- The paper introduces OMEGA, a framework that rigorously tests LLM generalization in mathematical problem solving across various domains.
- It employs 40 templated problem generators across six math areas to assess exploratory, compositional, and transformative reasoning capabilities.
- Results reveal significant performance drops with increased complexity and highlight challenges in achieving truly creative, novel problem-solving strategies.
OMEGA: Evaluating Generalization in LLM Math Reasoning (2506.18880)
The paper "OMEGA: Can LLMs Reason Outside the Box in Math? Evaluating Exploratory, Compositional, and Transformative Generalization" (2506.18880) presents a comprehensive evaluation framework, OMEGA, designed to test the limits of out-of-distribution generalization in LLMs regarding mathematical reasoning tasks. The framework focuses on assessing LLMs' capabilities across three specific axes of generalization: exploratory, compositional, and transformative generalization (Figure 1).

Figure 1: Examples of training-test pairs designed to test distinct generalization capabilities: (a) Explorative Generalization increases complexity within the same frame of thinking (e.g., extending geometric reasoning from an octagon to a dodecagon). (b) Compositional Generalization requires integrating multiple learned strategies (e.g., combining GCD and root-finding for polynomials). (c) Transformative Generalization demands a shift in thinking mode.
Problem Construction
The OMEGA benchmark introduces a novel approach to assess LLMs by generating training-test pairs through 40 templated problem generators spanning six mathematical domains: arithmetic, algebra, combinatorics, number theory, geometry, and logic puzzles (Table 1). Each template is meticulously designed to prevent success based merely on memorizing patterns presented during training, instead encouraging models to develop and apply innovative reasoning strategies.
Benchmark Design
Generalization Axes in OMEGA
OMEGA evaluates LLMs along three distinct axes of generalization, leveraging Boden’s typology of creativity:
- Exploratory Generalization: Tests if a model can apply known skills to more complex versions of previously encountered problems within the same domain (Figure 1a).
- Compositional Generalization: This examines LLMs' capacity to integrate individually learned reasoning skills into novel problems using the synthesized methodologies in new, coherent ways (Figure 2).
- Transformative Generalization: This axis challenges models to develop new, unconventional problem-solving strategies that depart from those seen during training.
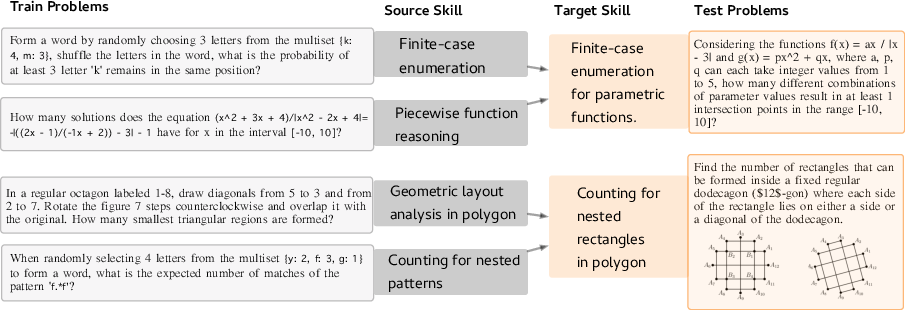
Figure 2: Two examples of compositional generalization in our training/test setup.
Experimentation and Results Analysis
Limits of LLMs on Increasing Problem Complexity
The study tested four advanced LLMs, including DeepSeek-R1 and variations of OpenAI models, across increasing complexity levels on the OMEGA benchmark. The results (Figure 3) illustrate a marked performance degradation among all models as problem complexity increased. CoT reasoning manifests as achieving initial accuracy, but as complexity rises, models demonstrate a propensity for excessive and destabilizing verification steps, as depicted in the "overthinking" regions of Figure 4.
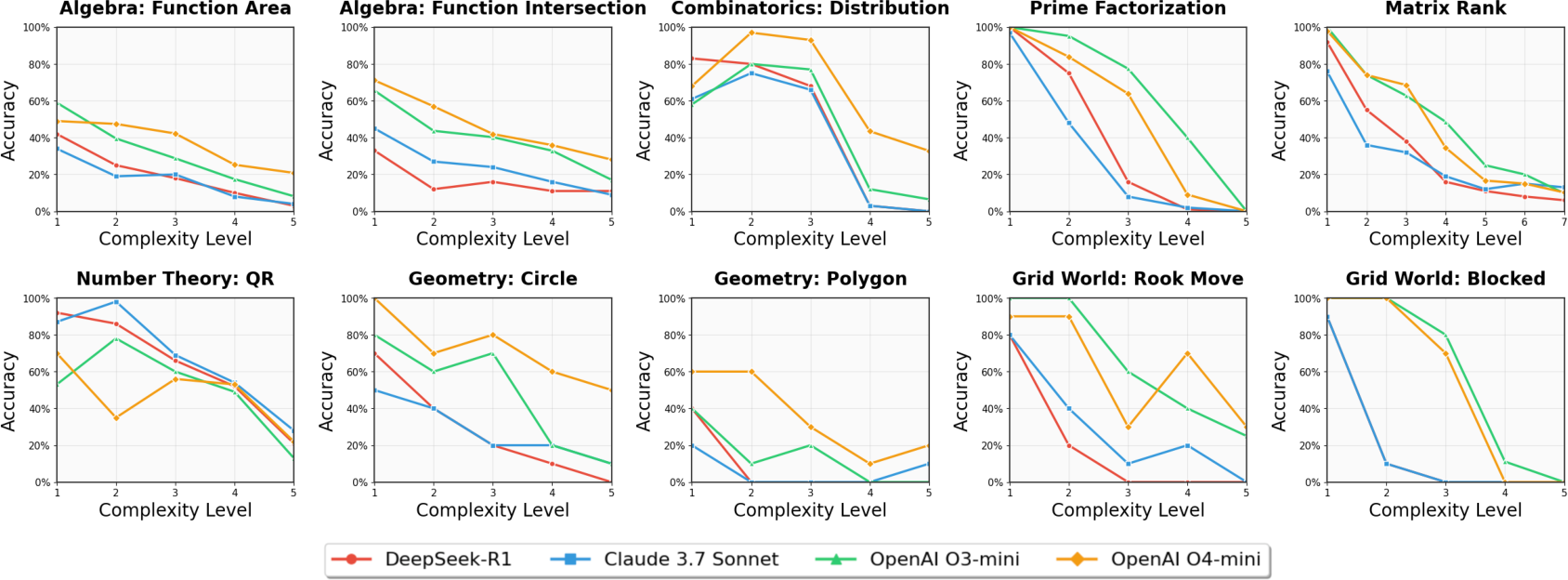
Figure 3: Exact match accuracy of four top-tier LLMs on OMEGA, plotted against increasing complexity levels.
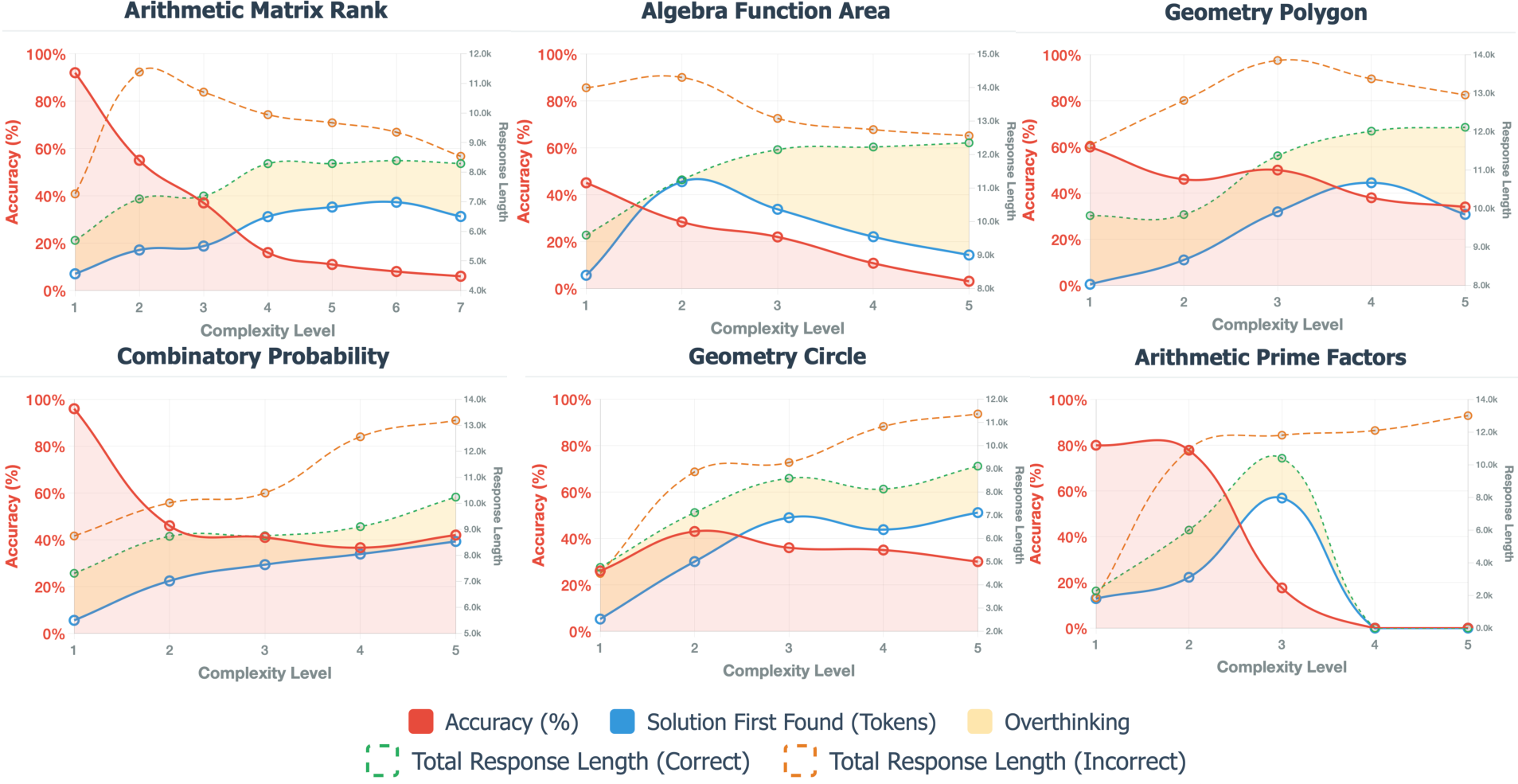
Figure 4: Performance and reasoning patterns across six mathematical task domains showing accuracy degradation and verification behavior as problem complexity increases. Models often reach the correct answer early in the response but continue generating unnecessary verification steps, as shown in the yellow overthinking regions.
RL training was examined to improve reasoning models, particularly Qwen-series LLMs, across three distinct generalization settings:
- Exploratory Generalization assessed whether models could apply known strategies to more complex tasks within the same domain. RL demonstrated significant improvements, especially on in-domain tasks (Figure 5).
- Compositional Generalization evaluated models' ability to integrate separate skills into new strategies. Despite RL showing improvements on individual skills, there were limited gains for synthesis tasks, revealing gaps in flexible skill composition.
- Transformative Generalization posed the most significant challenge. Models demonstrated limited ability to discover and apply new strategies, as shown in Figure 6. Even after enhancements via RL, models maintained near-zero accuracy on many OOD tasks.
Figure 4: Performance comparison of Qwen2.5-7B-Instruct on OMEGA under the exploratory generalization setting.
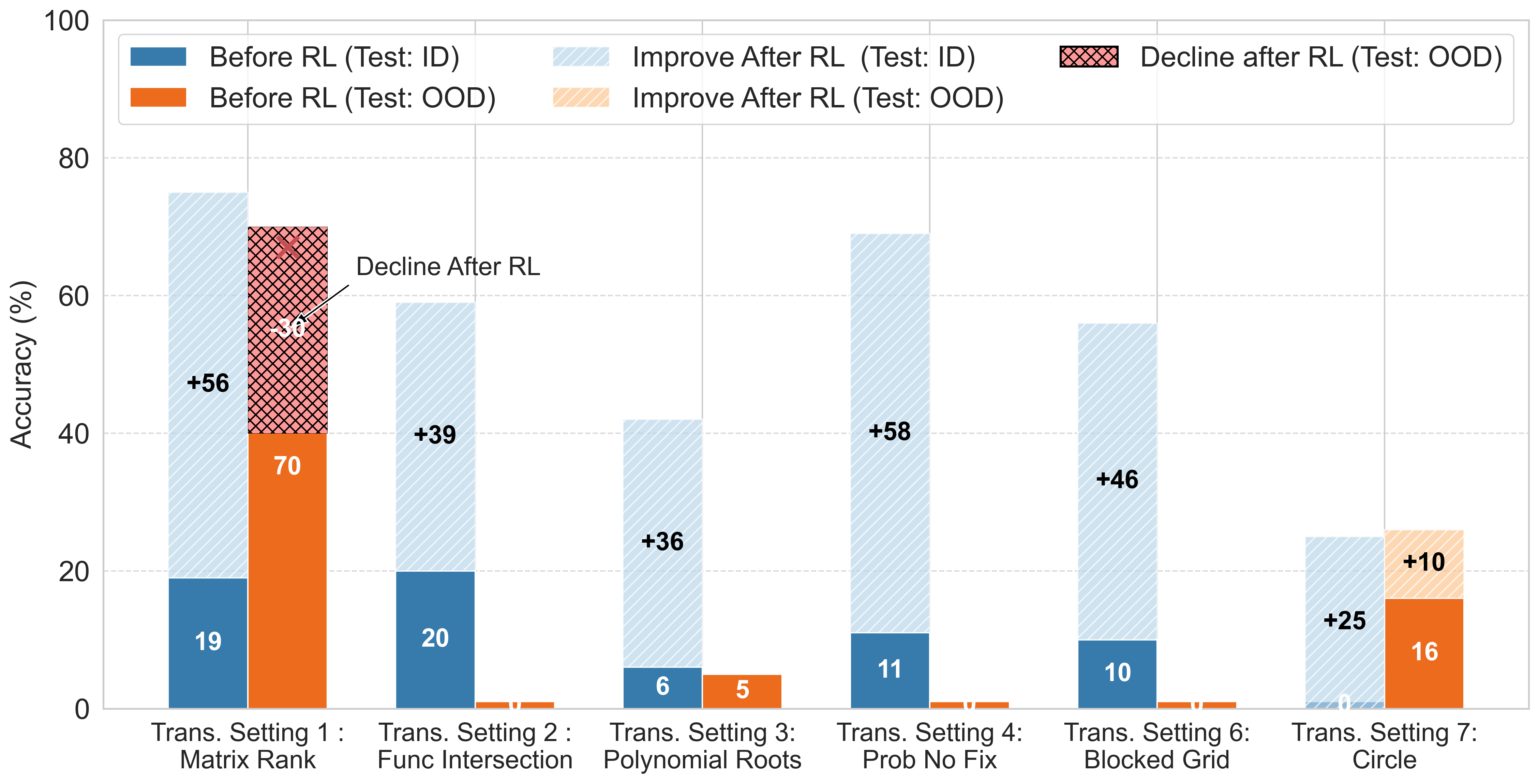
Figure 6: Performance comparison of Qwen2.5-7B-Instruct on OMEGA under the transformational generalization setting.
Implications and Future Directions
The investigations reveal critical limitations in current LLM reasoning capacities, particularly in handling complex mathematical tasks that demand ingenuity and the integration of multiple reasoning strategies. These findings accentuate the constraints of current architectures, especially in tasks requiring compositional and transformative generalization.
The implications of the OMEGA benchmark extend far beyond mere evaluation. They suggest the potential for future progress through strategies such as curriculum scaffolding and meta-reasoning controllers. These strategies aim to foster truly creative reasoning capabilities, enabling LLMs to perform novel strategic thinking akin to human problem-solving intricacies. Recognizing and addressing the gaps between LLMs and human mathematicians remains pivotal for advancing AI towards genuine mathematical creativity.