- The paper introduces an RL-based framework that dynamically constructs and manages memory to optimize long-context processing.
- It features a modular architecture with core, episodic, and semantic components, improving answer accuracy and memory efficiency.
- Empirical results demonstrate significant gains, enabling agents to handle sequences an order of magnitude longer than training data.
Mem-$: Learning Memory Construction via Reinforcement Learning
Introduction
The paper "Mem-α: Learning Memory Construction via Reinforcement Learning" (2509.25911) introduces a method to enhance LLMs constrained by limited context windows by developing sophisticated memory management strategies through reinforcement learning (RL). Unlike traditional memory-augmented agents, which typically rely on predefined instructions, Mem-α enables agents to dynamically learn how to manage memory systems. This approach optimizes memory construction through interaction, feedback, and a specially designed training dataset aimed at teaching effective memory management.
Reinforcement Learning Framework
Mem-α formulates memory construction as a reinforcement learning problem. The agent processes information chunks in a sequence and optimizes memory operations by maximizing reward signals based on downstream task performance, specifically question-answering accuracy. The architecture includes core, episodic, and semantic memory components, each designed to handle distinct types of information effectively.
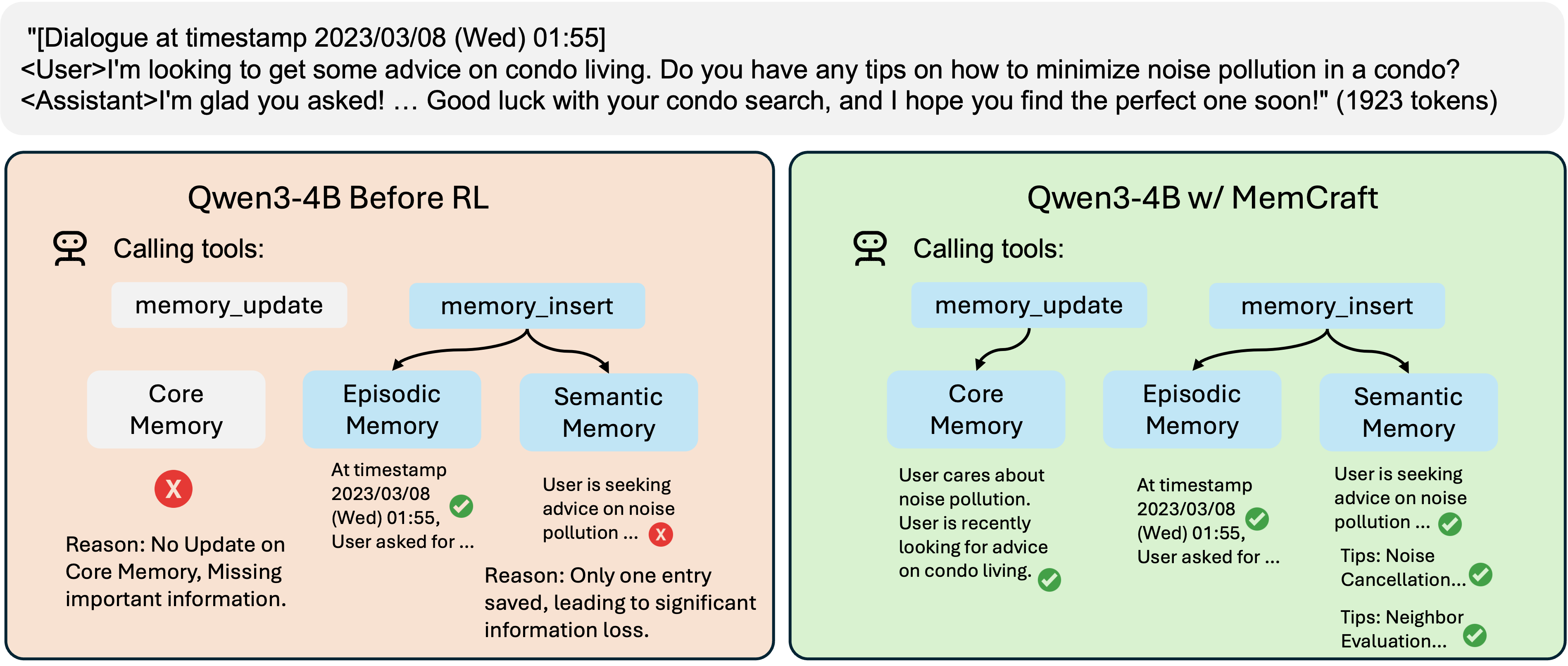
Figure 1: Reinforcement learning teaches agents to select appropriate memory tools and types. Before training (left), agents struggle with tool selection when given new information. After RL training (right), agents learn effective memory management policies.
Methodology
Memory Architecture
The memory architecture consists of:
- Core Memory: Stores continuous summaries of essential context.
- Semantic Memory: Retains factual, declarative knowledge as structured factual statements.
- Episodic Memory: Captures temporally-grounded events and experiences in a chronological manner.
This modular design allows flexible adaptation and sophisticated management of long-term storage, which traditional systems often overlook.
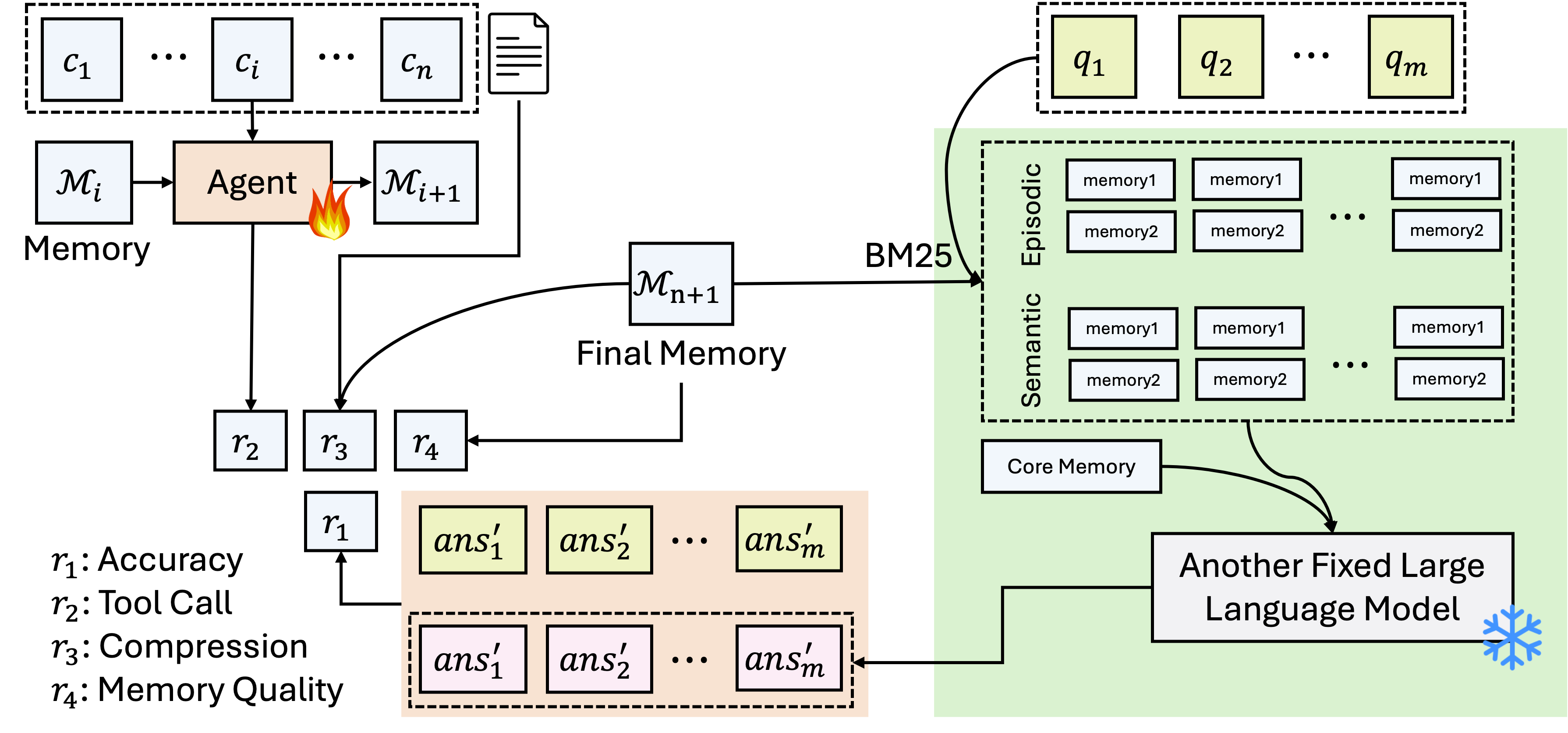
Figure 2: Training Framework of Mem-α.
Training and Reward Signal
Training focuses on processing interactions, deciding which memory tools and operations to apply, and is guided directly by question-answering accuracy. Four types of rewards are defined:
- Correctness Reward: Based on the accuracy of answers to evaluation questions.
- Tool Call Format Reward: Measures the percentage of correctly formatted function calls.
- Compression Reward: Encourages efficient memory use by promoting compact representations.
- Memory Content Reward: Ensures the semantic correctness of memory operations.

Figure 3: Memory Architecture: Core Memory stores a single paragraph (max 512 tokens), while Semantic Memory and Episodic Memory maintain expandable lists of sentences for facts and timestamped events, respectively.
Empirical Evaluation
Empirical evaluations reveal that Mem-α performs significantly better than state-of-the-art systems across benchmarks used to test memory-augmented agents. Notably, Mem-α exhibits robust generalization capabilities, handling sequences that are an order of magnitude longer than those present in the training data.
Technical and Practical Implications
Mem-α demonstrates a leap in memory construction for LLMs, enabling more efficient handling of long-term conversations and data processing. This method addresses the inherent limitations of context sizes in LLMs, paving the way for more advanced applications that require nuanced understanding and retention of extensive informational permutations.
These innovations imply potential applications in complex, real-world environments where dynamic information processing is critical, such as in adaptive conversational agents, and can further translate to scalable solutions in other memory-intensive computational paradigms.
Conclusion
Mem-α offers a robust framework for constructing and managing agent memory, significantly enhancing the long-term utility of LLM agents. The integration of RL provides agents with the ability to adapt and learn effective memory strategies autonomously. Future work could extend Mem-α's architecture to more complex memory systems and pursue its integration in interactive applications requiring real-time memory adaptation.