- The paper provides a comprehensive survey of reinforcement learning methods to enhance LLM outputs using both human and AI feedback.
- It categorizes key approaches, including RLHF, RLAIF, and DPO, detailing their frameworks and impact on model alignment.
- It highlights current challenges and future research directions in scaling and stabilizing reinforcement learning for LLMs.
Reinforcement Learning Enhanced LLMs: A Survey
Reinforcement learning (RL) has become a cornerstone technique for enhancing LLMs to improve the quality and alignment of their outputs. The paper "Reinforcement Learning Enhanced LLMs: A Survey" provides a comprehensive review of the field, addressing the use of RL techniques to optimize LLM performance and align models with human preferences. The survey categorizes key methods, models, and challenges in applying RL to LLMs.
Introduction to LLM and RL Alignment
LLMs are sophisticated LLMs pre-trained on vast textual data, capable of generating human-like responses across diverse applications. However, they sometimes produce outputs that may not align with human preferences in terms of relevance, coherence, or factual accuracy. The alignment of LLM outputs with human preferences is thus crucial for effective deployment in real-world applications.
Previously, supervised fine-tuning (SFT) was used to align LLM interactions using (Instruction, Answer) pairs. Despite its benefits, this approach has limitations, notably in its ability to generalize to tasks with multiple valid phrasings and in incorporating direct human feedback.
To overcome these limitations, RL can be employed for aligning LLM outputs through an iterative learning process where models receive rewards based on human or AI feedback, driving improvements in model behavior.
Basics of Reinforcement Learning for LLMs
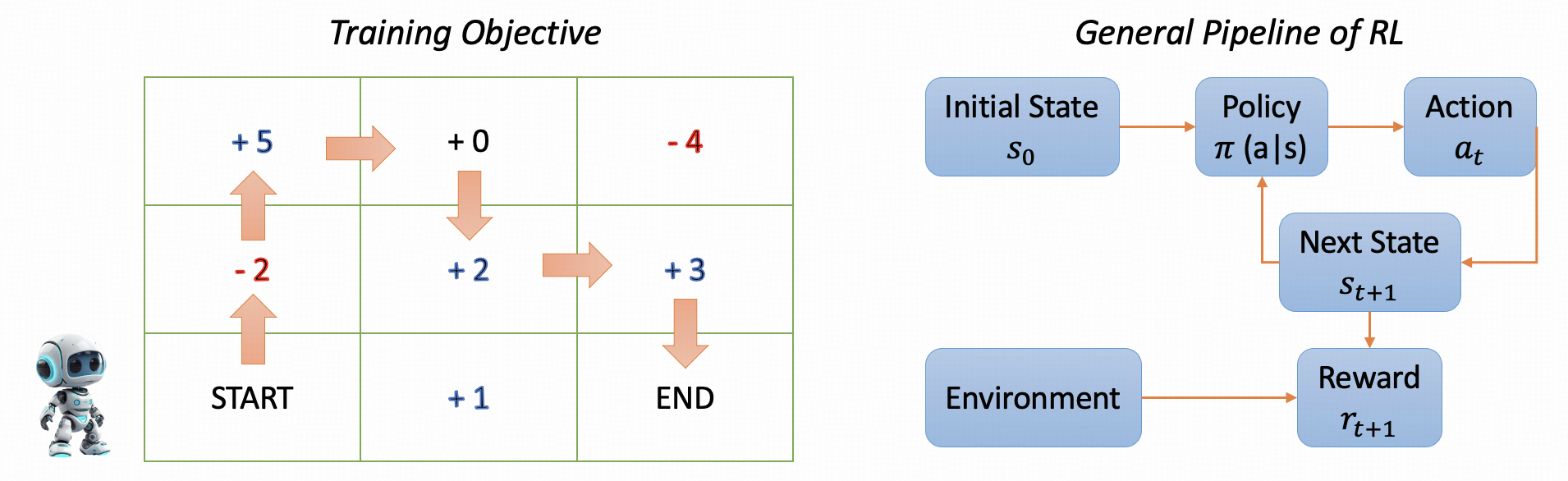
Figure 1: An example of the full process of RL. Training Objective: The goal is to train a robot to navigate from the bottom-left corner of a square to the top-right corner.
Reinforcement learning involves training an agent to engage with its environment to maximize cumulative rewards. Key components of RL include the agent, environment, state, action, reward, and policy. By mapping these components onto the LLM framework, the agent (LLM) can generate actions (tokens), transitioning through states (text sequences) while optimizing based on rewards calculated by a reward model.
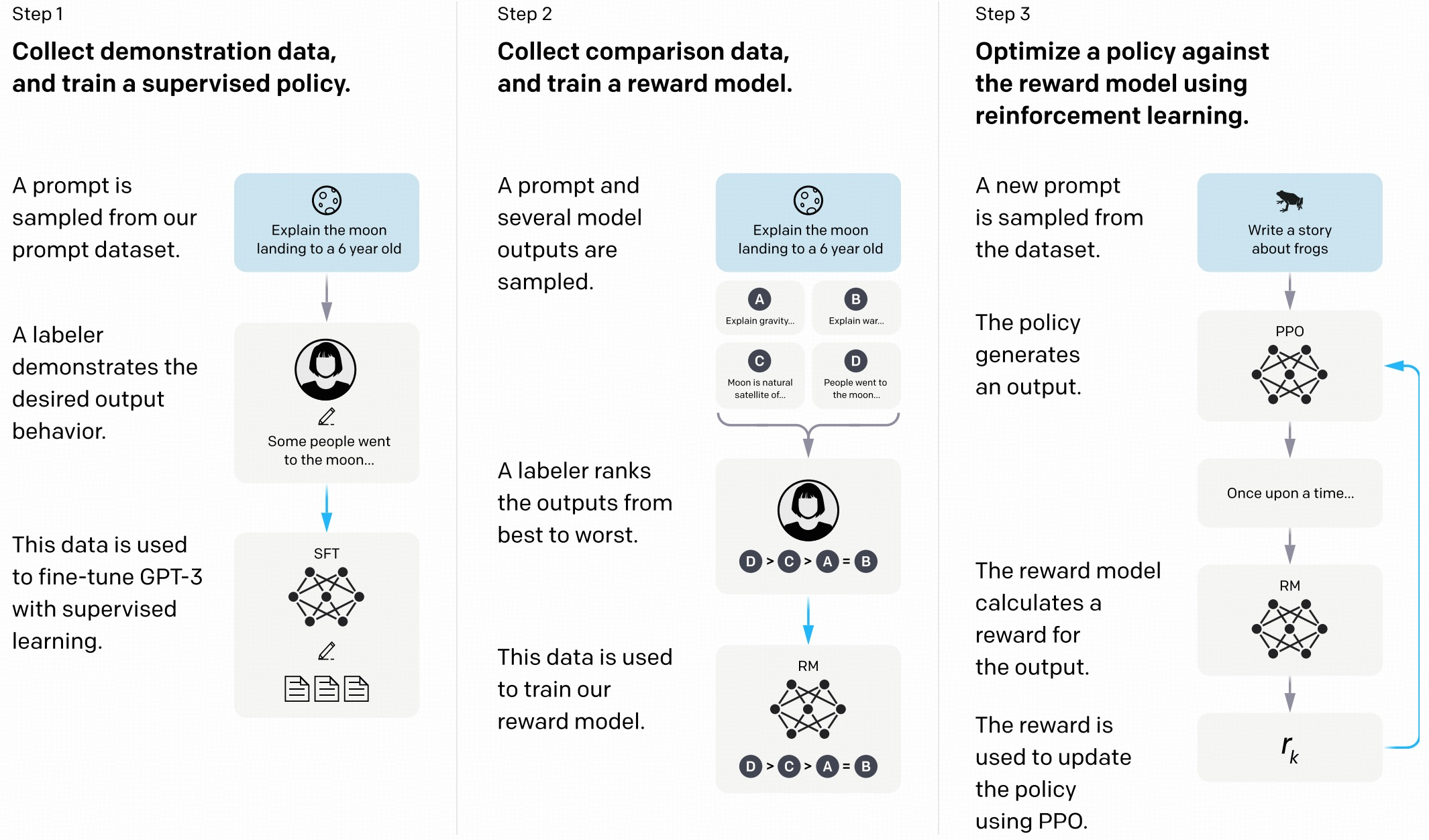
Figure 2: The framework of RL for LLMs proposed by \newcite{ouyang2022training}.
Ouyang et al. proposed a structured RL framework for LLMs that consists of a reward model trained on human feedback to score outputs, followed by policy optimization using PPO to improve the LLM's alignment with human preferences.
Popular RL-Enhanced LLMs
The survey explores a set of RL-enhanced LLMs, categorized into traditional RL approaches like RLHF and RLAIF, and newer methods like DPO. These models show that reinforcement learning is indispensable for enhancing their alignment:
- InstructGPT employs RLHF to leverage human feedback for refining model outputs to better align them with human expectations.
- GPT-4 integrates RLHF and rule-based reward models to refine its large multimodal model.
- Claude 3, with RLAIF, offers a promising alternative to human feedback, using AI systems for scalable, consistent alignment.
Each model demonstrates specific adaptations of RL techniques, showcasing various strategies to enhance alignment, reduce biases, and improve interpretability.
Reinforcement Learning from Human Feedback (RLHF)
RLHF involves training LLMs with feedback from humans, using reward models to optimize alignment. The process typically comprises collecting human annotations and using them to guide policy optimization.
The paper reviews models such as Skywork-Reward and HelpSteer2 datasets, which provide high-quality human preferences data enabling efficient RLHF implementations. These datasets help align LLMs with nuanced human feedback, enhancing their effectiveness across diverse tasks.
The iterative rewarding and policy optimization of LLM outputs allows models to refine their behavior systematically according to human preferences, leading to more desirable outputs.
Reinforcement Learning from AI Feedback (RLAIF)
RLAIF is an emerging alternative to human feedback, using AI systems to provide feedback for LLM alignments. The method mitigates scalability and consistency issues inherent in human-driven alignment.
Examples include using established LLMs to synthesize training data or prompt them as evaluators in RL processes. Eureka generates and refines reward functions autonomously, while GenRM redefines reward production through generative processes instead of discriminative modeling.
Direct Preference Optimization (DPO)
DPO simplifies the alignment process by directly utilizing human preference data without relying on reward models. This bypass reduces complexity while still achieving effective preference-based optimization.
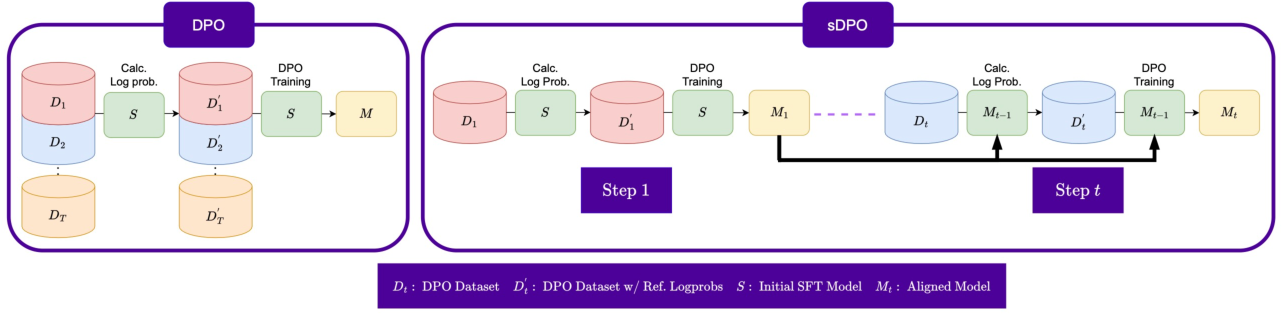
Figure 3: Overview of sDPO where preference datasets are divided to be used in multiple steps.
Recent advancements such as sDPO, which partitions preference datasets for iterative training, offer stable improvement paths by refining alignment progressively. Also, variants of DPO suggest further refinements for aligning models stably and efficiently.
Conclusion
The survey of reinforcement learning enhanced LLMs provides a detailed overview of current practices, popular models, associated methods, and emerging techniques in aligning LLMs with human preferences. By addressing challenges and exploring diverse RL approaches, the paper outlines potential paths for future work in this rapidly evolving field. As models become increasingly powerful, continued research into aligning their outputs with human expectations using RL remains crucial for safe and effective AI deployment.

