- The paper introduces Rollout Routing Replay (R3) to align training and inference routers in MoE RL, significantly reducing instability.
- It demonstrates reduced KL divergence and token discrepancies, validating the method using models like Qwen3-30B-A3B.
- The R3 technique stabilizes both on-policy and off-policy RL training without extra computational overhead, paving the way for robust MoE models.
Stabilizing Reinforcement Learning with Mixture-of-Experts by Aligning Routers
The paper "Stabilizing MoE Reinforcement Learning by Aligning Training and Inference Routers" explores stabilizing reinforcement learning (RL) in Mixture-of-Experts (MoE) models by proposing a technique known as Rollout Routing Replay (R3). This approach resolves significant discrepancies in expert routing behavior between training and inference phases, which can lead to RL training instability and potential collapse.
Introduction
Reinforcement learning serves as a critical means to enhance LLMs by post-training them to solve complex tasks, such as advanced mathematical reasoning and practical coding tasks. A critical challenge faced in this context is ensuring the stability of RL training, particularly in MoE models, where distinct routing mechanisms during training and inference introduce variations that jeopardize overall system robustness. Existing solutions, such as importance sampling and specialized kernels, fail to address the fundamental source of this instability in MoE models—the routing distribution.
Rollout Routing Replay (R3)
The core contribution of the paper is the Rollout Routing Replay method, which addresses the root cause of routing-induced instability in MoE RL. The R3 technique records routing distributions at inference time and replays them during training, thereby aligning router behavior across both phases. This alignment significantly reduces the KL divergence between training and inference policies and minimizes token discrepancy.
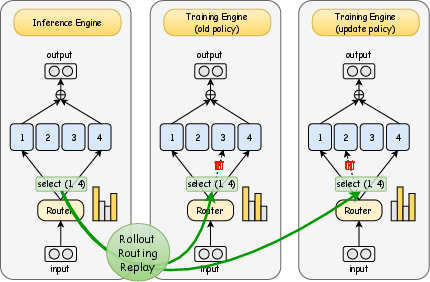
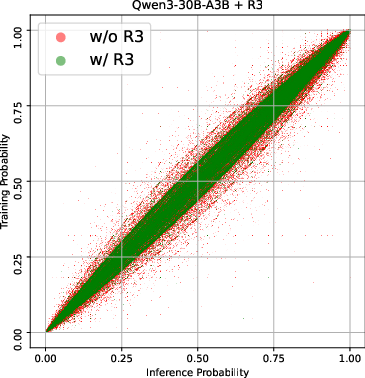
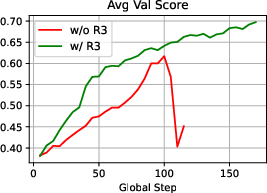
Figure 1: Illustration of the Rollout Routing Replay (R3) and its effect on training and inference discrepancies.
The process leverages cached routing masks, making R3 compatible with multi-turn dialogue tasks and prefix caching strategies used in agent tasks, which is crucial for maintaining efficient computation in large-scale models.
Training-Inference Discrepancies in MoE Models
The paper provides an in-depth analysis of discrepancies between training and inference in MoE frameworks. These discrepancies, largely attributable to dynamic expert selection by routers, result in output variability that exceeds that seen in dense models.
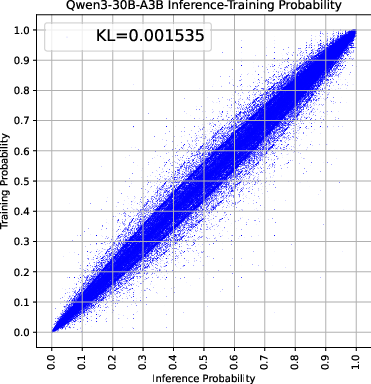
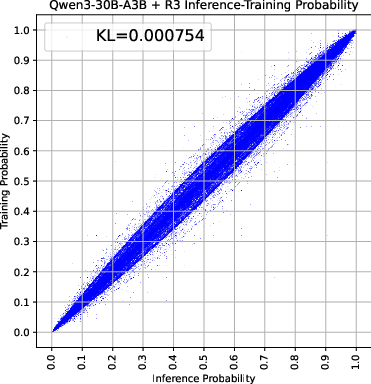
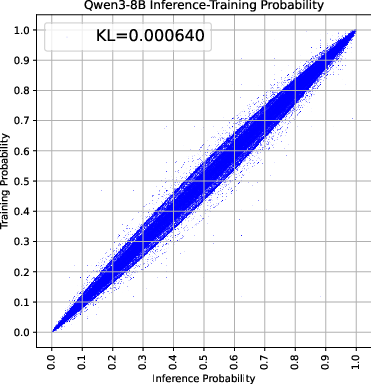
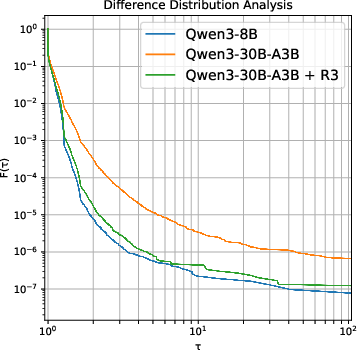
Figure 2: Analysis of training-inference collapse showing the estimated KL divergence and extreme token distribution.
Through empirical analysis using models such as Qwen3-30B-A3B, the researchers demonstrate that MoE models exhibit larger training-inference discrepancies than dense models due to routing inconsistencies. This phenomenon is further quantified using KL divergence and extreme token distribution metrics.
Experimental Results
To gauge R3’s efficacy, the authors conducted experiments where the method was integrated into various RL scenarios involving MoE models. The findings were compelling:
- R3 significantly stabilized training processes, preventing model collapse and improving overall performance when compared with existing methods such as GSPO and TIS.
- It demonstrated robustness across both on-policy and mini-batch style off-policy RL scenarios, surpassing dense model stability without added computational overhead.
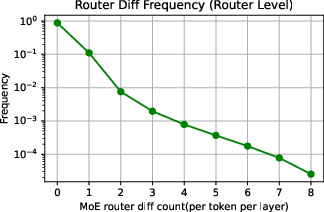
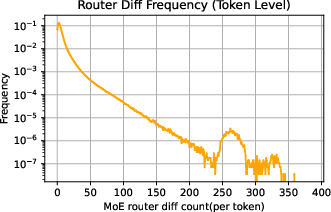
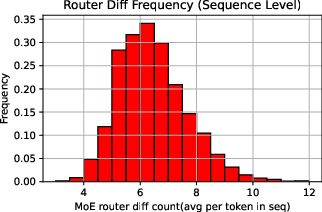
Figure 3: Training dynamics of the Qwen3-30B-A3B-Base model showing response length, gradient norm, entropy, and average validation score.
The reduction in training-inference discrepancies through R3 was also visually confirmed through scatter plots and extreme token distribution analyses, showcasing an order of magnitude decrease in routing disparities.
Conclusion
The presented work identifies routing discrepancies as the primary instability source in MoE RL frameworks and introduces R3 as an effective countermeasure by reusing inference routing information during training. This technique mitigates instability issues and enhances training performance, offering a viable pathway for achieving robustness in MoE-based reinforcement learning systems.
The implications of this research extend beyond immediate performance gains, paving the way for more reliable deployment of LLMs in complex environments. Future work could explore further optimizations and applications of the R3 technique to other architectures and domains, potentially broadening its scope and utility.

