- The paper presents PSPO, a novel method that softens policy updates by interpolating the current and behavior policies, replacing hard clipping with a soft trust region.
- The approach preserves non-vanishing gradients by contracting the importance ratio, leading to enhanced stability and improved performance on both in-domain and out-of-domain tasks.
- PSPO is implemented with simple linear interpolation, incurs no additional computational cost, and demonstrates robust empirical improvements over standard clipping techniques.
Probability Smoothing Policy Optimisation: A Soft Trust-Region Alternative to Clipping in LLM RL
Introduction
This paper introduces Probability Smoothing Policy Optimisation (PSPO), a novel approach to stabilizing policy updates in reinforcement learning (RL) for LLMs. The method is motivated by the limitations of ratio clipping, a standard technique in Proximal Policy Optimization (PPO) and its LLM-adapted variant, Group Relative Policy Optimization (GRPO). While ratio clipping prevents instability by truncating the importance sampling ratio, it introduces vanishing gradients and discards informative updates, especially outside the clipping range. PSPO replaces hard clipping with a soft trust region, achieved by smoothing the current policy toward the behavior (old) policy before computing the importance ratio. This approach is analogous to label smoothing in supervised learning and yields a surrogate objective with non-vanishing gradients everywhere, thus preserving learning signal and improving sample efficiency.
Methodology: Probability Smoothing Policy Optimisation
PSPO modifies the standard policy gradient update by linearly interpolating the current policy πθ with the behavior policy πold:
π~θ(at∣st)=(1−α)πθ(at∣st)+απold(at∣st)
where α∈[0,1] controls the smoothing strength. The importance ratio is then computed as:
r~t(θ)=πold(at∣st)π~θ(at∣st)=(1−α)rt+α
where rt=πold(at∣st)πθ(at∣st) is the standard importance ratio.
This smoothing contracts the ratio toward 1, effectively creating a soft trust region. Theoretical analysis shows that this contraction shrinks both the total variation and KL divergence between the current and behavior policies by a factor of (1−α), directly controlling the update magnitude. Importantly, the surrogate objective under PSPO maintains a non-zero gradient everywhere, avoiding the flat plateaus induced by clipping.
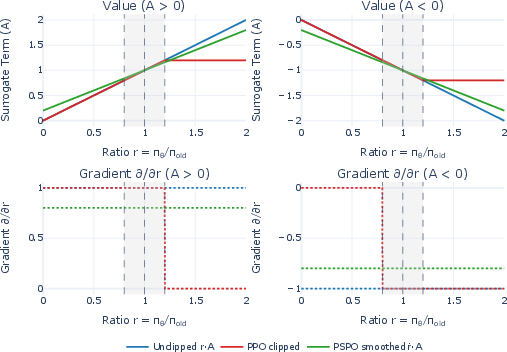
Figure 1: PSPO preserves non-zero gradients across the entire ratio range, in contrast to clipping which introduces flat regions with zero gradient outside the trust region.
The PSPO surrogate objective for GRPO (denoted as GR) becomes:
JGR(θ)=Et[G1i=1∑Gr~t,i(θ)A^t,i−βDKL[πθ∥πref]]
where A^t,i is the group-relative advantage, and β is typically set to zero in practice to reduce memory and computation.
Theoretical Properties
The paper provides several formal results:
- Total Variation and KL Contraction: Smoothing contracts the total variation and upper-bounds the KL divergence by (1−α) times their original values, directly setting a soft trust-region radius.
- Ratio Contraction: The smoothed ratio r~ is linearly contracted toward 1, and the gradient of the surrogate objective is always (1−α)A, where A is the advantage. This ensures non-vanishing gradients and stable updates.
- Overconfidence Regularization: The smoothed policy is always less overconfident than the original, reducing the risk of degenerate solutions.
- Surrogate as Scaled Policy Gradient: The PSPO objective is equivalent to an on-policy policy gradient scaled by (1−α), with the policy itself mixed with the behavior policy, providing implicit stability without explicit KL regularization.
Experimental Setup
The authors instantiate PSPO within GRPO (yielding GR) and evaluate on mathematical reasoning tasks using Qwen2.5-0.5B and 1.5B models. Training is performed on GSM8K, with evaluation on GSM8K (in-domain) and ASDiv, SVAMP, and MATH-500 (out-of-domain). The reward function is correctness-based, with a shaping bonus for format adherence. All methods are trained under identical hardware and decoding settings, and hyperparameters are tuned via grid search.
The main baselines are:
- Clipped GRPO: Standard GRPO with ratio clipping.
- Unclipped GRPO: Single-iteration GRPO (no data reuse, ratio always 1).
- SFT: Supervised fine-tuning.
- Base model: No RL fine-tuning.
Results
On GSM8K, GR achieves a >20 percentage point improvement over clipped GRPO for both 0.5B and 1.5B models (e.g., 39.7% vs. 17.6% for 0.5B; 59.4% vs. 37.8% for 1.5B, Top-1 accuracy at T=0). GR matches the performance of unclipped GRPO, but with improved response quality and stability. Out-of-domain generalization to ASDiv and SVAMP also shows substantial gains, while improvements on MATH-500 are more modest.
Qualitative Response Quality
LLM-as-Judge evaluations (using llama-3.3-70b-versatile) show that GR consistently produces responses with higher overall quality, better constraint adherence, logical coherence, mathematical soundness, and clarity compared to both clipped and unclipped GRPO. Notably, GR reduces instruction leakage and verbosity, yielding more concise and extractable outputs.
Implementation and Practical Considerations
PSPO is a drop-in replacement for ratio clipping in any clipped-ratio objective. The only required change is substituting r~t=(1−α)rt+α for rt in the loss calculation. This incurs no additional computational or memory overhead, making it suitable for large-scale or resource-constrained settings. The method is especially advantageous when multi-epoch updates or mini-batches are used, where unclipped GRPO would be unstable.
Discussion
PSPO addresses the core limitations of ratio clipping by providing a gradient-preserving, behavior-anchored soft trust region. Theoretical analysis guarantees contraction in both TV and KL divergence, and empirical results confirm improved stability and sample efficiency. The method is robust to hyperparameter choices and does not require explicit KL regularization, simplifying implementation and reducing resource requirements.
A key empirical finding is that while unclipped GRPO can match GR's quantitative performance in single-pass settings, it is less stable and produces lower-quality outputs, especially when data reuse or mini-batching is necessary. PSPO's soft trust region ensures stable learning in these more realistic training regimes.
Limitations and Future Directions
The evaluation is limited to mathematical reasoning tasks with objective, binary rewards. The effectiveness of PSPO in domains with subjective or continuous rewards remains to be established. Experiments are restricted to models under 2B parameters; scaling to larger models and more diverse architectures is an important direction for future work. Additionally, while GR matches unclipped GRPO in accuracy, the main advantage is in stability and response quality, which may be more pronounced in larger or sparser models.
Conclusion
PSPO provides a theoretically principled and practically efficient alternative to ratio clipping in RL for LLMs. By smoothing the current policy toward the behavior policy, it creates a soft trust region that contracts the update magnitude, preserves informative gradients, and improves both quantitative and qualitative performance. The method is simple to implement, incurs no additional computational cost, and is robust across model sizes and datasets. These properties make PSPO a compelling choice for stable and efficient RL fine-tuning of LLMs, particularly in settings requiring data reuse or large batch updates. Future work should explore its applicability to larger models, more diverse tasks, and alternative reward structures.

