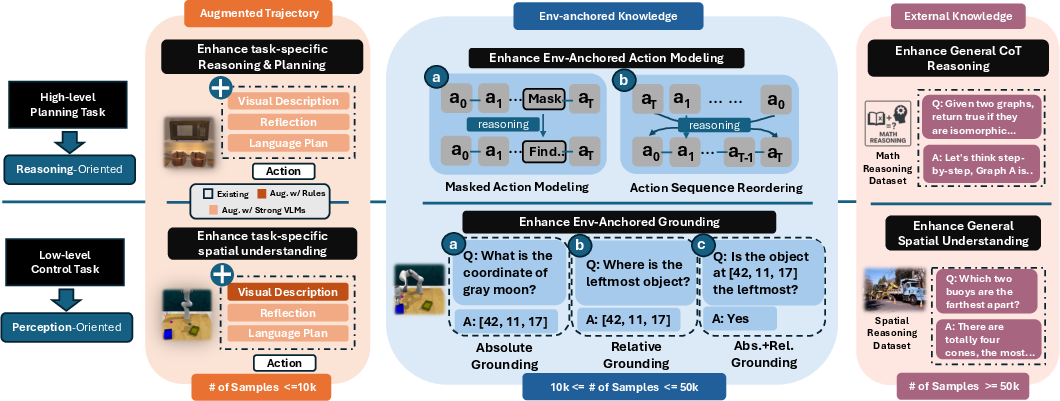
Embodied Prior Learning: Data Curation and Supervised Finetuning
EPL is motivated by the observation that small VLMs, after generic pretraining, lack environment-specific grounding and step-level reasoning. The paper introduces a principled taxonomy of prior data sources:
The EPL stage employs a sequential curriculum: environment-anchored and external priors are used to establish foundational skills, followed by trajectory-based finetuning to align with downstream agent tasks.
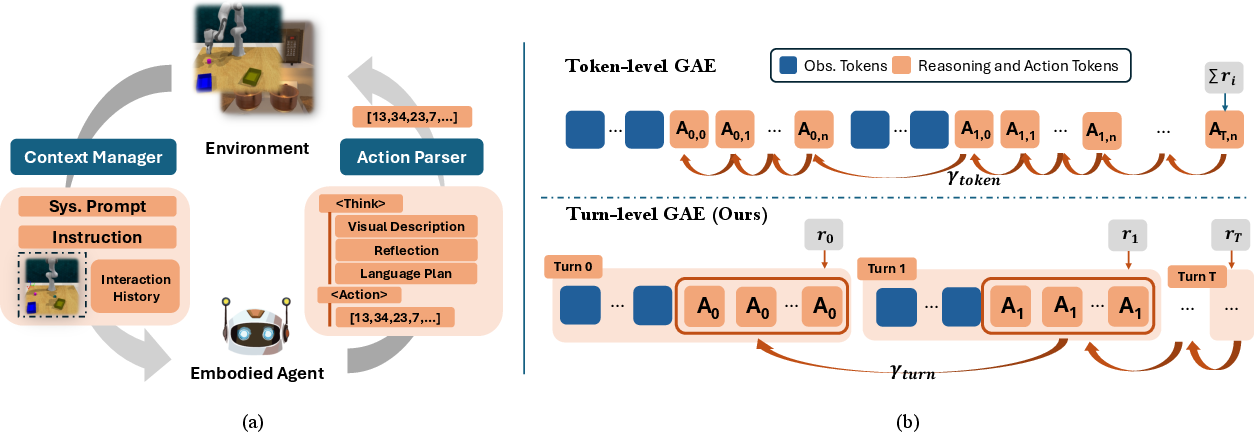
Online Reinforcement Learning: Agent Design and Policy Optimization
The RL stage addresses three challenges: efficient context management, sparse reward propagation in long-horizon tasks, and stable policy optimization for sequence-generating agents.
Experimental Results
ERA is evaluated on EmbodiedBench, covering both high-level planning (EB-ALFRED) and low-level control (EB-Manipulation). The 3B-parameter ERA model is compared against prompting-based large models (e.g., GPT-4o, Claude-3.5-Sonnet, Gemini-1.5-Pro) and training-based baselines (e.g., RL4VLM, VAGEN, Reinforced Reasoner, Robot-R1).
Key results:
- ERA-3B achieves 65.2% average success on EB-ALFRED and 48.3% on EB-Manipulation, outperforming GPT-4o by 8.4 and 19.4 points, respectively.
- On unseen task subsets, ERA demonstrates strong generalization, with gains of up to 38 points over VAGEN on spatial reasoning tasks.
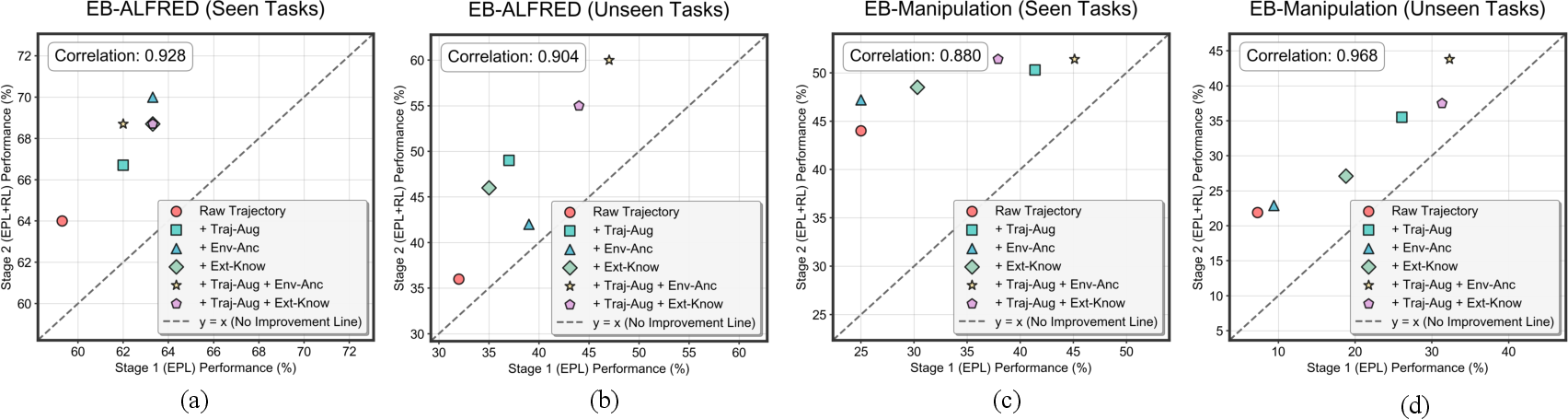
- EPL alone provides a strong foundation, but the addition of RL yields substantial further improvements, especially on out-of-distribution tasks.

Figure 4: Examples of ERA performing step-by-step reasoning and actions: (a) on EB-ALFRED, it identifies and reflects on earlier errors; (b) on EB-Manipulation, it accurately places the star into the correct slot of the shape sorter.
Ablation Studies and Analysis
Prior Data Ablations:
RL Design Ablations:
Context Management:
- Self-summarization enables efficient and effective context usage, outperforming longer history windows and reducing input length.
Error and Case Analysis
Error analysis reveals that EPL reduces all error types (perception, reasoning, planning), while RL is especially effective at reducing reasoning and planning errors. Case studies show that ERA can recover from earlier mistakes via reflection and adjust plans dynamically, a capability absent in EPL-only agents.

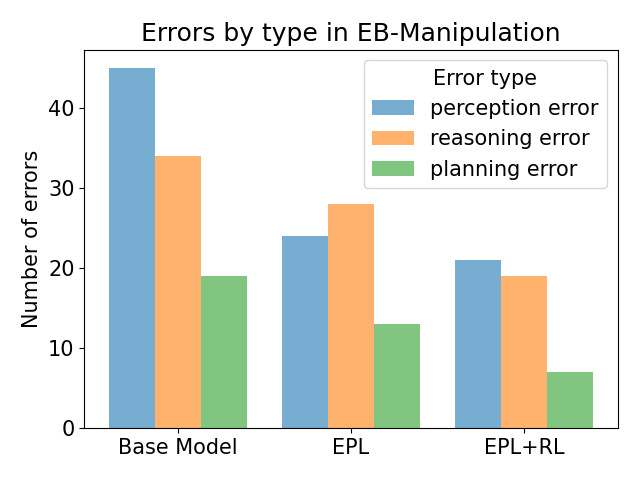
Figure 7: Comparing error statistics in two benchmarks.

Figure 8: Reflection error Example in EB-Manipulation. ERA successfully identified the correct target object: the azure triangular prism, while EPL mistakenly selected the yellow cube.
Figure 9: Successful reflection Example in EB-Manipulation. Both agents were able to identify the silver star as the target object.

Figure 10: Planning error example in EB-ALFRED. ERA successfully identified the second spray bottle as SprayBottle_2 while EPL repeatedly located the same SprayBottle.
Figure 11: Successful reflection example in EB-ALFRED. Both agents were able to identify the FloorLamp as the target object.
Implementation Considerations
- Resource Requirements: EPL and RL stages are optimized for efficiency, with the 3B model trained on 2 H200-140GB GPUs (EPL: 2–5 hours; RL: ~12 hours per task).
- Scalability: The framework supports large-scale parallel rollouts and is compatible with distributed training and memory optimizations (DeepSpeed, BF16, gradient checkpointing).
- Deployment: The agent's structured output format and context management facilitate integration into real-world or simulated robotic systems.
- Limitations: All evaluations are in simulation; real-world transfer remains an open challenge.
Implications and Future Directions
ERA demonstrates that compact VLMs, when equipped with structured embodied priors and refined via online RL, can match or surpass much larger models on challenging embodied tasks. The framework's modularity and data taxonomy provide a blueprint for scalable embodied agent development. The strong correlation between EPL and RL performance suggests that future work should focus on improving prior data quality and diversity, as well as exploring real-world deployment and sim-to-real transfer. The turn-level RL paradigm and self-summarization context management are likely to be broadly applicable to other agentic domains involving long-horizon, multimodal reasoning and control.
Conclusion
ERA establishes a practical and effective recipe for transforming small VLMs into generalizable embodied agents. By systematically integrating diverse prior knowledge and principled RL design, ERA achieves strong performance and generalization with modest computational resources. The framework's insights into data curation, context management, reward shaping, and policy optimization are expected to inform future research in embodied AI, agent alignment, and scalable multimodal learning.