- The paper introduces DeeptraceReward, a new benchmark that captures spatiotemporal deepfake traces in AI-generated videos through detailed annotations and precise localization.
- The evaluation of 13 multimodal LLMs shows high binary classification accuracy but poor performance in fine-grained artifact detection and temporal localization.
- Fine-tuned reward models on DeeptraceReward significantly improve detection, underscoring the need for better visual grounding and temporal reasoning in T2V models.
Learning Human-Perceived Fakeness in AI-Generated Videos via Multimodal LLMs
The rapid progress in text-to-video (T2V) generation models has led to the production of highly realistic synthetic videos. However, evaluation protocols for these models have predominantly focused on prompt alignment, global visual quality, or human preference in pairwise comparisons, neglecting the critical dimension of human-perceived fakeness at a fine-grained, spatiotemporal level. The central question addressed is: can humans reliably identify AI-generated videos and, crucially, provide grounded, localized reasons for their judgments? This work introduces DeeptraceReward, a benchmark and dataset designed to fill this gap by capturing human-perceived deepfake traces—spatiotemporally localized visual artifacts that betray machine generation.
DeeptraceReward Dataset: Collection and Annotation
The DeeptraceReward dataset comprises 4,334 expert-labeled deepfake trace annotations across 3,318 high-quality AI-generated videos, sourced from seven state-of-the-art T2V models (including Sora, Pika, Kling, MiniMax, Mochi, and Gen-3). An equal number of real videos, sampled from LLaVA-Video-178K, are included for balanced evaluation. The data curation pipeline involves prompt generation via GPT-4, manual filtering for high-quality, dynamic scenes, and expert annotation using the LabelBox platform.
Each annotation consists of:
- A natural language explanation of the perceived fake trace.
- A bounding box localizing the artifact in space and time (onset/offset timestamps).
- A categorical label from a taxonomy of nine major deepfake trace types (e.g., object distortion, blurring, merging, splitting, disappearance).

Figure 1: Human-perceived deepfake trace examples with bounding boxes, timestamps, and natural language explanations.
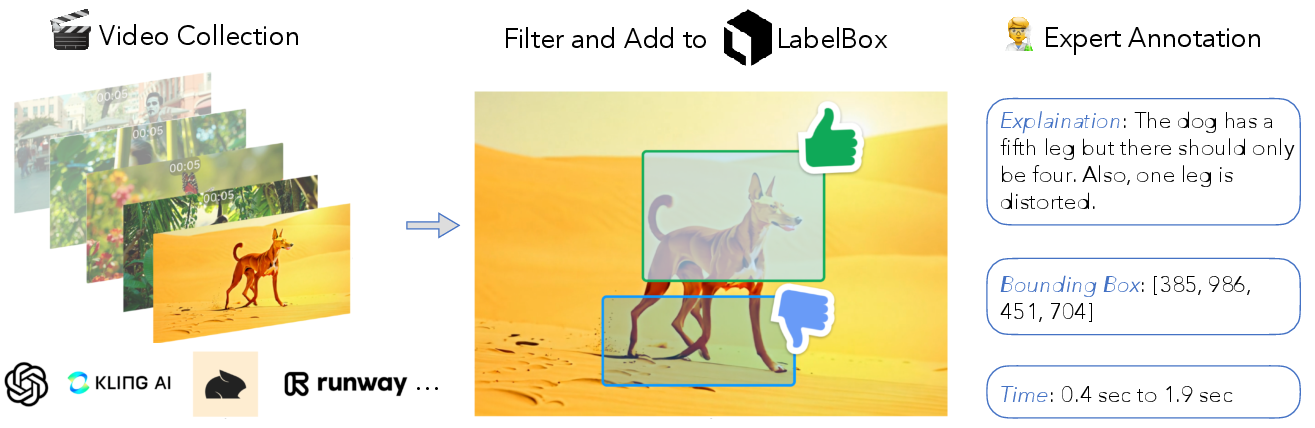
Figure 2: DeeptraceReward data curation pipeline, from prompt generation to expert annotation.
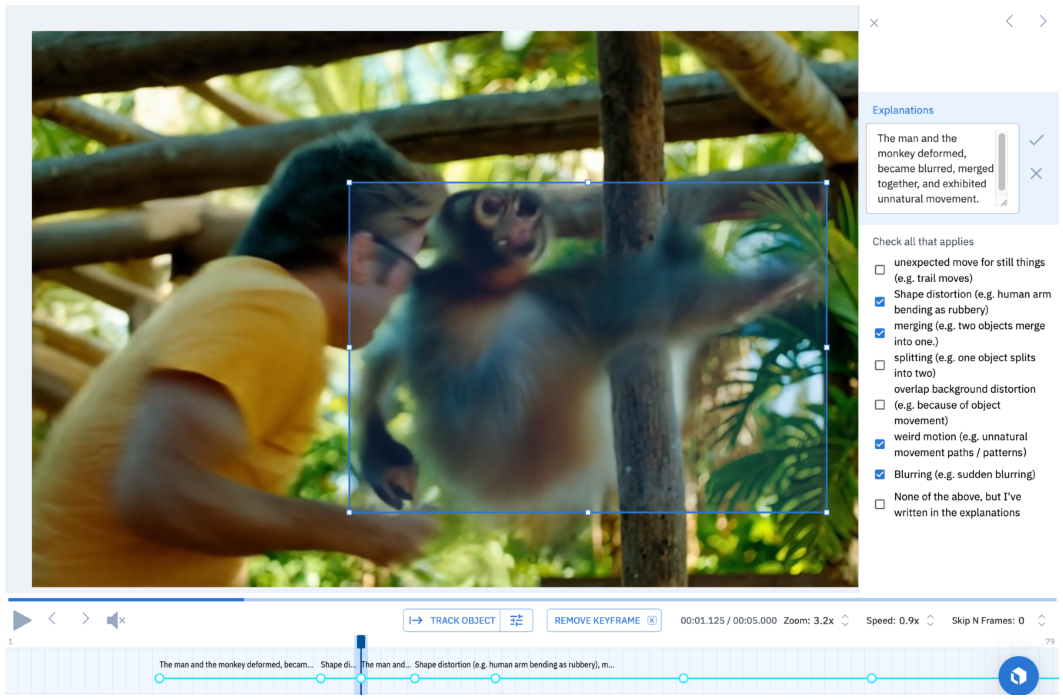
Figure 3: LabelBox annotation interface for spatiotemporal bounding box and explanation collection.
The annotation process is consensus-driven, with ambiguous cases resolved by majority vote and explanations post-processed for consistency using GPT-4. The dataset emphasizes movement-rich scenarios, as static scenes rarely elicit reliable human detection of fakeness.
Dataset Analysis
The nine major deepfake trace categories, covering 90% of annotated cases, are movement-centric and include object distortion, blurring, merging, splitting, disappearance, and other motion-related artifacts. The distribution of these categories reveals that certain artifact types (e.g., object distortion and blurring) are more prevalent in current T2V outputs.
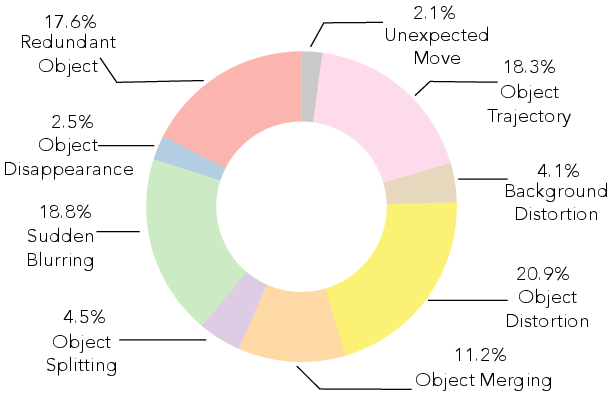
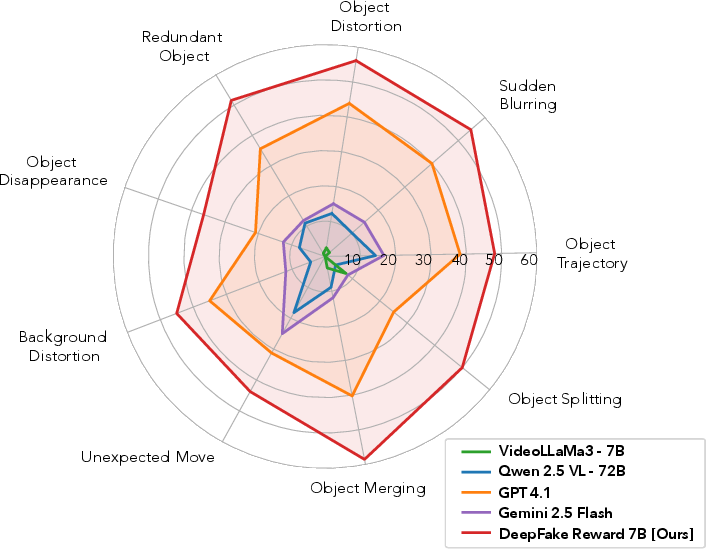
Figure 4: Distribution of deepfake trace categories in DeeptraceReward.
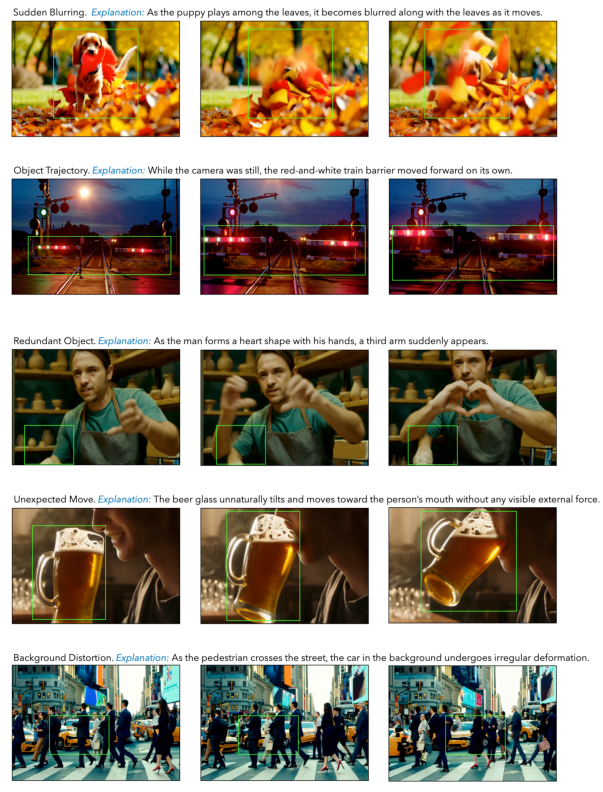
Figure 5: Examples of deepfake traces by category, illustrating the diversity of artifact types.
Experimental Protocol and Baseline Evaluation
Thirteen recent multimodal LLMs are evaluated on DeeptraceReward, including GPT-5, GPT-4.1, Gemini 2.5 Pro/Flash, Video-LLaVa, LLaVa-One-Vision, Phi-3.5/4-Vision, Qwen 2/2.5 VL (7B/32B/72B), and VideoLLaMA3 7B. The evaluation protocol, implemented via VLMEvalKit, is zero-shot and uses a standardized prompt requiring models to classify videos as real or fake, localize the artifact (bounding box and start time), and provide an explanation.
Metrics include:
- Binary classification accuracy (real vs. fake).
- Explanation quality (scored by GPT-4.1 as 0/0.5/1).
- Bounding box IoU and center distance.
- Temporal localization error (start time distance).
- An overall composite score.
All baseline models, including GPT-5 and Gemini 2.5 Pro, achieve high accuracy (>70%) on binary classification but perform poorly (<37% overall) on fine-grained deepfake trace detection. Notably, explanation generation is easier than spatial grounding, which in turn is easier than temporal localization. For example, GPT-5 achieves 90.7% classification accuracy but only 40.9% on explanation and 10.4 on bounding box IoU.
A consistent difficulty gradient is observed:
- Binary classification (easiest, >85% for SOTA models).
- Explanation generation (intermediate).
- Spatial grounding (harder).
- Temporal localization (hardest; most models default to maximal error).
Reward Model Training and Ablation
Supervised fine-tuning (SFT) is performed on two base models: VideoLLaMA3 7B and Qwen 2.5 VL 7B. The best-performing model (VideoLLaMA3 7B, SFT on DeeptraceReward) achieves 70.2% overall, surpassing GPT-5 by 34.7% and Gemini 2.5 Pro by 40.2%. It reaches 99.4% on binary classification, 70.6% on explanation, 32.6 on bounding box IoU, and 21.9 on time distance.
Ablation studies show that removing explanation or temporal supervision affects the corresponding metrics but does not yield substantial gains elsewhere, indicating that multi-task supervision is synergistic.

Figure 6: Qualitative comparison of ground-truth, GPT, and reward model explanations and groundings.
Error Analysis and Qualitative Insights
Baseline models often default to predicting the entire frame as the artifact region or fail to provide meaningful explanations. In contrast, the fine-tuned reward model localizes artifacts more precisely and generates more detailed, contextually appropriate explanations. However, even the best model lags behind human performance, especially in temporal localization.
Implications and Future Directions
The DeeptraceReward benchmark exposes a significant gap between current multimodal LLMs and human-level perception of fine-grained fakeness in AI-generated videos. The results suggest that:
- Binary classification is insufficient for robust evaluation of T2V models; fine-grained, explainable, and localized detection is necessary.
- Existing multimodal LLMs, even at large scale, lack the visual grounding and temporal reasoning required for human-aligned artifact detection.
- Reward models trained on DeeptraceReward can substantially improve performance, but further advances in model architecture and training are needed.
Practically, DeeptraceReward provides a rigorous testbed for developing socially aware and trustworthy video generation systems. The dataset and reward models can be leveraged for:
- Training T2V models with RLHF or direct reward optimization to minimize human-perceived artifacts.
- Developing explainable AI systems for deepfake detection in high-stakes domains (e.g., media forensics, content moderation).
- Benchmarking progress in multimodal grounding and temporal reasoning.
Theoretically, the work highlights the need for models that integrate fine-grained spatiotemporal perception, robust visual grounding, and natural language explanation capabilities. Future research may explore:
- Incorporating DeeptraceReward as a reward signal in RL-based T2V model training.
- Extending the annotation protocol to more diverse content and longer videos.
- Investigating the transferability of reward models across domains and modalities.
Conclusion
DeeptraceReward establishes a new standard for evaluating and training models on human-perceived fakeness in AI-generated videos. The benchmark reveals that current multimodal LLMs are inadequate for fine-grained deepfake trace detection, but targeted reward model training can yield substantial improvements. This work provides both a resource and a methodology for advancing human-aligned, explainable, and trustworthy video generation and detection systems.