- The paper introduces SAPO, a decentralized RL algorithm that achieves a 94% cumulative reward improvement by balancing local and external rollouts.
- It employs asynchronous, multi-agent experience sharing to enhance policy gradient updates and stabilize training in heterogeneous networks.
- Empirical results show that optimal local/external balance not only accelerates learning but also outperforms traditional RL approaches in resource-constrained environments.
Efficient LM Post-Training via Decentralized RL Experience Sharing: The SAPO Algorithm
Introduction
The paper presents Swarm sAmpling Policy Optimization (SAPO), a fully decentralized and asynchronous RL post-training algorithm for LMs. SAPO is designed to operate in heterogeneous, distributed networks where each node manages its own policy and shares decoded rollouts with others, enabling collaborative learning without synchronization or homogeneity constraints. The approach is motivated by the need to scale RL post-training for LMs efficiently, circumventing the latency, memory, and reliability bottlenecks of conventional distributed RL systems. The empirical results demonstrate that SAPO achieves up to 94% cumulative reward improvement over standard RL fine-tuning in controlled experiments, and provides insights from large-scale open-source deployments.
Methodology: Swarm Sampling Policy Optimization (SAPO)
SAPO formalizes RL post-training in a decentralized multi-agent setting. Each node in the swarm maintains its own policy πn, dataset Dn, and reward model ρn. Training proceeds in rounds, where each node:
- Samples a batch of tasks/questions.
- Generates multiple completions (rollouts) per question.
- Shares a subset of its rollouts, along with metadata and ground-truth answers, with the swarm.
- Constructs its training set by subsampling In local and Jn external rollouts (from the swarm).
- Computes rewards and updates its policy using a policy-gradient algorithm (e.g., PPO, GRPO).
This process is fully asynchronous and decentralized; nodes can filter, subsample, and re-encode external rollouts as needed. The algorithm is agnostic to model architecture, learning algorithm, and hardware, supporting both homogeneous and heterogeneous swarms.
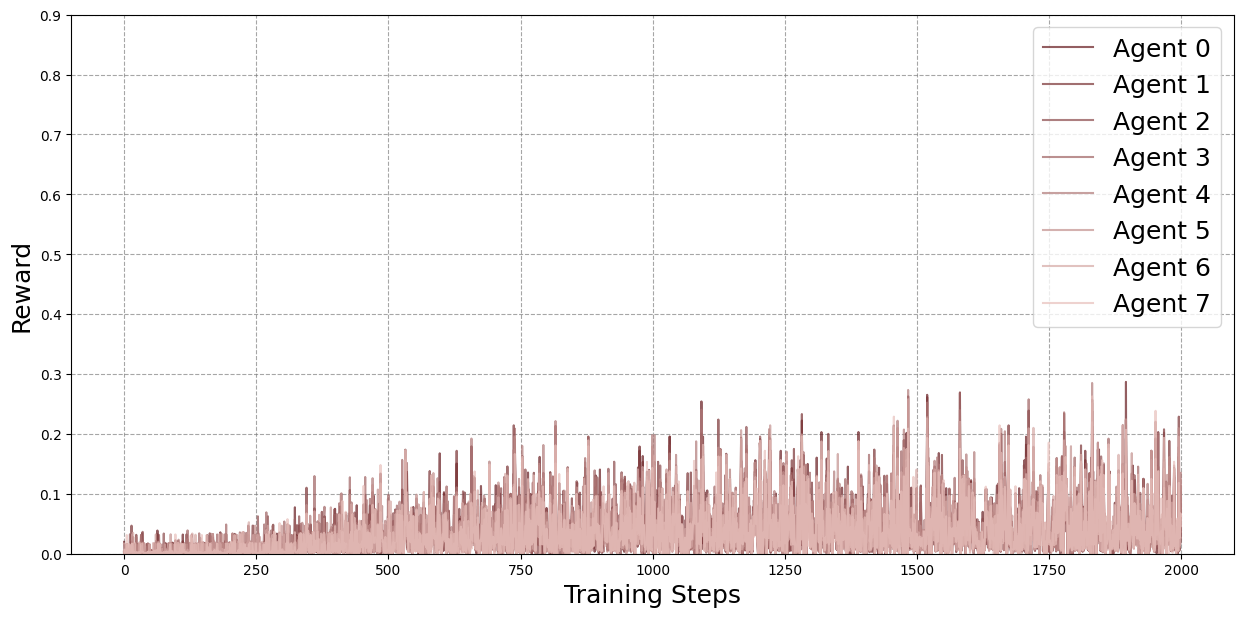
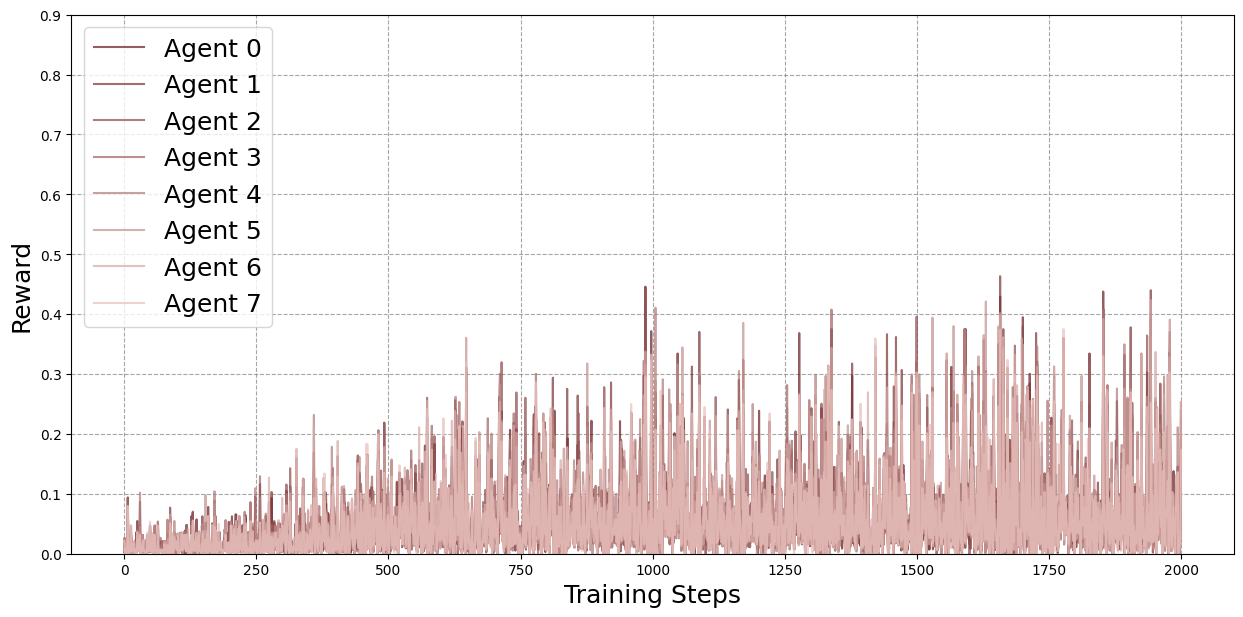
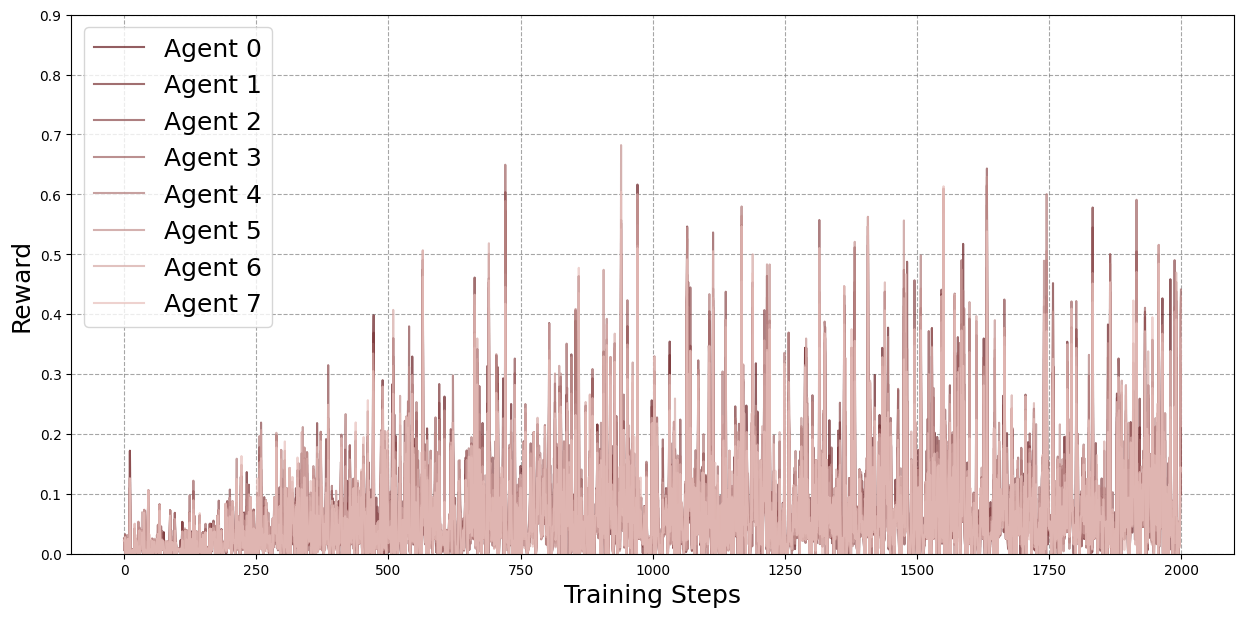
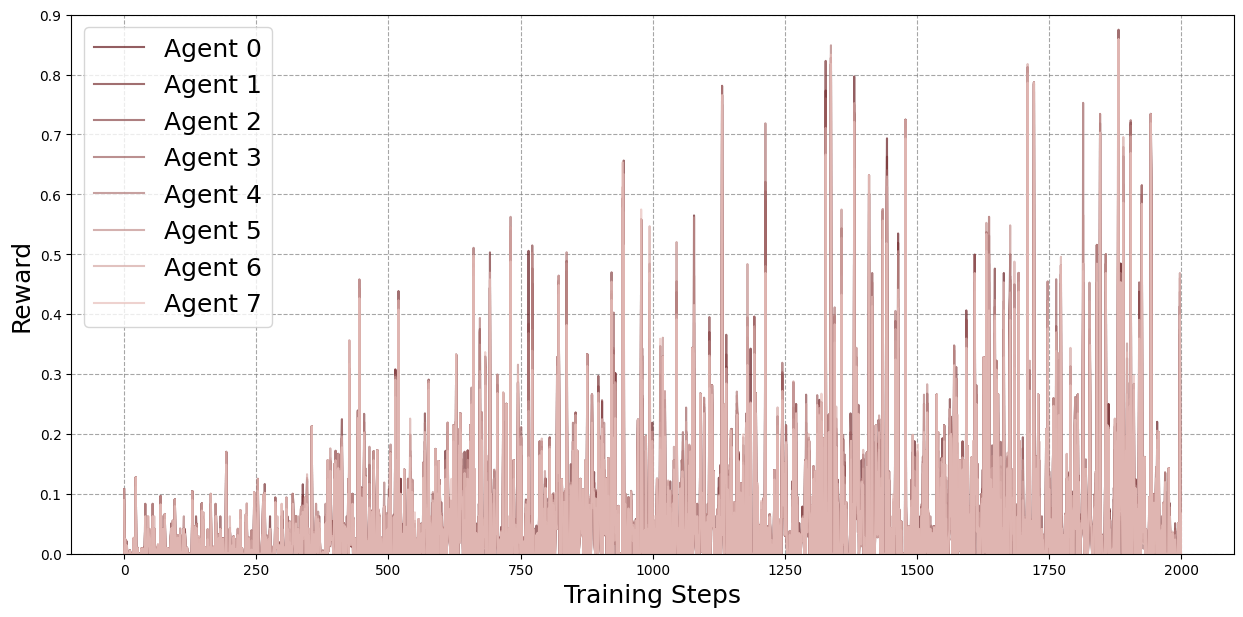
Figure 1: Baseline case, i.e.~8 local / 0 external rollouts.
Controlled Experiments: Setup and Results
Experiments were conducted using a swarm of eight Qwen2.5 models (0.5B parameters each), orchestrated via Docker and PyTorch distributed. The ReasoningGYM dataset provided procedurally generated, verifiable tasks across symbolic, numeric, and abstract reasoning domains. Each agent generated 8 completions per question, and policies were updated using GRPO with asymmetric clipping and no KL penalty.
Four configurations were evaluated: 8 local/0 external (baseline), 6 local/2 external, 4 local/4 external, and 2 local/6 external rollouts per agent per round. The total number of training samples was held constant.
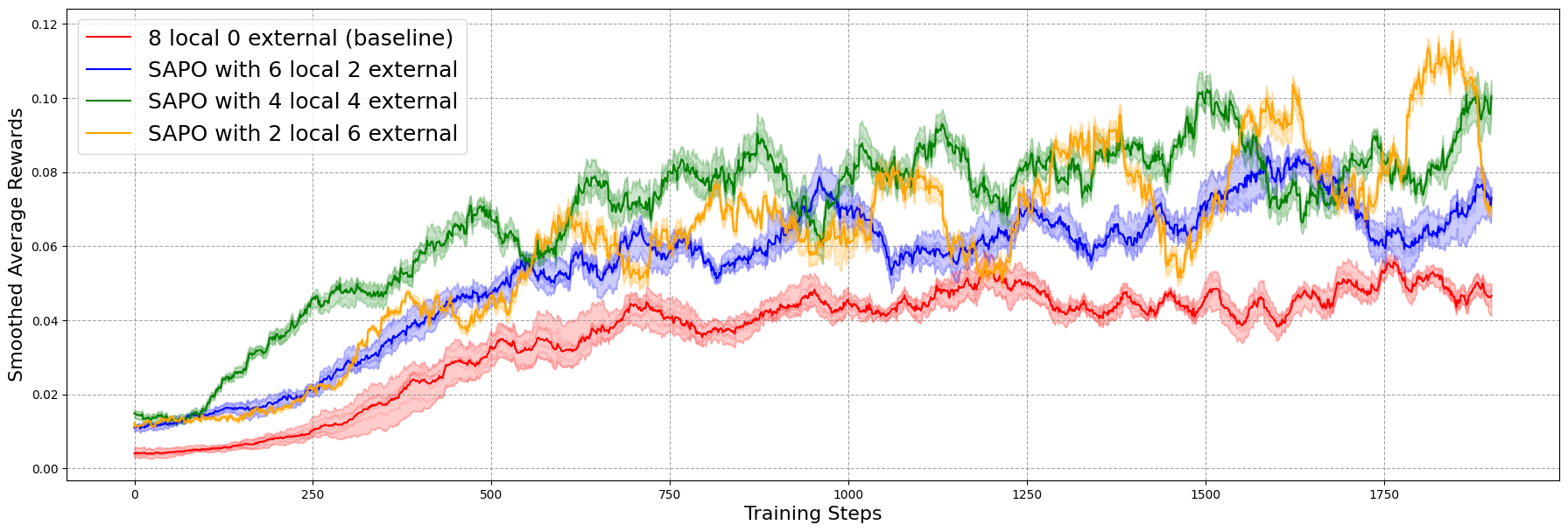
Figure 2: Average agent rewards for each configuration across training, smoothed with a moving average (window size 100). The 4 local / 4 external configuration consistently outperforms the baseline and, in nearly all rounds, also exceeds the 6 local / 2 external configuration in expected average reward. The 4 local / 4 external configuration also surpasses the 2 local / 6 external setup for most rounds, though the difference is smaller compared to the other cases.
Key findings:
- Balanced experience sharing (4 local/4 external) yields the highest cumulative reward ($1093.31$), a 94% improvement over the baseline ($561.79$).
- Excessive reliance on external rollouts (2 local/6 external) leads to oscillatory learning and forgetting, attributed to network effects and diminished pool quality.
- The moving average of agent rewards confirms that balanced sharing accelerates learning and generalization, while too much external sampling destabilizes training.
Large-Scale Swarm Training: Open-Source Demo Insights
A large-scale open-source demo involved thousands of nodes contributed by the Gensyn community, running diverse models and hardware. Each node participated in judge-based evaluation rounds using ReasoningGYM tasks. Analysis of peer-identified results revealed:
- For Qwen2.5 (0.5B), swarm-trained models significantly outperformed isolated counterparts after ~175 normalized rounds, as confirmed by statistical testing.
- For higher-capacity models (Qwen3, 0.6B), the performance gap between swarm and isolated training was negligible, suggesting SAPO's benefits are most pronounced for mid-capacity models.
- Uniform random sampling of external rollouts led to overrepresentation of low-reward samples; more sophisticated filtering could further enhance performance.
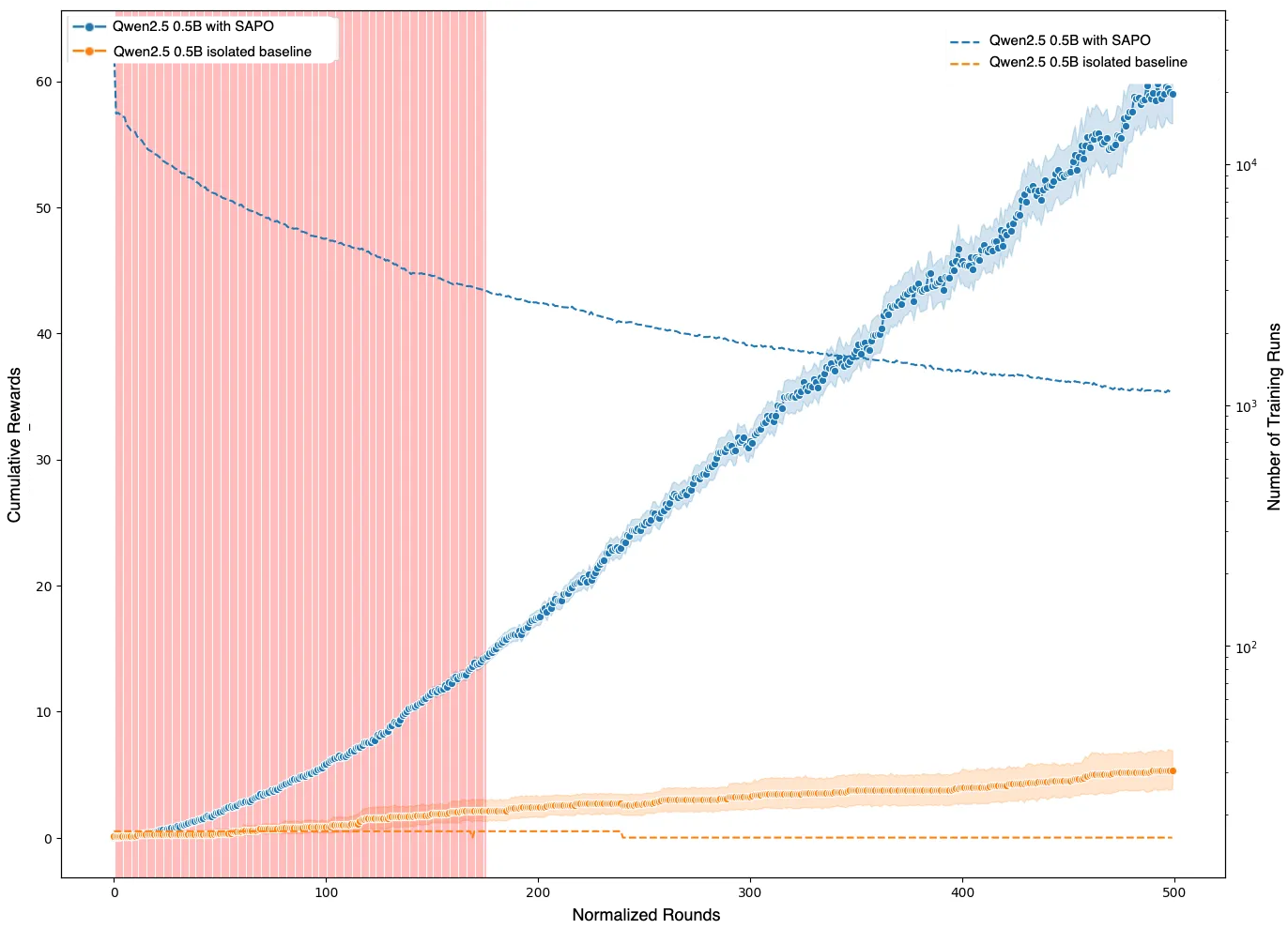
Figure 3: Shown in red are the regions where the adjusted p-value is greater than 0.05. After a certain number of rounds, in this case approximately 175, the performance per round of the models in the swarm significantly exceeds that of the model trained in isolation.
Practical and Theoretical Implications
SAPO demonstrates that decentralized experience sharing can dramatically improve sample efficiency and task performance in RL post-training for LMs, especially in resource-constrained or heterogeneous environments. The approach sidesteps the synchronization, communication, and infrastructure overheads of centralized distributed RL, making it suitable for edge devices and open collaborative networks.
Theoretical implications include:
- SAPO bridges single-agent RL fine-tuning and structured multi-agent frameworks, capturing collaborative benefits without explicit specialization or orchestration.
- Experience sharing enables rapid propagation of "Aha moments," bootstrapping learning across the swarm.
- The trade-off between local and external rollouts is critical; excessive external sampling can induce instability and forgetting.
Practical considerations:
- SAPO is agnostic to data modality and model architecture, supporting multi-modal and heterogeneous swarms.
- Communication and computational overhead from sharing and re-encoding rollouts is outweighed by collective learning gains.
- Adaptive sampling and filtering strategies are necessary to maintain pool quality and stability in large swarms.
Future Directions
The paper identifies several avenues for further research:
- Systematic evaluation of SAPO under greater heterogeneity (specialized tasks, diverse base models, human-in-the-loop policies).
- Development of meta-strategies for adaptive balancing and filtering of local vs. shared rollouts.
- Integration with reward-guided sharing, RLHF, or generative verifiers to enhance stability and robustness.
- Exploration of multi-modal swarms and self-organizing feedback loops in collaborative learning.
Conclusion
SAPO offers a scalable, decentralized framework for RL post-training of LMs, leveraging collective experience sharing to accelerate learning and improve generalization. Controlled and large-scale experiments validate its efficacy, with balanced sharing nearly doubling performance over standard RL fine-tuning. The approach is particularly well-suited for heterogeneous, open networks and resource-constrained environments. Future work should focus on adaptive strategies, heterogeneity, and multi-modal extensions to further realize the potential of collaborative RL in LLM post-training.

