LiveResearchBench: A Live Benchmark for User-Centric Deep Research in the Wild
Abstract: Deep research -- producing comprehensive, citation-grounded reports by searching and synthesizing information from hundreds of live web sources -- marks an important frontier for agentic systems. To rigorously evaluate this ability, four principles are essential: tasks should be (1) user-centric, reflecting realistic information needs, (2) dynamic, requiring up-to-date information beyond parametric knowledge, (3) unambiguous, ensuring consistent interpretation across users, and (4) multi-faceted and search-intensive, requiring search over numerous web sources and in-depth analysis. Existing benchmarks fall short of these principles, often focusing on narrow domains or posing ambiguous questions that hinder fair comparison. Guided by these principles, we introduce LiveResearchBench, a benchmark of 100 expert-curated tasks spanning daily life, enterprise, and academia, each requiring extensive, dynamic, real-time web search and synthesis. Built with over 1,500 hours of human labor, LiveResearchBench provides a rigorous basis for systematic evaluation. To evaluate citation-grounded long-form reports, we introduce DeepEval, a comprehensive suite covering both content- and report-level quality, including coverage, presentation, citation accuracy and association, consistency and depth of analysis. DeepEval integrates four complementary evaluation protocols, each designed to ensure stable assessment and high agreement with human judgments. Using LiveResearchBench and DeepEval, we conduct a comprehensive evaluation of 17 frontier deep research systems, including single-agent web search, single-agent deep research, and multi-agent systems. Our analysis reveals current strengths, recurring failure modes, and key system components needed to advance reliable, insightful deep research.









Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about building fair, real-world tests for AI “research assistants.” These AIs search the web, read many sources, and write long reports with citations—like a student doing a big school project but at internet scale. The authors create two things:
- LiveResearchBench: a set of 100 realistic research tasks that require up‑to‑date web searching and careful writing.
- DeepEval: a way to grade the AI’s reports so the grading is fair, detailed, and consistent.
Together, these help researchers see what today’s AI systems do well, where they struggle, and how to improve them.
What questions did the researchers ask?
They wanted to know:
- How can we test AI research assistants on tasks that feel like real life, not just toy problems?
- How can we grade long, open‑ended reports fairly—checking if they cover the topic, make sense, use proper evidence, and cite sources correctly?
- Which kinds of AI systems work best: one big AI doing everything alone (single‑agent), or a team of AIs with different roles (multi‑agent)?
- What are the common mistakes these systems make, and how can we fix them?
How did they study it? (Methods explained simply)
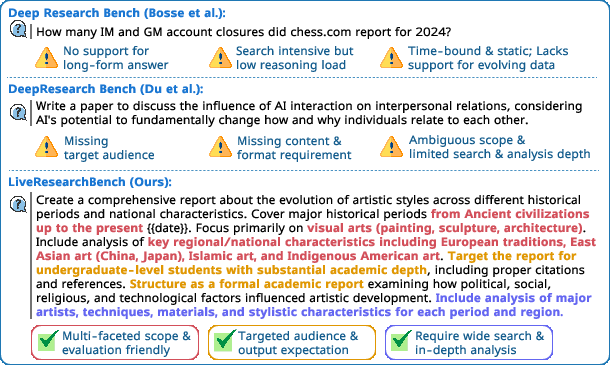
Think of LiveResearchBench like a set of challenging, well-written “assignments” a teacher gives to test research skills. The team designed these tasks using four simple rules:
- User‑centric: Tasks match real needs (e.g., a business report vs. a student overview).
- Unambiguous: Tasks clearly state the scope, audience, and format, so there’s no confusion.
- Time‑varying: Tasks need up‑to‑date info (e.g., “up to today’s date”), so the AI must actually search the live web.
- Multi‑faceted: Tasks require many steps, many sources, and real analysis—not just quick facts.
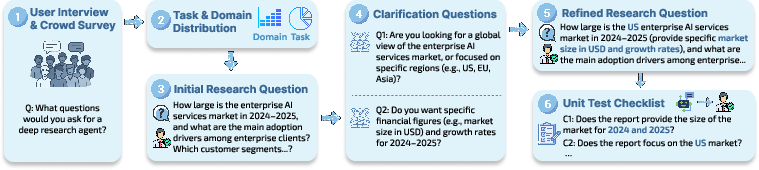
They built these tasks through interviews, expert drafting, and multiple rounds of checking. Each task comes with a “checklist” of must‑cover points, like the rubric a teacher uses to grade an essay.
DeepEval is the “grading system.” It checks six parts of each report, using simple ideas and analogies:
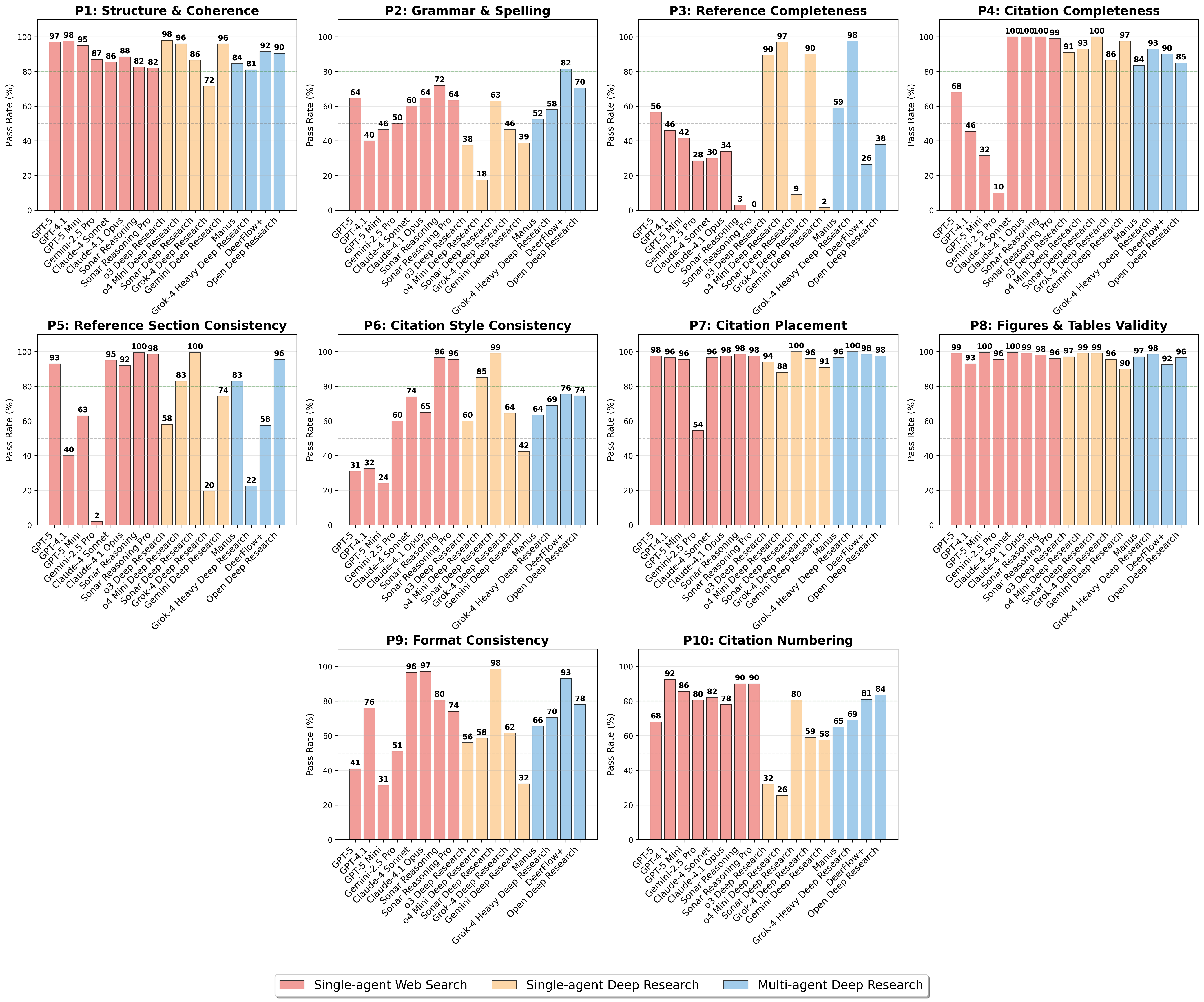
- Presentation: Is the report well organized and readable? (Like checking format, grammar, and structure.)
- Factual and logical consistency: Do the facts and claims stay consistent throughout? (No contradictions.)
- Coverage: Does it actually answer all parts of the question? (This uses the task’s checklist.)
- Analysis depth: Does it just list facts, or does it explain causes, trade‑offs, and insights?
- Citation association: Are important claims linked to sources?
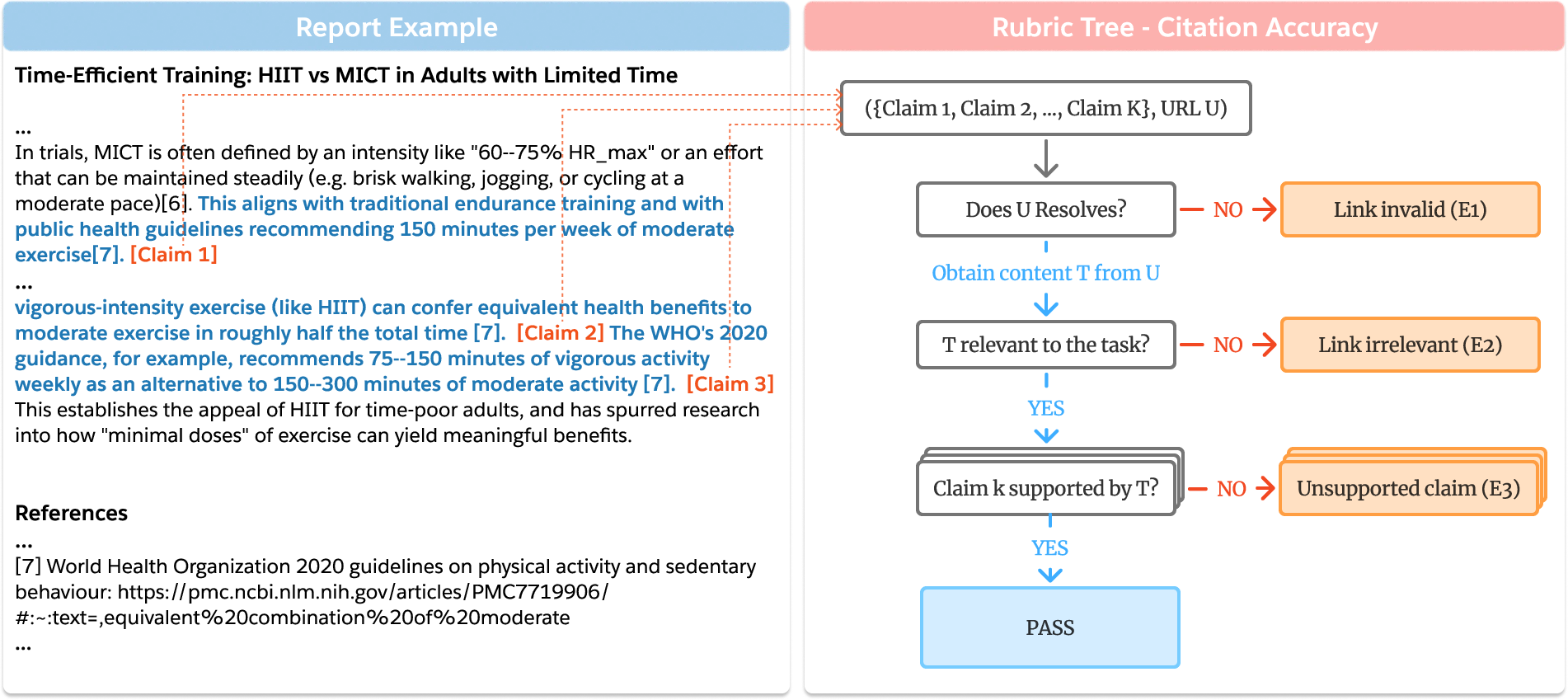
- Citation accuracy: Do those sources really support the claims? (They use a step‑by‑step “decision tree” to check links, like a librarian verifying each reference.)
To make grading fair, they used multiple strong AI “judges” and averaged their decisions—like having two teachers grade the same essay. They also used different grading styles depending on the skill:
- Checklists for structure and coverage
- Counting errors for consistency and missing citations
- Head‑to‑head comparisons for analysis depth
- A simple “if‑this-then-that” tree for verifying each source link
Finally, they tested 17 different AI systems, including single‑agent and multi‑agent designs.
What did they find, and why does it matter?
Here are the most important takeaways:
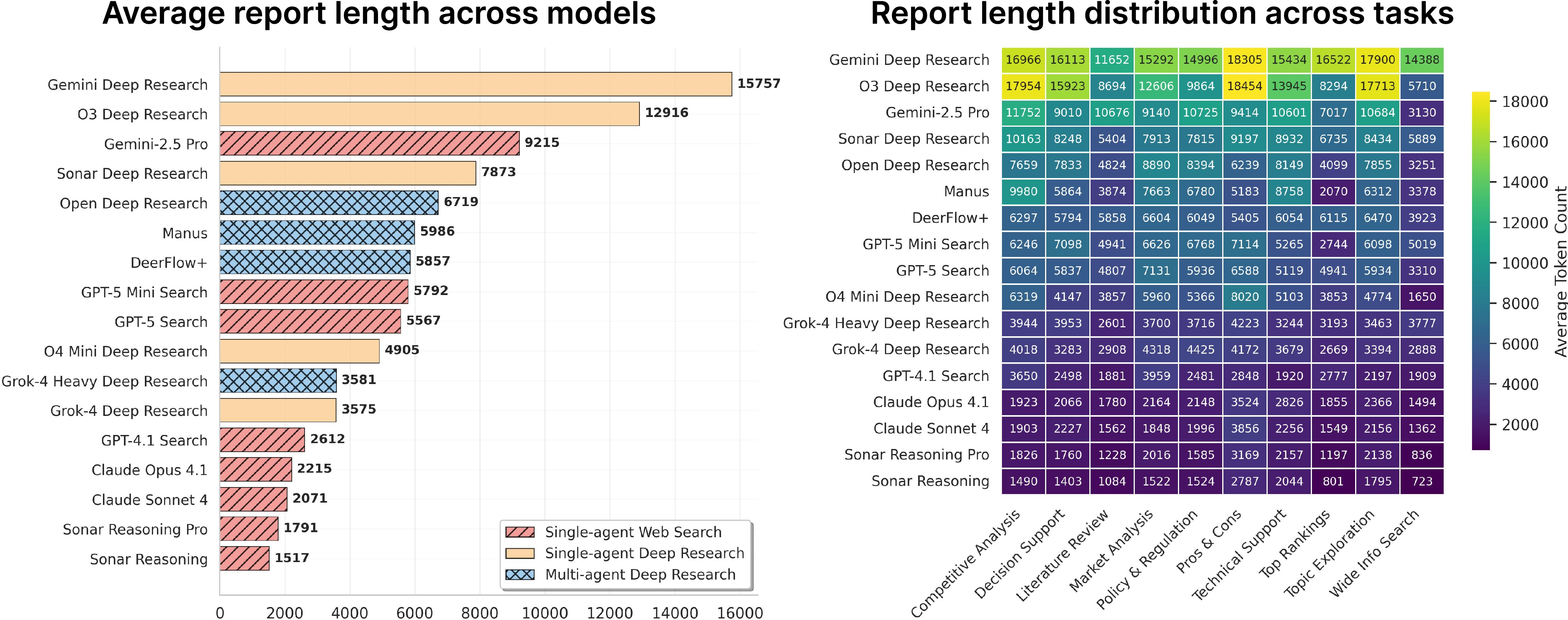
- Longer doesn’t mean better. Some systems write very long reports, but length alone doesn’t guarantee good logic, proper citations, or deep insights.
- Many AIs struggle with citations. Common issues include missing links, wrong links, or links that don’t actually support the claim. Even top systems made many citation mistakes, especially on tough tasks like market analysis.
- Different designs have different strengths:
- Single‑agent web systems (one AI doing it all) tended to be more consistent in facts and logic.
- Multi‑agent systems (a team with roles like planner, researcher, writer) tended to do better at linking claims to sources and producing polished reports.
- But no design was great at everything.
- Most systems are better “deep searchers” than “deep researchers.” They gather and organize lots of information but often don’t go far enough in making thoughtful, evidence‑based insights.
- There are trade‑offs under limits. When the AI reads hundreds of pages, it can’t remember everything. Without smart memory and summarizing, it either loses coverage (misses parts) or loses depth (stays shallow).
What’s the impact? (Why this research matters)
- Better tests lead to better tools. LiveResearchBench and DeepEval give the community a fair, detailed way to compare AI research assistants and see what to improve.
- Clear goals for improvement. To become truly helpful research partners, future AIs need:
- Stronger memory over long projects
- Smarter summarizing that keeps key evidence
- Better source handling (every claim linked and truly supported)
- Deeper synthesis and reasoning, not just collecting facts
- Real‑world benefits. Stronger, more reliable AI research tools could help students, scientists, journalists, and businesses make better decisions based on trustworthy, up‑to‑date information.
In short, this paper sets a high bar for what “deep research” AIs should do, shows where today’s systems fall short, and provides the tools to track real progress.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of gaps and open questions left unresolved by the paper that future researchers can concretely act on:
- Benchmark scale and representativeness: With only 100 tasks, does LiveResearchBench adequately capture the diversity and long-tail complexity of real-world deep research across domains, user personas, and task types? How does performance change as task volume and heterogeneity increase?
- Dataset release and reproducibility: The dataset is “subject to institutional approval.” When and how will tasks, checklists, and evaluation prompts be publicly released to ensure replicability, independent auditing, and community benchmarking?
- Dynamic web variance and comparability: Tasks depend on real-time web content. How can evaluations be made comparable across time, runs, and institutions (e.g., by snapshotting pages, logging retrieval artifacts, or versioning tasks by evaluation date)?
- Run-to-run stability: The paper does not evaluate stochastic variability (e.g., multiple seeds/temperatures). How stable are system scores across repeated runs per task, and how should instability be reported?
- Judge reproducibility and dependence on closed models: DeepEval relies on proprietary LLM judges (Gemini 2.5 Pro and GPT-5). Can similar agreement and reliability be achieved with open-source judges, and what is the impact of judge model upgrades on longitudinal comparability?
- Human alignment details: Agreement rates are reported, but inter-annotator agreement statistics, sample sizes, task distributions, and confidence intervals for human–LLM alignment are not fully detailed. How robust are these findings across domains and difficulty tiers?
- Checklist provenance and bias: Checklists are initially generated by GPT-5 and then human-validated. Do LLM-generated checklists introduce systematic biases (e.g., phrasing, granularity, scope) that shape model performance? Can purely human-constructed or independently developed checklists improve fairness?
- Coverage scoring granularity: Binary unit-test scoring for coverage may over-penalize partial fulfillment or underweight critical items. Can graded or importance-weighted coverage metrics better reflect user priorities and task-critical requirements?
- Composite score design: The paper averages heterogeneous metrics without explicit weighting or sensitivity analysis. How should composite scores be constructed (weights, normalization, trade-off curves) to reflect realistic user value functions?
- Depth metric baseline dependence: Analysis depth is assessed via pairwise comparisons against a single baseline (Open Deep Research). How sensitive are rankings to the choice of baseline, and can an absolute scale or multi-baseline ensemble remove baseline-induced bias?
- Citation association vs. multi-source attribution: The association metric penalizes missing or misplaced citations, but does not assess multi-source aggregation quality. How can evaluation reward correct multi-source synthesis and evidence attribution across multiple URLs per claim?
- Citation accuracy rubric-tree efficiency trade-offs: Grouping claims by URL and early termination via shallow relevance checks improves efficiency but may undercount nuanced support (e.g., evidence deeper in pages, PDF sections). What is the recall–cost trade-off, and can more robust retrieval/parsing (e.g., full-text indexing, PDF section extraction) raise accuracy?
- High E3 (unsupported claims) rates in market analysis: The paper shows large unsupported claim counts in market analysis. Can integrating structured financial datasets, paywalled sources, or data licenses (e.g., Statista, S&P Global) reduce hallucinations while preserving openness and reproducibility?
- Fairness across system resources: Systems differ in context windows, toolchains, and retry policies. How should evaluations normalize resource budgets (context size, tool access, thinking time, cost/latency caps) to enable fair comparisons?
- Cost and latency reporting: Practical viability requires reporting inference time, total tool calls, and dollar costs per task. How do systems trade off quality vs. speed/cost, and which configurations optimize utility for real users?
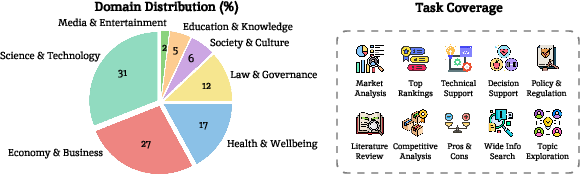
- Domain and multilingual coverage: Tasks span seven domains but are likely English-centric. How do systems perform in multilingual, cross-cultural contexts, and on domain-specific compliance-heavy tasks (e.g., legal, clinical) with jurisdictional nuances?
- Safety and risk evaluation: The benchmark does not assess harmful or unsafe outputs, especially in health, policy, or finance. How should safety (misinformation, regulatory compliance, ethical sourcing) be measured and incorporated into scoring?
- Robustness to web threats: Agents operate “in the wild,” yet robustness to prompt injection, SEO spam, link rot, paywalls, CAPTCHAs, and site-specific anti-scraping is not evaluated. Which defense mechanisms measurably reduce exploitation or degradation?
- Memory and compression ablations: The paper identifies memory/compression as bottlenecks but does not ablate architectures (e.g., hierarchical memory, deduplication, salience-aware compression). Which designs preserve coverage while enabling deeper synthesis under strict context limits?
- Planning and workflow analysis: Multi-agent pipelines differ in planner quality, role specialization, and handoff protocols. Which workflow components (planner, researcher, synthesizer, verifier) drive gains, and how do failures propagate across stages?
- Tool-use breadth: Many tasks may benefit from code execution, data analysis, spreadsheets, or knowledge base querying beyond web browsing. Does expanding tool-use materially improve factuality, citation reliability, and depth?
- Personalization and audience alignment: Tasks encode audience and format requirements, but the evaluation does not explicitly measure alignment to audience expertise or preferences. How can personalization metrics capture clarity, relevance, and pedagogical appropriateness?
- Temporal reasoning and “as of date” handling: Tasks require up-to-date information, but systems’ handling of temporal qualifiers (as-of dates, trend windows, revisions) is not evaluated. Can temporal consistency checks reduce outdated or mismatched claims?
- Adversarial and counterfactual stress tests: The benchmark does not test systems against conflicting sources, contradictory studies, or intentionally misleading pages. How resilient are agents at resolving conflicts and presenting uncertainty transparently?
- Provenance and audit trails: The paper does not require structured provenance logs (retrieval traces, decision rationales). Can standardized audit artifacts improve reproducibility, debugging, and accountability?
- Generalization beyond the benchmark: It remains unclear whether performance transfers to unseen, more complex or niche tasks. What is the out-of-distribution generalization profile, and can task difficulty be calibrated (e.g., via taxonomy or automatic difficulty scores)?
- Ethical and licensing constraints: Handling paywalled content, copyrighted materials, and source licensing is unaddressed. What policies and tooling enable ethically compliant deep research while maintaining evaluation rigor?
- Community governance and evolution: As a “live” benchmark, governance (task updates, deprecations, judge rotations) is not defined. How should the benchmark evolve while maintaining longitudinal comparability and preventing gaming?
- Statistical significance and uncertainty: The paper reports aggregate scores but not confidence intervals or significance testing across models/dimensions. Can uncertainty quantification (bootstrapping, hierarchical models) clarify whether observed differences are reliable?
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging LiveResearchBench tasks and the DeepEval evaluation suite, along with the paper’s task design principles and rubric-tree citation framework.
- Enterprise vendor benchmarking and model selection (software, consulting, finance, healthcare, legal)
- What: Use LiveResearchBench + DeepEval to run apples-to-apples evaluations across research agents and LLM providers; score models on coverage, analysis depth, factual consistency, and citation quality before procurement.
- Tools/workflows: Benchmark harness; score dashboards; checklists-based grading; LLM-ensemble-as-judge; SLA-ready metric reports.
- Assumptions/dependencies: Access to judge models (e.g., GPT-5, Gemini 2.5 Pro), evaluation budget, stable web access, dataset licensing and institutional approval.
- Continuous QA gates for AI-generated reports (newsrooms, market research agencies, enterprise KM; software)
- What: Integrate DeepEval in CI/CD to automatically block or flag reports with citation errors, logical inconsistencies, or incomplete coverage before delivery to clients.
- Tools/workflows: Report linting; rubric-tree citation validator; checklist pass/fail gates; error triage; retry workflows.
- Assumptions/dependencies: Judge model reliability/alignment, URL accessibility (paywalls, rate limits), reproducible runs for time-varying queries.
- Editorial fact-checking and citation validation (media, marketing, PR; education)
- What: Apply rubric-tree evaluation to verify claim–URL pairs at scale for long-form content (articles, whitepapers, briefs) and auto-flag invalid/irrelevant/unsupported citations.
- Tools/workflows: CMS plugin or browser extension; grouped URL retrieval; early relevance checks; citation association scoring.
- Assumptions/dependencies: Live web access; caching and rate-limit handling; handling of dynamic content and link rot.
- Prompt and task specification best practices (daily life, education, public sector)
- What: Adopt the paper’s four principles (user-centric, unambiguous, time-varying, multi-faceted) to craft clearer prompts and assignments that reduce ambiguity and improve output quality.
- Tools/workflows: Prompt templates with audience, scope, format, and coverage checklists; multi-model clarification queries.
- Assumptions/dependencies: Domain expertise to refine scope; user/audience clarity; organization-wide prompt standards.
- Academic instruction and assessment of research skills (education)
- What: Use benchmark tasks and DeepEval checklists to grade student reports on coverage, analysis depth, and citation correctness; teach evidence-grounded synthesis.
- Tools/workflows: LMS integration; auto-grading rubrics; pairwise depth comparisons; checklists for coverage; error-led feedback.
- Assumptions/dependencies: Access to judge models; transparency around LLM-as-judge bias; faculty oversight.
- Compliance and governance for AI-generated documents (policy, legal, regulated industries)
- What: Enforce internal evidence standards by requiring minimum DeepEval scores (e.g., citation accuracy thresholds) for AI-produced memos, proposals, and risk analyses.
- Tools/workflows: Policy-aligned checklists; audit logs of claim–source mappings; compliance dashboards; exception handling.
- Assumptions/dependencies: Governance buy-in; storage of evaluation artifacts; standardized documentation workflows.
- Model freshness and drift monitoring via time-varying tasks (software, enterprise)
- What: Schedule LiveResearchBench runs on “up-to-the-present” tasks to monitor retrieval freshness and factual consistency over time; alert on regressions.
- Tools/workflows: Scheduled evaluations; drift dashboards; regression thresholds; vendor-change impact tracking.
- Assumptions/dependencies: Regular web updates; reproducibility controls; cost management for frequent evaluations.
- Domain-specific benchmark curation using the six-stage pipeline (healthcare, finance, energy, policy)
- What: Reuse the paper’s curation pipeline (user interviews → expert drafting → model clarifications → expert refinement → checklist generation → multi-stage verification) to build sector-focused benchmarks.
- Tools/workflows: Multi-model clarification (to reduce bias); expert verification guidelines; checklist unit tests; QC stages.
- Assumptions/dependencies: Availability of domain experts; annotation budget; institutional review/approval.
- Immediate improvements to multi-agent systems via Deerflow+ practices (software/AI agents)
- What: Adopt inline citations, reference mapping, and long-context management to reduce token-limit failures and improve citation discipline in open-source pipelines.
- Tools/workflows: Evidence structuring; citation deduplication; long-context buffering; shared memory across sub-agents.
- Assumptions/dependencies: Base LLM capabilities; orchestration framework (LangChain, custom); context window constraints.
- Procurement and SLAs that reference DeepEval metrics (enterprise, finance, consulting)
- What: Embed target thresholds for coverage, consistency, and citation metrics in contracts; use evaluation reports as acceptance tests.
- Tools/workflows: Procurement checklists; acceptance criteria; periodic audits.
- Assumptions/dependencies: Agreement on metric definitions; audit reproducibility.
- Everyday verification aids for AI outputs (daily life)
- What: Lightweight browser extension or assistant that scans AI-generated text and flags unsupported or uncited claims using the association and accuracy checks.
- Tools/workflows: Client-side citation checker; quick relevance heuristics; user-friendly error summaries.
- Assumptions/dependencies: Permissions and web access; handling paywalled sources; minimal latency.
Long-Term Applications
The following applications require further research, scaling, or development—especially advances in memory, compression, and synthesis that the paper highlights as open challenges.
- “Evidence-grounded AI” standards and certification (policy, regulators, industry consortia)
- What: Establish common benchmarks and DeepEval-derived thresholds for certifying AI systems that produce long-form, citation-grounded outputs; public trust marks.
- Tools/products: Certification frameworks; standardized audits; reference benchmarks; LLM-ensemble-as-a-judge services.
- Dependencies: Consensus on metrics, independent auditors, transparency into model behavior, legal/regulatory alignment.
- Living systematic reviews and dynamic evidence synthesis (healthcare, public health)
- What: Sector-specific deep research agents that continuously ingest new studies and update clinical or policy guidance with verifiable citations and analysis depth.
- Tools/products: Domain checklists; medical evidence pipelines; hierarchical memory/compression modules; audit trails.
- Dependencies: Access to medical databases; handling paywalls/embargoes; clinical validation; bias/ethics governance.
- Policy analysis pipelines with verifiable sourcing (law/governance, energy, climate)
- What: Agents that aggregate evolving policy texts, stakeholder positions, and impact studies; provide argumentation with linked evidence and trade-off analyses.
- Tools/products: Rubric-tree citation validators; preference-aware compression; argumentation modules.
- Dependencies: Reliable access to government portals; multilingual coverage; cross-jurisdiction data normalization.
- Enterprise-scale research assistants with hierarchical memory and compression (software/AI agents, consulting)
- What: Systems that retain breadth and depth under context limits via updateable long-horizon memory, redundancy-aware merging, and importance-aware compression.
- Tools/products: Memory graphs; incremental summarizers; evidence deduplication and weighting; synthesis/argumentation units.
- Dependencies: Large-context LLMs or retrieval-augmented memory; robust compression without information loss; user-preference modeling.
- Third-party auditing services for AI-generated content (media, finance, legal)
- What: Independent platforms that run DeepEval-like suites and publish audit reports on citation accuracy, consistency, and analysis depth for vendors and clients.
- Tools/products: Audit APIs; reproducibility toolkits; evidence transparency reports; error taxonomies (E1/E2/E3).
- Dependencies: Secure data handling; impartiality; reproducibility across time-varying tasks; affordable evaluation at scale.
- Automated checklist generation and dynamic rubric trees (education, enterprise QA)
- What: Systems that convert task briefs into validated checklists and hierarchical evaluation rubrics per domain and audience.
- Tools/products: Checklist-generation services; rubric-tree compilers; domain calibration loops with expert-in-the-loop.
- Dependencies: Reliable LLMs for checklist drafting; human verification; domain coverage; adaptability to user goals.
- Peer-review assistance for academic publishing (academia)
- What: Tools that assess citation association/accuracy, logical consistency, and coverage for manuscripts; provide reviewer aids and integrity checks.
- Tools/products: Editorial integration; citation validation pipelines; analysis-depth comparators; provenance mapping.
- Dependencies: Access to cited sources; publisher policies; handling paywalled content; minimizing false positives/negatives.
- Legal and compliance due diligence with traceable evidence (legal, finance)
- What: Agents that compile deal memos or compliance reports with verifiable citations; auto-flag unsupported claims; maintain audit trails for regulators.
- Tools/products: Evidence registries; claim–source maps; compliance-grade evaluators; governance dashboards.
- Dependencies: Regulatory acceptance; secure data storage; confidentiality controls; handling evolving regulations.
- Personalized, preference-aware compression for different audiences (education, enterprise KM)
- What: Compression strategies that retain critical details aligned to user roles (executive, analyst, student) to balance coverage and depth.
- Tools/products: User-profiled summarizers; importance labeling; insight-density controllers; multi-view synthesis.
- Dependencies: Preference modeling; explainability of compression decisions; avoidance of discarding key evidence.
- Sectoral “living market analysis” with accuracy guarantees (finance, energy)
- What: Continuously updated market reports that meet citation accuracy thresholds and analysis-depth targets; tie to decisions (pricing, investment, capacity planning).
- Tools/products: Market data ingestion; DeepEval scoring gates; intervention workflows; traceable assumptions.
- Dependencies: Licensed data feeds; disclosure management; latency and cost control; domain-specific calibration.
- Standardized SLAs and risk frameworks for agentic systems (enterprise)
- What: Contractual metrics tied to DeepEval dimensions (coverage, consistency, association/accuracy, depth) with remediation clauses and monitoring.
- Tools/products: SLA templates; continuous benchmarking services; drift alerts; incident playbooks.
- Dependencies: Cross-vendor comparability; legal acceptance of evaluation protocols; cost and cadence of audits.
- Public-facing trust dashboards for AI research agents (policy, civil society)
- What: Transparency portals showing recent DeepEval scores on time-varying tasks; highlight failure modes and corrective actions.
- Tools/products: Trust dashboards; historical scorecards; error heatmaps; model update notes.
- Dependencies: Willingness of vendors to disclose; standardized reporting; user education on metrics.
Notes on assumptions and dependencies across applications
- Access to high-quality judge models and web browsing is critical; judge bias and alignment must be monitored.
- Costs can be non-trivial (LLM inference, web retrieval); caching, batching, and grouped URL evaluation help.
- Time-varying tasks challenge reproducibility; use versioning, snapshotting, and transparent run metadata.
- Domain adaptation and expert verification improve reliability; governance and privacy policies must be in place.
- Context-window limits and retrieval quality constrain performance; memory, compression, and synthesis modules are active research areas.
- Licensing, paywalls, and rate limits affect citation accuracy workflows; fallback strategies and access agreements may be needed.
Glossary
- Agentic judge: An autonomous evaluator (often an LLM with tools) used to verify claims and citations. "we employ an agentic judge with web access that performs a structured validation process"
- Agentic systems: AI systems that act as decision-making agents with tools to plan, search, and synthesize information. "marks an important frontier for agentic systems."
- Analysis Depth: An evaluation dimension that measures the depth and quality of reasoning and insight in reports. "\ding{185} Analysis Depth,"
- Checklist-based evaluation: An assessment protocol that scores outputs against a list of discrete yes/no criteria. "checklist-based, pointwise, pairwise, or rubric-tree"
- Citation Accuracy: Whether a citation genuinely supports the associated claim in the text. "\ding{187} Citation Accuracy."
- Citation Association: Whether every factual claim is properly linked to a source. "\ding{186} Citation Association,"
- Citation-grounded: Describes outputs whose claims are supported by explicit citations to sources. "To evaluate citation-grounded long-form reports, we introduce DeepEval"
- Context window: The maximal token capacity a model can attend to at once. "exceed the available context window."
- Data contamination: Leakage of evaluation content into training data, compromising fairness. "safeguarding against data contamination"
- Function-calling LLMs: LLMs that invoke external tools or functions via structured APIs. "Examples include function-calling LLMs"
- Ground truths: Canonical correct answers used for evaluation; in dynamic tasks these may not be fixed. "without a fixed ground truths."
- Grounded answers: Responses that are justified by external evidence or sources. "for grounded answers to complex queries"
- Hallucinations: Fabricated or unsupported content generated by a model. "highlighting that hallucinations persist even with web access."
- Human alignment study: An analysis comparing automated judgments to human evaluations to assess agreement. "conducted a human alignment study on the selected protocols."
- Inductive bias: Built-in assumptions or tendencies of a model that can skew evaluations. "To mitigate inductive bias from relying on a single model"
- LLM-as-a-judge: Using a LLM to evaluate outputs instead of (or alongside) humans. "naive LLM-as-a-judge setups produce inconsistent results."
- LLM-Ensemble-as-Judge: Using multiple LLM judges and aggregating their decisions to reduce bias and variance. "LLM-Ensemble-as-Judge."
- Long-horizon: Tasks requiring extended, multi-step reasoning and planning. "long-horizon, multi-step reasoning and planning."
- Multi-agent systems (MAS): Architectures where specialized agents collaborate in roles like planning, research, and writing. "Multi-agent systems (MAS) instead coordinate specialized roles"
- Multi-hop search: Search that requires chaining multiple retrieval steps across diverse sources. "requiring multi-hop search across diverse web sources and in-depth analysis."
- Pairwise comparison: An evaluation protocol that compares two outputs side-by-side to pick a winner (or tie). "Pairwise comparison, where the judge compares two reports side by side and selects the preferred one (or declares a tie)."
- Parametric knowledge: Information stored in a model’s parameters (as opposed to fetched from external sources). "beyond parametric knowledge"
- Pointwise (additive): An evaluation that identifies and counts individual errors, aggregating them into a score. "(2) Pointwise (additive), where the judge aims to find concrete errors in the report according to the criteria."
- Position-swap averaging: A technique to reduce positional bias by swapping the order of compared items and averaging results. "we adopt the position-swap averaging method"
- Pretraining corpora: The large text datasets used to train LLMs before fine-tuning. "from pretraining corpora"
- ReAct-style agents: Agents that interleave reasoning and acting (e.g., tool use) in a single loop. "ReAct-style agents"
- Reference-based metrics: Metrics that assess outputs by comparing them to reference answers or texts. "moved beyond simple reference-based metrics."
- Rubric tree: A hierarchical, stepwise evaluation procedure that categorizes and verifies claims/citations. "This procedure is organized as a rubric tree"
- Single-agent systems: Architectures where one model makes all tool-use and control decisions. "Single-agent systems place all tool-use decisions in one model."
- Sub-agents: Specialized agents within a multi-agent workflow tasked with subtasks like browsing or verification. "dispatch sub-agents for browsing, searching, synthesis, and verification"
- Time-varying tasks: Tasks whose correct answers change over time, necessitating up-to-date retrieval. "time-varying, featuring multi-faceted, search-intensive tasks across diverse domains."
- Token-limit failures: Errors or truncations caused by exceeding a model’s maximum context length. "eliminates token-limit failures"
- Unsupported claims: Statements that are not actually substantiated by their cited sources. "unsupported claims (claims not verifiable from the cited link) rather than invalid or irrelevant URLs"
Collections
Sign up for free to add this paper to one or more collections.

