Self-Contradiction as Self-Improvement: Mitigating the Generation-Understanding Gap in MLLMs
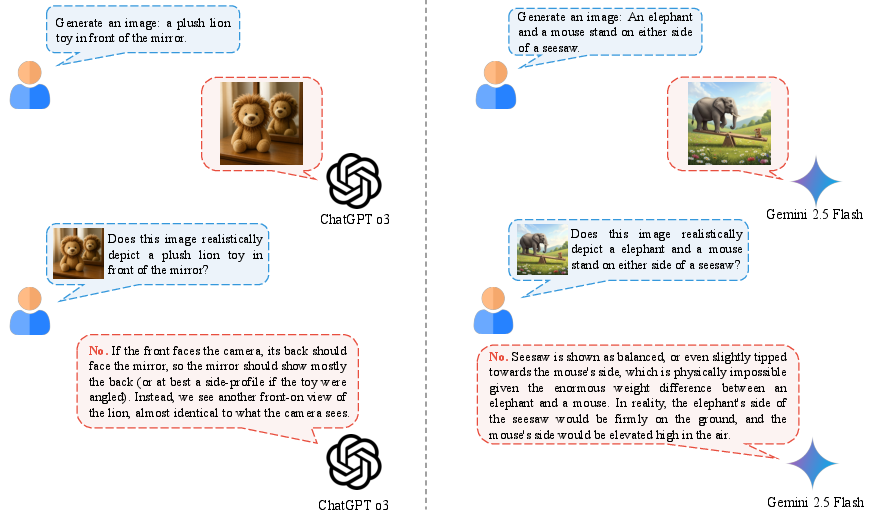
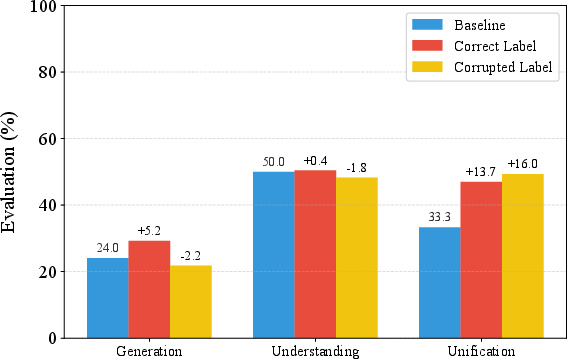
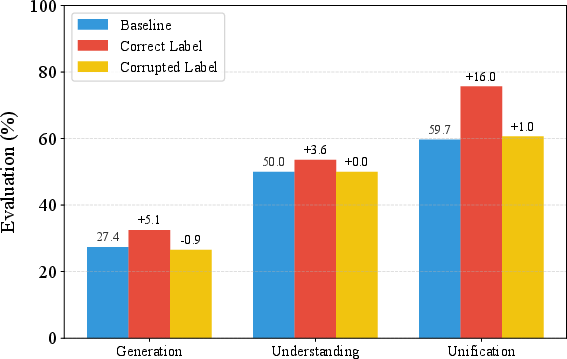
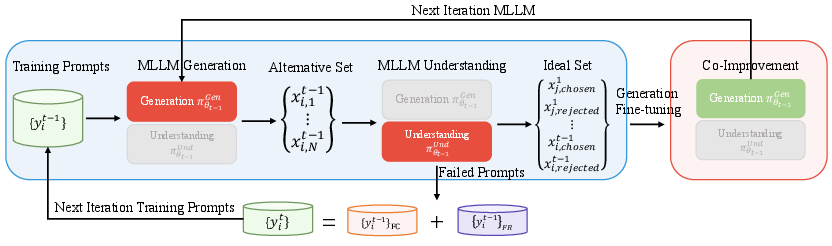
Abstract: Despite efforts to unify multimodal generation and understanding tasks in a single model, we show these MLLMs exhibit self-contradiction where generation produces images deemed misaligned with input prompts based on the model's own understanding. We define a Nonunified score that quantifies such self-contradiction. Our empirical results reveal that the self-contradiction mainly arises from weak generation that fails to align with prompts, rather than misunderstanding. This capability asymmetry indicates the potential of leveraging self-contradiction for self-improvement, where the stronger model understanding guides the weaker generation to mitigate the generation-understanding gap. Applying standard post-training methods (e.g., SFT, DPO) with such internal supervision successfully improves both generation and unification. We discover a co-improvement effect on both generation and understanding when only fine-tuning the generation branch, a phenomenon known in pre-training but underexplored in post-training. Our analysis shows improvements stem from better detection of false positives that are previously incorrectly identified as prompt-aligned. Theoretically, we show the aligned training dynamics between generation and understanding allow reduced prompt-misaligned generations to also improve mismatch detection in the understanding branch. Additionally, the framework reveals a potential risk of co-degradation under poor supervision-an overlooked phenomenon that is empirically validated in our experiments. Notably, we find intrinsic metrics like Nonunified score cannot distinguish co-degradation from co-improvement, which highlights the necessity of data quality check. Finally, we propose a curriculum-based strategy based on our findings that gradually introduces harder samples as the model improves, leading to better unification and improved MLLM generation and understanding.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.