- The paper introduces the MemAct framework, making memory management an intrinsic, learnable part of an agent’s policy for long-horizon tasks.
- It presents the DCPO algorithm to segment trajectories at memory action points for stable policy optimization and improved efficiency.
- Experimental results reveal that MemAct enables smaller models to outperform larger baselines by adaptively managing memory and tool use.
Memory as Action: Autonomous Context Curation for Long-Horizon Agentic Tasks
Introduction and Motivation
The paper introduces the Memory-as-Action (MemAct) framework, which reconceptualizes working memory management in long-horizon agentic tasks as an intrinsic, learnable component of the agent's policy, rather than an external, heuristic-driven process. The motivation stems from the observation that, in complex tasks requiring extended reasoning and tool use, the effectiveness of LLM-based agents is fundamentally limited by their ability to curate and maintain a relevant working memory. Traditional approaches rely on external controllers or handcrafted heuristics for memory operations such as selection, compression, and summarization, which are decoupled from the agent’s core decision-making. This separation precludes end-to-end optimization and prevents the agent from learning context curation strategies that are adaptive to its own capabilities and the demands of the task.
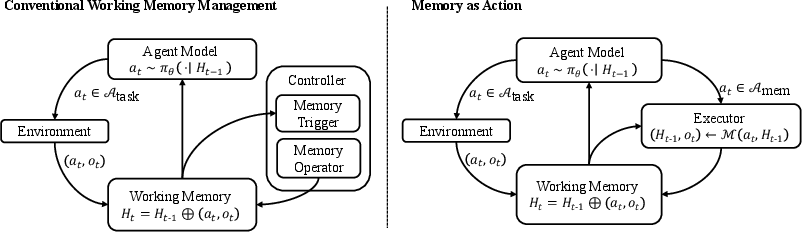
Figure 1: Comparison between MemAct and conventional memory management. MemAct integrates memory operations into the agent's policy, enabling goal-directed, policy-driven memory management.
MemAct formalizes context curation as a sequence of explicit, learnable memory-editing actions within the agent’s action space. The agent’s state at each timestep is the current working memory, a structured sequence of historical observations, tool calls, and outputs. The action space is partitioned into task actions (interacting with the environment) and memory actions (editing the working memory). Memory actions can prune, summarize, or otherwise transform the memory, breaking the standard append-only, prefix-accumulating assumption of LLM trajectories.
This design enables recursive and meta-level memory management, as the agent can edit not only task-relevant content but also records of prior memory actions. The agent is trained to maximize a sparse, terminal reward that combines task success with adherence to resource constraints (e.g., context length, token usage).
Dynamic Context Policy Optimization (DCPO)
The introduction of memory-editing actions creates "trajectory fractures," where the working memory is no longer a simple extension of the previous state. This disrupts the causal continuity required by standard policy gradient methods, which assume monotonic, prefix-accumulating histories. To address this, the authors propose Dynamic Context Policy Optimization (DCPO), a reinforcement learning algorithm that segments trajectories at memory action points. Each segment is treated as a causally consistent unit for policy gradient computation, and trajectory-level advantages are assigned based on the final outcome.
The DCPO training loop involves:
- Rolling out multiple trajectories per prompt.
- Segmenting each trajectory at memory action points.
- Sampling segments for policy updates.
- Computing group-normalized advantages per trajectory.
- Updating the policy using a masked loss that attributes gradients only to tokens generated within each segment.
This approach ensures stable and correct policy optimization in the presence of non-monotonic, editable histories.
Implementation Details
Memory management is operationalized via a prune_context tool, which takes as input a model-generated summary and a list of record IDs to prune. The agent invokes this tool as part of its action space, and the executor updates the working memory accordingly. For policy initialization, a segmented supervised fine-tuning (SFT) phase is used, leveraging MemAct-style demonstration data generated via staged prompting of a strong LLM. The DCPO phase then refines the policy using RL, with a reward signal provided by an automated evaluator (gpt-oss) that checks answer correctness and penalizes resource violations.
Experimental Results
Multi-Objective QA
On the Multi-Objective QA dataset, MemAct-14B-RL achieves a leading average accuracy of 59.1%, outperforming the much larger Qwen3-235B model, while using substantially fewer input tokens per round (3,447 vs. 8,625 for Search-R1-14B). The model generalizes robustly to tasks with more objectives than seen during training, with accuracy degrading gracefully as task complexity increases.
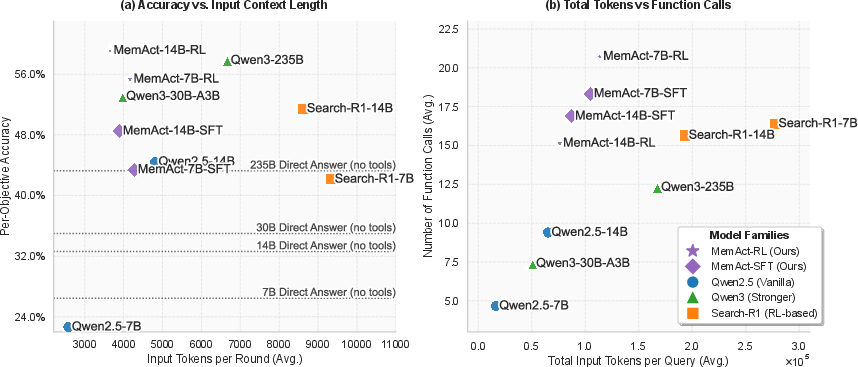
Figure 2: Model performance on the Multi-Objective QA dataset. MemAct achieves higher accuracy with greater context efficiency compared to baselines.
A detailed breakdown of tool usage reveals that MemAct enables smaller models to adopt adaptive strategies: the 14B model learns to use fewer external tools post-RL, while the 7B model compensates for its weaker internal knowledge by increasing both tool use and memory management actions. Both strategies are highly token-efficient, demonstrating that MemAct does not enforce a single policy but allows RL to discover approaches tailored to the model’s capabilities.
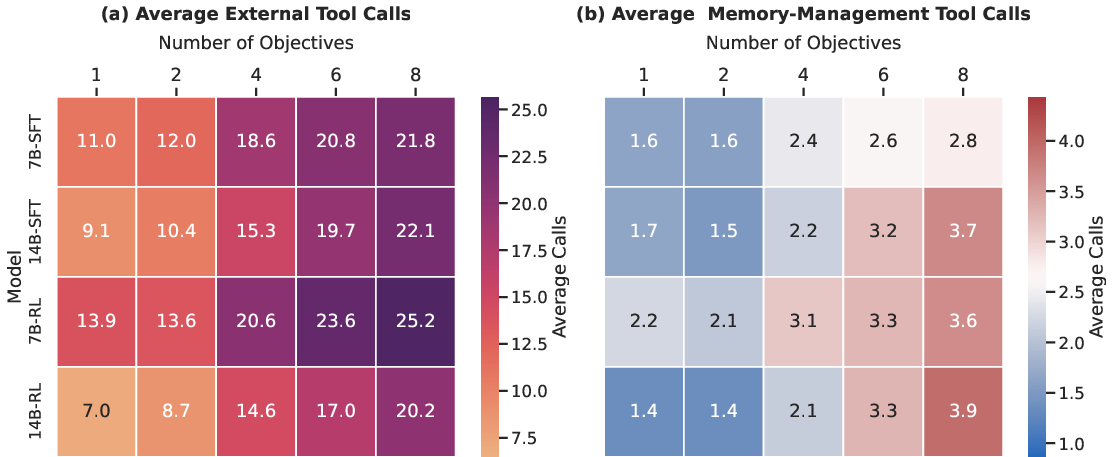
Figure 3: Tool usage by objective count. RL-tuned MemAct models adapt their external tool and memory management calls according to task complexity and model capacity.
Multi-hop QA Benchmarks
Across five multi-hop QA benchmarks, MemAct-14B-RL achieves an average score of 0.567, nearly matching the Search-R1 baseline (0.572) but with greater token efficiency. The RL phase consistently improves over SFT, especially on benchmarks requiring longer reasoning chains, indicating that end-to-end RL is effective at refining memory and tool-use policies for complex, long-horizon tasks.
Training Efficiency
The use of memory pruning in MemAct reduces rollout and policy update times by 40% and 25%, respectively, for the 7B model, compared to a no-memory baseline. This demonstrates a practical benefit in terms of computational resource savings.
Implications and Future Directions
The MemAct framework establishes that memory management can and should be an intrinsic, learnable part of agentic LLM policies. By integrating memory actions into the policy, agents can learn to balance reasoning depth, context relevance, and computational efficiency in an end-to-end fashion. This approach is compatible with existing RL pipelines and can be deployed with standard hardware and training infrastructure.
Theoretically, MemAct challenges the prevailing paradigm of external, heuristic-driven memory management and demonstrates that RL can discover adaptive, model-specific context curation strategies. Practically, it enables smaller models to compete with much larger ones on long-horizon tasks, provided they are equipped with effective memory policies.
Future work should explore more sophisticated memory operations, extend the framework to a broader range of agentic tasks, and further analyze the emergent trade-offs between reasoning depth and efficiency. The segmentation and trajectory-level optimization techniques introduced here may also inform RL approaches for other non-monotonic, history-editing agent architectures.
Conclusion
Memory-as-Action reframes working memory management as a core, learnable component of agentic LLMs, enabling end-to-end optimization of both reasoning and context curation. The DCPO algorithm addresses the unique challenges posed by editable histories, supporting stable RL training. Empirical results demonstrate that MemAct yields agents that are both more effective and more efficient, with adaptive strategies that generalize to complex, long-horizon tasks. This work provides a foundation for future research on intrinsic memory management and its role in scalable, resource-efficient AI agents.

