- The paper introduces a novel instruction-driven routing and sparsification framework to align vision, language, and action for efficient embodied AI deployment.
- It leverages a 3-stage progressive design with EFA-Routing, LFP-Routing, and CAtten modules to compress visual tokens and prune irrelevant features.
- Experimental results demonstrate a 97.4% simulation success rate and 2.79× faster inference, underscoring significant performance and efficiency improvements.
CogVLA: Cognition-Aligned Vision-Language-Action Model via Instruction-Driven Routing & Sparsification
Motivation and Problem Statement
Vision-Language-Action (VLA) models have become central to embodied AI, enabling agents to interpret natural language instructions, perceive complex scenes, and execute manipulation tasks. However, the high-dimensional multimodal representations produced by large pre-trained Vision-LLMs (VLMs) pose significant computational challenges for end-to-end action generation. Existing sparsification strategies—such as Mixture-of-Depths, layer skipping, and early exit—primarily optimize intra-LLM computation and neglect semantic coupling across perception, language, and action modalities. This leads to semantic degradation, loss of task-relevant features, and inefficient action generation.
CogVLA addresses these limitations by introducing a cognition-aligned, instruction-driven routing and sparsification framework. Drawing inspiration from human multimodal coordination, CogVLA establishes a unified optimization mechanism across vision, language, and action, reinforcing cross-modal coherence while improving computational efficiency.
Figure 1: Overview of CogVLA, highlighting the inefficiencies of traditional VLA models and the instruction-driven sparsification and routing mechanisms introduced by CogVLA.
Architecture: 3-Stage Progressive Design
CogVLA’s architecture emulates human cognitive pathways for manipulation, mapping its modules to the Visual Attention System (VAS), Supplementary Motor Area (SMA), and Premotor Cortex (PMC):
- Encoder-FiLM based Aggregation Routing (EFA-Routing):
- Injects instruction information into vision encoders (SigLIP, DINOv2) via FiLM modulation.
- Aggregates and compresses visual tokens to 25% of the original input scale, guided by task-specific instructions.
- Cross-encoder aggregation dynamically fuses features based on instruction semantics, producing a dual-aggregation token.
- LLM-FiLM based Pruning Routing (LFP-Routing):
- Prunes instruction-irrelevant visual tokens within the LLM using instruction-conditioned scaling and shifting.
- Employs a task-guided pruning router, retaining only tokens with high instruction relevance, achieving ~50% token pruning rate.
- Implements a shifted cosine schedule for layer-wise sparsity control.
- V-L-A Coupled Attention (CAtten):
- Integrates compressed multimodal representations for action decoding.
- Applies causal attention over vision-language tokens and bidirectional attention within action chunks, enabling parallel decoding.
- Enforces hierarchical token dependencies via a unified hybrid attention mask, ensuring logical consistency and temporal coherence.
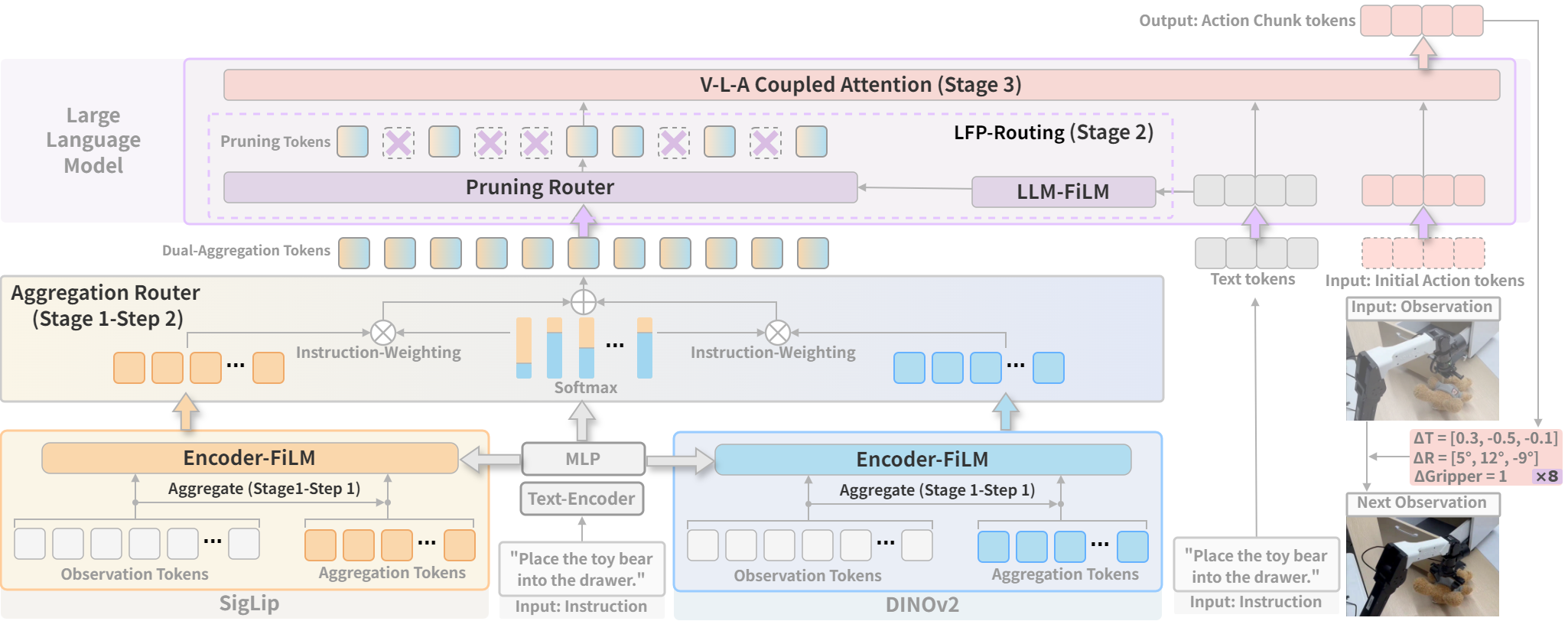
Figure 2: CogVLA framework, illustrating the instruction-driven routing and sparsification strategy for efficient action chunk prediction and cross-modal alignment.
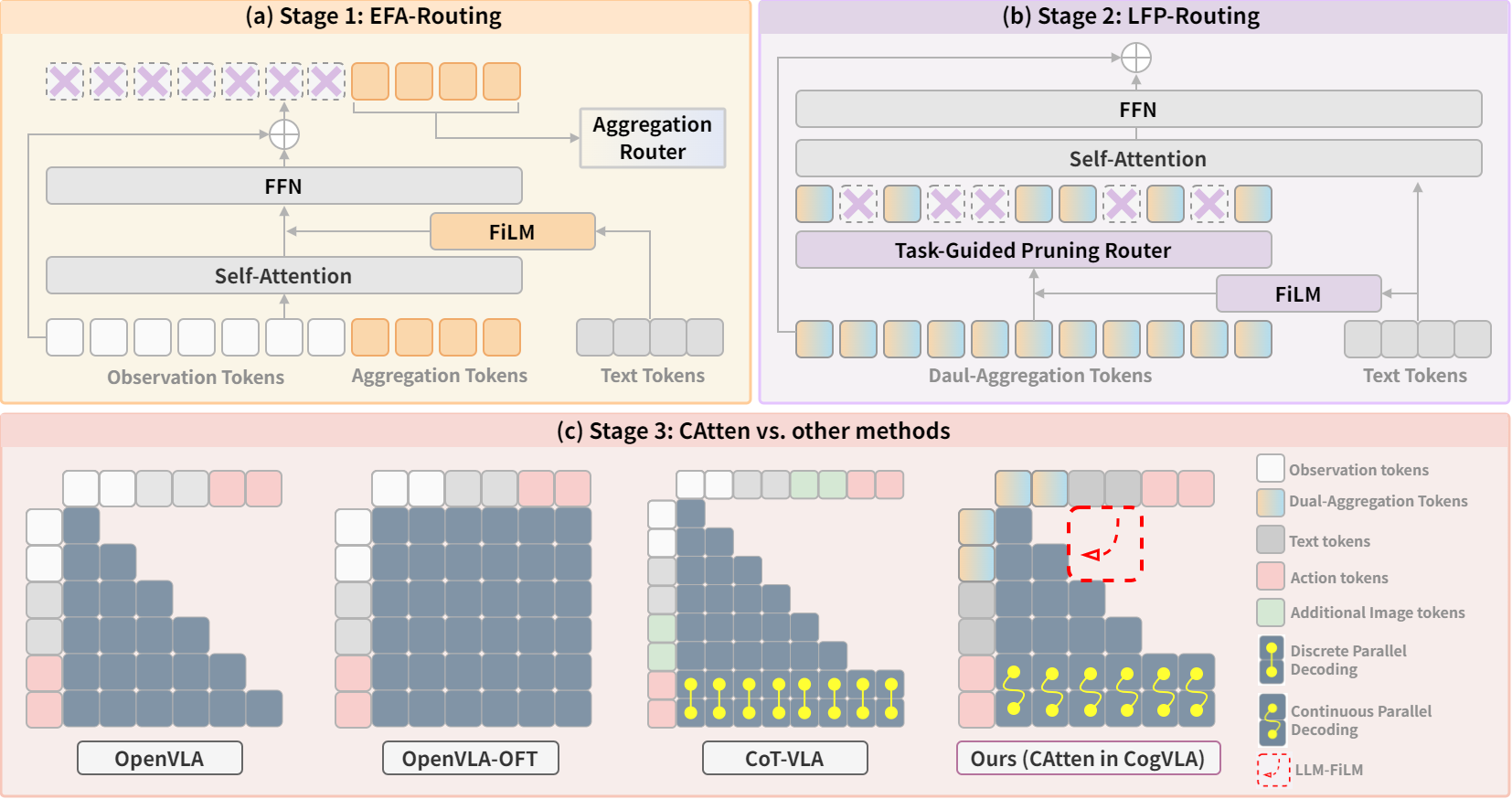
Figure 3: 3-stage progressive design, mapping EFA-Routing, LFP-Routing, and CAtten to VAS, SMA, and PMC, respectively, and highlighting the advantages of CAtten in parallel decoding and action intent injection.
Implementation Details
Two branches (SigLIP, DINOv2) each use 64 aggregation tokens. FiLM parameters are derived from linear transformations of instruction embeddings.
Cross-encoder fusion weights are predicted via a two-layer MLP conditioned on instruction embeddings.
Token retention ratio βl is scheduled per layer using a shifted cosine decay, clamped to [0.05,0.85].
Scaling and shifting functions are implemented as two-layer MLPs (hidden dim 2048).
Parallel decoding is enabled by bidirectional attention within action chunks, reducing inference latency.
Experimental Results
Simulation (LIBERO Benchmark)
CogVLA achieves a 97.4% average success rate across four task suites (Spatial, Object, Goal, Long), outperforming all baselines. Notably, it ranks second only in the Goal suite, attributed to an explicit trade-off between performance and efficiency—CogVLA reduces visual input by 8× compared to other VLA models.
Real-World Robotic Manipulation
On the Cobot Agilex ALOHA platform, CogVLA attains a 70.0% overall success rate across complex long-horizon tasks (Object Placement, Drawer Manipulation, T-shirt Folding), surpassing prior state-of-the-art models.
Efficiency
CogVLA demonstrates 2.79× faster inference, 22.54× higher throughput, 3.12× lower FLOPs, and 2.49× reduction in training cost compared to OpenVLA. Ablation studies confirm the synergistic contributions of EFA-Routing and LFP-Routing to efficiency and performance.
(Figure 4)
Figure 4: Visualization comparison between CogVLA and OpenVLA-OFT, showing superior success rates and efficiency gains in both simulation and real-world tasks.
Ablation and Analysis
Removing either EFA-Routing or LFP-Routing degrades performance and increases computational cost, validating the necessity of both stages.
- Sparsification Ratio Allocation:
Asymmetric allocation (e.g., 4× in Stage 1, 2× in Stage 2) yields optimal trade-offs, with early-stage compression followed by fine-grained pruning.
- Qualitative Visualizations:
Attention maps confirm that instruction-driven routing focuses perception on semantically relevant regions, supporting robust visual grounding.
Theoretical and Practical Implications
CogVLA’s biomimetic design demonstrates that cognition-aligned, instruction-driven sparsification can jointly optimize efficiency and cross-modal semantic alignment in VLA models. The framework’s modularity enables scalable deployment on resource-constrained platforms and facilitates generalization to diverse manipulation tasks. The parallel decoding enabled by CAtten further reduces inference latency, supporting real-time applications.
Limitations and Future Directions
Current sparsity schedules are fixed; future work should explore dynamic, instruction-conditioned sparsification.
Robustness to out-of-distribution instructions and unseen manipulation categories requires further evaluation.
Integrating haptic or force sensing could enhance performance in fine-grained manipulation.
Conclusion
CogVLA introduces a cognition-aligned, instruction-driven framework for Vision-Language-Action modeling, achieving state-of-the-art performance and efficiency through progressive routing and sparsification. Its biologically inspired architecture offers a pathway for scalable, interpretable, and robust embodied AI systems, with broad implications for assistive robotics, household automation, and industrial applications. Future research should focus on adaptive sparsification, lifelong learning, and multimodal integration to further advance the capabilities of VLA models.

