Single-stream Policy Optimization (2509.13232v1)
Abstract: We revisit policy-gradient optimization for LLMs from a single-stream perspective. Prevailing group-based methods like GRPO reduce variance with on-the-fly baselines but suffer from critical flaws: frequent degenerate groups erase learning signals, and synchronization barriers hinder scalability. We introduce Single-stream Policy Optimization (SPO), which eliminates these issues by design. SPO replaces per-group baselines with a persistent, KL-adaptive value tracker and normalizes advantages globally across the batch, providing a stable, low-variance learning signal for every sample. Being group-free, SPO enables higher throughput and scales effectively in long-horizon or tool-integrated settings where generation times vary. Furthermore, the persistent value tracker naturally enables an adaptive curriculum via prioritized sampling. Experiments using Qwen3-8B show that SPO converges more smoothly and attains higher accuracy than GRPO, while eliminating computation wasted on degenerate groups. Ablation studies confirm that SPO's gains stem from its principled approach to baseline estimation and advantage normalization, offering a more robust and efficient path for LLM reasoning. Across five hard math benchmarks with Qwen3 8B, SPO improves the average maj@32 by +3.4 percentage points (pp) over GRPO, driven by substantial absolute point gains on challenging datasets, including +7.3 pp on BRUMO 25, +4.4 pp on AIME 25, +3.3 pp on HMMT 25, and achieves consistent relative gain in pass@$k$ across the evaluated $k$ values. SPO's success challenges the prevailing trend of adding incidental complexity to RL algorithms, highlighting a path where fundamental principles, not architectural workarounds, drive the next wave of progress in LLM reasoning.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching LLMs to reason better using reinforcement learning (RL). The authors point out problems with a popular training style called “group-based” learning (like GRPO), and introduce a simpler, faster, and more reliable method called Single-stream Policy Optimization (SPO). SPO helps the model learn from every example without wasting time waiting for slow or unhelpful cases.
What questions are the authors trying to answer?
In simple terms, the paper asks:
- How can we train LLMs to reason better without wasting compute or getting unstable learning signals?
- Can we avoid the problems of group-based methods (like when all answers in a group are the same, so there’s nothing to learn)?
- Can we design a method that scales well when tasks take different amounts of time (for example, when the model uses tools or does long, multi-step reasoning)?
How does the method work?
First, a quick idea of RL here: the model sees a question (prompt), makes an answer, and gets a reward (for example, 1 if correct, 0 if wrong). Training adjusts the model to make good answers more likely.
Why group-based methods struggle
Group-based methods (like GRPO) generate several answers for the same prompt at once and compare them to create a learning signal. But they have two big issues:
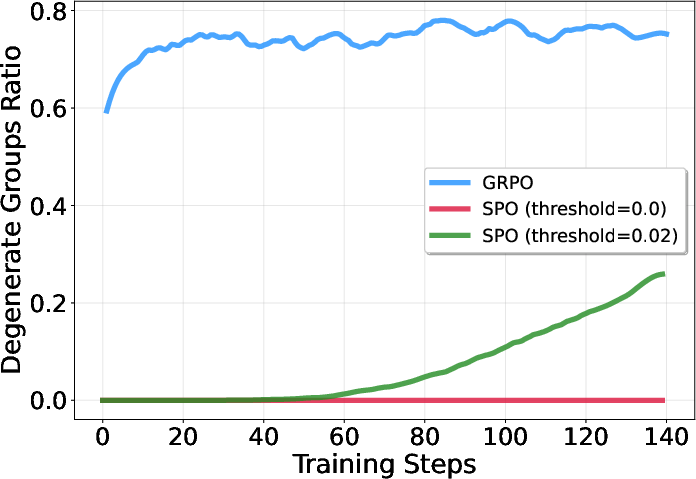
- Degenerate groups: If all answers are correct or all are wrong, the “difference” between them is zero. That means the model gets no learning signal, and all that compute is wasted.
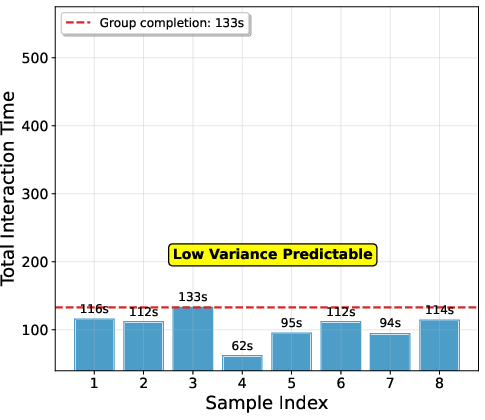
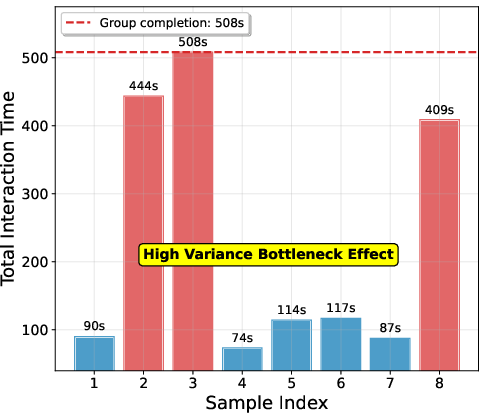
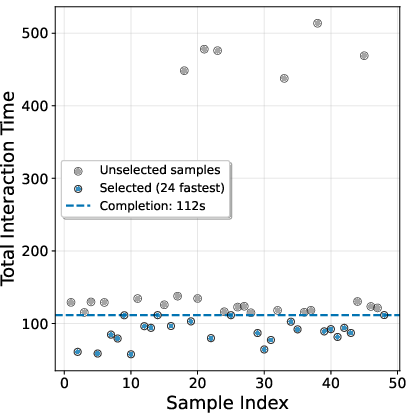
- Waiting on the slowest: In distributed systems, the whole group must finish before training can proceed. If one answer takes a long time (for example, a long tool-use chain), everything waits. This slows training a lot.
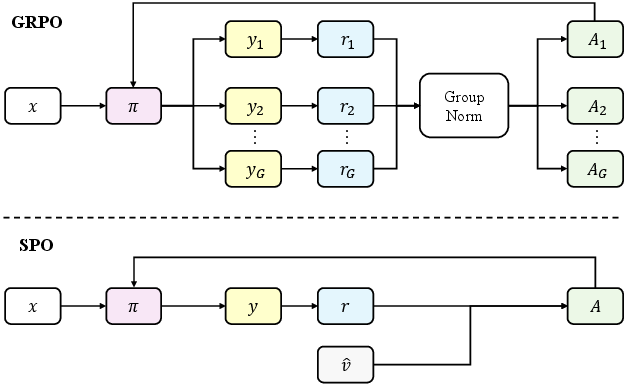
The new idea: Single-stream Policy Optimization (SPO)
Instead of using groups, SPO learns from one answer per prompt and still keeps the learning signal stable and strong. You can think of it like grading each answer against a fair, running estimate of how hard that question is.
SPO has three main parts:
- A persistent value tracker (the “fair score”)
- Imagine keeping a small record for each question: how often the model has gotten it right in the past. That record is the “value tracker.”
- It updates over time using a simple, statistics-friendly rule (like an adaptive moving average). If the model changes a lot (measured by how different its behavior is now vs. before), the tracker “forgets” older data faster so it stays current.
- This tracker acts as a baseline or expected score. The learning signal becomes “how much better or worse than expected was this answer?”
- Batch-wide normalization
- Instead of normalizing within a small group (which is noisy), SPO normalizes the learning signal across the whole batch of different prompts. This makes the signal smoother and more reliable.
- Prioritized sampling (an adaptive curriculum)
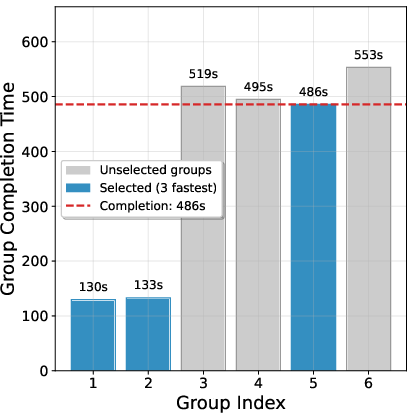
- SPO picks prompts that are most informative to train on next: not too easy (almost always correct) and not too hard (almost always wrong), but in the middle where the model can learn the most. It still keeps some randomness so it doesn’t ignore other prompts.
One more detail: SPO uses a careful update rule (similar to PPO-Clip) to avoid making giant, risky changes to the model all at once.
What did the experiments show?
Here’s what the authors found when training a Qwen3-8B model on hard math problems (with tool use like a Python interpreter) and testing on tough benchmarks (AIME 24, AIME 25, BeyondAIME, BRUMO 25, HMMT 25):
- Better accuracy and smoother training:
- On average, SPO beats GRPO by +3.4 percentage points on a key metric (maj@32).
- Notable gains include: +7.3 points on BRUMO 25, +4.4 on AIME 25, and +3.3 on HMMT 25.
- What is “maj@32”? The model tries each problem up to 32 times with different samples; if the majority of those tries are correct, it counts as correct. This measures consistency, not just luck.
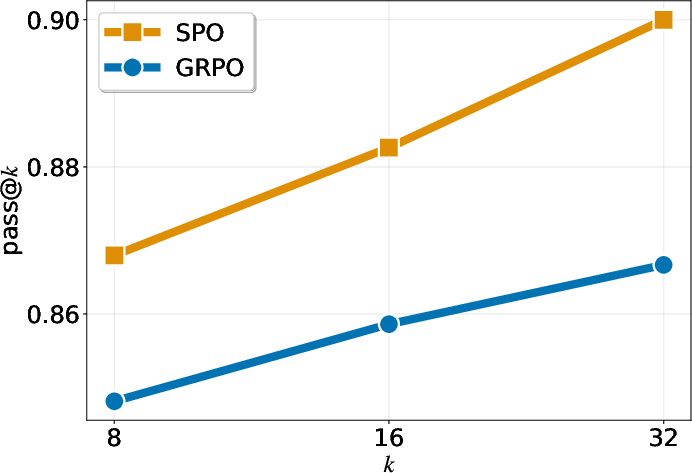
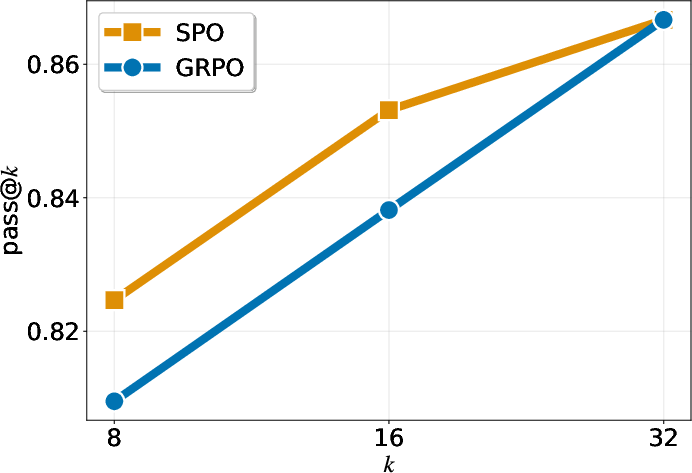
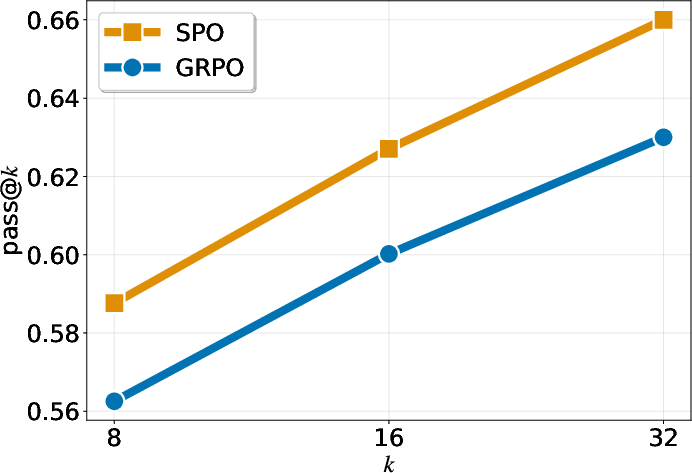
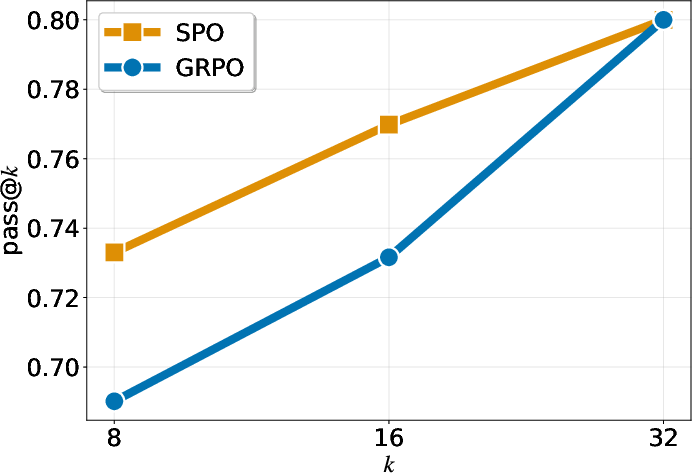
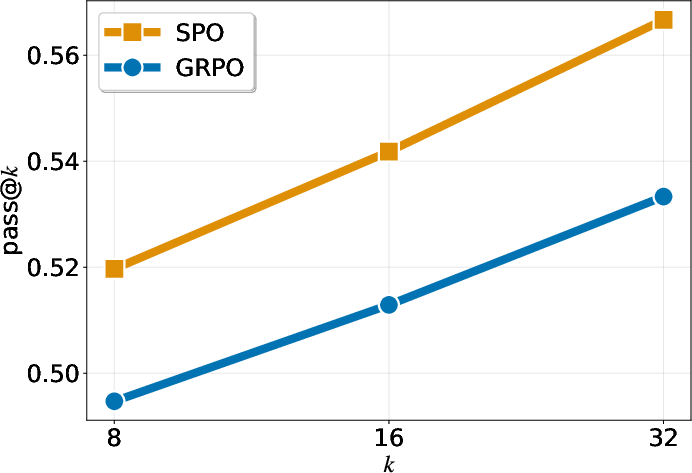
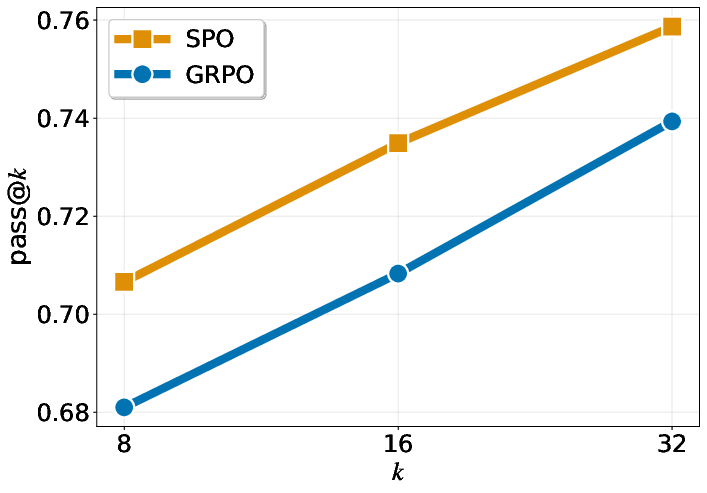
- “pass@k” (another metric) also improves across different values of k, meaning the probability of getting at least one correct answer within k tries is higher with SPO.
- Less wasted compute:
- GRPO often creates “degenerate groups” (all right or all wrong), producing zero learning signal. SPO avoids that. In SPO, even small or near-zero signals typically mean “the tracker predicted well,” not “no learning possible.”
- More stable learning signals:
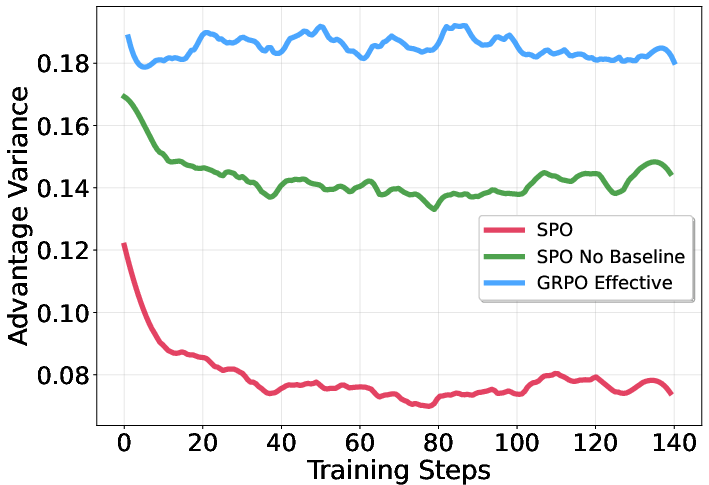
- SPO’s baseline (the value tracker) makes the signal less noisy than GRPO’s on-the-fly, per-group measurements. Less noise means more reliable training.
- Much better speed in “agentic” settings:
- In simulations where some tasks take much longer than others (like when the model does multi-step tool use), SPO’s group-free design avoids waiting for stragglers.
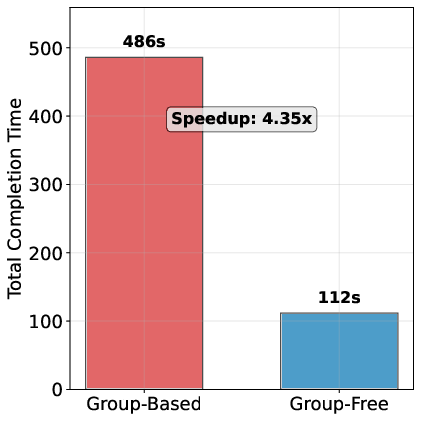
- Result: a 4.35× speedup in training throughput in a realistic long-tail timing scenario.
Why does this matter?
- Simpler and stronger: SPO is simpler than group-based methods (no need to generate multiple answers per prompt), yet it works better. It shows that solid fundamentals can beat complicated workarounds.
- Scales to real-world use: Because it doesn’t wait on groups, SPO is well-suited for advanced tasks where the model uses tools, browses, or plans over many steps—settings where some attempts naturally take longer.
- Efficient and principled: SPO keeps a persistent, adaptive estimate of “how hard this prompt is for the current model,” normalizes signals in a stable way, and focuses training where it helps most.
In short, SPO helps LLMs learn reasoning more efficiently, wastes less compute, trains faster in complex scenarios, and improves accuracy—without adding a lot of extra complexity.
Knowledge Gaps
Below is a concise, actionable list of knowledge gaps, limitations, and open questions left unresolved by the paper:
- Unbiasedness under prioritized prompt sampling: the method reweights the prompt distribution via w_i(x) without importance-correction; how biased is the learned policy relative to the target data distribution, and when (if ever) are IS corrections necessary?
- Generality beyond binary rewards: the paper claims easy generalization to non-binary rewards via EMA but provides no derivation, stability analysis, or empirical validation for continuous or multi-objective reward settings (e.g., outcome + format + cost).
- Credit assignment in multi-step/agentic settings: SPO treats an entire multi-turn/tool-using interaction as a single action with a sequence-level advantage; how to extend SPO to step-wise/turn-level returns and advantages with partial/intermediate rewards?
- Value-tracker KL computation: the KL-adaptive forgetting requires D(x) between the current policy and “the last policy that acted on x,” but the paper does not specify how D(x) is computed efficiently and accurately (token-level vs sequence-level, reference policy vs stored logits, cost at scale).
- Memory and scalability of the tabular tracker: storing Beta/EMA state per prompt may be feasible for 16k items but becomes memory-heavy for millions of prompts; what are memory/latency costs and data-structure strategies at web-scale?
- Cold-start cost and practicality: the required n0=8 offline samples per prompt can be substantial; the paper does not quantify the net compute vs GRPO (including dynamic sampling) or offer principled ways to amortize/reuse initial estimates across policies/datasets.
- Staleness for infrequently sampled prompts: the tracker’s forgetting relies on per-prompt KL with the last-acting policy; how is D(x) computed when a prompt has not been visited for many steps, and does staleness produce biased or high-variance advantages?
- Sensitivity to D_half, ρ_min/ρ_max, and ε (priority floor): there is insufficient ablation or guidance on hyperparameter sensitivity, interactions, and default-setting robustness across tasks and model sizes.
- Global advantage normalization under biased batches: batch-wise standardization mixes prompts sampled via a non-uniform curriculum; what are the stability and bias implications relative to per-prompt or robust normalization schemes?
- Length bias and token-level credit: SPO applies a single sequence-level advantage to all tokens, which can introduce length bias; how does it compare to length-aware baselines (e.g., OPO) or per-token credit assignment in long generations?
- Robustness to reward noise and verifier errors: the tracker assumes reliable binary feedback; how sensitive is SPO to mislabeled outcomes or flaky verifiers, and can the tracker incorporate uncertainty/robust updates?
- Empirical scope limited to math reasoning (Qwen3-8B): generalization to other domains (coding, instruction following, RLHF with preference models), larger models, and multilingual settings is untested.
- Limited baselines: comparisons are solely against GRPO; empirical evaluations against RLOO, OPO, PPO-with-critic, A*-PO, and strong dynamic-sampling variants are missing.
- Real-system throughput evidence: the 4.35× speedup is simulation-based; no real cluster, wall-clock, or cost-per-quality measurements are provided under realistic tool latencies and straggler behavior.
- Interaction with KL regularization and entropy control: while compatible with PPO-Clip and entropy-preserving variants (Clip-Higher, KL-Cov), the paper does not analyze how the tracker and batch normalization behave under varying KL penalties/entropy targets.
- Handling unseen/streaming prompts: the tabular tracker does not generalize across prompts; how to initialize and adapt values for unseen items in streaming or expanding datasets, and would a learned value approximator improve cold-start/generalization?
- Curriculum side effects: prioritized sampling may narrow coverage and overfit to “borderline” prompts; beyond a fixed ε, what mechanisms ensure distributional coverage and prevent curriculum collapse?
- Safety/behavioral drift: absent an explicit KL-to-reference penalty, how does SPO control policy drift and ensure safe/benign outputs in broader RLHF settings?
- Advantage variance theory and guarantees: while empirical variance plots are shown, a formal analysis of variance properties under batch normalization and prioritized sampling (with/without IS) is missing.
- Tool-integrated credit and environment variability: the method abstracts away tool latencies and partial progress signals; how to incorporate environment feedback (e.g., tool success rates, intermediate checks) into the value tracker and policy updates?
- Tracker update ordering and bias: updating the tracker immediately after observing r(x,y) while computing A(x,y) with v_{-1}(x) preserves action-independence; however, multi-epoch PPO updates reuse samples—does tracker evolution across epochs introduce subtle biases?
- Robust normalization under heavy-tailed advantages: the paper uses mean/std; alternatives (e.g., median/IQR, clipping) for heavy-tailed or multimodal advantage distributions are not explored.
- Fairness and stability of repeated sampling: focusing on high-uncertainty prompts may repeatedly sample a subset of items; what are the impacts on fairness across data subgroups and on catastrophic forgetting of already-mastered prompts?
- Implementation details for D(x) and storage: the required bookkeeping (last-acting policy snapshot per prompt, KL computation, tracker state) is not concretely specified; practical recipes and systems guidance are needed.
- Limits of SPO in sparse-success regimes: while the tracker aims to stabilize sparse rewards, the paper does not characterize the regime (success probability p) where SPO’s advantages over GRPO or dynamic sampling are largest/smallest.
These gaps suggest concrete directions: add IS-corrected prioritized sampling baselines; extend to step-wise returns and non-binary rewards with theory and experiments; provide real-system throughput studies; compare against broader baselines; analyze hyperparameter sensitivity; and develop scalable, generalizing value estimators and robust normalization techniques.
Collections
Sign up for free to add this paper to one or more collections.