MoGAN: Improving Motion Quality in Video Diffusion via Few-Step Motion Adversarial Post-Training
Abstract: Video diffusion models achieve strong frame-level fidelity but still struggle with motion coherence, dynamics and realism, often producing jitter, ghosting, or implausible dynamics. A key limitation is that the standard denoising MSE objective provides no direct supervision on temporal consistency, allowing models to achieve low loss while still generating poor motion. We propose MoGAN, a motion-centric post-training framework that improves motion realism without reward models or human preference data. Built atop a 3-step distilled video diffusion model, we train a DiT-based optical-flow discriminator to differentiate real from generated motion, combined with a distribution-matching regularizer to preserve visual fidelity. With experiments on Wan2.1-T2V-1.3B, MoGAN substantially improves motion quality across benchmarks. On VBench, MoGAN boosts motion score by +7.3% over the 50-step teacher and +13.3% over the 3-step DMD model. On VideoJAM-Bench, MoGAN improves motion score by +7.4% over the teacher and +8.8% over DMD, while maintaining comparable or even better aesthetic and image-quality scores. A human study further confirms that MoGAN is preferred for motion quality (52% vs. 38% for the teacher; 56% vs. 29% for DMD). Overall, MoGAN delivers significantly more realistic motion without sacrificing visual fidelity or efficiency, offering a practical path toward fast, high-quality video generation. Project webpage is: https://xavihart.github.io/mogan.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making AI‑generated videos move more realistically. Today’s video diffusion models can draw single frames that look great, but their motion often looks odd: things shimmer, jitter, ghost, or move in ways that don’t feel real. The authors introduce MoGAN, a simple add‑on training step that teaches a fast video model to produce smoother, more believable motion—without needing human ratings or special “reward” models—and without slowing it down at run time.
The Big Questions (in simple terms)
- Can we fix shaky or unrealistic motion in AI videos while keeping the images pretty?
- Can we teach a fast, few‑step video model to move as well as (or better than) a slower, many‑step model?
- Can we do this using the video’s motion itself (not text judges or human preference data)?
How MoGAN Works (with everyday analogies)
Think of video generation like an artist painting a short animation:
- Diffusion model: Like starting from TV static and “denoising” it into a clean video. Many models need lots of tiny steps (like 50 brush strokes) to get a good result. A “distilled” model learns to do it in only a few big strokes (here, just 3), which is much faster.
- The problem: The usual training goal focuses on getting each frame’s pixels right. It doesn’t directly punish weird motion between frames, so you can get sharp frames that “wiggle” or don’t move realistically.
MoGAN adds two ideas:
- A motion judge that only cares about movement
- Optical flow: Imagine drawing tiny arrows on every pixel showing where it moves from one frame to the next. That’s optical flow—like a wind map of motion.
- Motion critic (discriminator): The model computes these motion arrows for both real videos and generated ones. A “judge” network, which only sees these arrows (not the colors/pixels), learns to tell real motion from fake motion.
- Adversarial training (GAN): The video generator tries to fool the judge by producing motion that looks real in the optical‑flow space. The judge tries to catch it. Over time, the generator learns realistic motion patterns.
- A safety belt to keep looks and style
- Distribution Matching Distillation (DMD): This is like keeping the student artist (the fast 3‑step model) from drifting too far from a skilled teacher (the slower 50‑step model). It helps preserve appearance, text alignment, and overall style while the motion judge pushes on movement.
- Regularization (R1/R2): Extra stabilizers that keep the judge from becoming too harsh or overfitting, so training stays balanced.
Key points:
- The motion judge uses optical flow (the arrows) so it focuses on movement, not color or textures.
- The generator still uses only 3 steps at inference, so it stays fast.
- No human preference labels or external reward models are needed.
What They Found (and why it matters)
Across two standard benchmarks:
- VBench: Motion score improved by about +7.3% over the slow 50‑step teacher and +13.3% over the fast 3‑step baseline (DMD).
- VideoJAM-Bench: Motion score improved by about +7.4% over the teacher and +8.8% over DMD.
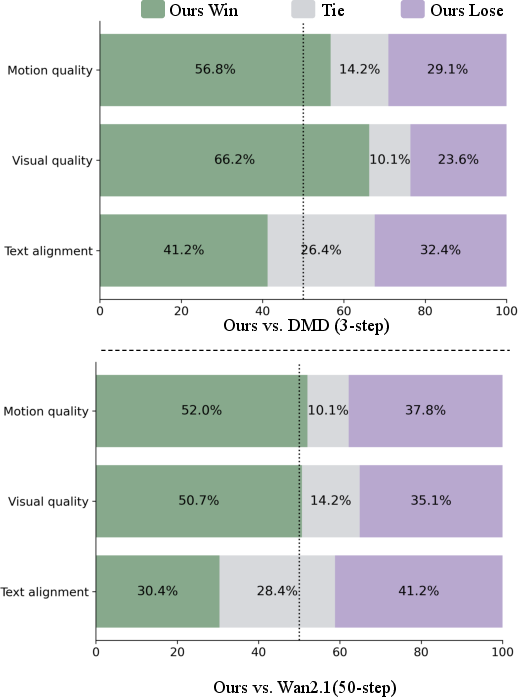
- Human study: People preferred MoGAN’s motion 52% vs. 38% against the teacher, and 56% vs. 29% against DMD.
- Image quality and aesthetics stayed as good as, or better than, the baselines.
- Speed: The model keeps the fast 3‑step sampling path, so it runs much faster than 50‑step models.
Why it matters:
- Many quick video models look nice but feel “flat” or “stiff.” MoGAN brings back natural motion—without sacrificing looks or speed.
- It focuses on the core missing piece (movement) instead of relying on text judges that don’t truly measure motion.
What This Could Change
- Better, more believable AI videos for creators, educators, and storytellers—especially when fast generation is important.
- A simple recipe for upgrading future video models: teach motion with a motion‑only judge, and keep looks with a style‑preserving regularizer.
- A practical alternative to reinforcement learning with reward models, which can be slow, finicky, or miss true motion quality.
A note on limits and future work
MoGAN depends on an optical‑flow tool to read motion. Flow can be less reliable for tiny movements or complicated 3D changes (like objects moving in depth). Future improvements might use 3D‑aware motion or better motion cues inside the model’s latent space.
Key Terms (quick, kid‑friendly explanations)
- Diffusion model: Starts from noise and gradually makes it look like a real picture or video.
- Distillation (teacher–student): The “student” learns to do in a few steps what the “teacher” does in many steps.
- Optical flow: Little arrows that show how each pixel moves from one frame to the next.
- GAN (generator vs. discriminator): The generator creates; the discriminator judges. They improve by competing.
- DMD (Distribution Matching Distillation): Keeps the fast student close to the teacher’s style so it doesn’t lose image quality.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, framed as concrete, actionable directions for future research.
- Sensitivity to optical-flow estimator: quantify how the choice of RAFT (and its training biases) affects adversarial supervision; compare against alternative 2D flow (PWC-Net, GMFlow) and 3D scene-flow or geometry-aware motion fields, especially under occlusions, fast articulation, and out-of-plane motion.
- Flow hacking risk: assess whether the generator learns to exploit RAFT-specific failure modes (e.g., brightness-constancy violations) to “look good” to the motion discriminator while remaining perceptually implausible; develop tests and countermeasures.
- Camera vs. object motion disentanglement: evaluate whether MoGAN improves object-centric dynamics or primarily encourages camera motion; report stratified metrics and datasets isolating these cases.
- Long-horizon behavior: measure motion realism and temporal coherence on substantially longer clips (e.g., 5–20 seconds, higher FPS) beyond the 49-frame window used by the discriminator; test for drift, identity consistency, and accumulation of artifacts.
- Resolution and scalability: characterize performance and stability at higher spatial resolutions (e.g., 1080p/4K) and higher FPS, including memory/compute trade-offs for truncated BPTT and chunked decoding.
- Diversity impacts: examine whether adversarial flow supervision reduces sample diversity or induces mode collapse; add diversity metrics (e.g., LPIPS/feature diversity across seeds) and object/state variation evaluations.
- Motion metric coverage: complement VBench/VideoJAM metrics with explicit flicker/jitter measures, identity preservation over time, and physics plausibility (e.g., gravity consistency, collision handling, velocity/acceleration distributions).
- Semantic/text alignment trade-offs: rigorously quantify the impact of MoGAN on prompt compliance across categories (actions, verbs, spatial relations), and explore mechanisms to mitigate the slight alignment drop relative to 50-step teachers.
- Domain generalization: test on broader datasets (indoor/outdoor, low-light, complex depth, crowds) and prompts requiring fine-grained or subtle motion (e.g., facial micro-expressions), to determine robustness beyond “rich and dynamic” curated data.
- Dataset bias and curation transparency: analyze how the 15K “motion-rich” real videos were selected, potential class/motion-type imbalances, and the effect of such biases on the learned motion statistics.
- Discriminator design ablations: investigate alternative motion features (divergence/curl, occlusion boundaries, per-object flow via segmentation/tracking), multi-scale temporal receptive fields, and sequence-level classifiers beyond adding a magnitude channel.
- Loss formulation choices: compare logistic GAN to WGAN-GP, hinge, or relativistic losses for flow-space adversarial training; provide stability and sample-quality trade-offs.
- Regularization theory and tuning: justify and systematically ablate the nonstandard R1/R2 “noise-invariance” penalties (vs. gradient penalties), including sensitivity to noise σ, weights, and training schedules.
- Joint training of the flow estimator: explore end-to-end training or fine-tuning of the optical-flow network to reduce estimator/model mismatch, and study whether this improves motion supervision or amplifies hacking.
- Conditioning in the discriminator: the motion discriminator is prompted with “a video with good motion” and fixed t*; evaluate whether removing/fixing conditioning is optimal, and whether semantic- or physics-aware conditioning improves motion realism.
- Applicability beyond 3-step distilled models: test MoGAN with 1-step generators, multi-step samplers, or non-DMD distillation frameworks; assess whether clean intermediates are strictly required and how to adapt when they are not.
- Interaction with control/guidance: examine compatibility and synergies with physics priors, motion-prompts, or guidance methods (e.g., real-time warped noise) to achieve both realism and controllability.
- Training stability and reproducibility: report variance across seeds and runs, sensitivity to learning rates/batch sizes, discriminator update ratios, and chunk/window hyperparameters to establish a robust recipe.
- Compute and efficiency reporting: provide detailed training-time memory/compute costs for MoGAN (vs. DMD-only and 50-step), including the overhead of decoding, flow computation, and truncated BPTT.
- Identity and appearance consistency: add objective and human evaluations for identity preservation, texture stability, and color consistency across frames to substantiate claims of “not sacrificing visual fidelity.”
- Evaluation breadth vs. baselines: include direct comparisons to RL post-training with motion-specific rewards (DPO/GRPO variants) and recent training-free temporal stabilizers (e.g., FlowMo) across multiple datasets and settings.
- Motion amplitude calibration: verify that MoGAN’s increase in “dynamics degree” does not overshoot realistic motion; introduce prompts where subtle or minimal motion is desired and evaluate motion amplitude control.
- Integration of physics constraints: explore hybrid objectives combining flow-space GAN with physics-inspired priors (e.g., rigid-body constraints, scene-aware dynamics) to address non-physical artifacts noted in the discussion.
- Latent-space motion surrogates: investigate whether latent flow or feature-space temporal statistics can replace pixel-space decoding to reduce training cost while preserving motion learning.
- Failure-case catalog: systematically document scenarios where MoGAN degrades motion or appearance (e.g., rapid scene changes, heavy occlusions), enabling targeted fixes and benchmarks.
Practical Applications
Immediate Applications
The following applications can be deployed now by practitioners using current video diffusion stacks (e.g., Wan2.1-T2V-1.3B) and the post-training recipe presented in the paper. Each item notes sector relevance, potential tools/products/workflows, and dependencies or assumptions.
- Motion-enhanced text-to-video generation for creative production
- Sector: Media and entertainment, advertising, social media
- What: Fine-tune existing few-step T2V models with MoGAN to reduce jitter, ghosting, and flicker while preserving aesthetics and speed (3-step sampling).
- Tools/products/workflows: “MoGAN Post-Training” as a fine-tuning job on top of Wan/DMD; add a “Motion QA gate” (flow-based scoring) in render pipelines; seed sweep + motion-score selection.
- Assumptions/dependencies: Access to a pretrained generator (e.g., Wan2.1), a motion-rich real video set for adversarial training (e.g., ~15K clips), RAFT (or equivalent) flow estimator, and GPU capacity for short fine-tuning (≈800 steps). Slightly weaker text alignment than full-step models may require prompt iterations.
- Motion QA and automated quality gating for generation pipelines
- Sector: Software for creative operations, MLOps for generative systems
- What: Use the trained flow-space discriminator as a runtime “motion realism” score to filter or rank outputs (e.g., auto-reject low-motion or jittery clips).
- Tools/products/workflows: A “Flow-based Motion Validator” plugin/API; batch scoring for A/B creative variants; integration into CI/CD for model releases.
- Assumptions/dependencies: Reliable optical flow estimation on decoded frames; decoding chunking and checkpointing for efficiency; acceptance of flow-based scores as a proxy for motion quality.
- Faster content iteration and ideation loops
- Sector: Marketing, product design, education content creation
- What: Exploit MoGAN’s few-step speed to generate many candidates quickly, then use motion scores to pick the best for human review and final polishing.
- Tools/products/workflows: “Rapid Variation Studio” workflows combining prompt banks + seed sweeps + motion scoring; curated handoff to editors.
- Assumptions/dependencies: Motion-score correlates with perceived quality; content teams can adopt automated pre-screening.
- Live or near-real-time generative backgrounds and motion overlays
- Sector: Streaming, events, virtual production
- What: Deploy 3-step MoGAN models to drive smooth dynamic backgrounds, lower-thirds, and ambient motion loops without distracting artifacts.
- Tools/products/workflows: “Motion-safe” T2V loop generator with flow validation; trigger-based scene changes managed by motion QA thresholds.
- Assumptions/dependencies: Stable inference latency on target hardware; acceptable text alignment for lower-demand overlays vs. narrative content.
- Post-processing enhancement for pre-existing generations
- Sector: Video editing software
- What: Re-generate problematic clips from legacy models using MoGAN post-trained models to improve motion coherence while matching target look.
- Tools/products/workflows: “Motion Repair” batch tool that re-prompts or re-seeds with MoGAN and compares flow statistics.
- Assumptions/dependencies: Access to the original prompts or the ability to approximate them; time budget for re-generation.
- Dataset curation and filtering for motion-rich training corpora
- Sector: ML data engineering
- What: Use the flow-space discriminator to select real videos with diverse, clean motion for future training or evaluation sets.
- Tools/products/workflows: “Flow-based Curator” that scores candidate videos by motion realism/variety before ingestion.
- Assumptions/dependencies: Discriminator generalizes to real data modalities; RAFT’s 2D flow is sufficiently informative across domains.
- Academic benchmarking and ablation frameworks
- Sector: Academia
- What: Adopt MoGAN’s flow-adversarial post-training as a reproducible baseline when studying motion fidelity, few-step distillation, and GAN-in-diffusion techniques.
- Tools/products/workflows: Public benchmarks (VBench, VideoJAM) with motion-score reporting; standardized ablation protocols (w/ and w/o DMD, R1/R2).
- Assumptions/dependencies: Availability of open weights, reproducible training scripts, and consistent metric implementations.
- Efficient motion-focused model evaluation
- Sector: Research tools
- What: Apply the motion discriminator as an evaluative signal for model selection during hyperparameter sweeps, reducing reliance on expensive human studies.
- Tools/products/workflows: “Motion-first model selection” dashboards plotting motion-score vs. aesthetics; automated early stopping criteria.
- Assumptions/dependencies: The flow discriminator’s scores track human judgments for the target distribution.
- Synthetic data generation with improved motion for downstream ML tasks
- Sector: Robotics simulation-to-real transfer, autonomous driving perception pretraining
- What: Generate videos with realistic dynamics to pretrain motion-sensitive perception modules (e.g., optical flow, action recognition) or augment datasets.
- Tools/products/workflows: Synthetic corpora pipelines using MoGAN as the generator; motion-aware sampling strategies to diversify dynamics.
- Assumptions/dependencies: 2D flow realism aids target tasks; domain gap manageable; no need for strict physical accuracy.
Long-Term Applications
These applications will benefit from further research, scaling, and engineering development, particularly in geometry-aware motion, longer horizons, and safety considerations.
- Geometry/physics-aware motion discriminators
- Sector: Software, robotics, simulation
- What: Extend the motion GAN to 3D-consistent flow or scene flow, occlusion reasoning, and physically grounded dynamics to mitigate 2D flow’s limitations.
- Tools/products/workflows: “3D Motion-GAN” leveraging multi-view or depth estimation; physics priors integrated into the discriminator or generator.
- Assumptions/dependencies: Reliable 3D motion estimation at scale; efficient decoders; robust training stability with richer signals.
- High-FPS, long-horizon generative video
- Sector: Film, TV, gaming, VR/AR
- What: Scale MoGAN to minutes-long sequences and higher frame rates, preserving motion coherence across scenes, cuts, and camera moves.
- Tools/products/workflows: Truncated BPTT and memory-efficient decoding for long clips; hierarchical discriminators with multi-scale motion heads.
- Assumptions/dependencies: Advanced memory management, chunked decoding, and efficient flow estimation; strong prompt plan and scene continuity tooling.
- Real-time interactive generative cinematography
- Sector: Virtual production, interactive storytelling
- What: Combine few-step generation with live control (camera trajectories, actor beats) while keeping motion consistent in response to user inputs.
- Tools/products/workflows: “Director’s Console” with motion-safe generative camera rigs; controller APIs for motion amplitude and smoothness.
- Assumptions/dependencies: Low-latency inference plus motion feedback loops; robust guidance signals that don’t destabilize dynamics.
- Motion-aware alignment and safety controls
- Sector: Policy, platform trust and safety
- What: Design platform policies and tooling that monitor motion realism in synthetic videos (e.g., deepfake risk indicators, watermark conditions), and enforce safety gates (e.g., detect implausible accelerations).
- Tools/products/workflows: Flow-space anomaly detectors; policy dashboards linking motion metrics to content moderation; disclosures for generated motion realism.
- Assumptions/dependencies: Regulatory consensus on motion-based risk signals; reliable detectors across content domains.
- Motion-conditioned editing and control tools
- Sector: Post-production, creator tools
- What: Allow users to edit motion properties (e.g., speed, amplitude, smoothness) via knobs, with MoGAN-like discriminators ensuring realism after edits.
- Tools/products/workflows: “Motion Stylizer” panels inside NLEs and compositors that re-generate sequences under motion constraints.
- Assumptions/dependencies: Stable inference with controllable motion parameters; intuitive UI and prompt-to-motion mapping.
- Latent-space motion surrogates for scalable training
- Sector: Foundation model training
- What: Replace pixel-space flow with latent motion representations to reduce decoding costs while retaining motion supervision.
- Tools/products/workflows: “Latent Flow” encoders; joint training of generator and motion surrogate; hybrid adversarial objectives.
- Assumptions/dependencies: High-fidelity latent motion features; differentiable, efficient surrogate models; validated correlation with perceived motion.
- Domain-specific motion realism (sports, medical, industrial processes)
- Sector: Sports analytics, healthcare education, manufacturing
- What: Train specialized discriminators on domain motion (e.g., sports biomechanics, surgical procedures) to generate instructive, realistic dynamics for training and simulation.
- Tools/products/workflows: Domain-tailored motion datasets and discriminators; curriculum prompts; integration with training simulators.
- Assumptions/dependencies: Access to high-quality domain data; expert labeling of motion realism; alignment with pedagogical goals.
- Energy-efficient generative pipelines
- Sector: Sustainability in AI operations
- What: Use few-step, motion-stable generation to reduce compute per clip while meeting creative quality targets, informing organizational sustainability policies.
- Tools/products/workflows: “Green GenOps” scorecards combining motion, aesthetics, and energy per minute generated; budget-aware rendering schedulers.
- Assumptions/dependencies: Accurate energy accounting; acceptance of motion-centric KPIs; organizational buy-in.
- Detection and provenance tools for synthetic motion
- Sector: Policy, cybersecurity, platform integrity
- What: Develop flow-space detectors and provenance signals that identify synthetic motion patterns and watermark dynamics for provenance tracking.
- Tools/products/workflows: Motion watermarking aligned with flow statistics; verification APIs for platforms; audit trails for generative media.
- Assumptions/dependencies: Robustness to adversarial attacks; interoperability with existing provenance standards; minimal false positives.
Cross-cutting assumptions and dependencies
Adoption feasibility across the above applications depends on:
- Hardware and software: Access to pretrained T2V models (e.g., Wan2.1), GPU resources for short fine-tuning, and efficient decoding/flow computation (chunked decoding, checkpointing).
- Data: Availability of motion-rich real video datasets; licensing and ethical sourcing compliant with organizational policies.
- Model behavior: RAFT-based 2D flow as a proxy for motion realism; potential misinterpretations for occlusions, out-of-plane motion, small motions, or complex depth changes.
- Trade-offs: Slight text alignment reductions in few-step distilled models; need for prompt engineering or hybrid pipelines when alignment is critical.
- Governance: Risk management for more realistic synthetic motion (deepfakes); policy frameworks and provenance tooling to ensure responsible deployment.
Glossary
- AdamW: An optimizer that combines Adam with decoupled weight decay to improve generalization in deep networks. "The optimization uses AdamW with a learning rate of ."
- Adversarial objective in dense optical flow space: A GAN-style training signal applied to sequences of optical flow fields to encourage realistic motion. "we introduce an adversarial objective in dense optical flow space."
- all-pairs 4D correlation volume: A tensor capturing similarities between all pixel pairs across two feature maps, used for precise flow estimation. "builds an all-pairs 4D correlation volume "
- auxiliary token: An additional learned token used in attention mechanisms to aggregate or guide information for prediction. "each using cross-attention with an auxiliary token followed by a small MLP"
- Backward simulation: A DMD procedure that reconstructs cleaner intermediates by simulating the generative process in reverse. "Backward simulation~\cite{yin2024dmd2} with to get "
- brightness constancy: The assumption that pixel intensity of a point remains constant between frames, foundational for optical flow. "typically under brightness constancy ."
- chunk-recurrent Wan decoder: A decoder that processes video latents in recurrent chunks to handle long sequences efficiently. "chunk-recurrent Wan decoder~\cite{wan2025wan}, which is slow and memory-intensive."
- cross-attention: An attention mechanism where one sequence attends to another (e.g., motion features attending to learned tokens). "each using cross-attention with an auxiliary token followed by a small MLP"
- Diffusion Adversarial Post-Training: A method that adversarially fine-tunes diffusion generators against real data to improve realism. "Diffusion Adversarial Post-Training~\cite{lin2025seaweedAPT} adversarially fine-tunes one-step generators against real data."
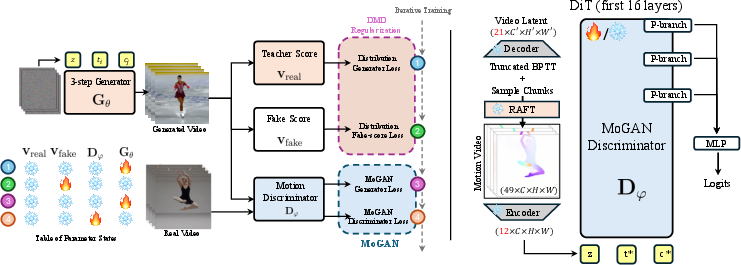
- Diffusion Transformer (DiT): A transformer architecture tailored for diffusion models, used here to build the motion discriminator. "A Diffusion Transformer (DiT) based discriminator receives only the flow sequence"
- Distribution Matching Distillation (DMD): A distillation framework that trains a few-step student to match the teacher’s intermediate distributions. "Under the distribution matching distillation (DMD~\cite{yin2023dmd, yin2024dmd2}) settings"
- dynamics degree: A metric quantifying how much and how naturally motion occurs in generated videos. "we adopt the motion smoothness and dynamics degree metrics from VBench"
- Flow matching (FM): A training paradigm that fits a velocity field to transport samples from prior to data along a prescribed path. "Under flow matching (FM), we fit a time-dependent velocity field "
- gradient checkpointing: A memory-saving technique that recomputes activations during backprop to enable training larger models or sequences. "we combine truncated backpropagation through time (BPTT), gradient checkpointing, and chunk subsampling/early stopping"
- initial-value ODE: An ordinary differential equation solved from an initial condition to generate samples in flow/diffusion models. "generate samples by solving the initial-value ODE: "
- latent chunks: Segments of latent sequences processed in parts to handle long videos efficiently in memory and compute. "we use 12 latent chunks corresponding to 49 frames in pixel space."
- logistic GAN loss: The standard GAN loss using the softplus/logistic formulation for discriminator and generator objectives. "We adopt the logistic GAN loss~\cite{goodfellow2014gan}"
- mode collapse: A GAN failure mode where the generator produces limited diversity to exploit the discriminator. "yielding mode collapse and temporal artifacts in Fig.~\ref{fig:ablation_1}."
- motion discriminator: A discriminator that evaluates the realism of motion (e.g., optical flow sequences) rather than raw pixels. "A motion discriminator consumes flow and outputs a real value"
- motion score: A combined metric (average of smoothness and dynamics degree) to assess overall motion quality. "motion score defined as the mean of motion smoothness (based on frame interpolation) and dynamics degree (based on optical flow)"
- optical flow: A dense field of per-pixel displacements between consecutive frames representing apparent motion. "Optical flow provides a low-level, motion-centric representation that abstracts away appearance"
- P-Branch: A lightweight prediction branch attached at multiple layers of the discriminator to make multi-scale motion judgments. "(P-Branch in Figure~\ref{fig:pipeline} (right))"
- RAFT: A state-of-the-art optical flow method using recurrent updates and correlation volumes for accurate motion estimation. "We adopt RAFT~\cite{teed2020raft}"
- R1 and R2 regularization: Regularizers applied to discriminator outputs to stabilize GAN training and prevent overfitting. "We apply R1 and R2 regularization~\cite{roth2017stabilizing} on the discriminator"
- truncated backpropagation through time (BPTT): Backpropagating gradients through a limited temporal window to control memory/compute in sequence models. "we combine truncated backpropagation through time (BPTT), gradient checkpointing, and chunk subsampling/early stopping"
- VBench: A benchmark suite for evaluating video generation across motion and quality dimensions. "On VBench, MoGAN boosts motion score by +7.3\% over the 50-step teacher and +13.3\% over the 3-step DMD model."
- VideoJAM-Bench: A benchmark emphasizing motion-aware evaluation of generated videos. "On VideoJAM-Bench, MoGAN improves motion score by +7.4\% over the teacher and +8.8\% over DMD"
- vision-language reward models: Models that score videos/images with text to provide reward signals for RL-based post-training. "rely on vision-language reward models that evaluate only a small number of sampled frames"
Collections
Sign up for free to add this paper to one or more collections.