- The paper introduces a dual refinement approach that refines both task specifications and trajectory data, significantly improving data quality without human annotation.
- The methodology leverages categorized exploration and post-hoc trajectory refinement to achieve high task diversity and efficient execution.
- The paper demonstrates robust benchmark performance and cost-effective fine-tuning of web agents, ensuring reliable adaptation to unseen online environments.
Adapting Web Agents with Synthetic Supervision: Dual Refinement for Robust Environmental Transfer
Overview and Motivation
The challenge of rapid and robust adaptation for web-interactive agents is of particular importance as real-world deployments confront novel websites with scarce environment-specific demonstrations. The paper "Adapting Web Agents with Synthetic Supervision" (2511.06101) introduces a fully synthetic, LLM-driven framework that addresses these challenges by refining both task specifications and trajectory data during the data generation process. This dual refinement approach directly targets and mitigates quality degradation sources—hallucinations in LLM-generated tasks and noise/misalignment in control trajectories—without reliance on test-set leakage or human-labeled targets.
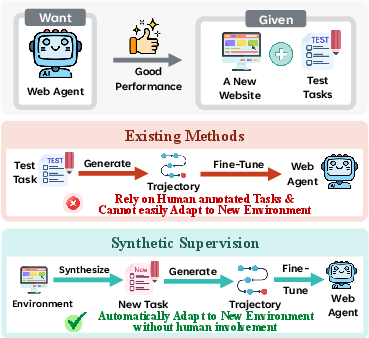
Figure 1: The dual refinement framework adapts an agent to a new web environment via synthetic data, in contrast to baselines that may leverage test set tasks or suffer from data quality issues.
Dual-Refinement Framework: Methodology
The pipeline consists of four sequential stages designed to enforce environment grounding, coverage, and high-quality learning signals:
- Task Synthesis with Categorized Exploration:
The environment is systematically explored by categorizing UI elements according to their functional intent (e.g., search, navigation, account management). Sampling actions within each category yields diverse state transitions, each prompting the LLM to synthesize high-level tasks grounded in specific, observed context.
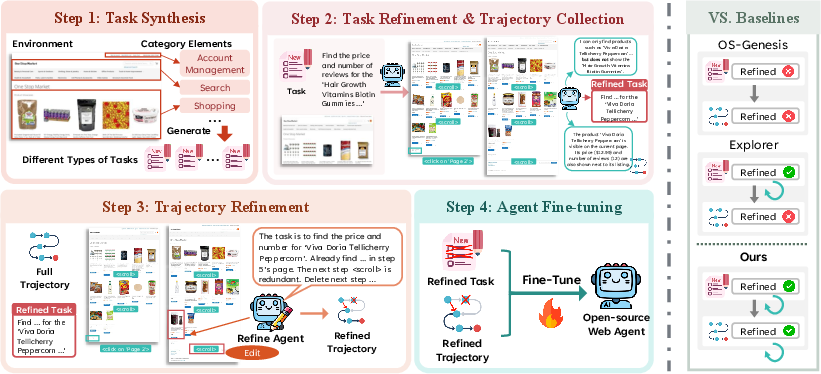
Figure 2: Dual-refinement pipeline versus baseline methods; distinctive is the iterative categorization and staged refinements that yield high-quality, domain-appropriate data.
- Task Refinement during Trajectory Collection:
Task specifications are monitored during agent execution. Lightweight predicates—existence, parameter specification, and stalled progress—trigger refinement when task feasibility is contradicted by live observations. The LLM then concretizes, aligns, or downsizes task objectives, ensuring that the specification always reflects reachable, non-hallucinated goals (see example in Figure 3).
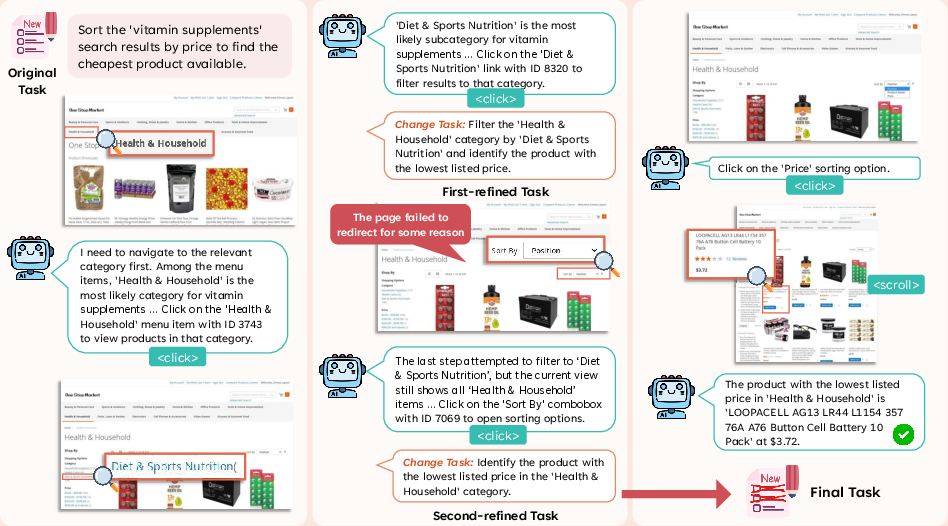
Figure 3: During execution, when a task is found to be infeasible or hallucinated, the specification is refined to align with real context.
- Post-hoc Trajectory Refinement:
Completed (or interrupted) interaction sequences are further optimized by a retrospection phase. The LLM, with global context, removes irrelevant or redundant actions, reorders commutable steps, or discards irreparable traces entirely. This ensures all supervision pairs are minimal, executable, and maximally aligned with the terminal task specification.
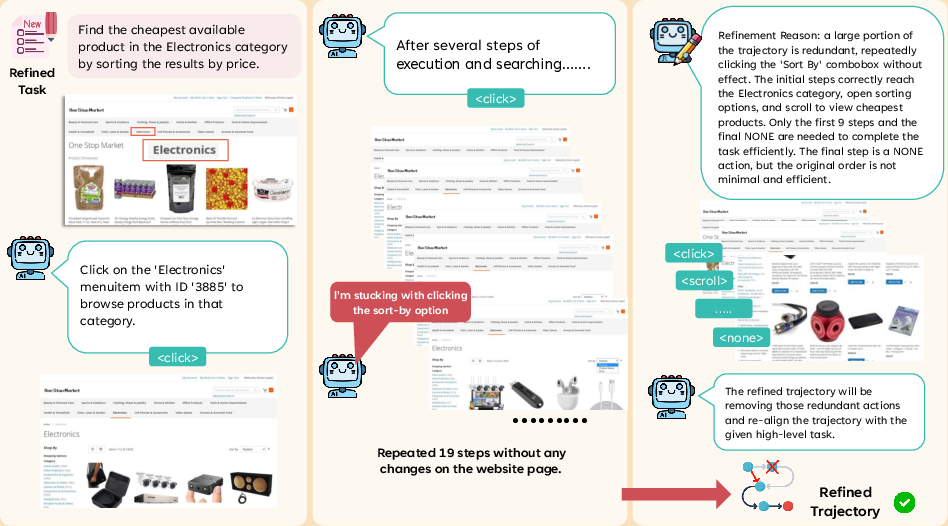
Figure 4: Example of trajectory refinement—removal/reordering of steps ensures that the final action sequence is efficient, consistent with the goal, and free from spurious loops or redundancies.
- Fine-tuning Open-Source Web Agents: The refined set of (task,trajectory) pairs is then used to fine-tune open-source multimodal LLM agents. Training is standard SFT over these pairs, using a fixed history window.
Analysis of Synthetic Data Quality and Diversity
Empirical evaluation demonstrates that the quality and diversity of synthesized data is critical for successful adaptation:
t-SNE visualizations and diversity scoring (Figure 5) show that categorization-based exploration achieves higher coverage, with sampled synthetic tasks distributed comparably to human-authored test sets.
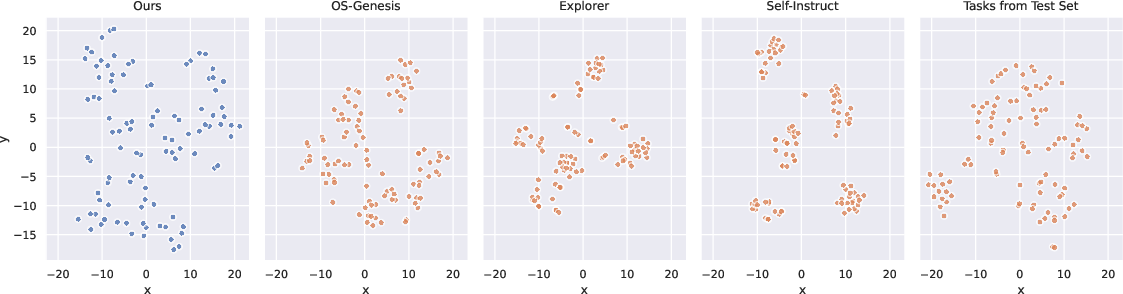
Figure 5: t-SNE scatter plots indicate that the dual-refinement regime generates a more even and diverse spread of tasks relative to baselines.
Refined data achieves high ratings in human/LLM judgment for both task plausibility and trajectory efficiency. Compared to prior baselines, trajectories have fewer redundant steps and higher alignment with goals, and the synthesized data contains fewer hallucinated or impossible tasks.
Empirical Results
- Performance on Standard Benchmarks:
Across five websites in the WebArena benchmark, the dual-refinement approach achieves substantially higher average task success rates than all synthetic-data baselines, often halving the gap to the (unrealistic) upper bound where agents are fine-tuned using test-set tasks.
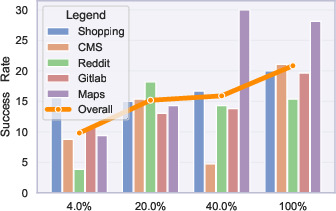
Figure 6: Performance gains on all web domains improve steadily with increasing synthetic data, demonstrating scaling robustness.
The dual-refinement method is more sample-efficient: agents require fewer synthetic interactions and LLM calls to reach performance parity, resulting in substantial API cost savings.
Removing either task or trajectory refinement produces marked declines in outcome, confirming both stages are necessary. Notably, trajectory refinement is shown to "unlock" the gains obtained by task refinement—without the post-hoc cleanup step, history noise would mask the benefit of more specific tasks.
Case Studies: Interpretability and Correction Dynamics
Detailed case studies (Figures 5 and 6) illustrate the real-time correction mechanics:
- Task Refinement resolves hypothetical misalignments (e.g., attempted interaction with nonexistent elements after category navigation failure) by dynamically updating the high-level goal.
- Trajectory Refinement excises or reorders sub-optimal or repeated action loops (e.g., repeated ineffective sort attempts), enforcing coherence and improving generalization.
Practical and Theoretical Implications
The pipeline is fully automated; no test set leakage or external demonstrations are required, making the approach extensible to arbitrary unseen websites in-the-wild.
- Model-Agnostic and Modular:
The methodology applies to any LLM-based or multimodal agent design (demonstrated with Qwen2.5-VL and UI-TARS), underscoring its generality.
- Implications for Agentic RL:
The paradigm—supervision via dual-refined, environment-specific synthetic data—addresses long-standing concerns regarding data scarcity, overfitting to test distributions, and brittleness to environment shifts.
Limitations and Future Directions
- LLM Dependency and Error Propagation:
While the dual LLMs reduce hallucination, real-world scaling may expose rare error propagation where both refinement levels fail. More robust fail-safes or uncertainty quantification could be explored.
The need for coverage via category exploration may incur significant overhead for extremely large or non-standard sites. Future work on efficient, structure-aware exploration should be valuable.
- Multi-agent and Continual Adaptation:
Integrating this framework with continual learning and multi-agent collaboration paradigms may further improve adaptation and robustness in evolving online environments.
Conclusion
This work establishes a rigorous, scalable methodology for adapting web-interactive agents to unseen sites, purely via synthetic supervision augmented by task and trajectory refinement. The empirical evidence and in-depth analyses demonstrate that properly structured and cleaned synthetic data closes much of the adaptation gap, and sets a baseline for future research in both practical deployment of web agents and theoretical advances in autonomous dataset synthesis for agent learning.