- The paper demonstrates that iterative synthetic data generation can significantly improve the finetuning of small language models under constrained data budgets.
- It introduces an active learning-based closed-loop sampling strategy that prioritizes challenging samples based on student loss and uncertainty.
- Experimental results across mathematical and logical reasoning tasks show increased data efficiency and enhanced model performance.
Detailed Summary of "Towards Active Synthetic Data Generation for Finetuning LLMs" (2512.00884)
The paper "Towards Active Synthetic Data Generation for Finetuning LLMs" addresses the practical challenges associated with improving the capabilities of small LLMs (SLMs) by utilizing synthetic data generated iteratively from larger teacher models. This approach contrasts with static synthetic dataset generation and showcases how iterative methods can enhance student performance under constrained data generation budgets.
Introduction to Synthetic Data Generation in LLMs
LLMs have demonstrated proficiency across various domains, yet their computationally intensive nature poses significant challenges, particularly in real-time inference. Small LLMs are posited as viable alternatives that are more efficient while still offering customization potential through finetuning. Finetuning, especially using synthetic data, typically focuses on supervised fine-tuning (SFT) which is critical for adapting models to specific task distributions efficiently.
Methodologies: Iterative Synthetic Data Generation
The paper introduces a closed-loop, iterative synthetic data generation process that tailors the generation of new data samples dependent on the current state of the student model. The central hypothesis is that iterative refinement via active data selection strategies from the active learning domain outperforms static, volume-intensive synthetic data generation.
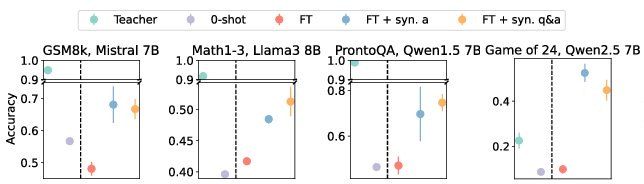
Figure 1: SFT performance on 1k data points for various datasets and SLMs. We compare the effect of synthetic answer generation and synthetic question and answer generation to using the seed dataset, D0, for SFT. 0-shot SLM and teacher performances are included for reference.
Experimental Framework
The research validates its core methodologies across four datasets focused on mathematical and logical reasoning, employing distinct small LLMs as students. By incrementally integrating synthetic data generated through iterative loops and evaluating different selection algorithms rooted in active learning, the proposed approach successfully demonstrates increased data efficiency.
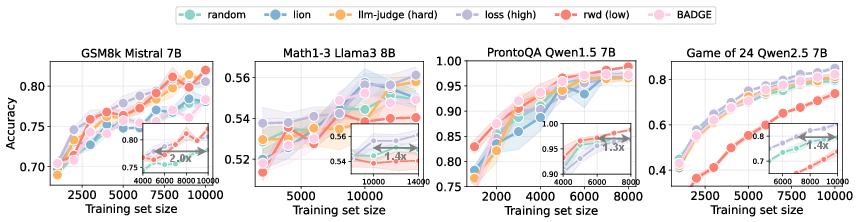
Figure 2: Student performance over successive synthetic data iterations with growing training sets. Each inset plot shows the proportion of data random sampling requires for the same performance as the best active scorers for synthetic data generation.
Results and Discussion
The results consistently indicate that iterative synthetic data generation, guided by metrics that assess the student model's current performance, leads to more efficient learning trajectories than static data generation. Algorithms prioritizing "hard" samples based on student loss and uncertainty demonstrate superior performance across multiple LLM configurations and datasets.
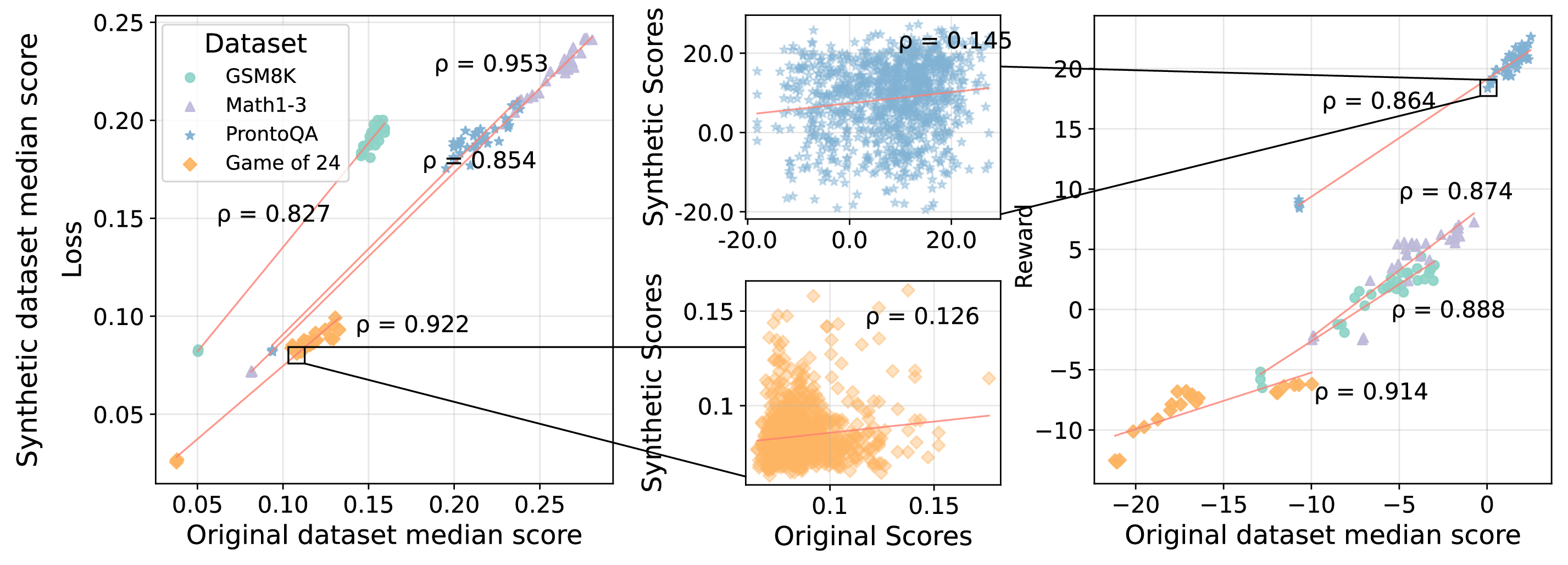
Figure 3: The rank correlations between original and synthetic dataset scores from iterative synthetic data generation. We plot student loss and reward scores and show Spearman's rank correlations (ρ) between dataset medians before and after synthetic data generation.
Implications and Future Directions
The implications for AI at large are profound: the integration of active learning principles into data generation not only enhances training efficiency but also offers scalable pathways for improving models without large-scale data acquisition costs. The distinct advantage of iterative synthetic data generation lies in its capacity to dynamically adapt training resources to model needs, potentially revolutionizing finetuning paradigms for SLMs and beyond.
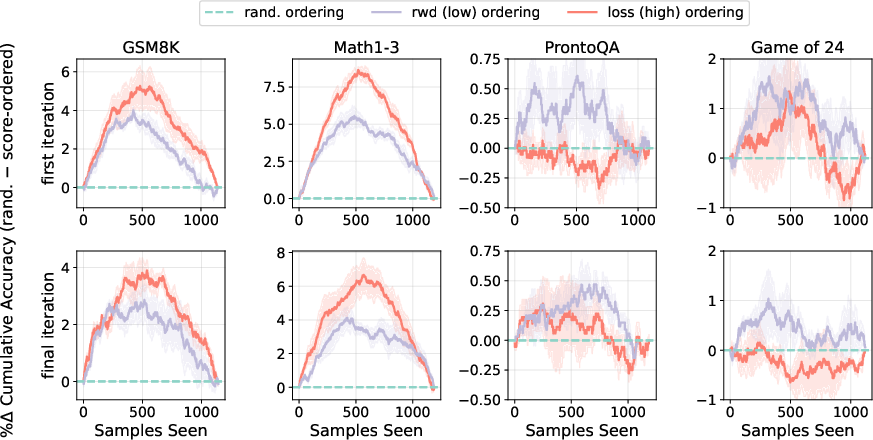
Figure 4: The percentage difference in synthetic data cumulative accuracy when using random sampling minus score ordering: high to low loss and low to high reward.
Conclusion
The study provides an extensive analysis of integrating iterative synthetic data generation methods with active learning principles. By leveraging these strategies, synthetic datasets achieve enhanced outcomes in terms of data efficiency and performance. Future exploration may deepen understanding of synthetic data properties and further refine selection mechanisms to harness full potential of finetuning approaches. The work highlights a pathway for fostering more intelligent, adaptive, and efficient AI systems using personalized data generation strategies.