- The paper introduces RealDPO, a framework that aligns video generative models using real win samples to overcome reward hacking and overfitting issues.
- It employs a tailored Direct Preference Optimization loss in diffusion models to enhance motion smoothness and human action consistency.
- The approach is validated on the RealAction-5K dataset, demonstrating superior visual, textual, and motion quality compared to existing methods.
RealDPO: Preference Alignment for Video Generation via Real Data
Introduction and Motivation
The paper introduces RealDPO, a preference alignment paradigm for video generative models that leverages real-world data as positive samples in Direct Preference Optimization (DPO) training. The motivation stems from the persistent challenge in video synthesis: generating complex, natural, and contextually consistent human motions. Existing diffusion-based video models, even state-of-the-art DiT architectures, often produce unrealistic or unnatural movements, especially in human-centric scenarios. Traditional supervised fine-tuning (SFT) on curated datasets provides limited corrective feedback and is prone to overfitting, while reward-model-based preference learning suffers from reward hacking, scalability issues, and bias propagation.
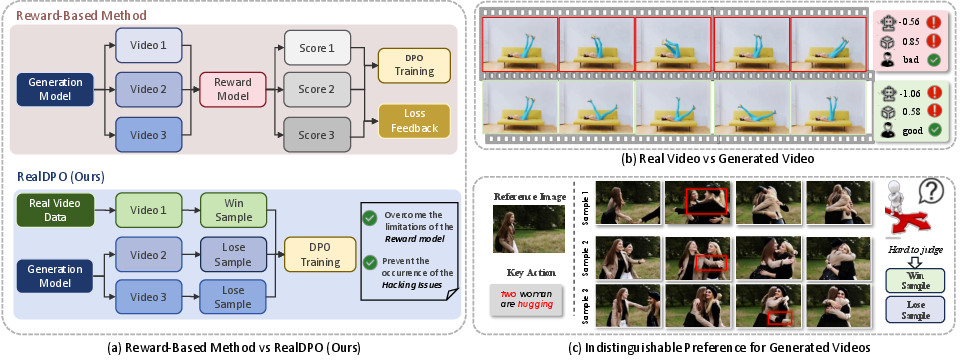
Figure 1: RealDPO leverages real data as win samples for preference learning, circumventing reward model limitations and hacking issues.
RealDPO extends the DPO paradigm to video diffusion models by using real videos as win samples and synthetic outputs as lose samples. This approach directly addresses the distributional errors of pretrained generative models and eliminates the need for external reward models, thus avoiding reward hacking and bias propagation. The framework is built upon a tailored DPO loss for diffusion-based transformers, inspired by Diffusion-DPO, and is designed to efficiently align model outputs with human preferences.
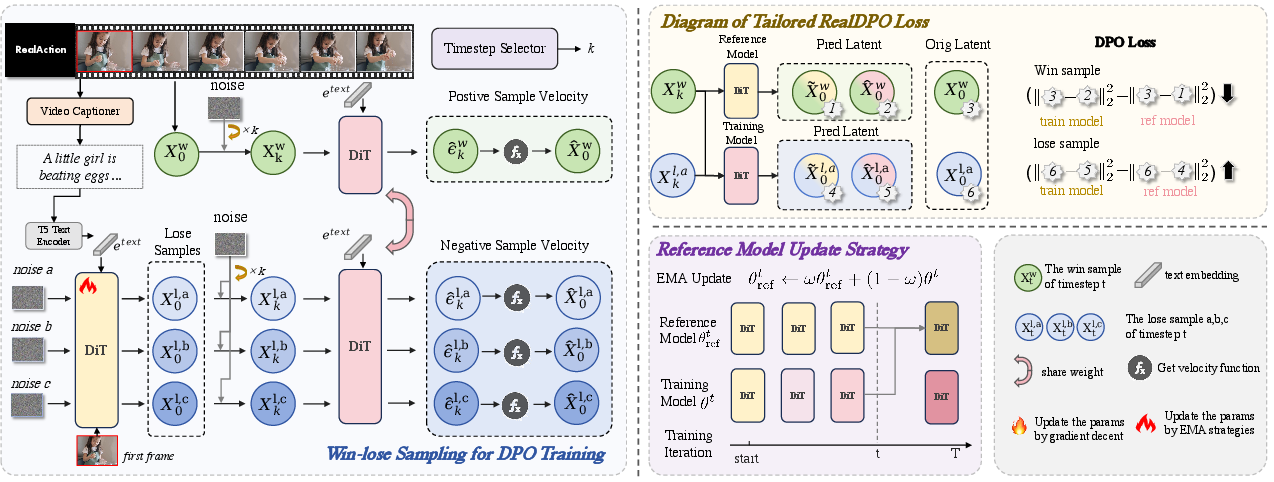
Figure 2: The RealDPO framework utilizes real data for preference alignment, with a custom DPO loss and reference model update strategy.
The DPO loss for diffusion models is formulated as:
LDPO(θ)=−E[logσ(−βTω(λt)(∥x0w−x^0w∥22−∥x0w−x~0w∥22−(∥x0l−x^0l∥22−∥x0l−x~0l∥22)))]
where x0w/x0l are the original win/lose samples, x^0w/x^0l are the predicted latents by the training model, and x~0w/x~0l are the predicted latents by the reference model. The reference model is updated via EMA to prevent over-optimization.
Implementation Details
- Data Pipeline: RealAction-5K, a curated dataset of 5,000 high-quality videos of daily human activities, is used for win samples. Data is filtered using Qwen2-VL and manually inspected for quality.
- Negative Sampling: Synthetic videos are generated with diverse initial noise and paired with the same prompt as the win sample.
- Training: The DPO loss is computed for each win-lose pair, and the reference model is periodically updated via EMA.
- Computational Efficiency: Offline negative sampling and latent-space training reduce pixel-space decoding overhead, enabling scalable training on high-resolution videos.
Quantitative and Qualitative Results
Extensive experiments demonstrate that RealDPO achieves superior performance in video quality, text alignment, and motion realism compared to SFT, reward-model-based methods (LiFT, VideoAlign), and pretrained baselines.
- User Study: RealDPO outperforms all baselines in Overall Quality, Visual Alignment, Text Alignment, Motion Quality, and Human Quality.
- MLLM Evaluation: Using Qwen2-VL, RealDPO matches or exceeds baselines in all dimensions, with particularly strong results in motion and human quality.
- VBench-I2V Metrics: RealDPO achieves competitive scores across subject consistency, background consistency, motion smoothness, and aesthetic quality.

Figure 3: RealDPO generates more natural motion compared to SFT, as evidenced by qualitative comparisons.

Figure 4: RealDPO alignment significantly improves the naturalness and consistency of generated actions.

Figure 5: RealDPO demonstrates superior visual and semantic alignment compared to reward-model-based methods.
RealAction-5K Dataset
The RealAction-5K dataset is a key contribution, providing high-quality, diverse, and well-annotated videos of human actions. The dataset is constructed via a multi-stage pipeline: keyword-based collection, LLM-based filtering, manual inspection, and automated captioning.
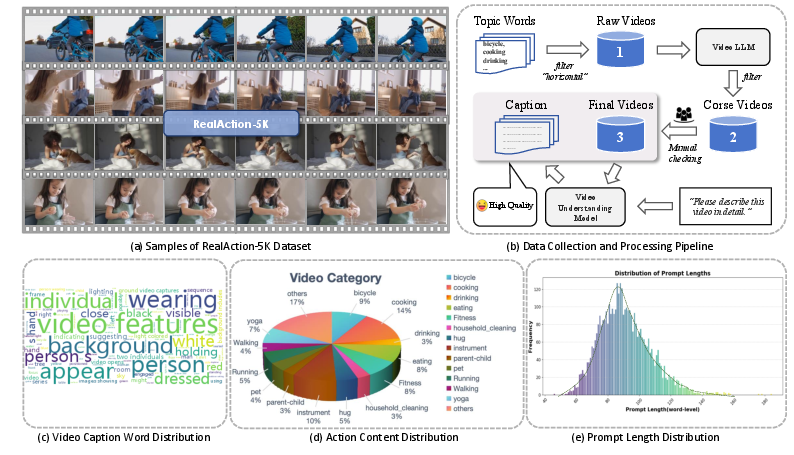
Figure 6: Overview of RealAction-5K, including sample diversity, data processing, and caption statistics.
Trade-offs and Limitations
- Data Efficiency: RealDPO requires fewer high-quality samples than SFT, but the quality of real data is critical for effective alignment.
- Model Constraints: The effectiveness of RealDPO is bounded by the expressiveness of the underlying video generative model.
- Generalization: While RealDPO excels in human action synthesis, its extension to other domains (e.g., non-human motion, abstract scenes) requires further investigation.
Implications and Future Directions
RealDPO advances the upper bound of preference alignment in video generation by directly leveraging real data, offering a scalable and robust alternative to reward-model-based methods. The paradigm is particularly suited for complex motion synthesis, where reward models are insufficient. Future work may explore:
- Domain Extension: Adapting RealDPO to broader video domains, including multi-agent and non-human scenarios.
- Automated Data Curation: Integrating more sophisticated LLMs for automated filtering and annotation.
- Hybrid Alignment: Combining real-data preference learning with weak reward models for domains lacking sufficient real data.
Conclusion
RealDPO presents a data-efficient, robust framework for preference alignment in video generation, leveraging real-world data as win samples and a tailored DPO loss for diffusion-based transformers. The approach demonstrably improves motion realism, text alignment, and overall video quality, outperforming SFT and reward-model-based methods. The introduction of RealAction-5K further supports scalable and effective training. RealDPO sets a new standard for preference alignment in complex motion video synthesis and provides a foundation for future research in multimodal generative modeling.
