AlphaResearch: Accelerating New Algorithm Discovery with Language Models
Abstract: LLMs have made significant progress in complex but easy-to-verify problems, yet they still struggle with discovering the unknown. In this paper, we present \textbf{AlphaResearch}, an autonomous research agent designed to discover new algorithms on open-ended problems. To synergize the feasibility and innovation of the discovery process, we construct a novel dual research environment by combining the execution-based verify and simulated real-world peer review environment. AlphaResearch discovers new algorithm by iteratively running the following steps: (1) propose new ideas (2) verify the ideas in the dual research environment (3) optimize the research proposals for better performance. To promote a transparent evaluation process, we construct \textbf{AlphaResearchComp}, a new evaluation benchmark that includes an eight open-ended algorithmic problems competition, with each problem carefully curated and verified through executable pipelines, objective metrics, and reproducibility checks. AlphaResearch gets a 2/8 win rate in head-to-head comparison with human researchers, demonstrate the possibility of accelerating algorithm discovery with LLMs. Notably, the algorithm discovered by AlphaResearch on the \emph{``packing circles''} problem achieves the best-of-known performance, surpassing the results of human researchers and strong baselines from recent work (e.g., AlphaEvolve). Additionally, we conduct a comprehensive analysis of the remaining challenges of the 6/8 failure cases, providing valuable insights for future research.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview of the Paper
This paper introduces AlphaResearch, an AI “research agent” that tries to invent new algorithms—step-by-step, like a scientist—using LLMs. The goal is to see whether AI can go beyond solving known problems and actually discover better ways to solve open-ended challenges, sometimes even beating the best solutions humans have found so far.
Key Objectives or Questions
The authors set out to answer simple but big questions:
- Can AI discover genuinely new algorithms, not just repeat what’s already known?
- How can we reliably check if an AI’s research ideas are both creative and practical?
- What kind of testing setup (like a competition) would fairly compare AI versus human researchers?
How Did the Researchers Do It?
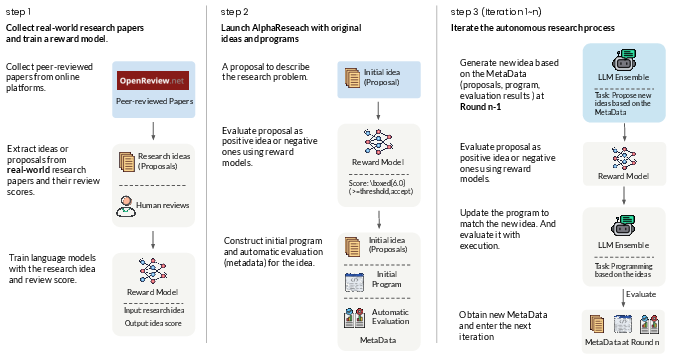
To make AI discovery both creative and trustworthy, they built a “dual research environment.” Think of it like a science fair with two judges:
- A simulated peer-review “judge” (like real scientists reviewing papers):
- They trained a “reward model” using thousands of real peer reviews from ICLR (a top AI conference).
- This model gives a score to each idea based on qualities like novelty, relevance, and likely impact.
- It helps filter out ideas that sound cool but aren’t realistic.
- A code execution “judge” (like a referee checking the rules and score):
- The AI writes code for its idea.
- The code is run automatically to check two things:
- Does it follow the rules of the problem?
- How well does it perform according to a clear score?
AlphaResearch works in a loop, similar to how you’d improve a school project:
- Propose a new idea.
- Check if the idea is promising using the peer-review model.
- If it passes, write or update code for the idea.
- Run the code and see how well it scores.
- Keep the best results and repeat until it beats the human-best or runs out of time.
To compare AI and humans fairly, they built a public benchmark called AlphaResearchComp:
- It includes 8 open-ended algorithm problems from areas like geometry and number theory.
- Each problem has a well-defined scoring rule and a “human-best” result from the literature.
- Everything is checked automatically for fairness and reproducibility.
Main Findings and Why They Matter
Here are the key results, explained simply:
- AlphaResearch beat human-best results on 2 out of 8 problems.
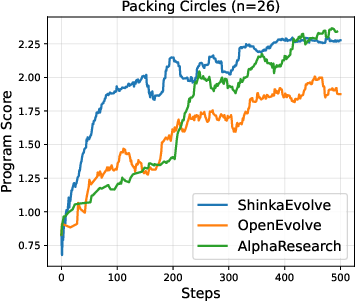
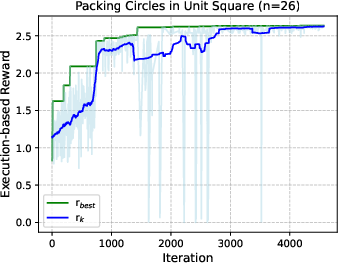
- Most notably, it set new records on the “Packing Circles” problem:
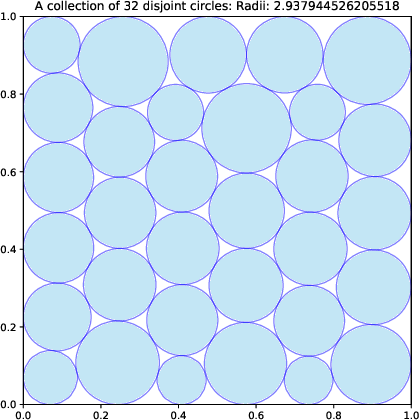
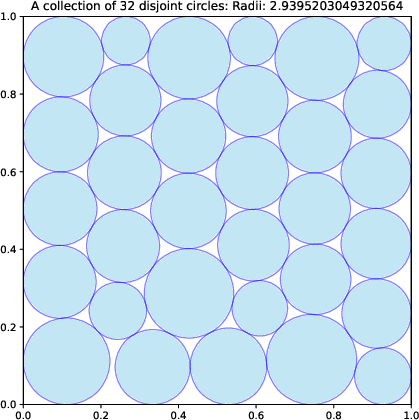
- For 26 circles, it improved the best-known result.
- For 32 circles, it achieved the best-of-known performance worldwide.
- “Packing Circles” means fitting n circles inside a square so the total size (sum of radii) is as large as possible. Imagine arranging coins in a box to fit the biggest total size without overlapping—they found smarter arrangements.
- The peer-review reward model worked well:
- Trained on real conference reviews, it correctly classified good vs. not-so-good ideas about 72% of the time on new data, better than humans in their test and other baseline models.
- In practice, it filtered out many ideas that would later fail when implemented, saving time and focusing effort.
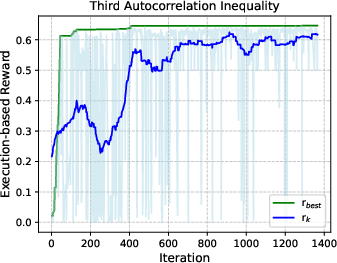
- The process steadily improved results over time:
- In most problems, the execution score climbed as the agent iterated ideas and code, showing it can “learn” and refine just like a researcher.
- But there are limits:
- On 6 problems, AlphaResearch could not beat the human-best.
- When starting from already excellent human solutions (like Littlewood polynomials and MSTD), it often couldn’t find better ones—suggesting current AI still struggles with pushing past very strong human work.
These results matter because they show that:
- AI can sometimes invent better algorithms than humans.
- Combining “creative idea scoring” (peer review) with “hard checks” (code execution) balances imagination and practicality.
- Transparent, well-defined benchmarks help track real progress.
Methods Explained in Everyday Language
- Algorithm: A step-by-step recipe for solving a problem.
- LLM: An AI that reads and writes text; here, it generates research ideas and code.
- Reward Model: A trained AI “judge” that gives a score to ideas, similar to reviewers grading a science fair project.
- Execution-based verification: Running the code to make sure it follows rules and to measure how well it works—like testing a robot you built to see how fast it completes a maze.
An analogy: Imagine designing a new video game strategy.
- The peer-review model is like a coach telling you whether your strategy is promising.
- The code executor is like actually playing the game with your strategy to see your score.
- AlphaResearch keeps proposing strategies, checks them with the coach, tries them in the game, and keeps the best one, repeating until it’s better than anyone else’s.
Implications and Potential Impact
- Accelerating discovery: AI could help scientists and engineers explore more ideas quickly, filter out weak ones, and implement the promising ones—speeding up progress.
- Better research tools: Training reward models on real reviews brings “human-like taste” to AI, guiding it toward meaningful ideas rather than just flashy ones.
- Real-world applications: In the future, similar methods could optimize things like chip design, scheduling, network routing, or fast math routines (tensor computations), where tiny improvements matter a lot.
- Next steps: The authors suggest using bigger and better reward models, adding more tools, and tackling more complex problems to push AI discovery further.
In short, AlphaResearch shows a practical way for AI to act like a researcher: think of new ideas, judge them like experts, test them with code, and steadily improve—sometimes beating the best humans, and often learning from failure.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes what remains missing, uncertain, or unexplored, and suggests concrete directions future researchers could act on:
- Dual-reward design is under-specified: the paper does not formalize how peer-review reward and execution-based reward are combined, weighted, or scheduled over time. Provide a principled framework (e.g., multi-objective optimization, adaptive weighting, or bandit-style scheduling) and ablate thresholds/weights on discovery rate and final performance.
- Domain mismatch in the reward model (RM): AlphaResearch-RM-7B is trained on ICLR ML peer-review records but used to filter ideas in mathematical/algorithmic tasks (geometry, number theory). Quantify and mitigate cross-domain misalignment (train domain-specific RMs, perform cross-domain calibration, or use task-specific review corpora).
- RM input signal is limited: training uses only paper abstracts and the average overall rating. Evaluate the impact of richer inputs (full reviews, per-criterion scores like novelty/significance/correctness, rebuttals, meta-reviews) on filtering quality and discovery outcomes.
- RM evaluation is narrow: reported binary accuracy at a fixed 5.5 threshold, with no calibration, ROC/AUC, reliability, or error structure analyses. Report calibration curves, correlation with downstream execution success, precision/recall at multiple thresholds, and inter-annotator agreement baselines.
- False negatives from RM are nontrivial: 43 viable ideas were rejected by RM in one ablation. Investigate adaptive thresholds, exploration–exploitation strategies, ensembling, or uncertainty-aware acceptance to reduce rejection of promising ideas while keeping failure rates low.
- Execution environment details are insufficient: verification and measurement modules, numerical tolerances, randomness control (seeds), and robustness checks are not fully documented. Provide formal specifications, determinism guarantees, and sensitivity analyses to ensure reproducibility and fairness across agents.
- Code execution safety is not addressed: there is no description of sandboxing, resource limits, or security policies when running LLM-generated code. Document isolation mechanisms, time/memory quotas, and safe I/O to prevent exploits and ensure consistent evaluation.
- Agent sampling and credit assignment are opaque: the policy for sampling prior trajectory states
(i_t, p_t, r_t)is unspecified (e.g., uniform, prioritized replay, or performance-weighted). Ablate sampling strategies and study their impact on convergence speed and final outcomes. - Compute budgets and fairness across baselines are unclear: comparisons (e.g., with OpenEvolve/ShinkaEvolve) lack standardized compute/tokens/iterations and use a proprietary model (
o4-mini). Report per-task budgets, iteration counts, token usage, wall-clock time, and hardware; match budgets for fair head-to-heads. - Benchmark scope is small (8 tasks) and improvements are marginal in several cases: expand problem set, include difficulty tiers, diverse domains (discrete/combinatorial, continuous optimization, formal proofs), and measure scalability to harder/realistic tasks.
- Human-best baselines may be outdated or unverified: the paper relies on literature/online repositories for “best-of-human” values without independent validation. Establish a community-reviewed baseline registry, reproduce baselines in the same environment, and track updates over time.
- The
excel@bestmetric is ill-defined in the paper (malformed equation and unclear indicator semantics): formally define the metric, directionality, normalization, and aggregation; report aggregate statistics with confidence intervals and significance testing. - Generalization of discovered “algorithms” is untested: results appear instance-specific (e.g., circle packing at n=26/32). Evaluate whether discovered methods generalize across parameter sweeps (vary n, dimensionality), adjacent problem families, and unseen tasks.
- Initialization sensitivity is not analyzed: starting from scratch vs. starting from best-known solutions likely affects exploration and outcomes. Systematically ablate initialization strategies and quantify their effect on trajectory and final performance.
- Contribution of the peer-review RM across tasks is only shown in one ablation: conduct broader ablations to measure RM’s effect on sample efficiency, success rate, and final scores across all benchmark tasks.
- Idea-to-code translation mechanics are underspecified: how are ideas converted into patches? What edit operations, tools, or verification scaffolds are used? Detail patching protocols, diff strategies, test scaffolding, and error-repair loops; ablate these components.
- Human-in-the-loop settings are unexplored: assess whether occasional human feedback (e.g., on RM errors or feasibility checks) improves discovery, and quantify cost–benefit versus fully autonomous operation.
- Lack of theoretical insight: discovered solutions are reported as performance numbers without formal analysis (e.g., invariants, convergence guarantees, or proofs of optimality). Provide post-hoc characterization, derive heuristics or structural properties, and explore formal certification.
- RM bias and fairness are not audited: ML review-trained RM may favor specific writing styles, topics, or conventional framing, penalizing unconventional mathematical ideas. Audit for domain/style biases and implement debiasing or diversity-promoting mechanisms.
- RM scaling laws and data composition effects are not studied: explore how model size, training data size, and data heterogeneity affect RM accuracy and downstream discovery; perform controlled scaling-law experiments.
- External validation of “best-of-known” claims is missing: solicit domain-expert verification (e.g., circle packing community), replicate results in independent implementations, and submit findings to peer-reviewed venues for validation.
- No multi-objective optimization framework: novelty, feasibility, and performance are treated via a single gate plus execution reward. Develop Pareto-front optimization, composite rewards with tunable trade-offs, and learning-to-rank strategies to balance competing objectives.
- Handling partially feasible/non-executable ideas is simplistic (skip-on-fail): investigate idea salvage strategies (decomposition, scaffolding, iterative refinement), and measure recovery rates and downstream impact.
- Failure-case analysis is claimed but not detailed in the main text: provide a systematic taxonomy of the 6/8 failures, root-cause analyses (RM errors, execution brittleness, search stagnation), and tested mitigations with quantified effects.
- Reproducibility details are incomplete: random seeds, environment versions, dependency management, and deterministic pipelines are not fully specified. Release comprehensive reproducibility artifacts and reproducibility reports.
- Ethical considerations and attribution are absent: discuss risks of generating misleading “algorithms,” attribution to prior work, and policies for claims of novelty; implement plagiarism/duplication checks and disclosure practices.
- Limited comparison with AlphaEvolve/ShinkaEvolve: the comparison is restricted to one task and early steps; problems sets are not aligned. Conduct matched, multi-task head-to-head evaluations with equal budgets and standardized environments.
- Stopping criteria and convergence are heuristic (max rounds n): investigate principled stopping rules (e.g., plateau detection, statistical improvement tests), anytime performance tracking, and convergence diagnostics.
- Integration with external tools is only suggested: evaluate the impact of incorporating theorem provers, mathematical optimization libraries, specialized solvers, and search heuristics; quantify gains and identify best synergies.
Practical Applications
Practical Applications Derived from the Paper
The following applications translate AlphaResearch’s findings and innovations—its dual research environment (peer-review-trained reward model plus execution-based verification), the AlphaResearchComp benchmark, and demonstrated algorithmic improvements—into actionable use cases across industry, academia, policy, and daily life. Each item notes sector(s), potential tools/products/workflows, and assumptions/dependencies that affect feasibility.
Immediate Applications
- Autonomous algorithm improvement in production software
- Sectors: software, HPC, ML systems
- Use case: Automatically propose, filter, implement, and evaluate algorithmic patches for performance-critical code paths (e.g., sorting, graph ops, numerical kernels) within CI/CD.
- Tools/Products/Workflows: “Idea-to-Patch” IDE plugin; Dual-reward CI step combining AlphaResearch-RM for idea filtering and a unit/integration/perf harness for execution scoring; excel@best dashboards to track gains over baselines.
- Assumptions/Dependencies: Robust test suites and perf benchmarks; sandboxed executors; access to a capable LLM; governance for patch acceptance and rollback; IP/licensing checks for AI-generated code.
- Kernel and tensor compiler optimization
- Sectors: ML infra, HPC
- Use case: Search and validate faster tensor kernels (e.g., GEMM variants, convolution tiling, fusion strategies) for frameworks like TVM, XLA, Triton.
- Tools/Products/Workflows: “AlphaKernelSearch” plugin that integrates with compiler autotuners; execution-based profilers; RM thresholding to avoid infeasible ideas.
- Assumptions/Dependencies: Stable evaluation harnesses on target hardware; reproducible perf measurements; compute budget for large search; device-specific constraints.
- Heuristic search for packing, layout, and scheduling
- Sectors: logistics, manufacturing, robotics, EDA (chip floorplanning)
- Use case: Adapt circle-packing advances to bin packing, warehouse slotting, PCB/component placement, robotic item arrangement, and production scheduling.
- Tools/Products/Workflows: “Packing Heuristic Studio” with domain constraint validators; execution-based scoring (utilization, collision, time); idea filtering via RM for novelty/feasibility.
- Assumptions/Dependencies: Accurate domain constraints; simulation fidelity to real-world conditions; human oversight for safety-critical deployments.
- R&D ideation triage and prioritization
- Sectors: industry R&D, academia
- Use case: Rank and filter internal proposal abstracts for novelty and likely impact before allocating experiment resources.
- Tools/Products/Workflows: RM-as-a-service (“Idea Scoring RM”); reviewers’ dashboards; calibrated thresholds; active learning loops to refine the RM on local outcomes.
- Assumptions/Dependencies: RM bias auditing; domain adaptation to non-ICLR areas; institutional policies for AI-assisted evaluation.
- Reproducible algorithm benchmarking-as-a-service
- Sectors: academia, developer tooling
- Use case: Host AlphaResearchComp-style competitions with executable pipelines, clear metrics, and reproducibility checks to evaluate new algorithms and code.
- Tools/Products/Workflows: Benchmark orchestration platform; standardized evaluators; excel@best metric; artifact registry to share code/results.
- Assumptions/Dependencies: Curated tasks with verifiable objectives; hosting costs; community adoption and maintenance.
- Developer productivity assistant for iterative code improvement
- Sectors: software
- Use case: Within IDEs, propose micro-optimizations or refactors, verify them against tests and perf benchmarks, and only accept validated improvements.
- Tools/Products/Workflows: “AlphaResearch IDE Assistant” tying idea generation to targeted code patches and automated execution; perf regression guardrails.
- Assumptions/Dependencies: High-quality test/perf coverage; safe code application; developer-in-the-loop review.
- Operations research experiment automation
- Sectors: transportation, supply chain, energy dispatch
- Use case: Automate exploration of heuristic variants (e.g., routing, load balancing) with execution scoring against historical or simulated demand.
- Tools/Products/Workflows: Domain simulators; RM filters for idea quality; batch search workflows with top-k surfacing and reproducibility logs.
- Assumptions/Dependencies: Representative simulation datasets; stability of scoring functions; approval processes for production policy changes.
- Curriculum modules for teaching algorithm discovery
- Sectors: education, academia
- Use case: Course labs where students use the dual environment to propose, implement, and validate new algorithmic ideas with transparent pipelines.
- Tools/Products/Workflows: “AlphaResearch Classroom” notebooks; prebuilt evaluators; grading via excel@best improvement over baselines.
- Assumptions/Dependencies: Institution compute limits; appropriate problem selection; pedagogical guidance to avoid over-reliance on the LLM.
- Peer-review support signals (non-binding)
- Sectors: academia, scholarly publishing
- Use case: Provide auxiliary signals on novelty/likelihood-of-acceptance for editors to triage workloads and flag potential outliers for extra scrutiny.
- Tools/Products/Workflows: RM scoring service integrated with submission platforms; dashboards for editors; bias monitoring reports.
- Assumptions/Dependencies: Strong governance; transparency for authors; RM fairness audits; strict “assistive only” usage to avoid gatekeeping by AI.
- Security and QA: guided fuzzing and test generation
- Sectors: software security, QA
- Use case: Use the idea-generation and execution loop to propose test inputs or harnesses, execute them, and keep only those that increase coverage or find failures.
- Tools/Products/Workflows: “AutoFuzz with RM” plugin; coverage and crash-based scoring; patch proposals for test suites.
- Assumptions/Dependencies: Safe execution sandboxes; robust telemetry; triaging workflows for found issues.
Long-Term Applications
- Autonomous discovery of domain-specific algorithms in healthcare
- Sectors: healthcare, medical physics, operations
- Use case: Radiotherapy treatment planning (beam placement, dose optimization), patient scheduling, and resource allocation with validated executable pipelines.
- Tools/Products/Workflows: Hospital-grade simulators; RM adapted to medical novelty/impact; clinical validation workflows.
- Assumptions/Dependencies: Regulatory approval; rigorous safety and ethics review; data privacy; high-fidelity simulators.
- Energy grid optimization and storage dispatch
- Sectors: energy, utilities
- Use case: Discover algorithms for grid scheduling, demand response, storage control under uncertainty.
- Tools/Products/Workflows: Grid simulators; execution scoring based on stability/cost; RM trained on energy domain literature and outcomes.
- Assumptions/Dependencies: Access to grid models/data; reliability guarantees; compliance with regulatory constraints.
- Quantitative finance strategy search under strict evaluation
- Sectors: finance
- Use case: Propose trading strategies or risk models; execute on backtesting/simulation; filter for novelty and robustness.
- Tools/Products/Workflows: Backtesting harnesses; RM calibrated to financial novelty/impact; risk management guardrails.
- Assumptions/Dependencies: Data licensing; overfitting mitigation; compliance and auditability.
- Integrated scientific discovery with lab automation
- Sectors: biotech, materials science, chemistry
- Use case: Combine idea generation and code execution with robotic labs to run experiments and refine hypotheses.
- Tools/Products/Workflows: “Lab-in-the-loop Research Agent”; experiment planners; RM tuned on domain peer-review data; safety interlocks.
- Assumptions/Dependencies: Robotic infrastructure; experimental ontologies; safety protocols; reproducible experimental pipelines.
- Formal theorem discovery and proof verification
- Sectors: academia, software verification
- Use case: Generate conjectures, implement proof attempts or counterexample searches, and validate via formal provers.
- Tools/Products/Workflows: Integration with proof assistants (Lean/Isabelle/Coq); RM trained on math venues; execution scoring via proof success.
- Assumptions/Dependencies: Formalization of targets; compute for proof search; expert oversight for interpretation.
- AutoML research copilot for discovering losses, augmentations, and architectures
- Sectors: ML research, applied ML
- Use case: Propose new training objectives or architectures; execute training runs; keep only reproducible improvements.
- Tools/Products/Workflows: “AutoAlgo” platform; RM tuned on ML venues beyond ICLR; excel@best measured on canonical benchmarks.
- Assumptions/Dependencies: Significant compute; robust contamination controls; multi-seed, multi-dataset validation.
- EDA: chip floorplanning and placement algorithm evolution
- Sectors: semiconductors
- Use case: Discover heuristics for macro placement, routing, timing closure with executable scoring against design constraints.
- Tools/Products/Workflows: Integration with commercial/open EDA tools; RM adapted to EDA literature; domain-specific validators.
- Assumptions/Dependencies: Access to proprietary flows; industrial-scale compute; IP constraints; tight coupling to fabrication requirements.
- Multi-agent competitive discovery platforms
- Sectors: research tooling, platforms
- Use case: Host “research tournaments” where agent ensembles propose, implement, and challenge algorithms against shared evaluators.
- Tools/Products/Workflows: Orchestration for agent competition; transparency tooling (provenance, logs); reputation systems.
- Assumptions/Dependencies: Standardized tasks; incentive design; security and fairness mechanisms.
- Policy: AI-assisted grant triage and program design with audited RM
- Sectors: public policy, funding agencies
- Use case: Use RM signals to triage large volumes of proposals and identify areas where agent-based discovery is promising; inform programmatic priorities.
- Tools/Products/Workflows: Auditable RM pipelines; bias and fairness dashboards; human-in-the-loop decision processes.
- Assumptions/Dependencies: Legal/ethical frameworks; stakeholder buy-in; transparency mandates; continuous calibration.
- Standardization of excel@best and executable pipelines for scientific publishing
- Sectors: academia, publishers
- Use case: Require reproducible evaluators and excel@best-style reporting for algorithmic claims.
- Tools/Products/Workflows: Publisher toolkits; artifact evaluation services; community-maintained evaluators.
- Assumptions/Dependencies: Community consensus; maintenance funding; variability across disciplines.
- Algorithm marketplace and provenance registry
- Sectors: software platforms, IP markets
- Use case: Curate and license agent-discovered algorithms with verified performance and detailed provenance logs.
- Tools/Products/Workflows: Registries with execution traces; licensing workflows; integration SDKs.
- Assumptions/Dependencies: IP frameworks for AI-generated artifacts; liability structures; validation guarantees.
- Scaling and debiasing the Reward Model with multi-venue, multi-domain data
- Sectors: cross-sector
- Use case: Build larger, domain-adapted RMs that generalize beyond ICLR into energy, healthcare, finance, and materials science.
- Tools/Products/Workflows: Data ingestion pipelines from diverse peer-review sources; adversarial bias audits; continual learning mechanisms.
- Assumptions/Dependencies: Data access permissions; privacy/compliance; rigorous evaluation across domains.
Glossary
- AlphaEvolve: An execution-based autonomous coding agent for scientific and algorithmic discovery, used as a baseline for comparison. "Inspired by AlphaEvolve \citep{novikov2025alphaevolve}, we construct automatic evaluation process with code executor"
- AlphaResearch: An autonomous research agent that iteratively proposes, verifies, and optimizes ideas to discover new algorithms. "AlphaResearch discovers new algorithms by iteratively running the following steps: (i) proposing new research ideas, (ii) verify the ideas in the dual research-based environment, and (iii) optimizing the proposals for higher reward from the environment."
- AlphaResearchComp: A benchmark-style competition of eight open-ended algorithmic problems for transparent evaluation against human researchers. "we construct AlphaResearchComp, a simulated discovery Competition between research agents and human researchers"
- AlphaResearch-RM-7B: A fine-tuned 7B reward model trained on peer-review records to score and filter research ideas. "We fine-tune Qwen2.5-7B-Instruct with the RM pairs, yielding the AlphaResearch-RM-7B model."
- autoconvolution peak minimization: An optimization task aiming to minimize the peak value of a function’s autoconvolution (convolution of a function with itself). "autoconvolution peak minimization (upper bound)"
- bfloat16: A 16-bit floating-point format with a wide exponent range, used to speed training while maintaining numeric stability. "using bfloat16 precision under FSDP"
- code executor: An automated system that runs generated code to verify constraints and measure performance. "we construct automatic evaluation process with code executor"
- excel@best: A metric measuring percentage improvement over the best human baseline on open-ended problems. "we propose a new metric - excel@best (excel at best)"
- execution-based verification: Validating solutions by running code to check constraints and measure outcomes. "Execution-based verification systems like AlphaEvolve \cite{novikov2025alphaevolve} can rigorously validate whether code runs and meets constraints"
- FSDP: Fully Sharded Data Parallel; a distributed training strategy that shards model states across devices. "using bfloat16 precision under FSDP"
- ideation–execution gap: The discrepancy between generating research ideas and successfully implementing them into working solutions. "the ideationâexecution gap \citep{si2025ideation} between generating and executing on new ideas"
- knowledge contamination: Leakage where evaluation data overlaps with training or model knowledge, compromising fairness. "which prevents knowledge contamination between the train and test split."
- Littlewood polynomials: Polynomials with coefficients restricted to ±1, important in harmonic analysis and combinatorics. "littlewood polynomials (n=512)"
- max-min distance ratio: An objective that considers the ratio of maximal to minimal pairwise distances, often minimized for uniform configurations. "minimizing max-min distance ratio"
- MSTD: “More Sums Than Differences” sets; integer sets with more distinct pair sums than differences. "MSTD (n=30)"
- packing circles: A geometric optimization problem of placing disjoint circles in a square to maximize the sum of radii. "packing circles (n=32)"
- pass@k: A code-generation metric where success is counted if any of k independent attempts passes verification. "pass@k~\citep{chen2021evaluating} is a metric denoting that at least one out of i.i.d. task trials is successful"
- program-based verification: Validation using executable programs to check constraints and compute objective scores. "The synergy between an iterative real-world peer review environment and program-based verification empowers AlphaResearch"
- reward model: A learned model that assigns scores to guide search toward promising ideas and implementations. "we train a reward model with ideas from real-world peer-review information to simulate the real-world peer-review environment."
- simulated real-world peer review environment: An evaluation setup emulating academic peer-review to score novelty and feasibility of ideas. "by the simulated real-world peer-reviewed environment and execution-based verification."
- spherical code: An arrangement of points on a sphere maximizing minimal angular separation; used in coding theory and discrete geometry. "spherical code (d=3, n=30)"
- SWE-Bench: A benchmark of real-world GitHub issues for evaluating LLMs’ software engineering capabilities. "SWE-Bench \citep{jimenez2024swebench} introduces the problems in real-world software development."
- trajectory: The sequence of ideas, programs, and results generated over iterative optimization by the agent. "The resulting trajectory is denoted as "
- Verification module: A component that checks whether a generated program meets explicit problem constraints. "(i) Verification module that validates whether conforms to the problem constraints."
Collections
Sign up for free to add this paper to one or more collections.