WebSailor-V2: Bridging the Chasm to Proprietary Agents via Synthetic Data and Scalable Reinforcement Learning
Abstract: Transcending human cognitive limitations represents a critical frontier in LLM training. Proprietary agentic systems like DeepResearch have demonstrated superhuman capabilities on extremely complex information-seeking benchmarks such as BrowseComp, a feat previously unattainable. We posit that their success hinges on a sophisticated reasoning pattern absent in open-source models: the ability to systematically reduce extreme uncertainty when navigating vast information landscapes. Based on this insight, we introduce WebSailor, a complete post-training methodology designed to instill this crucial capability. Our approach involves generating novel, high-uncertainty tasks through structured sampling and information obfuscation, RFT cold start, and an efficient agentic RL training algorithm, Duplicating Sampling Policy Optimization (DUPO). With this integrated pipeline, WebSailor significantly outperforms all open-source agents in complex information-seeking tasks, matching proprietary agents' performance and closing the capability gap.
First 10 authors:




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces WebSailor‑V2, an AI “web agent” designed to do deep research on the internet. Think of it as a smart assistant that can search, read webpages, check academic papers, run code, and use reasoning to answer hard, multi‑step questions. The authors present a full recipe for building such an agent: how to make the right training data, how to teach it with supervised learning, and how to improve it further using reinforcement learning. Their goal is to help open‑source systems catch up to powerful, closed‑source research tools from big companies.
Key Questions the Paper Tries to Answer
- How can we create training data that teaches an AI to handle messy, real‑world web research, not just simple fact lookups?
- How can we train an AI agent at scale, safely and cheaply, when real web tools are slow, unpredictable, or expensive?
- Can a well‑trained, mid‑sized open‑source model match or beat much larger or proprietary systems at deep research tasks?
Methods and Approach
The Agent’s Brain and Behavior
- The agent uses a framework called ReAct, which follows a simple loop: think → act (use a tool) → observe (see results) → repeat. This avoids complicated plans and lets the model learn general reasoning strategies.
- It’s built on a 30‑billion‑parameter model (Qwen3‑30B‑A3B), a mixture‑of‑experts (MoE) type of model that is efficient but strong.
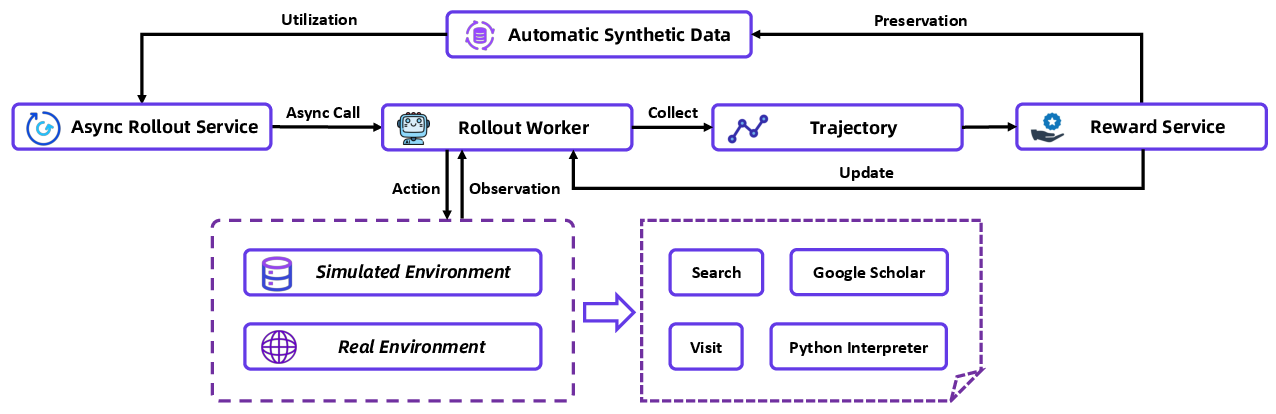
The agent can use four tools:
- Search: ask a search engine and get results.
- Visit: open a webpage and summarize what’s relevant.
- Google Scholar: search for academic papers.
- Python: run code in a safe sandbox to calculate or analyze.
Better Training Data: SailorFog‑QA‑V2
To train smart research skills, the authors made a new dataset based on a dense “knowledge graph.” Imagine a huge web of connected facts about people, companies, events, dates, and more. Instead of growing this graph in a simple, tree‑like way, they deliberately added many cross‑links and loops, like a real web of information.
From this graph, they create question‑answer tasks that force the agent to:
- Deal with uncertainty, not just “hidden names” (obfuscation) — for example, clues might be vague or indirect, making the agent infer and verify.
- Use different reasoning patterns, because questions target different “roles” of nodes in the graph.
- Follow realistic research steps, including tracking which searches and links led to new facts.
They also extract subgraphs using “random walks” (like wandering through connected facts) to sample a wide variety of structures efficiently.
Two‑Stage Training: SFT then RL
- Supervised Fine‑Tuning (SFT) cold start: First, they teach the model with high‑quality, synthetic examples from SailorFog‑QA‑V2. This gives the agent a solid “starter strategy,” so it doesn’t flail during later training.
- Reinforcement Learning (RL): Then they let the agent practice solving tasks and learn from rewards (successes and failures), updating its policy over time.
A key innovation is the dual RL environment:
- Simulated environment: A fast, cheap “practice internet” built from offline Wikipedia. It’s stable, controllable, and perfect for quickly testing ideas.
- Real environment: Carefully managed connections to real web tools. The authors add caching, retries, backups, and rate limits so training isn’t ruined by slow or broken APIs.
Finally, they use a closed feedback loop: as training progresses, the system automatically generates and filters new data to match the agent’s needs, improving quality and stability over time.
A Simple View of the RL Algorithm
The RL method (based on GRPO) rewards the agent for good trajectories and carefully handles bad ones to keep training stable. It:
- Samples fresh attempts using the newest policy (on‑policy).
- Uses token‑level learning signals.
- Reduces noise by comparing each attempt to the group average.
- Excludes some “empty” failures (like answers cut off by length limits) so they don’t destabilize learning.
The authors emphasize that the algorithm matters, but the biggest wins come from great data and a stable training setup.
Main Findings and Why They Matter
The agent was tested on several tough benchmarks:
- BrowseComp‑EN (English) and BrowseComp‑ZH (Chinese): Hard internet research tasks with multiple clues and steps.
- xBench‑DeepSearch and GAIA: Tool‑use and reasoning tests, including academic tasks.
- Humanity’s Last Exam (HLE): Deep academic questions from experts worldwide.
Results:
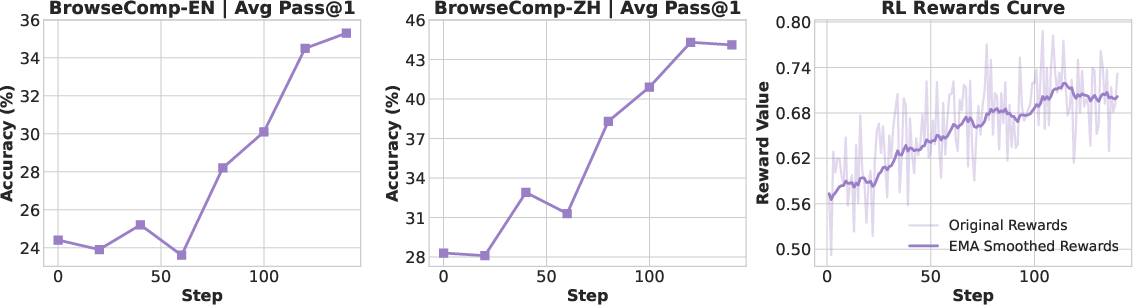
- WebSailor‑V2 scored 35.3 (EN) and 44.1 (ZH) on BrowseComp — the best among open‑source agents.
- It scored 73.7 on xBench‑DeepSearch and 74.1 on GAIA, competitive with top proprietary systems.
- On HLE, it scored 30.6 — beating even some much larger models, including a 671‑billion‑parameter system (DeepSeek‑V3.1) in that benchmark.
Key takeaways:
- A strong data pipeline plus stable RL can make a mid‑sized open‑source model perform like (or better than) giant models on deep research tasks.
- The SFT stage is crucial. Without a good starting policy, RL fails to learn well because successful trajectories (and rewards) are rare in complex tasks.
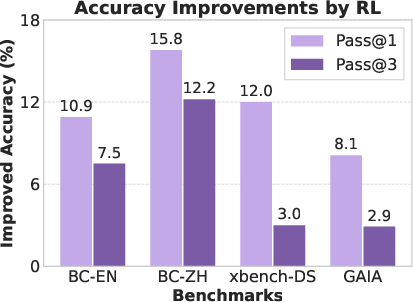
- RL improved first‑try accuracy most on simpler tasks (better choosing the right path immediately), and raised both first‑try and multiple‑try accuracy on harder tasks (genuinely boosting problem‑solving ability).
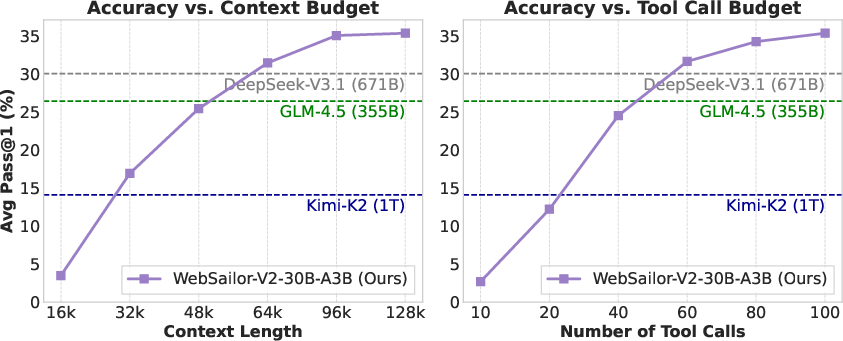
- Longer context helps: increasing the context window to 128k tokens allowed the agent to track long research sessions and improved accuracy, though most correct cases fit within 64k.
Implications and Potential Impact
This work shows a practical path to building strong, open‑source research agents:
- High‑fidelity training data that mirrors real web complexity teaches robust reasoning.
- A scalable, dual‑environment RL setup lets teams iterate fast and then reliably train in the real world.
- Careful tool management makes training affordable and stable.
- Smaller models, trained well, can challenge or beat much larger ones on difficult research tasks.
If widely adopted, these ideas could:
- Narrow the gap between open and closed AI systems in deep research.
- Make advanced research assistants more accessible to students, journalists, scientists, and small organizations.
- Encourage future work to add smarter context management, better report writing, and broader toolkits — on top of a strong, simple ReAct core.
In short, WebSailor‑V2 is a blueprint: build rich data, train safely at scale, and let a straightforward agent loop learn powerful, general research skills.
Knowledge Gaps
Below is a focused list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper that future work could act on:
- Data: The paper claims “a wider array of uncertainty definitions” beyond obfuscation but does not enumerate or taxonomize them, report their proportions, or ablate their individual contributions to capability gains.
- Data: No distributional statistics are provided for SailorFog-QA-V2 (graph size, entity/type coverage, degree distributions, cyclicity metrics), making it hard to assess structural diversity or replicate the sampling regime.
- Data: Decontamination procedures are not specified; it is unclear whether SailorFog-QA-V2 (or SFT/RL data) overlaps with evaluation benchmarks (BrowseComp, HLE, xbench), or how potential leakage is prevented/measured.
- Data: The symbiotic data-policy feedback loop is described conceptually, but concrete mechanisms (trigger criteria, sampling weights, filtering rules, and stopping conditions) are not specified or evaluated.
- Data: The dataset’s temporal coverage and handling of time-sensitive facts (e.g., evolving web content) are unspecified; robustness to temporal drift is untested.
- Data: Multilingual scope is limited to EN and ZH; there is no analysis of transfer to other languages or scripts, nor evaluation on region-specific search ecosystems (e.g., Baidu, Bing, Yandex).
- Data: Modality scope is restricted—GAIA is evaluated on a text-only subset; no support or experiments for images, PDFs with tables/figures, or scanned documents are provided.
- Simulator: The Wikipedia-only simulated environment lacks quantitative fidelity validation; no metrics quantify sim-to-real gap (e.g., action-observation distribution divergence, transfer ratio, or performance drop).
- Simulator: Search in simulation (offline Wikipedia) does not mirror live web ranking, snippets, or noise; the effect of index differences on learned policies is not measured.
- Simulator: Reward definitions/mechanics in simulation and real environments are not specified; it is unclear whether rewards are sparse, shaped, or aligned between environments.
- Training environment: The managed real environment’s reliability layer (caching, retries, fallback tools) is described, but no throughput, latency, failure-rate, or cost metrics are reported to establish scalability and reproducibility.
- RL algorithm: Key choices (token-level GRPO variant, leave-one-out baseline, negative-sample filtering) lack ablations; the contribution of each to stability and performance is not quantified.
- RL algorithm: Criteria for excluding “negative samples” are heuristically described but not formalized; the impact on bias, credit assignment, and sample efficiency is unknown.
- RL algorithm: No comparisons to alternative objectives (e.g., value-based critics, KL-control, entropy regularization schedules, trajectory-level rewards) or to off-policy methods are provided.
- RL dynamics: High policy entropy is observed but not connected to inference-time behavior; how entropy/exploration translates to stability, determinism, and user-facing reliability at deployment is not evaluated.
- SFT: The provenance and quality control of SFT trajectories (which open models generated them, acceptance rates, error types, and filtering thresholds) are not detailed; risk of codifying systematic errors is unassessed.
- Generalization: The agent is evaluated mainly on web research benchmarks; transfer to other agentic domains (GUI interaction, APIs, forms/auth flows, multi-step workflows with state) is unexplored.
- Tools/action space: The toolset is limited (search, visit, Google Scholar, Python); no support or evaluation for PDFs, citations export/verification, code execution with data files, spreadsheets, or structured API use.
- Security/safety: No evaluation of prompt injection, malicious content, data exfiltration, or code-sandbox escape risks; no red-teaming or defense strategies are reported.
- Robustness: Sensitivity to non-stationary search results, regional restrictions, CAPTCHAs/paywalls, crawler blocking, and content variability is not stress-tested.
- Evaluation: Heavy reliance on LLM-as-a-judge lacks calibration; inter-judge reliability, adjudication protocols, and sensitivity to judge model choice are not reported.
- Evaluation: Results are pass@1 with non-zero temperature; there is no systematic analysis across seeds/temperatures, no confidence intervals, and limited pass@k reporting—making significance and robustness unclear.
- Evaluation: Fairness controls are missing—tool-call budgets, context limits, and inference parameters for baselines (especially proprietary systems) are not standardized or normalized by cost.
- Compute/reporting: Training compute, token budgets, wall-clock time, and financial cost are not disclosed; reproducibility (seeds, exact checkpoints, tool versions) is limited without these details.
- Failure analysis: There is no systematic breakdown of failure modes (by uncertainty type, graph topology, domain, or tool failure), hindering targeted data or algorithmic improvements.
- Long-context behavior: While 128k context is used, strategies for context management (memory, summarization, retrieval, forgetting curves) and robustness to context overflow are not studied.
- Temporal robustness: No longitudinal evaluation is presented (re-running months later) to quantify performance drift due to web changes and tool variability.
- Ethical/legal: The paper does not discuss compliance with site terms, robots.txt, rate limits, or licensing when caching content (including Google Scholar); governance and auditability are unspecified.
- Benchmark scope: HLE and other benchmarks may have partial or evolving content overlap with training corpora (e.g., Wikipedia); explicit contamination checks and replication artifacts are absent.
- Presentation layer: The model underperforms slightly on report-writing vs retrieval; no concrete methods or ablations are provided to improve discourse quality, citation formatting, or factual grounding in generated reports.
Collections
Sign up for free to add this paper to one or more collections.

