Reinforcement Learning Foundations for Deep Research Systems: A Survey
Abstract: Deep research systems, agentic AI that solve complex, multi-step tasks by coordinating reasoning, search across the open web and user files, and tool use, are moving toward hierarchical deployments with a Planner, Coordinator, and Executors. In practice, training entire stacks end-to-end remains impractical, so most work trains a single planner connected to core tools such as search, browsing, and code. While SFT imparts protocol fidelity, it suffers from imitation and exposure biases and underuses environment feedback. Preference alignment methods such as DPO are schema and proxy-dependent, off-policy, and weak for long-horizon credit assignment and multi-objective trade-offs. A further limitation of SFT and DPO is their reliance on human defined decision points and subskills through schema design and labeled comparisons. Reinforcement learning aligns with closed-loop, tool-interaction research by optimizing trajectory-level policies, enabling exploration, recovery behaviors, and principled credit assignment, and it reduces dependence on such human priors and rater biases. This survey is, to our knowledge, the first dedicated to the RL foundations of deep research systems. It systematizes work after DeepSeek-R1 along three axes: (i) data synthesis and curation; (ii) RL methods for agentic research covering stability, sample efficiency, long context handling, reward and credit design, multi-objective optimization, and multimodal integration; and (iii) agentic RL training systems and frameworks. We also cover agent architecture and coordination, as well as evaluation and benchmarks, including recent QA, VQA, long-form synthesis, and domain-grounded, tool-interaction tasks. We distill recurring patterns, surface infrastructure bottlenecks, and offer practical guidance for training robust, transparent deep research agents with RL.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is a survey (a big review) about how to train “deep research systems” — AI agents that can plan and carry out multi-step investigations on the internet and in files, use tools like search and code, and then write good answers with citations. The authors argue that reinforcement learning (RL) is the best way to train these agents end to end, and they organize recent research into a clear map so others can build better systems.
What questions does the paper try to answer?
In simple terms, the paper asks:
- What are deep research agents, and how should they be built?
- Why do common training methods like “copying from examples” (SFT) or “picking the better answer” (DPO) fall short?
- How does reinforcement learning help an agent learn from trial and error across many steps and tools?
- How should we create training tasks, design rewards, and set up systems so these agents learn well?
- How do we evaluate whether these agents are actually good at real research?
How did the authors study it?
This is a survey, so the authors read many papers (mainly from 2025) and organized them into a few big themes. They also explain key ideas in easy-to-understand ways and point out patterns that keep showing up.
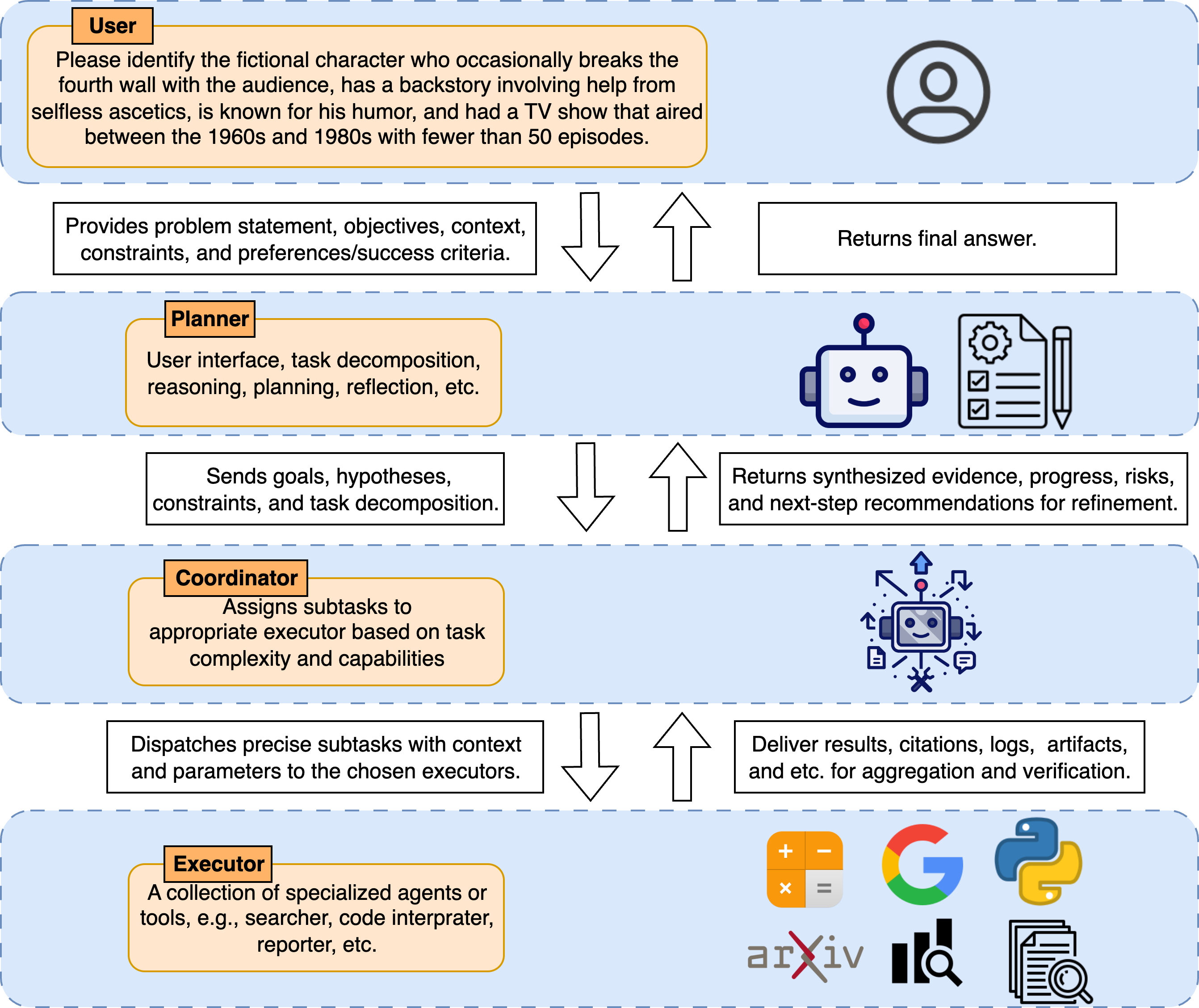
The pieces of a deep research agent
Think of a school project team:
- Planner: the “brain” that breaks the big problem into smaller steps and decides what to do next.
- Coordinator: the “team lead” who assigns tasks, collects results, and checks them.
- Executors: the “specialists” who do specific jobs — search the web, browse pages, run code, read images, etc.
In real systems, training the whole team at once is too hard. So most work trains just the Planner to get very good at reasoning and using a few core tools. Later, this stronger Planner can plug into the full team.
Why SFT and DPO aren’t enough
- SFT (Supervised Fine-Tuning) = “learn by copying examples.” Great for learning formats (like how to call a tool or cite sources), but weak for long tasks where early mistakes snowball.
- DPO (preference learning) = “learn by choosing between two drafts.” Helpful for picking better text, but it doesn’t truly connect actions (like which thing to search) to final success, and it depends a lot on hand-made labels and step designs.
Both miss the feedback loop of real-world tools and web changes (pages can move, sites can block you, prices change).
Why reinforcement learning (RL) helps
RL = “learn by doing, get a score, adjust.” It:
- Learns from the whole journey, not just the final sentence.
- Figures out which earlier steps deserve credit or blame (credit assignment).
- Encourages exploring different strategies and recovery behaviors (like trying a new query when one fails).
- Lets you balance goals: accuracy, time, cost, safety.
How to get training data for RL
To train by trial and error, you need good tasks and clear success checks. The survey explains two key levers:
- Construct: Create hard questions that require multiple steps, recent info, or multiple webpages (so the model can’t just guess or memorize). For example:
- Cross-document questions that need combining info from several sources.
- Browsing over link graphs (like clicking through Wikipedia) to find evidence.
- Easy-to-hard rewrites that gradually add more steps to solve.
- Obfuscation (hiding obvious clues) to prevent one-shot answers.
- Curate: Filter and schedule those tasks so learning is effective:
- Remove questions that are answerable from memory or one page.
- Keep tasks that can be checked automatically (exact answer, a test, or a reliable judge model).
- Use difficulty labels and curricula (start easier, ramp up).
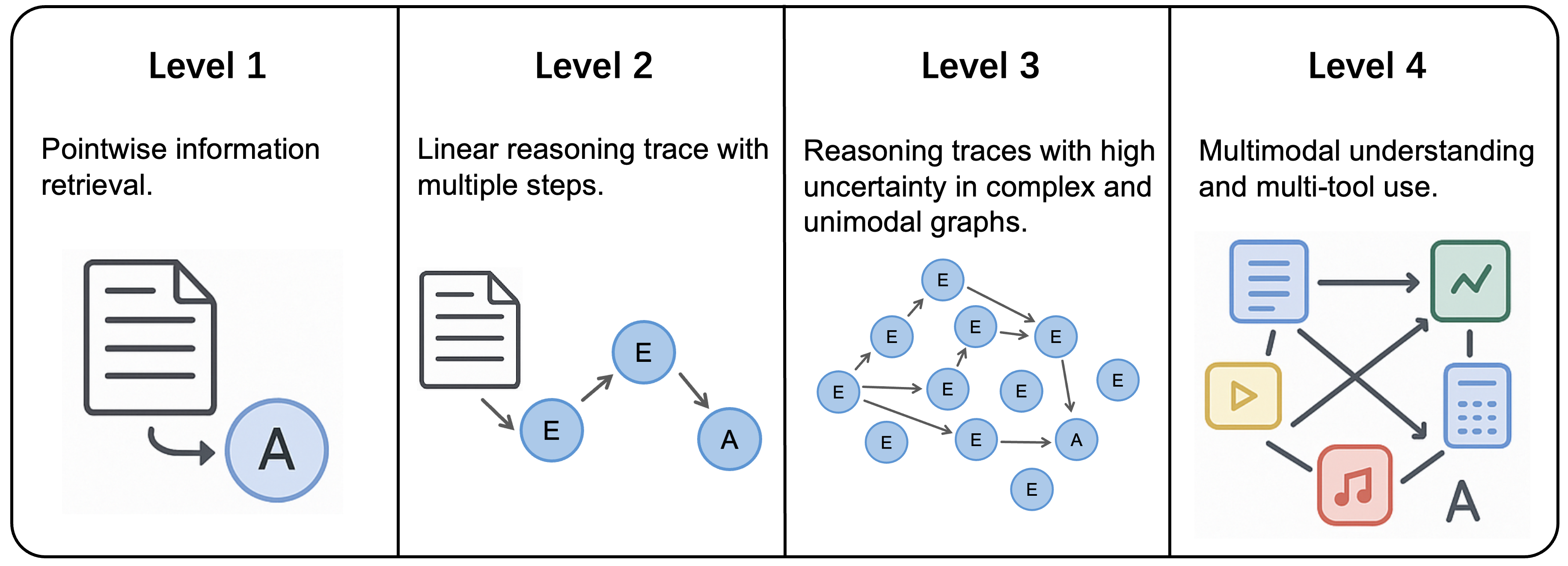
The authors also propose four “levels” of task difficulty:
- Level 1: Simple, answerable from memory or one search.
- Level 2: Multi-hop but with a clear path (classic multi-step QA).
- Level 3: Messy, uncertain, requires broad exploration and cross-checking across texts.
- Level 4: Like Level 3, but multimodal (text + images/audio/code) and multiple tools.
How RL training usually works
Typical training pipeline (in plain language):
- Cold start (optional): Give the model a short “practice phase” to learn formats and tool-calling basics so early RL doesn’t crash.
- Rollouts: For each question, the agent thinks, decides to search or use a tool, reads results, thinks again, and eventually answers — all in a structured script with tags like > , <search>, <information>, <answer>.
Rewards: Score the final answer (e.g., exact match), and sometimes also give small rewards for correct formatting. Some works add step-level signals (like “did this search actually help?”).
- Update: Use a training recipe (like PPO or GRPO) to improve the policy from these scores. Many systems “ignore” tool-generated text when updating so the model learns only from its own tokens.
Common improvements the survey highlights:
- Cold start helps stability and faster learning.
- Curriculum learning (start easy, go harder) improves results.
- Outcome rewards (final correctness) are most common; format rewards help structure; some add retrieval-usefulness rewards.
- Multiple training recipes exist (PPO, GRPO, REINFORCE); each trades off stability vs. speed, but they all work with the same overall loop.
Systems, architectures, and evaluation
- Training frameworks: Open-source toolkits are emerging to run many long, tool-based rollouts at scale. The survey lists these and notes bottlenecks (cost, logging, reproducibility).
- Architectures: The Planner–Coordinator–Executors setup is common. Multi-agent and hierarchical designs make it easier to swap tools, parallelize, and audit decisions.
- Benchmarks: A wide range of tests exist — from question answering, to browsing-heavy tasks, to long-form writing with citations, to domain-specific setups (finance, etc.), and multimodal benchmarks (text + images).
What did they find, in simple takeaways?
Here are the main lessons the authors distill:
- Training the whole stack end-to-end is impractical today. Focus on training the Planner well with RL, then plug it into a larger system.
- SFT and DPO are useful scaffolding (teach format and basic moves), but they don’t truly optimize multi-step, tool-using behavior in changing web environments.
- RL matches the problem: it learns strategies across many steps, uses real feedback from tools, and supports exploration and recovery.
- Good data is key: build tasks that force multi-step reasoning and recent info; curate them to remove shortcuts and schedule by difficulty.
- A practical curriculum: start with Level 1–2 to learn formats and basic planning, move to Level 3 for exploration and cross-checking, then Level 4 for multimodal skills.
- Common training patterns: cold start helps; curriculum helps; final-answer rewards plus small format checks are strong baselines; standard RL optimizers (PPO/GRPO) work reliably.
- Infrastructure matters: long rollouts, tool calls, and logging require solid systems. Masking tool tokens during training and keeping consistent formats improve stability.
- Evaluation is expanding: beyond short answers, tests now include browsing, long reports with citations, multimodal questions, and domain-grounded tasks.
Why is this important?
If we want AI that can do real research — not just write nice-sounding text — it must plan, search, read, verify, and synthesize across many steps and tools. This survey explains how RL can train those skills directly:
- Better reliability: Agents learn recovery strategies when searches fail or sources disagree.
- Less hand-holding: Fewer human-made step labels and rigid schemas.
- Clearer trade-offs: Agents can learn to balance accuracy, time, and cost.
- More transparency: Structured roles (Planner, Coordinator, Executors) make it easier to log, audit, and assign credit to steps.
The paper also points to promising future directions:
- Active task generation: Let the agent help create and pick the next best training tasks based on what it’s weak at.
- Better step-level judges: Cheap, reliable ways to score process quality (not just final answers).
- Stronger multimodal and multi-objective training: Integrate images, tables, code, and clear goals (accuracy, safety, cost) over long horizons.
- Scalable systems: Faster, cheaper infrastructure for many long, tool-rich training runs.
In short, this survey offers a roadmap for building robust, transparent “AI researchers” using reinforcement learning — moving from copying examples to truly learning how to investigate and decide.
Collections
Sign up for free to add this paper to one or more collections.