- The paper introduces Direct-Align, which enables efficient reward optimization across all timesteps, avoiding overfitting and reward hacking.
- It proposes SRPO, a text-conditioned framework that shapes rewards through relative preference differences for fine-grained aesthetic control.
- Experiments demonstrate significant improvements in realism (up to 3.7x) and efficiency (75x faster training) compared to prior RL methods.
Directly Aligning the Full Diffusion Trajectory with Fine-Grained Human Preference
Introduction
This work addresses two central challenges in aligning text-to-image diffusion models with human preferences: (1) the computational and optimization bottlenecks of direct reward-based reinforcement learning (RL) across the full diffusion trajectory, and (2) the inflexibility and bias of reward models, which often require costly offline adaptation to new aesthetic or semantic targets. The authors introduce a two-part solution: Direct-Align, a method for efficient, stable reward-based optimization at any diffusion timestep, and Semantic Relative Preference Optimization (SRPO), a framework for online, text-conditional reward shaping that robustly mitigates reward hacking and enables fine-grained, prompt-driven control.
Methodology
Direct-Align: Full-Trajectory Reward Optimization
Conventional direct reward optimization in diffusion models is limited to late denoising steps due to gradient instability and computational cost. This restriction leads to overfitting and reward hacking, as models exploit reward model biases at the end of the trajectory. Direct-Align circumvents this by leveraging the closed-form relationship between noisy and clean images in the diffusion process:
xt=αtx0+σtϵgt
Given a noisy image xt and known noise ϵgt, the clean image x0 can be exactly recovered via interpolation, enabling accurate reward assignment and gradient propagation at any timestep. This approach eliminates the need for iterative denoising and allows for efficient, stable optimization across the entire diffusion trajectory.
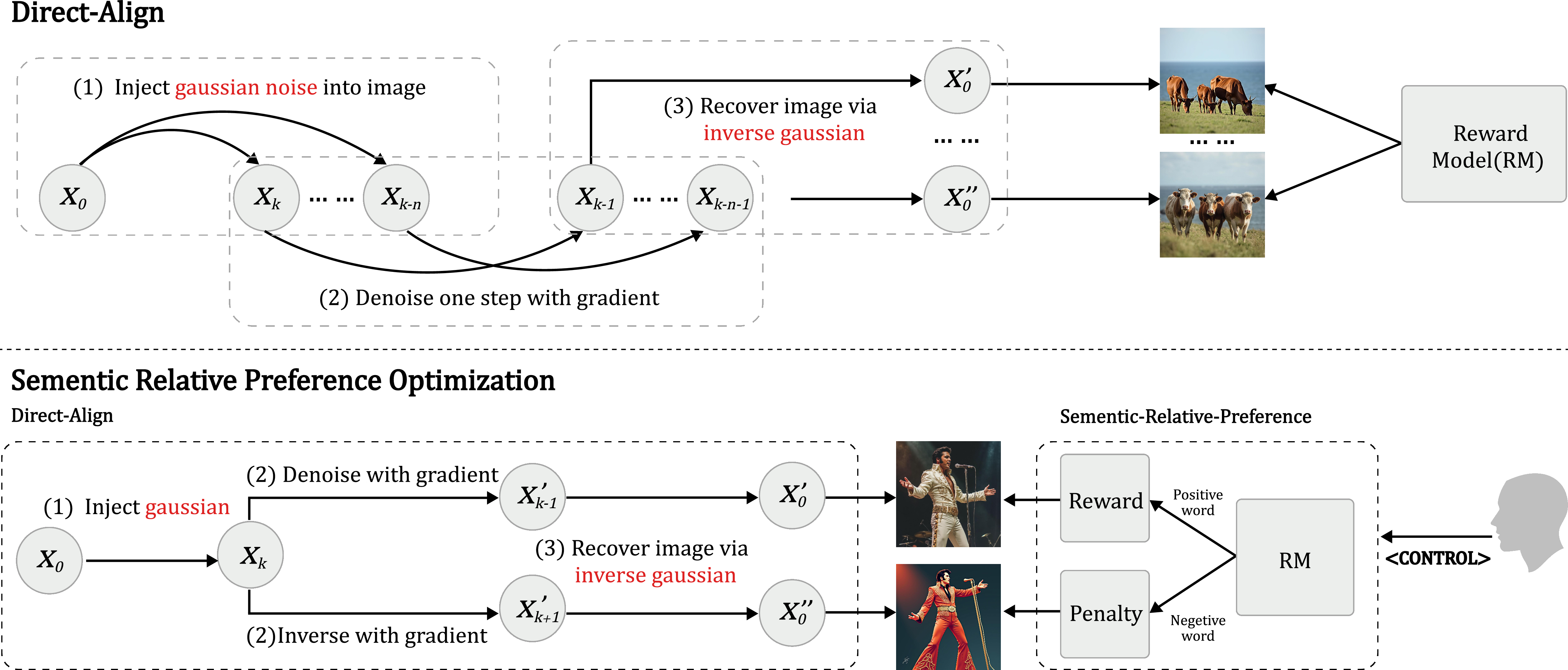
Figure 1: Method overview. SRPO combines Direct-Align for full-trajectory optimization and a single reward model with both positive and negative prompt conditioning.

Figure 2: One-step prediction at early timesteps. Direct-Align achieves high-quality reconstructions even with 95% noise, outperforming standard one-step methods.
The method further aggregates rewards across multiple timesteps using a decaying discount factor, which regularizes optimization and reduces late-timestep overfitting.
Semantic Relative Preference Optimization (SRPO)
SRPO reformulates reward signals as text-conditioned preferences, enabling online adjustment via prompt augmentation. Instead of relying on static, potentially biased reward models, SRPO computes the relative difference between rewards for positive and negative prompt augmentations:
rSRP(x)=r1−r2=fimg(x)T⋅(C1−C2)
where C1 and C2 are text embeddings for desired and undesired attributes, respectively. This formulation penalizes irrelevant directions and aligns optimization with fine-grained, user-specified semantics.
SRPO supports both denoising and inversion directions, allowing for gradient ascent (reward maximization) and descent (penalty propagation) at different timesteps, further enhancing robustness against reward hacking.

Figure 3: Comparison of optimization effects. SRPO penalizes irrelevant reward directions, effectively preventing reward hacking and enhancing image texture.
Experimental Results
Quantitative and Qualitative Evaluation
The authors conduct extensive experiments on the FLUX.1.dev model using the HPDv2 benchmark, comparing SRPO and Direct-Align to state-of-the-art online RL methods (ReFL, DRaFT, DanceGRPO). Evaluation metrics include Aesthetic Predictor 2.5, PickScore, ImageReward, HPSv2.1, GenEval, DeQA, and comprehensive human assessments.
SRPO achieves 3.7x improvement in perceived realism and 3.1x improvement in aesthetic quality over the baseline, with a 75x increase in training efficiency compared to DanceGRPO (10 minutes on 32 H20 GPUs). Notably, SRPO is the only method to substantially improve realism without introducing reward hacking artifacts.

Figure 4: Human evaluation results. SRPO demonstrates significant improvements in aesthetics and realism, with a substantial reduction in AIGC artifacts.

Figure 5: Qualitative comparison. SRPO yields superior realism and detail complexity compared to FLUX and DanceGRPO.
Reward Model Generalization and Robustness
SRPO is evaluated with multiple reward models (CLIP, PickScore, HPSv2.1) and consistently enhances realism and detail complexity. The method is robust to reward model biases and does not exhibit reward hacking, in contrast to prior approaches.

Figure 6: Cross-reward results. SRPO generalizes across different reward models, maintaining high image quality and robustness.
Fine-Grained and Style Control
By conditioning on style-related control words, SRPO enables prompt-driven fine-tuning for attributes such as brightness, artistic style, and realism. The effectiveness of control depends on the reward model's ability to recognize the style terms, with high-frequency words in the reward training set yielding stronger controllability.

Figure 7: SRPO-controlled results for different style words, demonstrating prompt-driven fine-grained control.
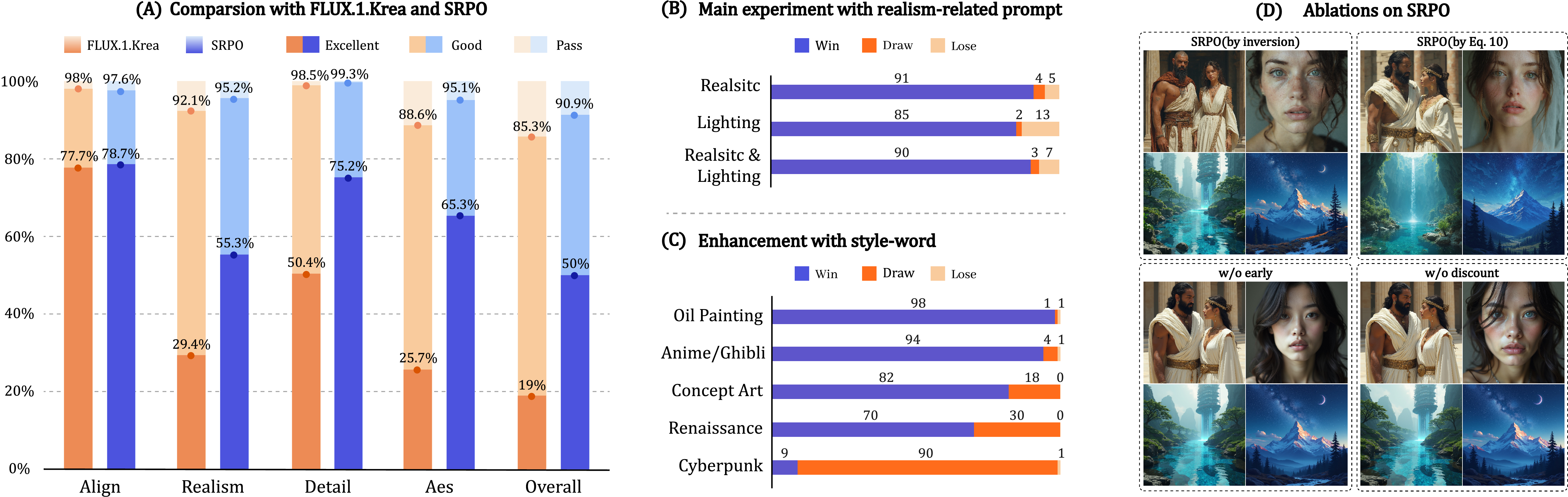
Figure 8: Experimental overview. SRPO improves realism, enables enhanced style control, and ablation studies confirm the importance of early timestep optimization and inversion.
Analysis and Ablations
Denoising Efficiency
Direct-Align enables accurate reward-based optimization at early timesteps, where standard one-step methods fail due to noise-induced artifacts. Shorter model-predicted step proportions yield higher final image quality.
Optimization Interval
Training restricted to late timesteps increases reward hacking rates. Early or full-trajectory optimization, as enabled by Direct-Align, mitigates this effect.
Ablation Studies
Removing early timestep optimization or the late-timestep discount in Direct-Align degrades realism and increases vulnerability to reward hacking. Inversion-based regularization further improves robustness.
Implications and Future Directions
This work demonstrates that full-trajectory, reward-based RL is both feasible and highly effective for aligning diffusion models with human preferences, provided that optimization is stabilized and reward signals are regularized via semantic relativity. The SRPO framework enables prompt-driven, fine-grained control without the need for costly reward model retraining or large-scale data collection.
Limitations include reduced controllability for rare or out-of-domain control tokens and limited interpretability due to reliance on latent space similarity. Future work should focus on systematic control strategies, learnable control tokens, and reward models explicitly responsive to prompt structure. The SRPO approach is extensible to other online RL algorithms and modalities.
Conclusion
The combination of Direct-Align and SRPO constitutes a significant advance in the practical alignment of diffusion models with nuanced human preferences. By enabling efficient, robust, and prompt-driven optimization across the full diffusion trajectory, this framework sets a new standard for controllable, high-fidelity text-to-image generation. The methodology is broadly applicable and opens new avenues for research in reward modeling, RL-based generative model alignment, and fine-grained user control in generative AI.