- The paper demonstrates that transformer models can rapidly learn optimal actions in reinforcement learning tasks by leveraging episodic memory mechanisms.
- It employs a meta-learning framework on gridworld and tree maze tasks to reveal structured internal representations that align with environmental layouts.
- The findings show that transformers generalize across similar contexts via flexible memory retrieval, outperforming traditional reinforcement learning methods.
Mechanisms of In-Context Reinforcement Learning in Transformers
Introduction
The paper "From Memories to Maps: Mechanisms of In-Context Reinforcement Learning in Transformers" explores how transformers can mimic biological learning processes by using in-context learning for reinforcement learning tasks. The research aims to understand how these models can perform fast and efficient learning by leveraging their memory architecture, akin to episodic memory in animals. The study uses transformer models trained on tasks inspired by rodent behavior, seeking to uncover the emergent learning mechanisms and their parallels to natural cognition.
The experiments utilize a meta-learning framework where transformers are trained on a distribution of planning tasks, including spatially regular gridworlds and hierarchically structured tree mazes. The meta-learning setup involves training the transformer to predict optimal actions given in-context experiences, using a supervised pretraining approach inspired by decision-pretraining transformers (DPTs).
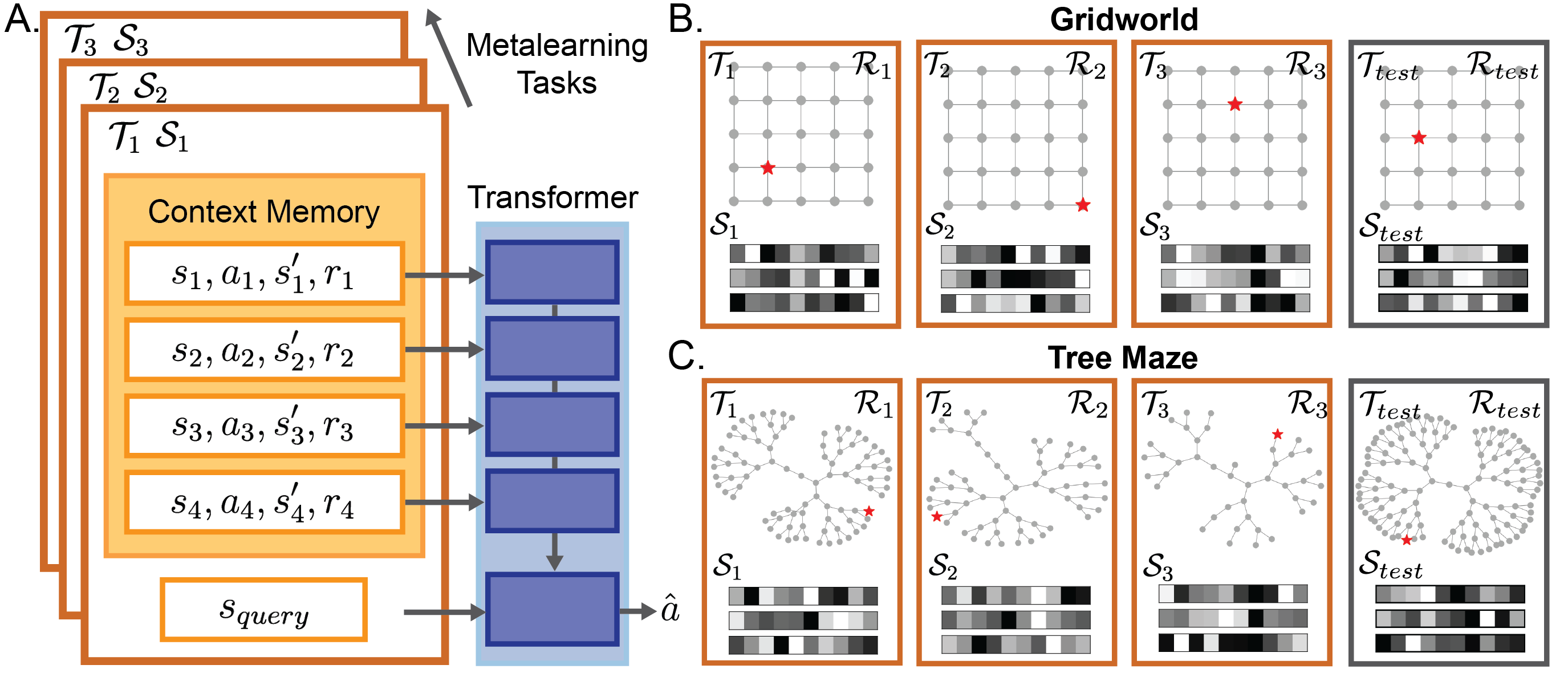
Figure 1: A transformer is trained to in-context reinforcement learn in diverse planning tasks. A. Diagram of the meta-learning setup.
Rapid Learning and Planning
Transformers trained under this paradigm demonstrate the capacity for rapid adaptation in new tasks, achieving high returns after minimal reward exposures. The model's performance surpasses traditional reinforcement learning methods such as tabular Q-learning and deep Q-networks (DQN), particularly in its ability to find efficient paths in new environments.
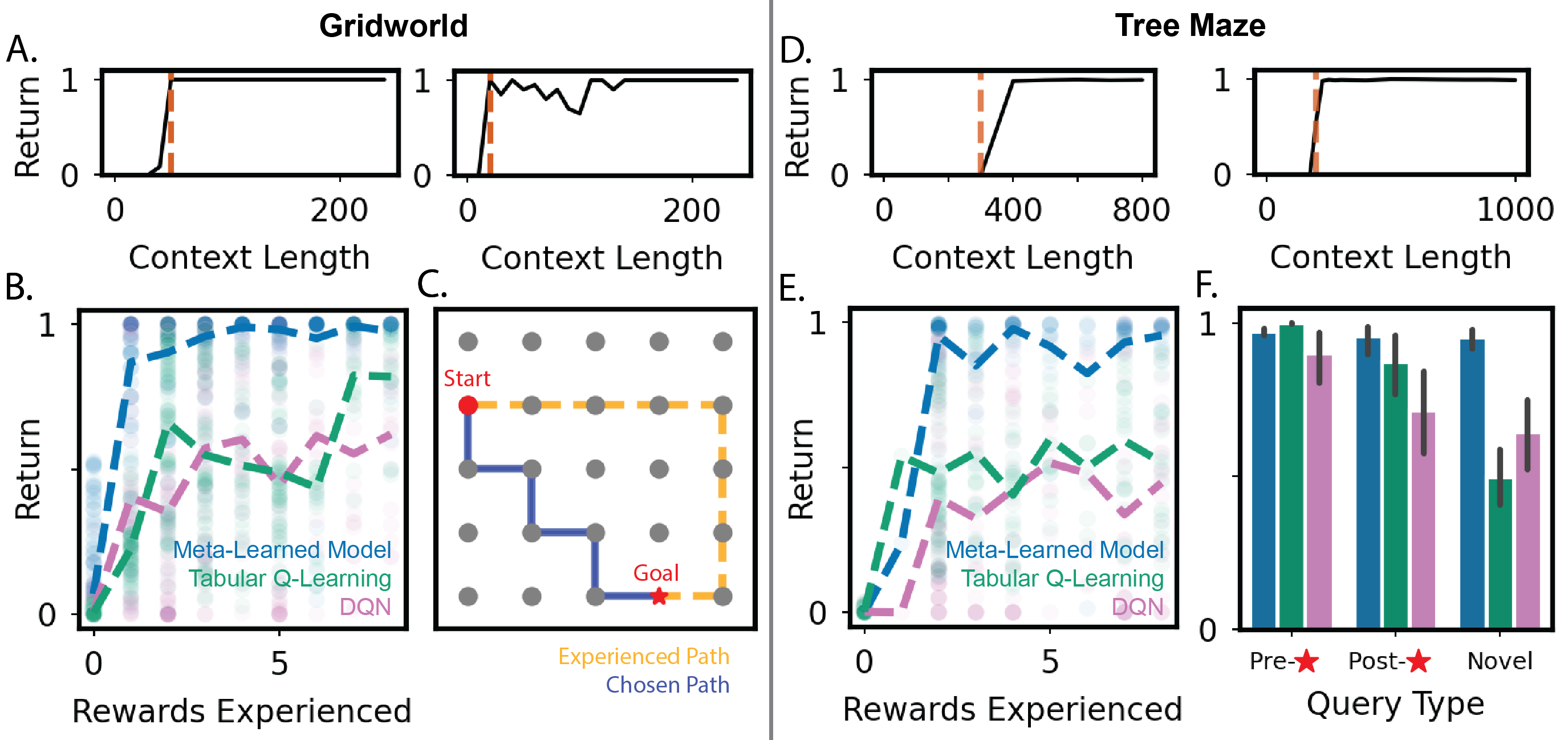
Figure 2: Transformers can rapidly learn and plan in new tasks, outperforming baselines like tabular Q-learning and DQN.
In-Context Structure Learning
The research shows that transformers develop structured internal representations through in-context learning. In gridworld tasks, these representations align well with the Euclidean structure of the environment, while in tree mazes, they reflect more hierarchical layouts. This alignment improves with the length of in-context exposure and is crucial for the model's decision-making process.
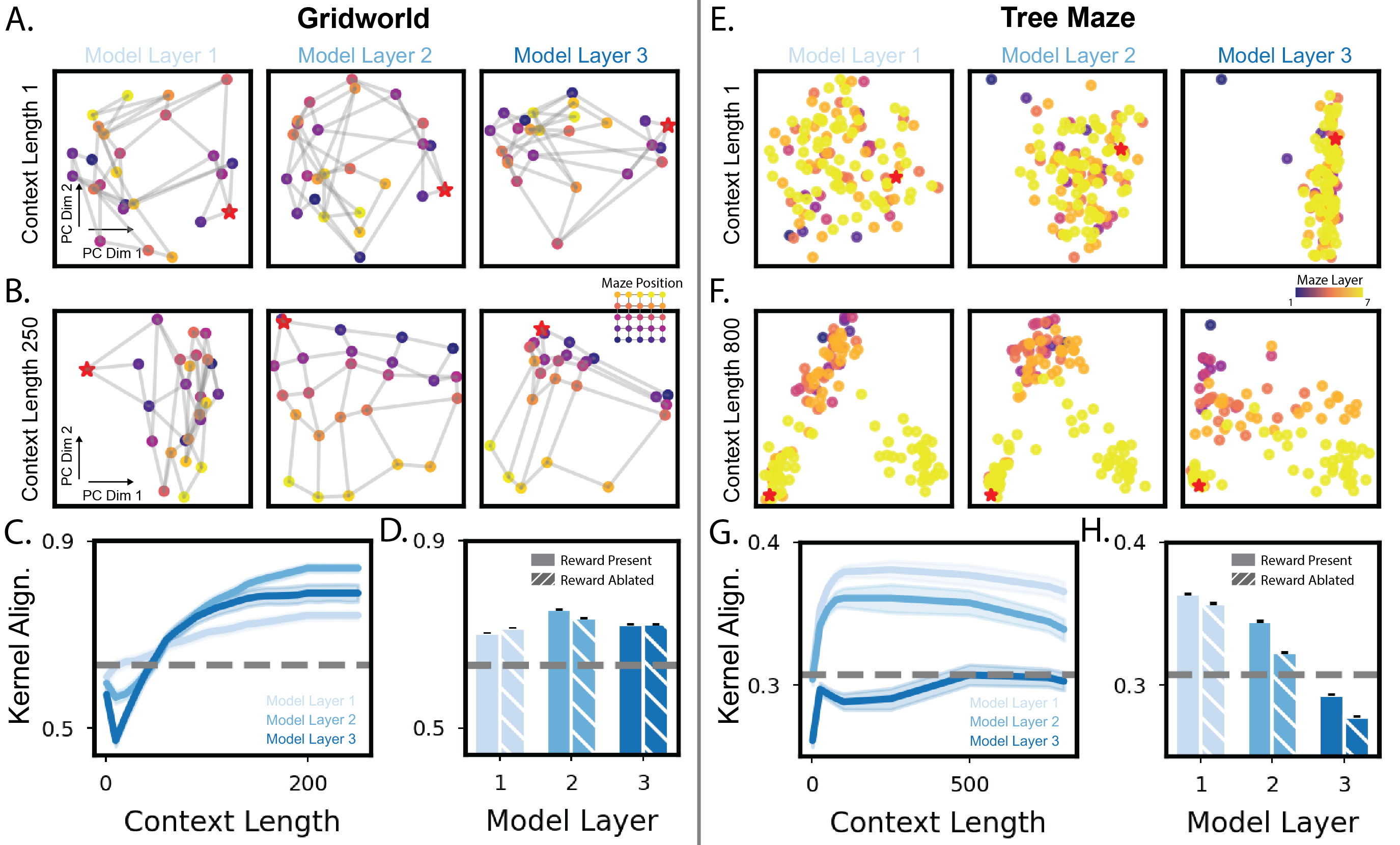
Figure 3: Model representations are shaped by in-context structure learning, showing alignment with environment structures.
Cross-Context Representation Alignment
Another significant finding is that transformers align representations across different environments sharing similar structures. This cross-context alignment suggests that transformers can generalize learned strategies and adapt them to novel, structurally similar settings, mimicking a capability thought to be supported by the hippocampal–entorhinal circuit in the brain.
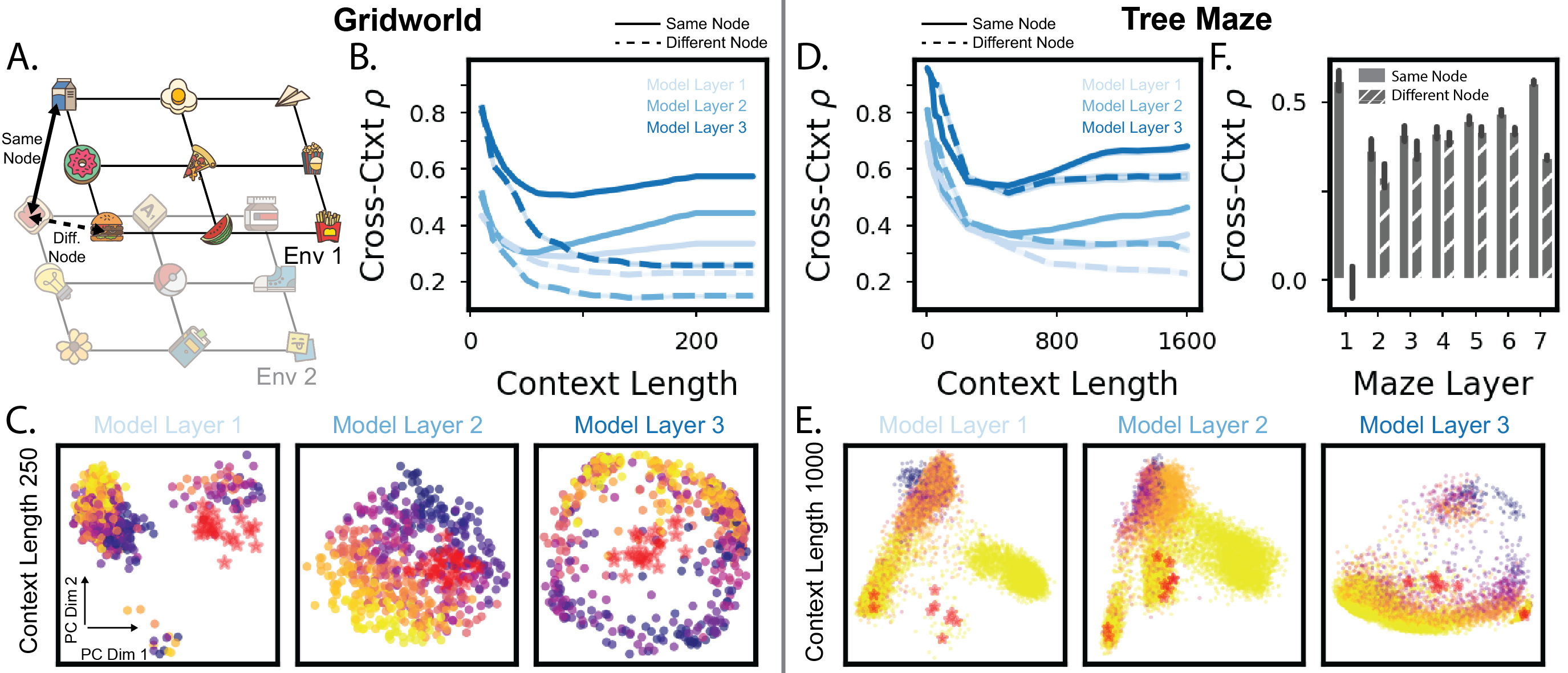
Figure 4: As context grows, representations align across environments with similar structures.
Memory Retrieval and Decision-Time Computation
The model's decision-making process is characterized by limited expansion of memory retrieval, focusing on states near the query and goal. This pattern indicates that transformers do not engage in traditional model-based planning, such as simulating paths through intermediate states, but instead rely on flexible memory retrieval strategies.
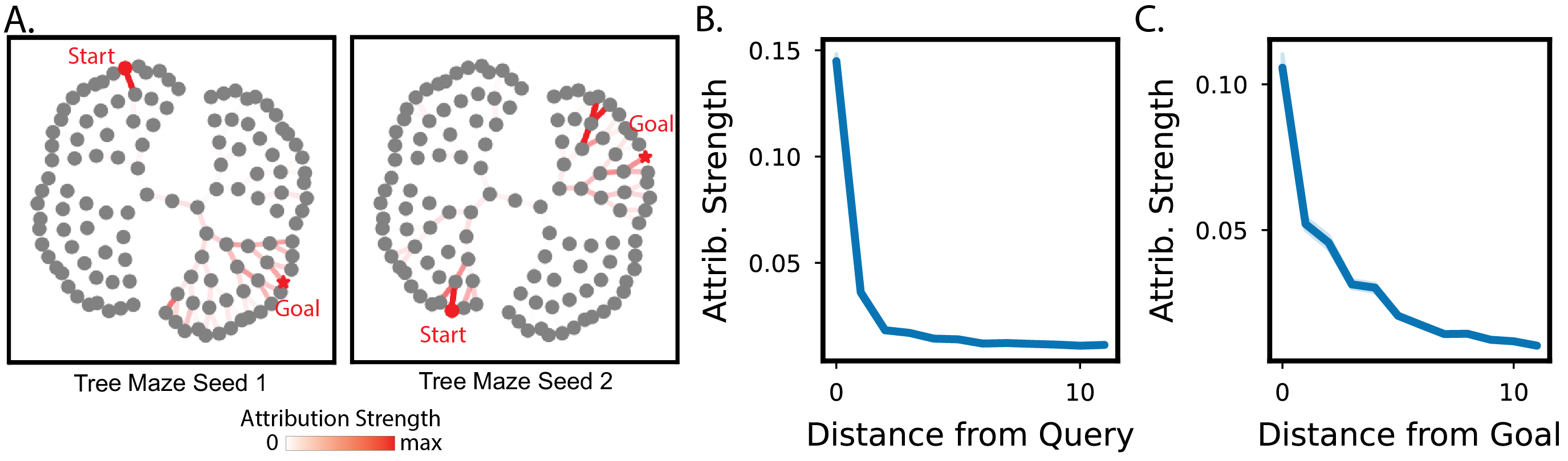
Figure 5: Memory retrieval at decision time shows limited expansion from the query and goal states.
Non-Model-Free and Non-Model-Based Learning Strategies
The study finds that the implemented reinforcement learning strategy does not resemble traditional model-free or model-based approaches. In gridworld tasks, transformers achieve a spatial understanding of the environment, allowing them to bypass unseen states. In tree mazes, they tag critical paths and heuristically navigate towards rewards.
Conclusion
The exploration of in-context reinforcement learning in transformers reveals insights into how such models can efficiently learn and adapt, paralleling biological systems. This work opens avenues for future research into the cognitive processes underlying rapid learning and the broader implications of using episodic memory-inspired architectures for artificial intelligence. Such advances could contribute to developing AI systems capable of adaptive and flexible decision-making in dynamically changing environments.

