Large VLM-based Vision-Language-Action Models for Robotic Manipulation: A Survey
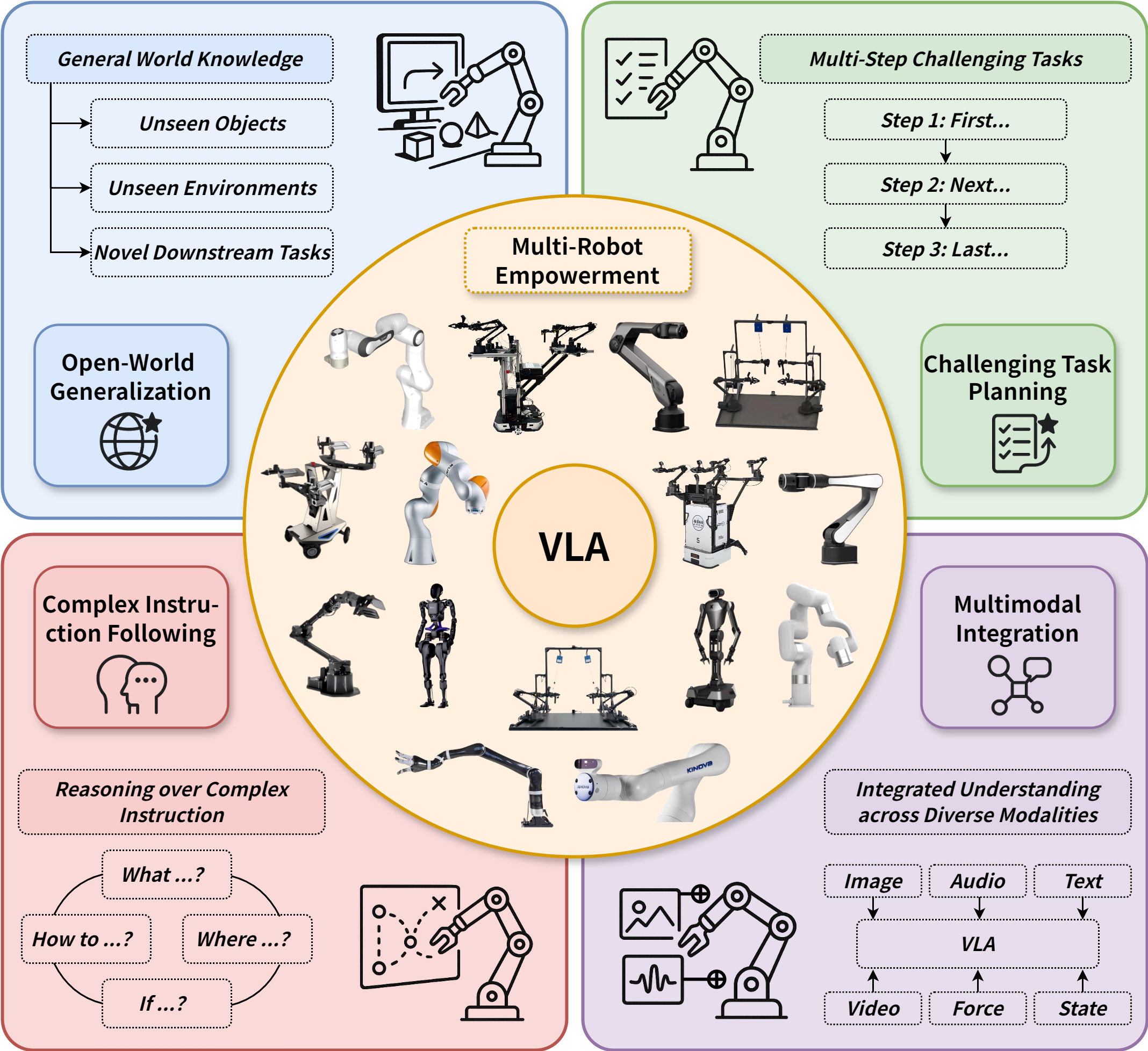
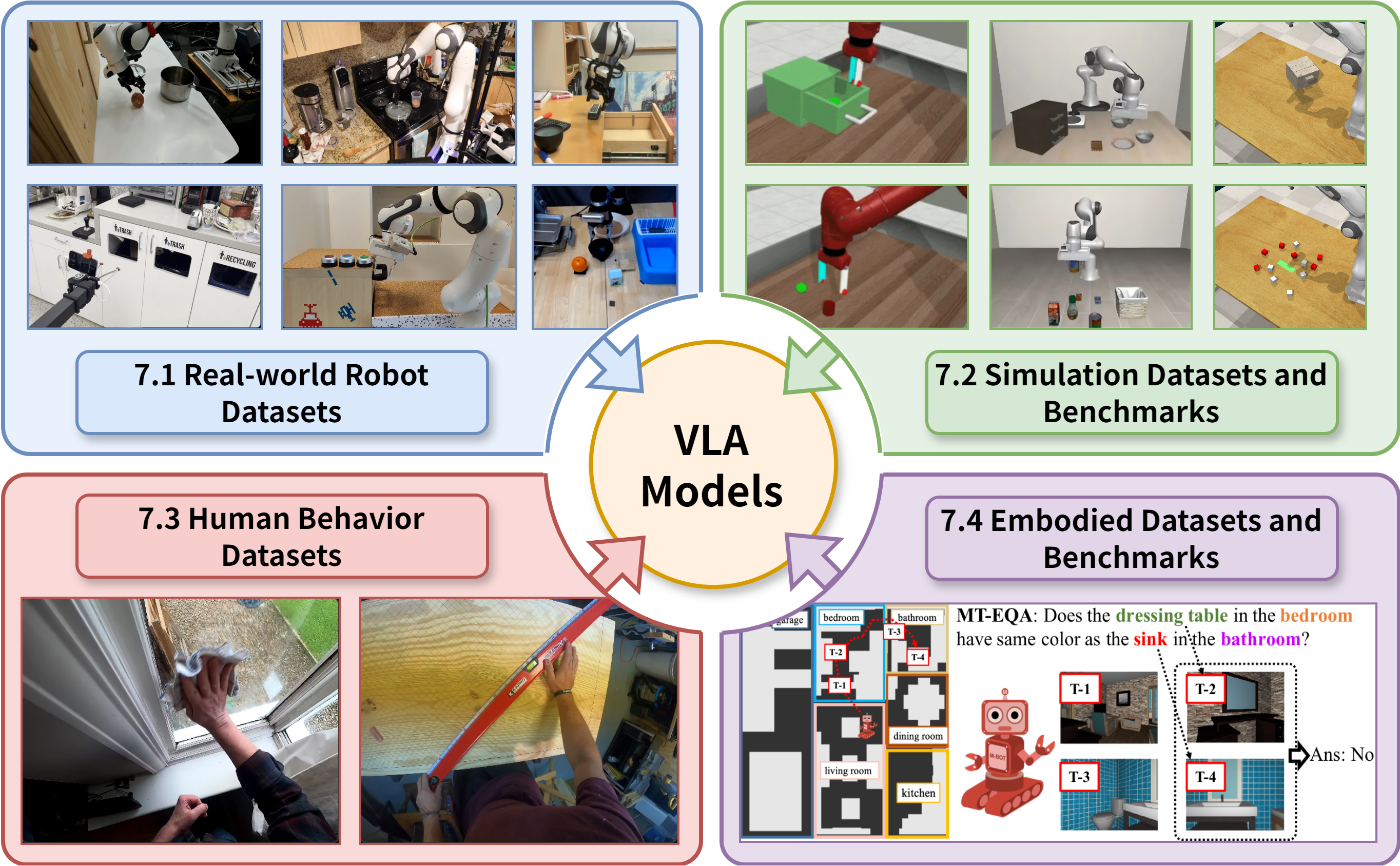
Abstract: Robotic manipulation, a key frontier in robotics and embodied AI, requires precise motor control and multimodal understanding, yet traditional rule-based methods fail to scale or generalize in unstructured, novel environments. In recent years, Vision-Language-Action (VLA) models, built upon Large Vision-LLMs (VLMs) pretrained on vast image-text datasets, have emerged as a transformative paradigm. This survey provides the first systematic, taxonomy-oriented review of large VLM-based VLA models for robotic manipulation. We begin by clearly defining large VLM-based VLA models and delineating two principal architectural paradigms: (1) monolithic models, encompassing single-system and dual-system designs with differing levels of integration; and (2) hierarchical models, which explicitly decouple planning from execution via interpretable intermediate representations. Building on this foundation, we present an in-depth examination of large VLM-based VLA models: (1) integration with advanced domains, including reinforcement learning, training-free optimization, learning from human videos, and world model integration; (2) synthesis of distinctive characteristics, consolidating architectural traits, operational strengths, and the datasets and benchmarks that support their development; (3) identification of promising directions, including memory mechanisms, 4D perception, efficient adaptation, multi-agent cooperation, and other emerging capabilities. This survey consolidates recent advances to resolve inconsistencies in existing taxonomies, mitigate research fragmentation, and fill a critical gap through the systematic integration of studies at the intersection of large VLMs and robotic manipulation. We provide a regularly updated project page to document ongoing progress: https://github.com/JiuTian-VL/Large-VLM-based-VLA-for-Robotic-Manipulation.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.