- The paper introduces a unified platform combining multi-view video diffusion, efficient action decoding, and closed-loop simulation to advance robotic manipulation.
- It employs a two-stage training process leveraging large-scale real-world robotic episodes, enabling high-fidelity video generation and rapid policy inference.
- The system demonstrates robust cross-embodiment generalization and outperforms baseline models, validated by the comprehensive EWMBench evaluation.
Introduction
Genie Envisioner (GE) presents a unified, video-generative world foundation platform for robotic manipulation, integrating policy learning, evaluation, and simulation within a single architecture. The platform is structured around three principal modules: GE-Base, a large-scale, instruction-conditioned video diffusion model; GE-Act, a lightweight action decoder for mapping latent representations to executable action trajectories; and GE-Sim, an action-conditioned neural simulator for high-fidelity, closed-loop policy development. The system is complemented by EWMBench, a comprehensive benchmark suite for evaluating visual fidelity, physical plausibility, and instruction-policy alignment. This essay provides a detailed technical analysis of the architecture, training methodology, empirical results, and implications for future research in embodied AI.
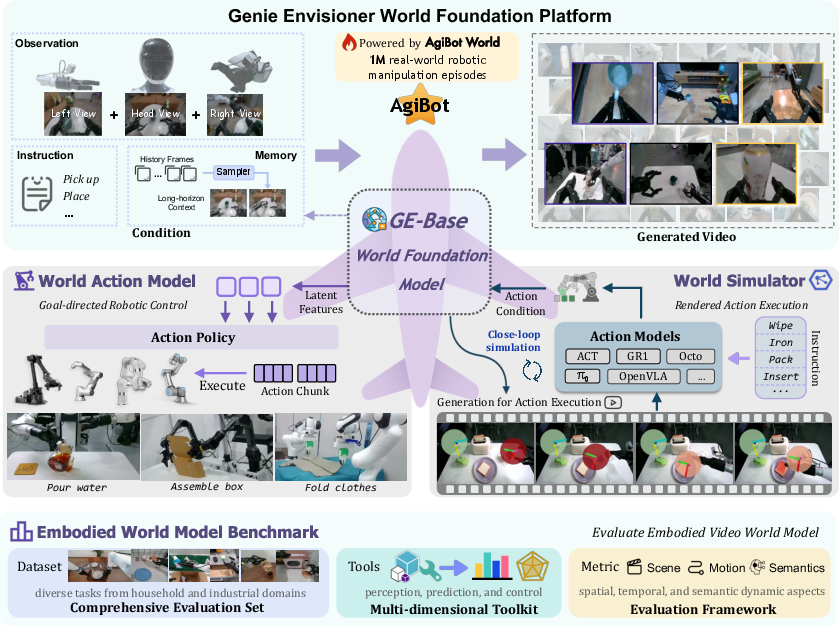
Figure 1: Overview of the Genie Envisioner World Foundation Platform, integrating manipulation policy learning and evaluation within a unified video-generative framework.
GE-Base: World Foundation Model
GE-Base is the core of Genie Envisioner, designed as a multi-view, instruction-conditioned video diffusion transformer. The model is trained on the AgiBot-World-Beta dataset, comprising over one million real-world, instruction-aligned, multi-view robotic manipulation episodes. The architecture employs an autoregressive video generation process, segmenting outputs into discrete video chunks, each conditioned on initial observations, language instructions, and a sparse memory of historical frames. This design enables the model to capture extended temporal dependencies and maintain semantic alignment throughout manipulation sequences.
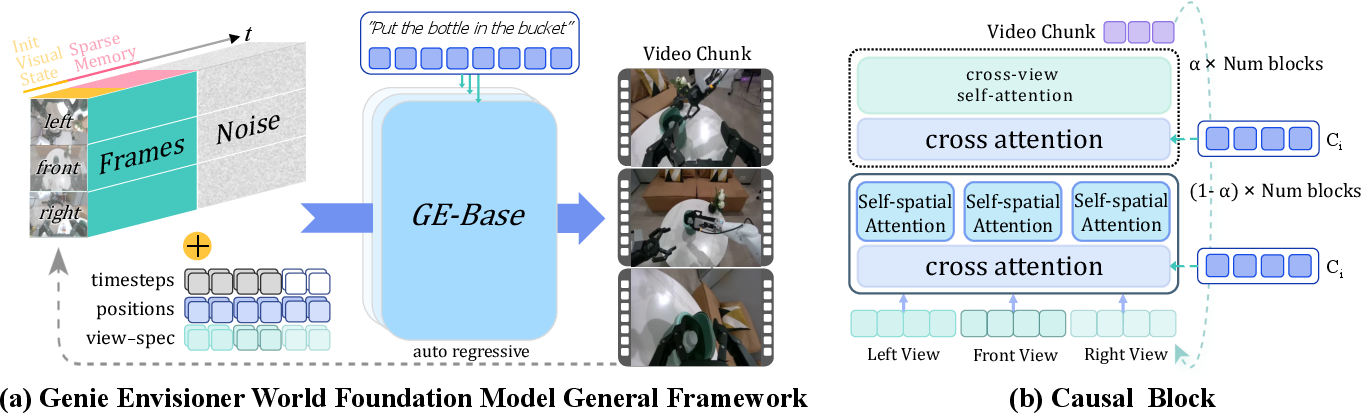
Figure 2: Overview of the GE-Base World Foundation Model, illustrating the autoregressive, multi-view video generation process and cross-view causal block for spatial consistency.
The training pipeline involves a two-stage process:
- Multi-Resolution Temporal Adaptation (GE-Base-MR): Pretraining on high-frame-rate sequences with variable sampling rates to learn spatiotemporal invariance.
- Low-Frequency Policy Alignment (GE-Base-LF): Fine-tuning on low-frame-rate sequences to align with the temporal abstraction required for downstream action modeling.
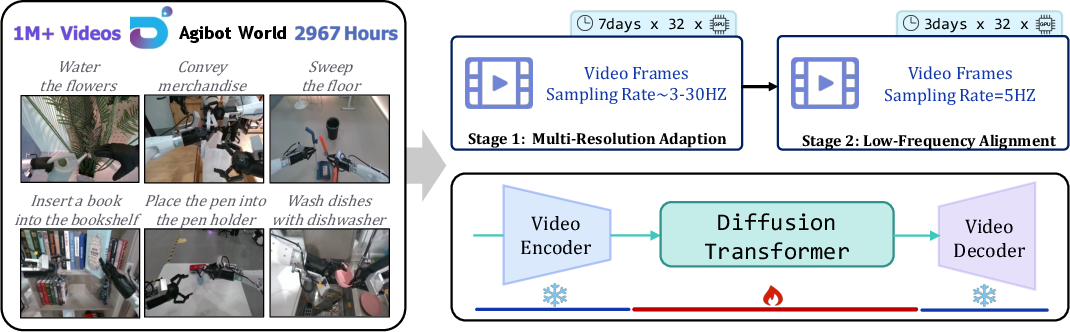
Figure 3: GE-Base Training Process, showing domain adaptation and fine-tuning stages on large-scale, real-world robotic data.
GE-Base demonstrates strong generalization in generating instruction-aligned, temporally coherent, and spatially consistent multi-view videos across diverse manipulation tasks and embodiments.

Figure 4: Multi-view robotic manipulation videos generated by GE-Base, reflecting accurate spatial and temporal alignment with language instructions.
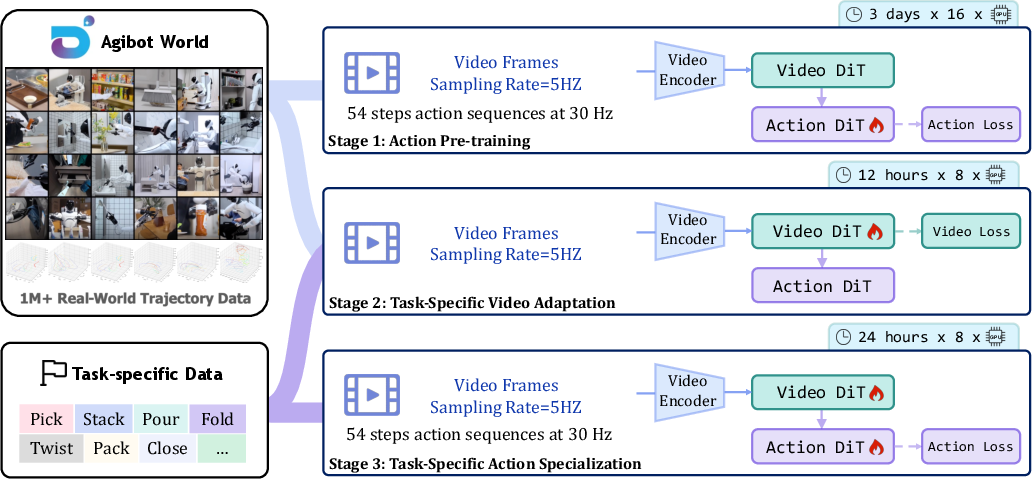
GE-Act: World Action Model
GE-Act extends GE-Base by introducing a parallel action branch that transforms visual latent representations into structured action policy trajectories. The architecture mirrors the DiT block depth of GE-Base but reduces hidden dimensions for efficiency. Visual features are integrated into the action pathway via cross-attention, and final action predictions are generated using a diffusion-based denoising flow-matching pipeline.
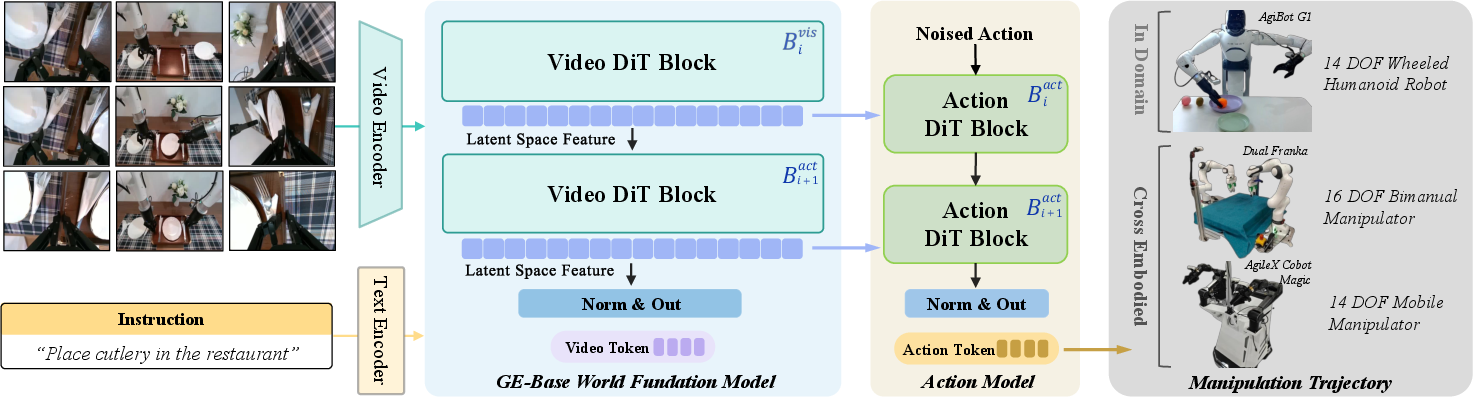
Figure 5: Overview of the GE-Act World Action Model, highlighting the parallel action branch and cross-attention integration.
The training procedure consists of:
GE-Act achieves low-latency, end-to-end control, generating 54-step torque trajectories within 200 ms on commodity GPUs. It outperforms state-of-the-art VLA baselines on both in-domain and cross-embodiment tasks, demonstrating robust generalization with minimal adaptation data.
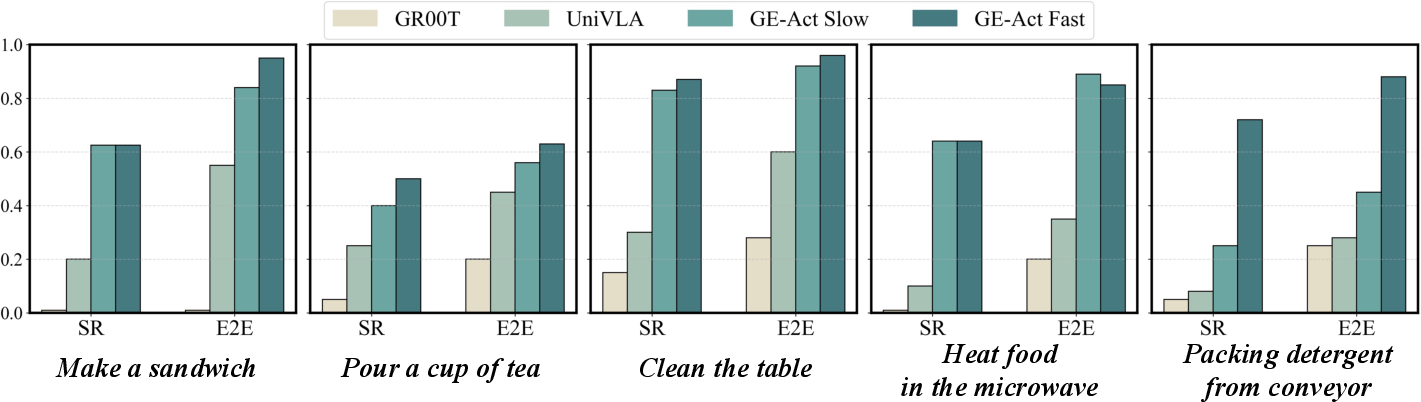
Figure 7: Task-specific real-world robotic manipulation performance comparison on AgiBot G1, showing GE-Act's superior SR and E2E metrics.

Figure 8: Real-world robotic manipulation on AgiBot G1 via GE-Act, illustrating consistent and contextually appropriate behaviors.
Cross-Embodiment Generalization
GE's architecture supports rapid adaptation to novel robotic embodiments through a two-stage fine-tuning protocol: visual generative adaptation and action head retraining. Empirical results on Agilex Cobot Magic and Dual Franka platforms, using only one hour of teleoperated demonstrations, show that GE-Act significantly outperforms leading VLA models, especially in complex, fine-grained deformable object manipulation tasks.

Figure 9: Real-world demonstration of GE-Act on Agilex Cobot Magic, executing complex manipulation with minimal adaptation data.

Figure 10: Multi-view video generation on Agilex Cobot Magic by GE-Base for complex folding tasks.

Figure 11: Real-world demonstrations with GE-Act on Agilex Cobot Magic, including cloth-folding and box-folding.

Figure 12: Robotic video generation and real-world manipulation on Dual Franka via GE.
GE-Sim: World Simulator
GE-Sim repurposes GE-Base as an action-conditioned video generator, enabling closed-loop policy evaluation and controllable data generation. The simulator incorporates a hierarchical action-conditioning mechanism, fusing spatial pose and temporal motion deltas into the video generation process. This design supports high-fidelity, action-aligned video rollouts, facilitating scalable policy training and evaluation.
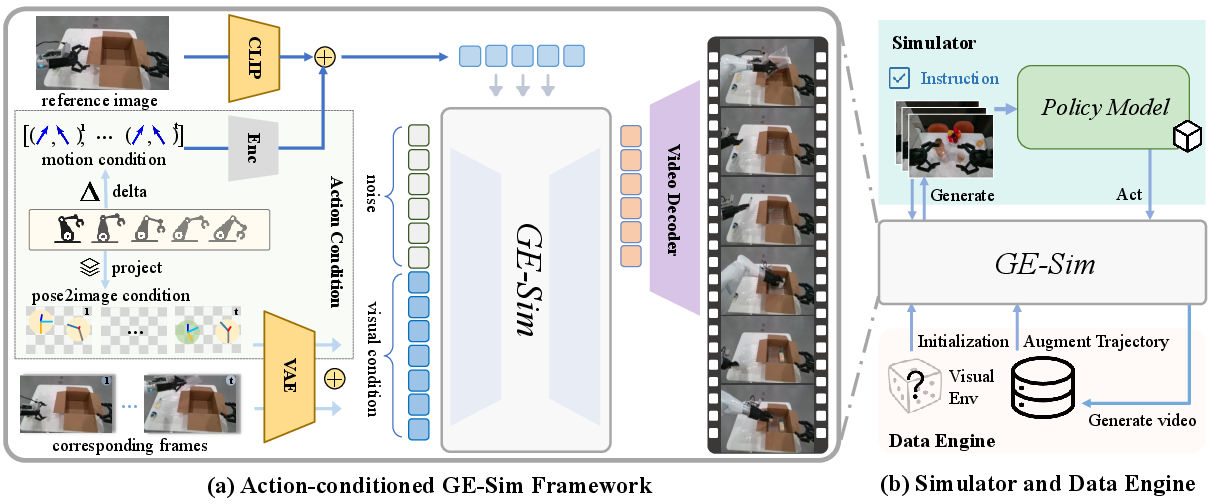
Figure 13: Overview of the GE-Sim World Simulator, showing action-conditioned video generation and closed-loop policy evaluation.

Figure 14: Action-conditioned video generation by GE-Sim, visualizing spatial alignment between projected action targets and predicted frames.
EWMBench: Embodied World Model Benchmark
EWMBench provides a comprehensive evaluation suite for video-based world models in robotic manipulation, measuring scene consistency, action trajectory quality, and motion semantics. The benchmark dataset is curated for diversity and task coverage, and the evaluation metrics are designed to reflect spatial, temporal, and semantic fidelity.
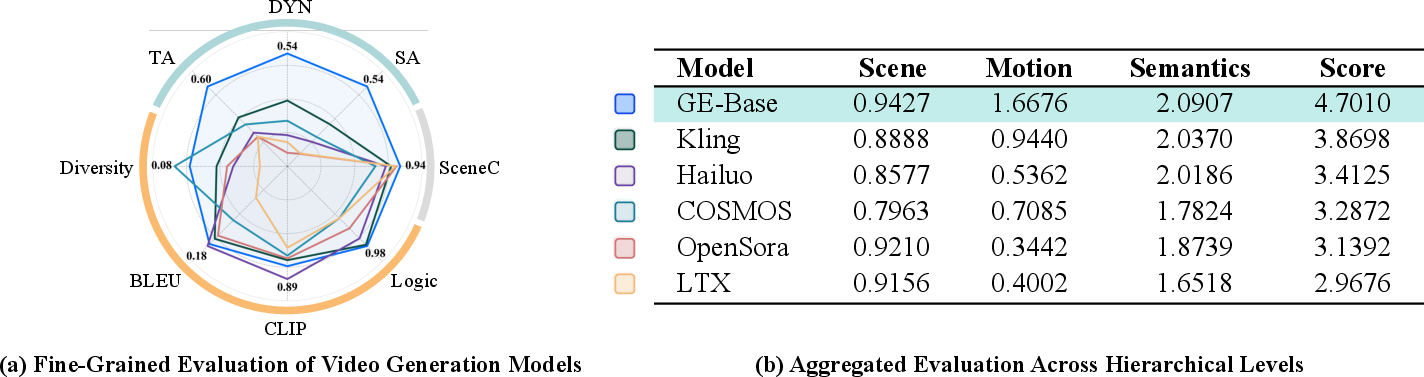
Figure 15: Comprehensive evaluation of video world models for robotic manipulation using EWMBench, comparing GE-Base with state-of-the-art baselines.
EWMBench demonstrates strong alignment with human preference ratings, outperforming general video benchmarks in capturing task-relevant dimensions of quality.
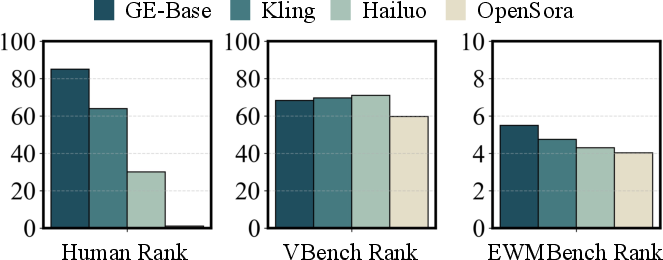
Figure 16: Consistency and validity analysis of evaluation metrics, showing high concordance between EWMBench and human judgments.
Limitations
Despite its strengths, Genie Envisioner is limited by its reliance on a single large-scale real-world dataset, restricting embodiment and scene diversity. The current focus is on upper-body, parallel-jaw gripper manipulation, with dexterous and full-body tasks remaining unaddressed. Evaluation protocols, while comprehensive, still depend on proxy metrics and partial human validation, highlighting the need for more robust, automated assessment methods.
Conclusion
Genie Envisioner establishes a unified, scalable foundation for instruction-driven, general-purpose embodied intelligence in robotic manipulation. The integration of high-fidelity video world modeling (GE-Base), efficient action policy inference (GE-Act), and closed-loop simulation (GE-Sim), evaluated through a rigorous benchmark (EWMBench), enables robust policy learning, rapid cross-embodiment adaptation, and reliable evaluation. The platform's empirical results demonstrate superior performance and generalization compared to existing baselines, positioning it as a practical basis for future research in embodied AI. Future work should address data diversity, embodiment scope, and evaluation automation to further advance the capabilities of world foundation models for robotics.