- The paper demonstrates that introducing input-dependent positional embeddings enables robust cognitive map learning, significantly improving OOD generalization in AI navigation tasks.
- The MapFormer-EM and MapFormer-WM variants integrate absolute and relative positional encodings to effectively model episodic and working memory systems.
- Experimental results show that MapFormer outperforms baseline models like RoPE and CoPE, confirming the benefits of a structural bias in complex decision-making.
Introduction
The concept of cognitive maps, originally proposed by Edward Tolman, suggests that humans and animals maintain internal models that encode abstract relationships among entities in the world, facilitating adaptation to novel situations. Despite the impressive capabilities of Transformers to process sequences and enable the training of models to generate coherent outputs across diverse tasks, they often lack the ability to generalize well to out-of-distribution scenarios. This gap underscores the potential of cognitive maps, which are inherently robust to OOD generalization, due to their capacity to disentangle structural relationships from specific content.
MapFormer introduces architectures rooted in Transformer models to learn cognitive maps from observational data. By incorporating input-dependent positional embeddings, these models can disentangle structure from content naturally. Two variants of MapFormer unify absolute and relative positional encoding to model episodic (EM) and working memory (WM), respectively. The paper presents substantial empirical evidence of MapFormer’s superior performance in navigation tasks, providing a compelling case for the inclusion of structural bias in AI models.
Cognitive Maps in AI
Current AI systems generally lack the flexible adaptability exhibited by humans and animals, often failing in OOD generalization tasks. Cognitive maps encode abstract relationships and support flexible decision-making, extending beyond spatial navigation to encompass abstract conceptual information. Human cognition exemplifies robustness and flexibility due to this ability to develop cognitive maps. Crucially, cognitive maps separate invariant world structures from variable content components observed in data. Disentangling structure from content reduces the required training data significantly, facilitating stronger generalization capabilities.
The concept of path integration, a process that involves mentally simulating the impact of future actions and maintaining an internal estimate of location, is fundamental for decision-making. It's a significant advantage that allows animals to represent planned actions and adapt rapidly to manipulations in their environment.
MapFormers leverage self-supervised learning, unifying relative rotary and absolute positional embeddings to represent cognitive constructs. The introduction of action-dependent positional embeddings in MapFormer models supports robust encoding of cognitive maps. This structural bias ensures strong generalization abilities even in complex tasks and facilitates inherent flexibility in adapting the encoded map for diverse scenarios.
Two variants, MapFormer-EM and MapFormer-WM, were developed to model episodic and working memory systems. The EM variant relies on absolute positional embeddings to form cognitive maps, factoring in content encoded neural population distinctly from structure. In contrast, the WM variant utilizes relative positional encoding, implicitly representing sequence information in concert with content.
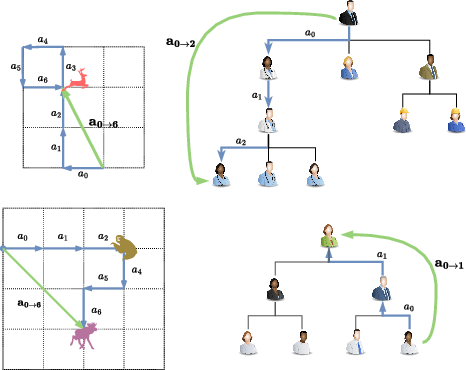
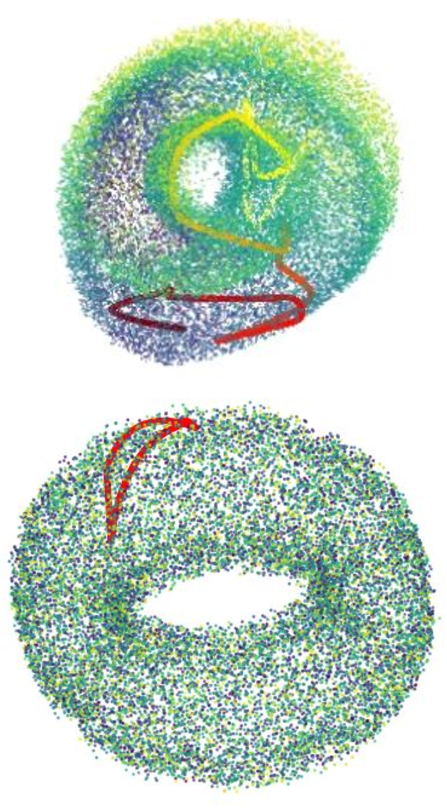
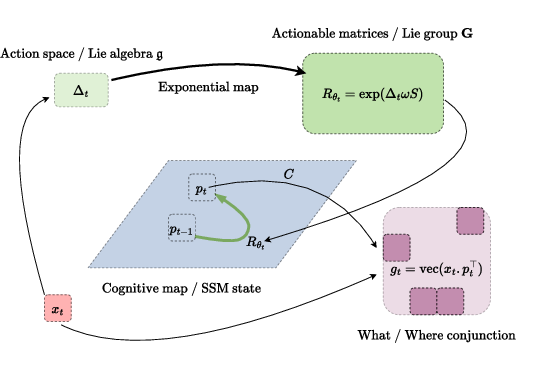
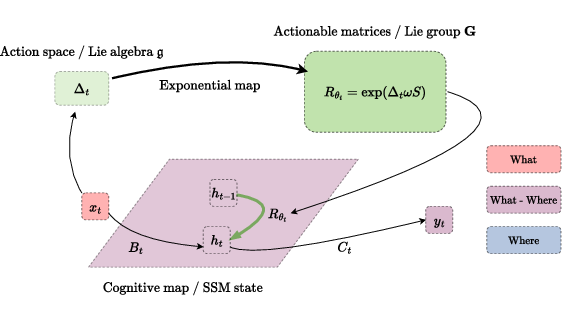
Figure 1: Cognitive Maps: Disentangling Structure and Content for Path Integration in Episodic and Working-Memory Models.
Path Integration and Neural Mechanisms
Implementing scalable cognitive maps necessitates profound modifications in current architectures. Previous work utilizing recurrent neural networks highlighted that input-dependent matrices hold potential for action representation. While highly effective in structured tasks, these models do not scale efficiently due to sequential processing.
MapFormers address these limitations by integrating path operations into Lie-group theory, wherein action-dependent matrices are subgroups capable of performing structural mapping actions. Through input-dependent positional embeddings and parallel processing capabilities of Transformers, MapFormers compute path integration efficiently.
Architecture-specific roles in MapFormer variants facilitate distinct memory functions. MapFormer-EM stores structured memories via a neural population encoded in positional embeddings, akin to episodic recall. Conversely, MapFormer-WM embeds sequence memory along neural activity slots, integrating what and where in distinct memory slots.
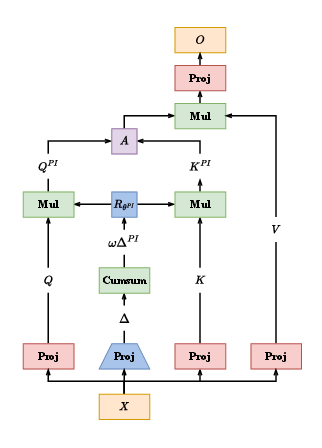
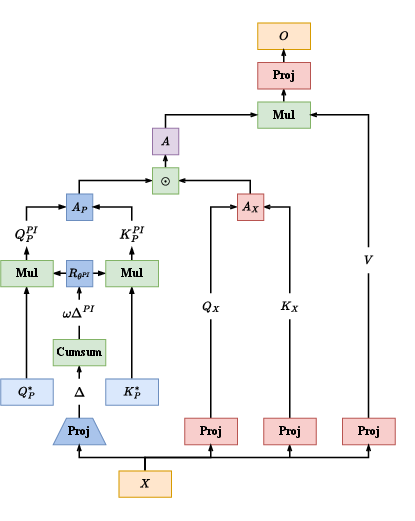
Figure 2: MapFormers: Path-Integration Transformer-Based Models that Learn Cognitive Maps.
Experimental Insights
MapFormers are evaluated on tasks including selective copy and forced grid navigation, both exhibiting complex structural dependencies. Results demonstrate superior performance of MapFormer models over baseline models such as RoPE and CoPE in generalizing OOD scenarios efficiently.
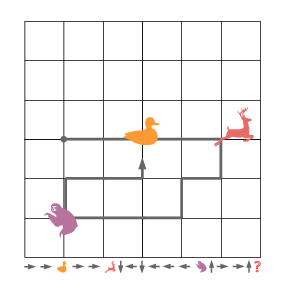
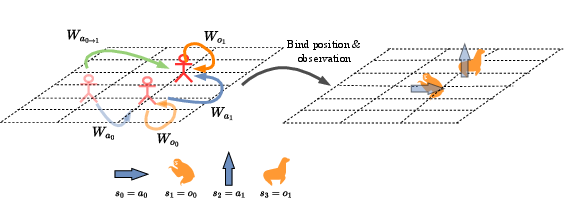
Figure 3: Model Performance in Selective Copy and Forced Grid Navigation Tasks.
Empirical analyses suggest that architecture choices fundamentally impact learning efficiency in recall versus reasoning tasks. Experiments ascertain MapFormer-EM models demonstrate enhanced recall capabilities, scaling effectively with increased model size, sequence length, and vocabulary size.
Conclusion
MapFormer architectures offer a robust advancement in AI, representing a key shift toward integrating cognitive-inspired approaches in scalable models. The efficient disentanglement of structure from content opens new avenues in both AI and neuroscience for modeling complex decision-making frameworks. Future work could involve extending these insights to broader, non-spatial domains, thereby enhancing the AI models’ interpretability and robustness in diverse applications. Further, the interplay between abstract learning via cognitive maps and real-world task applications presents compelling research trajectories.
The advancements presented in MapFormers elucidate the inherent value in binding cognitive paradigms with existing AI frameworks, effectively addressing limitations in current AI models and underscoring the intersection of neuroscience with computational learning theories. Through sophisticated architectural modifications, MapFormer paves the way for genuinely adaptable and resilient AI systems, marking a substantial progression in both fields.