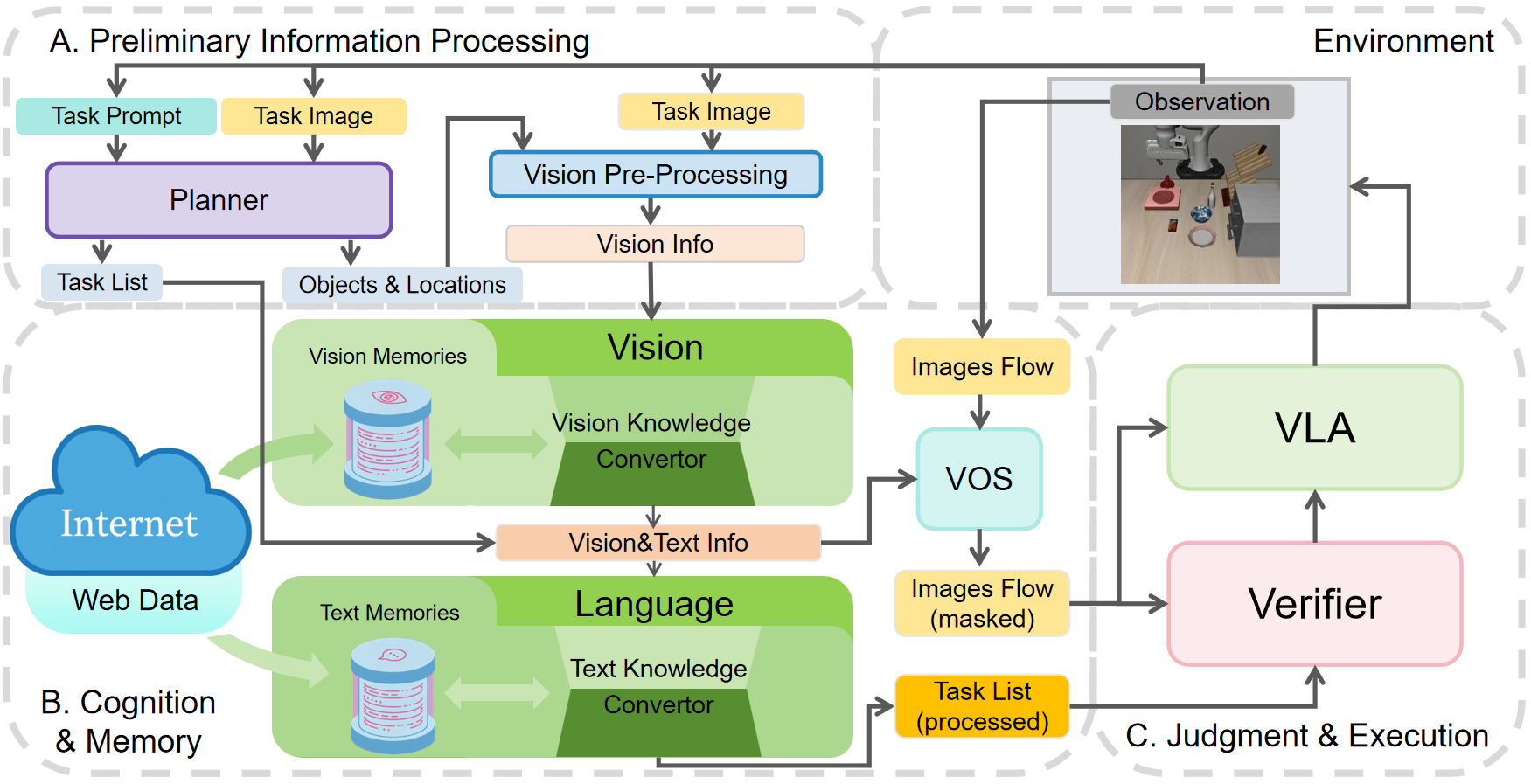
- The paper presents VLA², a modular agentic framework that significantly improves VLA model success on out-of-distribution tasks by integrating external knowledge and structured memory.
- The framework employs a three-stage pipeline—preliminary processing, cognition and memory, and judgment and execution—to decompose tasks and enrich representations.
- Experimental results show substantial gains, with up to 44.2% improvement over baselines on hard benchmarks and effective zero-shot adaptation to novel object concepts.
VLA²: An Agentic Framework for Vision-Language-Action Models in Unseen Concept Manipulation
Introduction and Motivation
The paper introduces VLA², a modular agentic framework designed to enhance the generalization capabilities of Vision-Language-Action (VLA) models in robotic manipulation, particularly for out-of-distribution (OOD) object concepts and instructions. While VLA models such as OpenVLA and RT-2 have demonstrated strong performance on in-domain tasks, their success rates degrade sharply when confronted with novel object appearances or language descriptions not present in the training data. VLA² addresses this limitation by integrating external knowledge sources (web retrieval, object detection) and structured memory into the VLA execution pipeline, enabling rapid adaptation to unseen concepts without retraining the core model.
System Architecture
VLA² is architected as a three-stage pipeline: Preliminary Information Processing, Cognition and Memory, and Judgment and Execution.
Vision and Language Processing
The vision module overlays transparent masks on detected objects and locations, reducing overfitting to surface textures and enabling compositional generalization. When detection fails, web search and GLM attribute extraction are invoked, and the resulting memory is persisted for subsequent tasks.
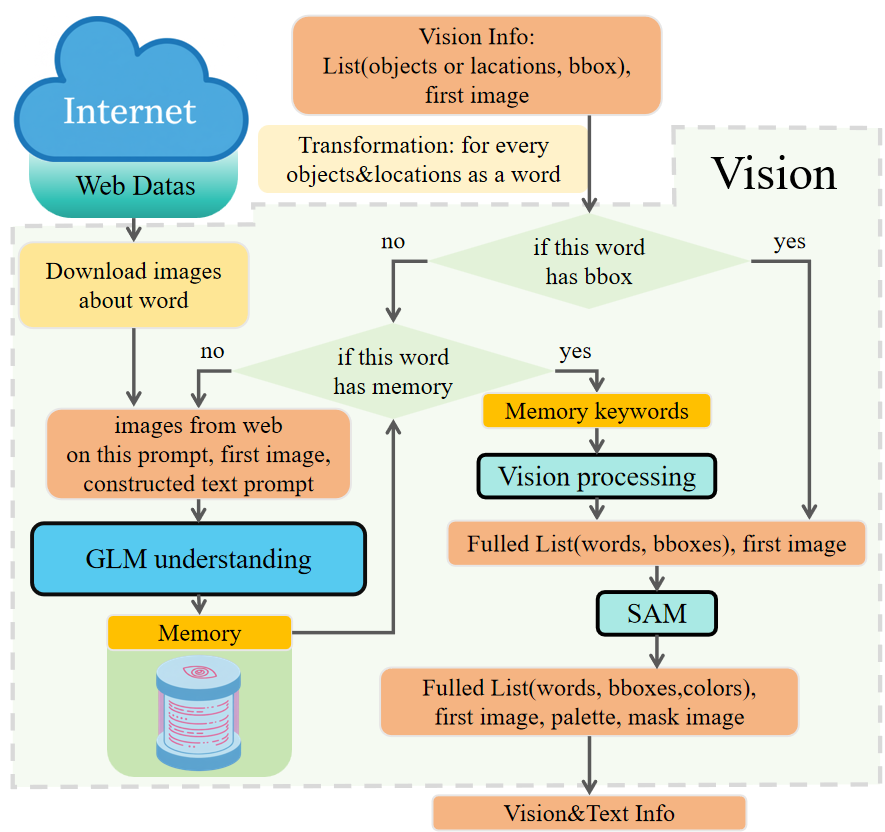
Figure 2: Vision framework. This figure illustrates the whole structure and contents within Vision.
The language module enforces lexical normalization, replacing OOD tokens with in-distribution equivalents using evidence from visual crops, web collages, and external snippets. This process is critical for bridging semantic gaps in task instructions and ensuring consistent system-level cognition.
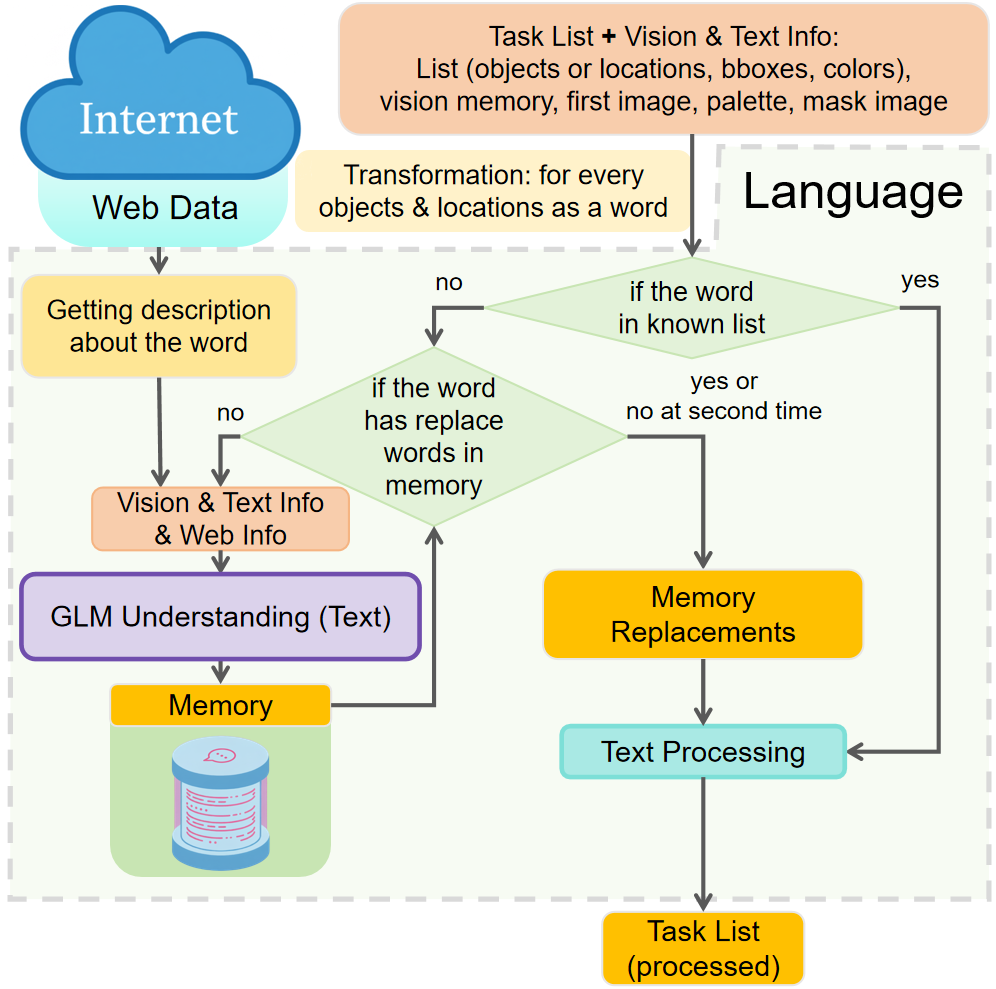
Figure 3: Language framework. This figure illustrates the whole structure and contents within Language.
The transformation pipeline systematically converts external information (images, text, web data) into knowledge representations accessible to the VLA. This process includes task decomposition, object detection, web-based attribute extraction, mask generation, and controlled vocabulary alignment.
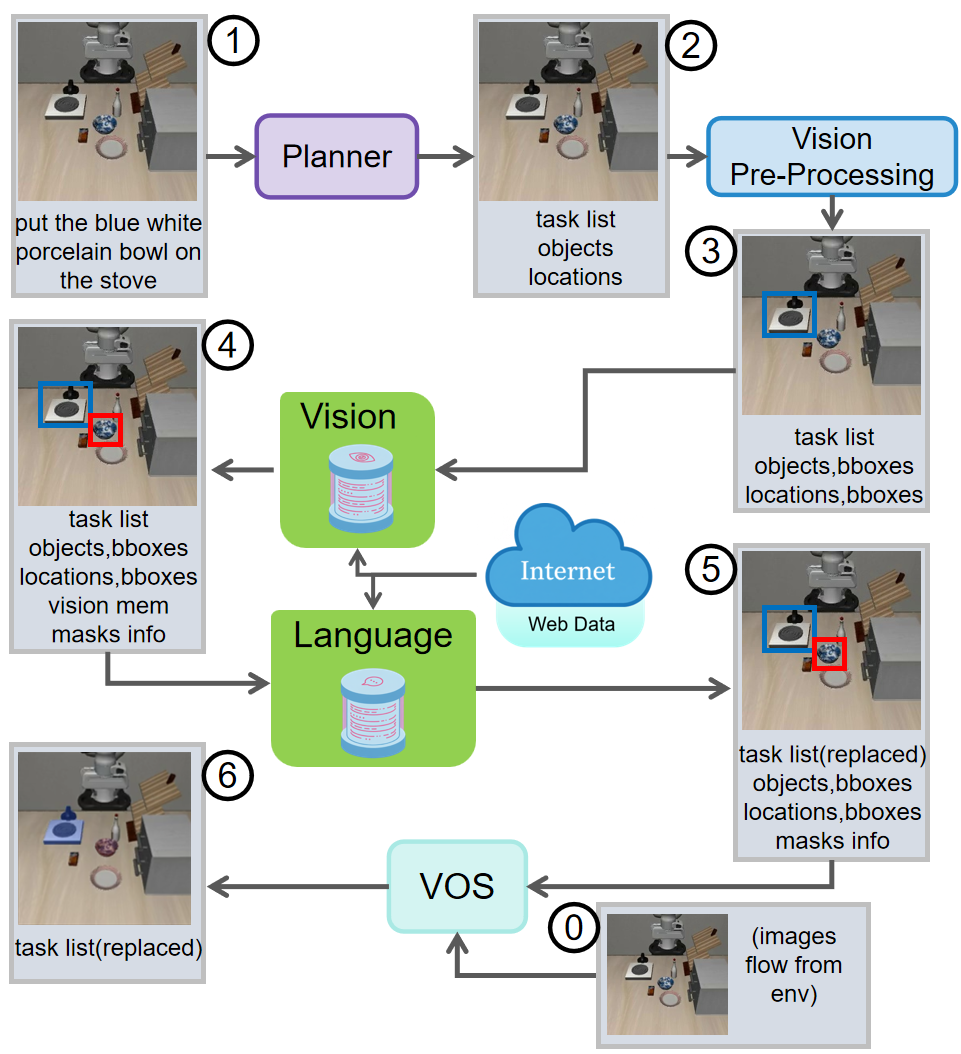
Figure 4: Transformation pipeline. This figure demonstrates how external information is progressively converted into knowledge available to the VLA via the system described in the main text.
Detailed examples illustrate the processing of previously unseen objects (e.g., "blue white porcelain bowl"), showing how vision and language memory modules enable the system to recognize and manipulate novel items.
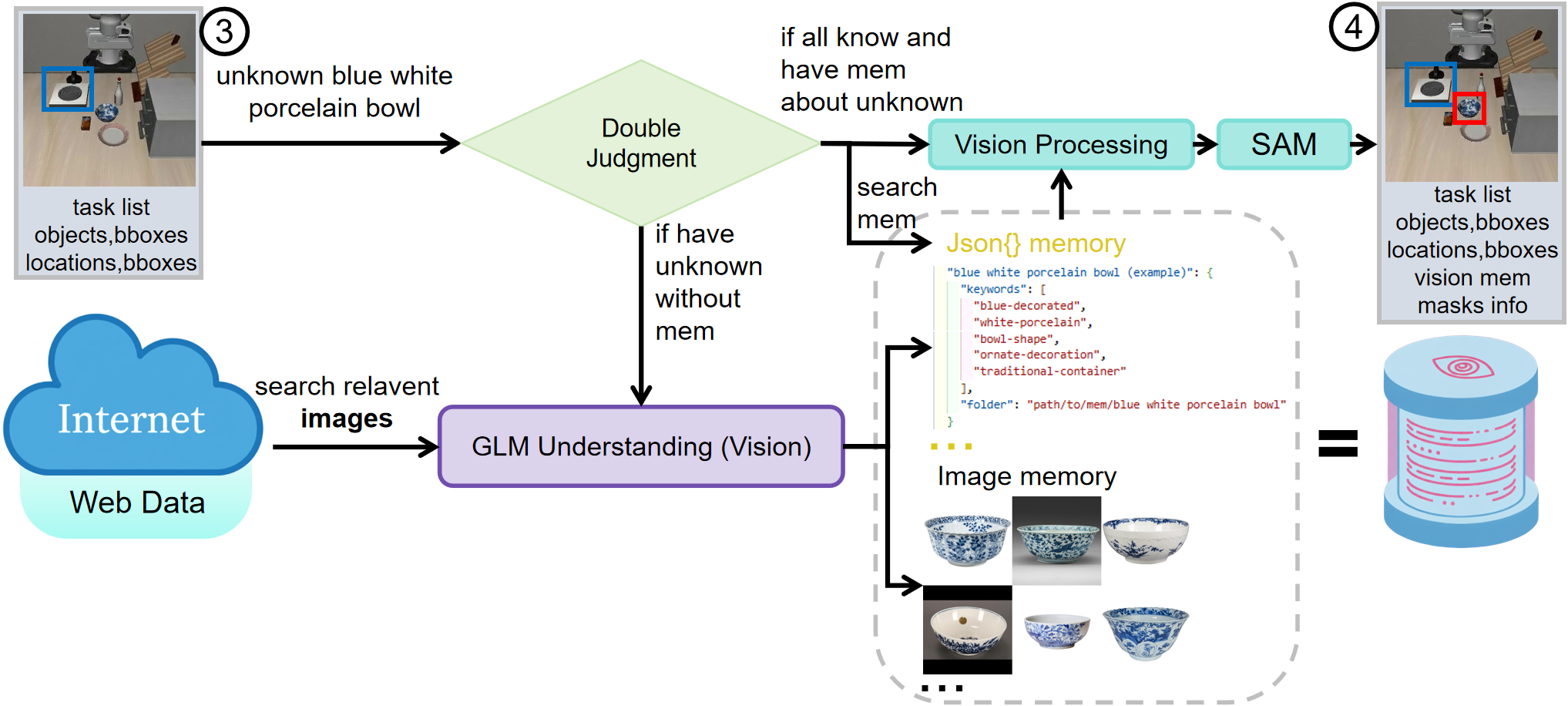
Figure 5: Vision processing for unknown blue white porcelain bowl. The system generated the keywords and stored the images here automatically during evaluation.
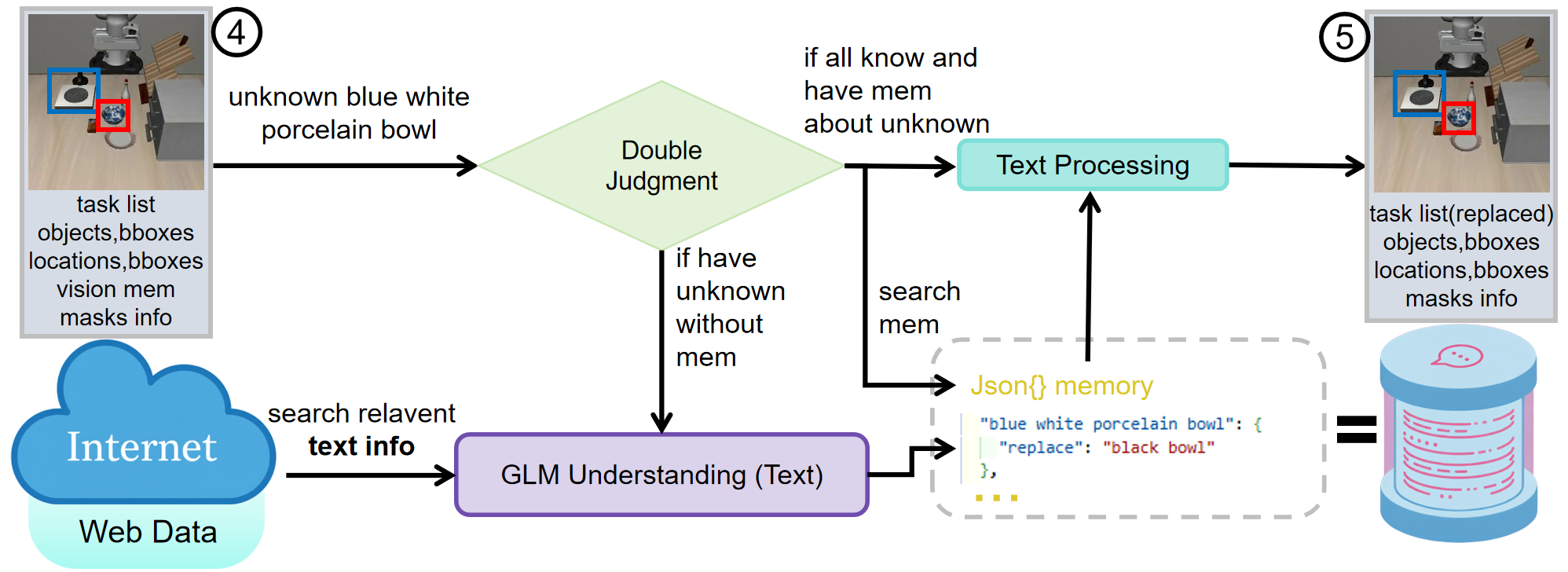
Figure 6: Language processing for unknown blue white porcelain bowl. The equals sign and the gray dotted box denote the same meaning of reference as in Figure 5.
Experimental Evaluation
Benchmark Design
A new evaluation benchmark was constructed on the LIBERO simulation environment, introducing Easy, Medium, and Hard variants with progressively more challenging OOD modifications (color changes, semantic reinterpretations, novel object categories). The framework was compared against state-of-the-art VLA baselines (OpenVLA, OpenVLA-OFT, π0, Agentic Robot) across both in-domain and OOD tasks.

Figure 7: Comparison between origin and new environments. A single rendered scene highlights the modified objects; novel items in other scenes share the same appearance.
Main Results
VLA² achieves the highest average success rate (SR) in the OpenVLA family on in-domain tasks (80.1%), and demonstrates substantial gains on OOD benchmarks, with a 44.2% improvement over OpenVLA in the Hard environment and a 20.2% average improvement across all custom environments. On the most challenging tasks (e.g., semantic shifts, compositional generalization), VLA² outperforms all baselines, including those with more advanced backbones.
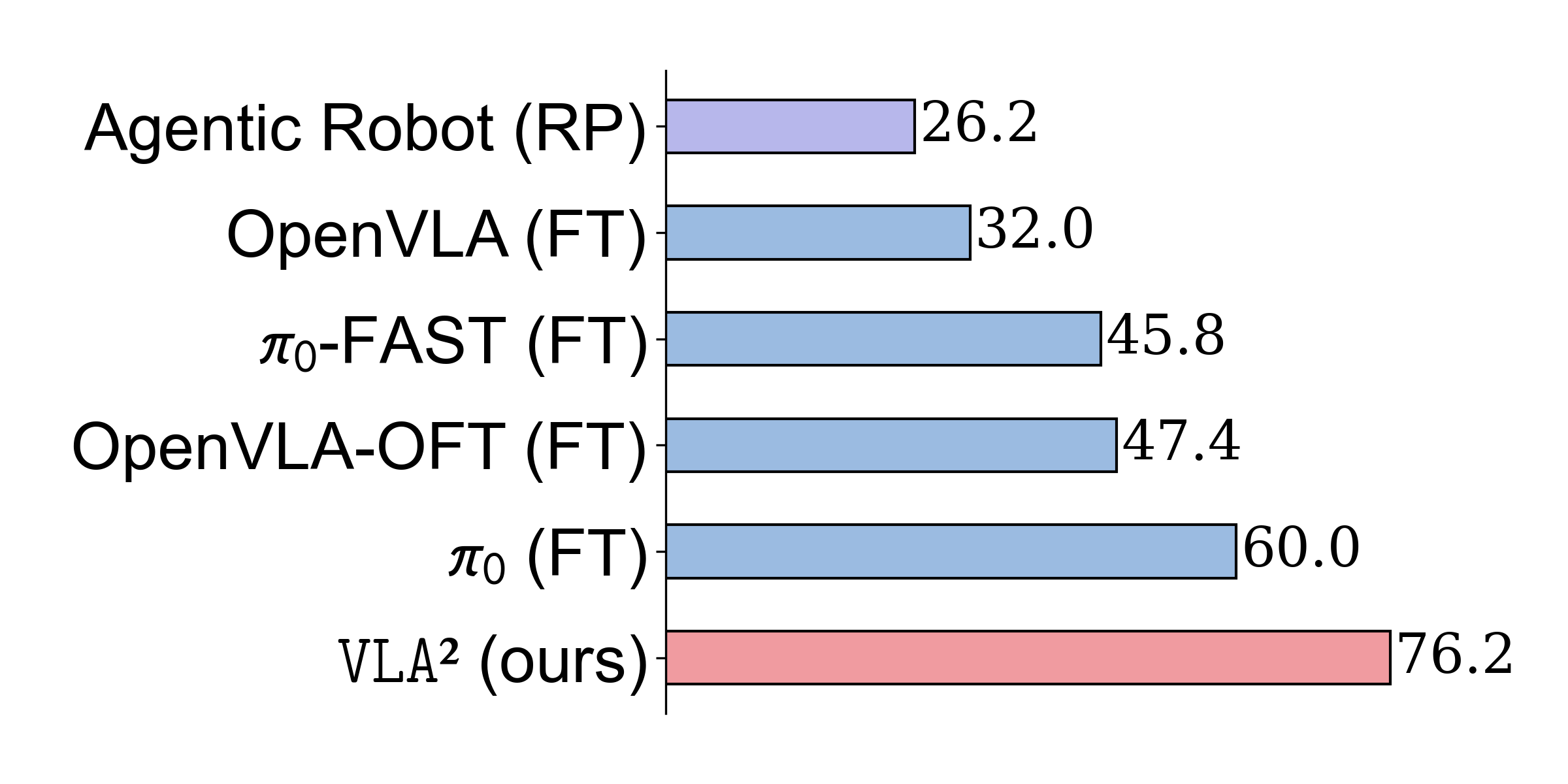
Figure 8: Evaluation result on our custom Hard-level benchmark. VLA² surpasses other state-of-the-art models finetuned on the original LIBERO dataset in unseen concept evaluation.
Ablation Studies
Ablations reveal the critical contributions of each module:
- Mask overlays: Removing masks reduces SR by 11.4 points, with the largest drops in cluttered or occluded scenes.
- Lexical replacement: Disabling semantic substitution yields a 25-point SR degradation, with catastrophic failures on tasks requiring grounding of novel nouns.
- Web retrieval: Omitting web search and memory lowers SR by 11 points, disproportionately affecting novel-brand targets.
- All modules removed: Adopting the Agentic Robot pipeline without VLA² enhancements collapses SR to 26.2, with many hard tasks failing entirely.
Computational Efficiency
Module-level runtime analysis shows that the additional overhead incurred by vision preprocessing, language normalization, and mask generation is modest (∼10 seconds per task), with the majority of computation time spent in VLA execution and planning. The memory-first design enables rapid reuse and minimizes latency in repeated invocations.
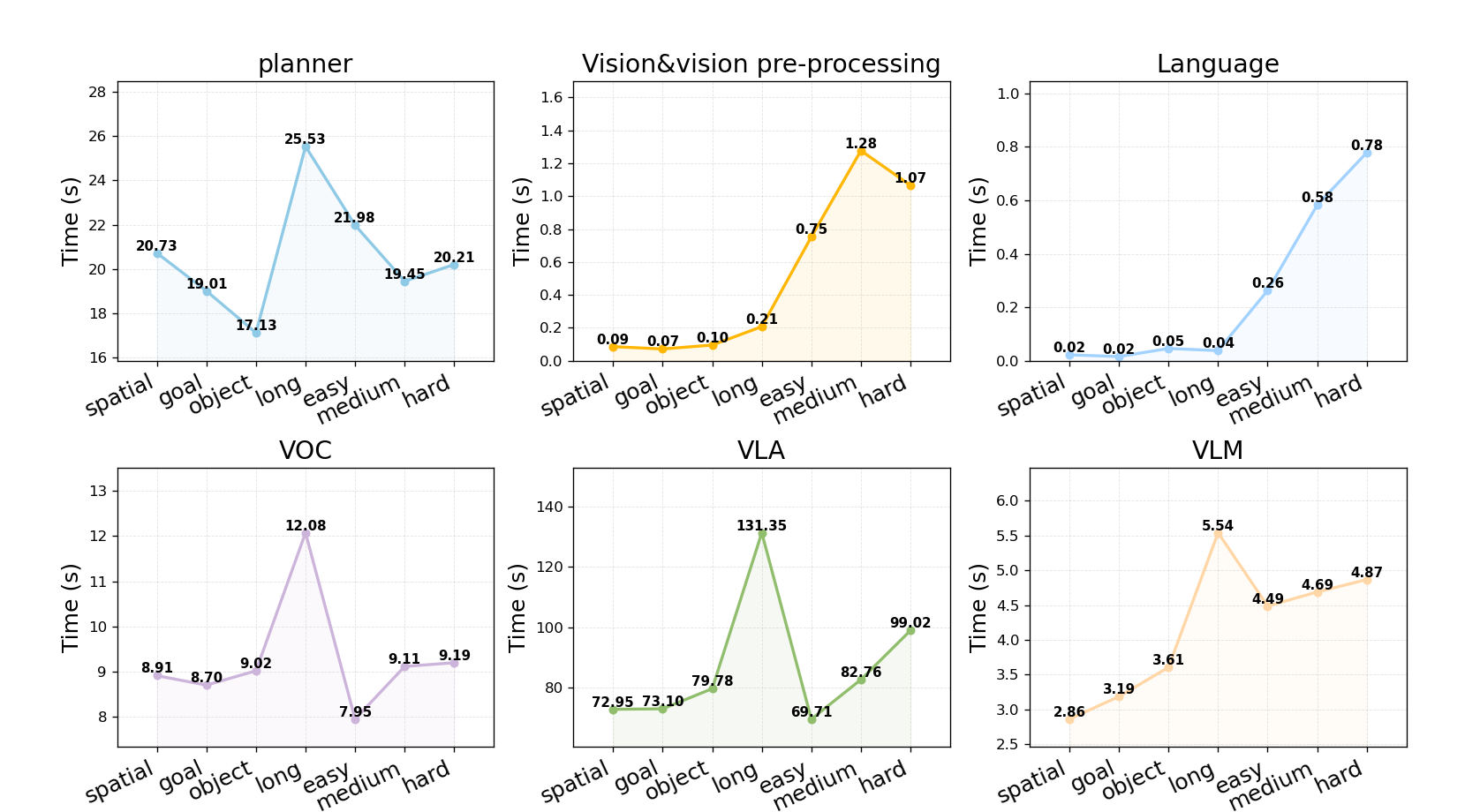
Figure 9: Modules runtime across tasks. Average computation time of each module in the agent framework for each task.
Implications and Future Directions
VLA² demonstrates that agentic frameworks integrating external knowledge sources and structured memory can substantially improve the OOD generalization of VLA models in robotic manipulation. The explicit transformation of unfamiliar inputs into in-distribution representations enables robust zero-shot adaptation without retraining or large-scale joint data collection. The approach is modular and extensible, suggesting potential for further integration of additional tools (e.g., real-time web APIs, advanced semantic parsers) and for deployment in real-world open-world environments.
Theoretical implications include the validation of instant learning and memory reuse mechanisms for rapid concept assimilation, as well as the importance of fine-grained vision-language alignment (color masks, token-level normalization) in embodied agent systems. The results challenge the notion that scaling backbone models alone suffices for generalization, highlighting the necessity of system-level augmentation.
Conclusion
VLA² presents a comprehensive agentic framework that empowers VLA models to manipulate objects with unseen concepts by leveraging external knowledge, structured memory, and modular processing pipelines. The system achieves state-of-the-art OOD generalization on challenging benchmarks, with strong empirical evidence for the efficacy of mask overlays, lexical normalization, and web-based retrieval. While the framework is currently limited to simulation, its modularity and efficiency position it as a promising foundation for future real-world embodied AI systems. Further research should explore increased autonomy, broader tool invocation, and real-world deployment to fully realize the potential of agentic VLA architectures.