Visual Spatial Tuning
Abstract: Capturing spatial relationships from visual inputs is a cornerstone of human-like general intelligence. Several previous studies have tried to enhance the spatial awareness of Vision-LLMs (VLMs) by adding extra expert encoders, which brings extra overhead and usually harms general capabilities. To enhance the spatial ability in general architectures, we introduce Visual Spatial Tuning (VST), a comprehensive framework to cultivate VLMs with human-like visuospatial abilities, from spatial perception to reasoning. We first attempt to enhance spatial perception in VLMs by constructing a large-scale dataset termed VST-P, which comprises 4.1 million samples spanning 19 skills across single views, multiple images, and videos. Then, we present VST-R, a curated dataset with 135K samples that instruct models to reason in space. In particular, we adopt a progressive training pipeline: supervised fine-tuning to build foundational spatial knowledge, followed by reinforcement learning to further improve spatial reasoning abilities. Without the side-effect to general capabilities, the proposed VST consistently achieves state-of-the-art results on several spatial benchmarks, including $34.8\%$ on MMSI-Bench and $61.2\%$ on VSIBench. It turns out that the Vision-Language-Action models can be significantly enhanced with the proposed spatial tuning paradigm, paving the way for more physically grounded AI.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching AI models to understand space better—like how objects are arranged in a room, how far they are, and how things relate across different views or over time. The authors call their approach Visual Spatial Tuning (VST). It helps Vision-LLMs (VLMs)—AIs that can look at images or videos and talk about them—develop human-like spatial skills, from simply noticing where things are to reasoning and planning based on those relationships.
What questions does the paper try to answer?
The paper asks:
- How can we help AI see and understand “where things are” (spatial perception) from images, multiple views, and videos?
- How can we help AI think through spatial problems (spatial reasoning), like figuring out where objects are in relation to each other, or reconstructing a scene from different camera angles?
- Can we do this without adding heavy, specialized 3D tools to the model, and without hurting the model’s general abilities on other tasks?
- Will better spatial understanding help AI agents act more effectively in the physical world (like robots following instructions)?
How did the researchers do it?
They built a training process and two big datasets to grow spatial skills step by step, similar to how people learn.
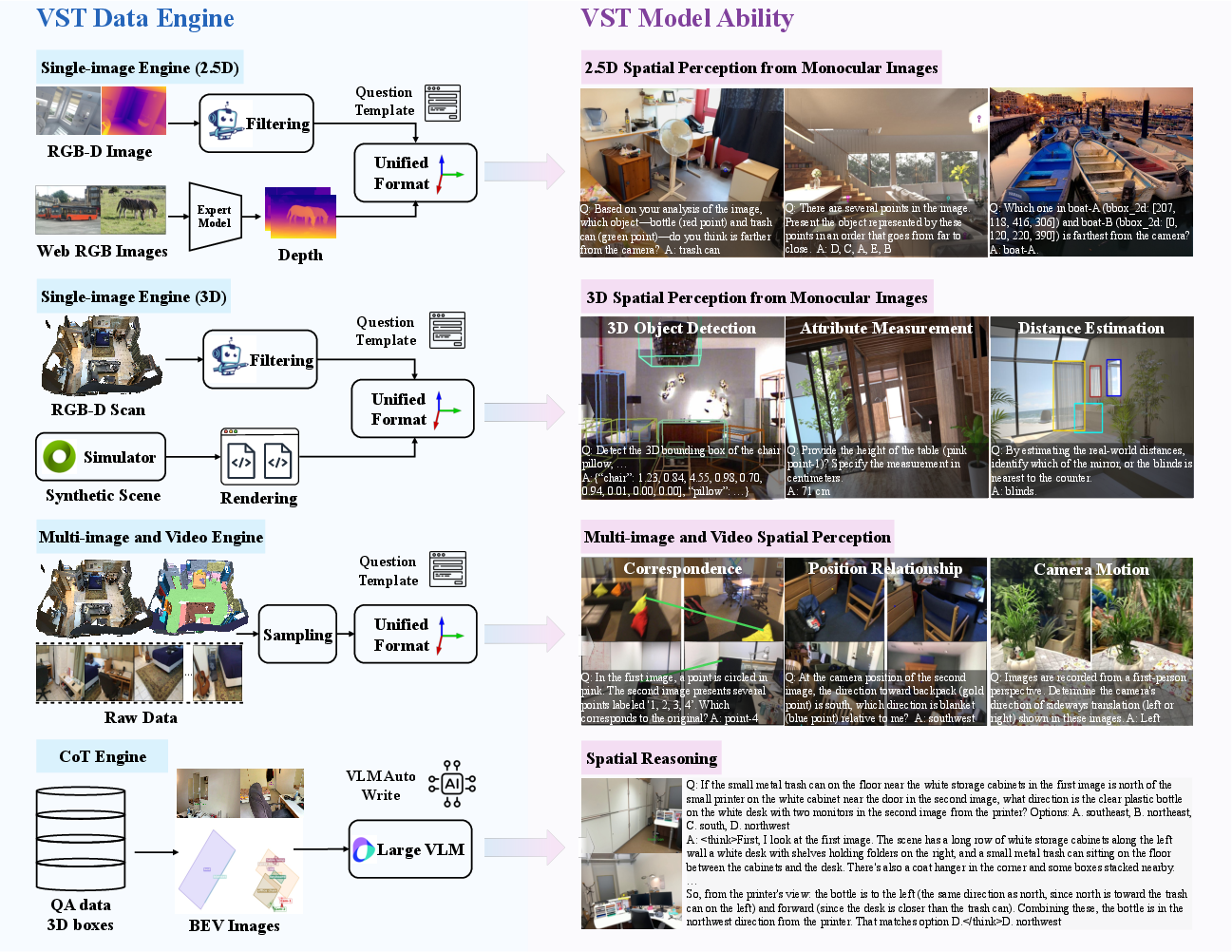
Building two datasets
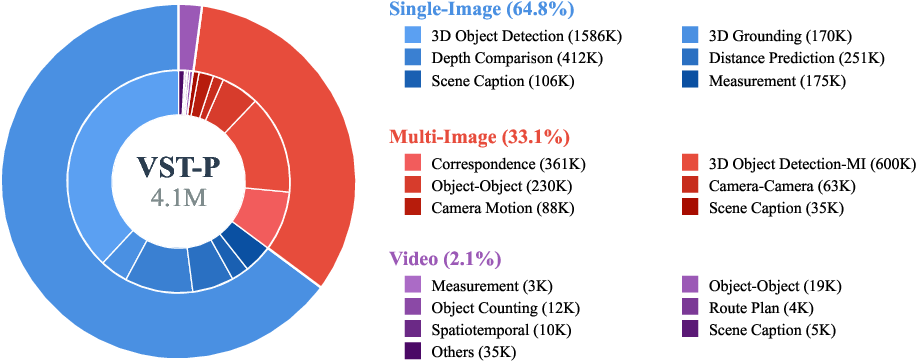
- VST-P (Perception): A huge set with about 4.1 million examples for learning “spatial perception.” It covers 19 skills using:
- Single images (most of the data): learning depth (how near or far things are), 3D object detection, and distance estimation.
- Multiple images of the same place from different angles: learning how views connect, matching points across images, and understanding camera motion.
- Videos: learning how things change and appear over time, like the order in which objects show up.
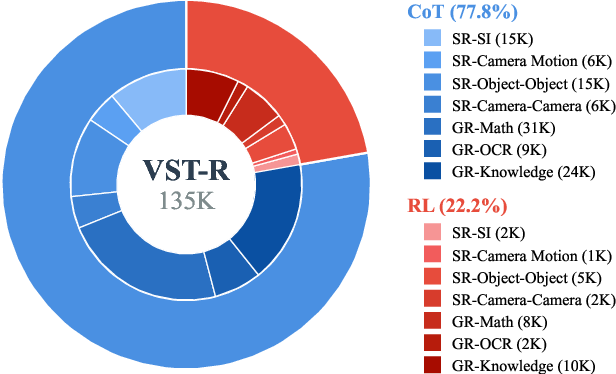
- VST-R (Reasoning): A smaller set with around 135,000 examples for “spatial reasoning.” It teaches the model to think step-by-step (called chain-of-thought, or CoT) and includes questions where answers can be checked by rules. Many samples are multi-view because reasoning across different angles is more challenging and useful.
Training in three steps
To make learning smooth and robust, the model trains progressively:
- Stage 1: Supervised fine-tuning (SFT)
- The model is shown lots of labeled examples (from VST-P) and learns to predict correct answers. It also sees some general, non-spatial tasks to avoid forgetting its other skills.
- Stage 2: CoT cold start
- The model practices explaining its thinking step-by-step on spatial reasoning tasks (from VST-R), plus some general reasoning tasks. This teaches it to write out the “mental map” and logic that lead to an answer.
- Stage 3: Reinforcement learning (RL)
- The model answers spatial questions multiple ways, gets scored by rules (like how accurate its 3D boxes are or whether the answer matches the correct format), and improves based on those scores. Think of it like practicing and getting feedback to get better.
Helpful tricks that made learning work better
- Field of View (FoV) unification: The model sees images from many different cameras. To avoid confusion, they “re-project” images so they look like they were taken with a standard lens. That makes geometry more consistent.
- Bird’s-Eye View (BEV) prompting: For multi-view scenes, they provide a top-down map (like a floor plan or a drone view). This makes relationships clearer and helps the model build a mental layout of the scene.
- Scene captions focused on layout: Instead of only describing what’s in an image, they add text that explains where things are and how they are arranged. This teaches the model to talk about space, not just objects.
- No special 3D encoders: They show you can reach strong spatial performance using a standard vision-language backbone, not extra heavy 3D modules.
Extending to action
They also turn the spatially trained model into a Vision-Language-Action (VLA) system. Given a picture and an instruction (“pick up the red block”), the model predicts a sequence of actions. Actions are discretized into tokens so the model can “say” the actions step by step, just like it answers questions.
What did they find?
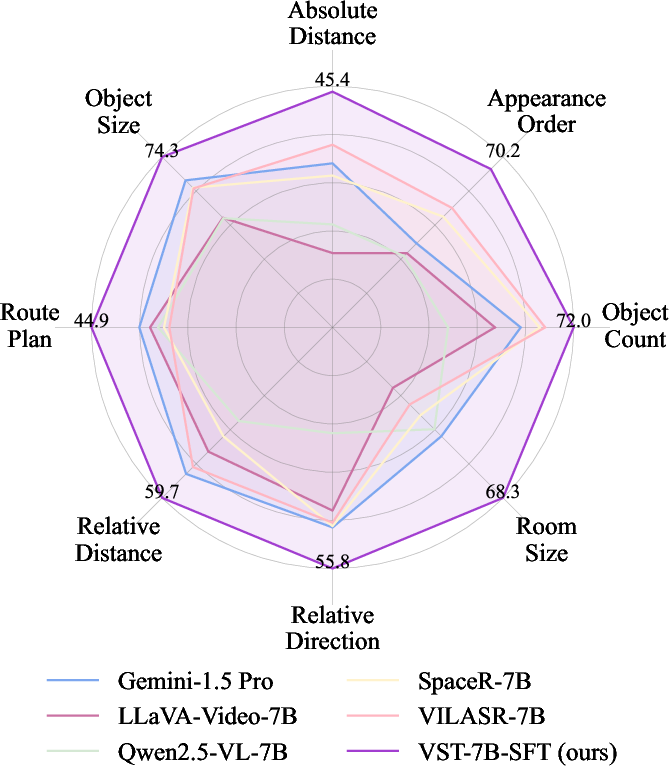
The trained models achieved state-of-the-art results on several spatial benchmarks, while keeping good general abilities:
- On MMSI-Bench (multi-image spatial reasoning), the model reached 34.8%.
- On VSIBench (video spatial understanding), it reached 61.2%.
- On CVBench (single-image spatial tasks), it scored up to 86.5%.
- It also performed strongly on 3D object detection (e.g., 44.2 AP@15 on SUN RGB-D), beating both general VLMs and some specialized 3D methods—without using extra 3D encoders.
- The improvements helped action tasks too: fine-tuning on VST boosted a robot learning benchmark (LIBERO) by 8.6%.
Why this matters:
- The model doesn’t just name objects; it knows where they are, how big they might be, and how they relate across views and time.
- It reasons about space step-by-step and can reconstruct scenes mentally, like building a map in its head.
- It shows that smart data and training can unlock 3D understanding in general-purpose models.
What’s the big impact?
Better spatial understanding opens doors for AI that can operate in the physical world:
- Robotics: More reliable manipulation and navigation because the AI grasps distances, layout, and relative positions.
- Autonomous driving: Stronger reasoning about scenes from many cameras.
- AR/VR: More accurate placement and interaction in virtual and mixed reality.
- Everyday AI assistants: Improved ability to help with tasks that involve space, like arranging furniture, packing, or planning routes.
Overall, Visual Spatial Tuning shows a practical path to teaching AI “where things are” and “how to think about space” using a standard architecture, smart datasets, and step-by-step training—bringing AI closer to human-like spatial intelligence.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, articulated so future researchers can act on them:
- Impact of FoV unification on geometry fidelity:
- No ablation quantifies how the virtual camera projection alters metric accuracy, object scale, or aspect ratios across datasets with diverse intrinsics.
- Unclear whether FoV normalization introduces distortions that degrade 2D tasks or multi-view consistency.
- Camera extrinsics availability and reliability:
- The pipeline assumes access to accurate camera poses; robustness to unknown, noisy, or miscalibrated extrinsics is not evaluated.
- No self-calibration or pose-estimation strategy is presented for in-the-wild multi-view inputs.
- Euler-angle representation for camera motion:
- Potential issues (e.g., gimbal lock, discontinuities) are not addressed; no comparison with quaternion or Lie group () representations.
- Privileged BEV prompting during CoT generation:
- Teacher CoT relies on ground-truth 3D boxes and BEV images that are unavailable at inference; the degree of “privileged information leakage” into training is not quantified.
- No study of CoT quality when BEV annotations are noisy, absent, or replaced by learned/estimated layouts.
- Layout reconstruction accuracy:
- The model is said to “reconstruct the spatial layout by text,” yet no metric or benchmark evaluates textual layout fidelity against ground truth (e.g., object positions, relations, topology).
- Depth and 3D labels quality and uncertainty:
- Heavy use of pseudo depth labels (Depth Anything v2) and heterogeneous 3D boxes from varied sources; no uncertainty-aware training, error modeling, or sensitivity analysis to label noise.
- No breakdown of performance degradation when synthetic vs. real depth/3D annotations are mixed or mismatched.
- Dataset domain coverage and bias:
- Training data is predominantly indoor (ScanNet, SUN RGB-D, Matterport3D, Hypersim, Objectron, ARKitScenes); generalization to outdoor, driving, aerial, or egocentric scenarios remains untested.
- No fine-grained analysis of category-level or scene-type performance or failure modes.
- Video understanding limitations:
- Video data is only 2.1% of VST-P; the paper shows gains on VSI-Bench, but does not analyze robustness to camera motion, occlusions, dynamic scenes, long temporal horizons, or multi-episode continuity.
- Multi-image scenario robustness:
- The pipeline assumes consistent multi-view geometry; impacts of partial views, heavy occlusion, non-overlapping fields of view, or scene symmetry (perceptual aliasing) are not explored.
- Reward design and RL stability:
- GRPO reward mixes accuracy and format; risks of reward hacking and over-optimization for formatting are not analyzed.
- IoU thresholding (e.g., 3D IoU>0.25) is somewhat permissive; no sensitivity study across stricter thresholds or alternative geometry rewards.
- Group size, sampling strategy, and stability/variance of RL training are not reported.
- Trade-offs with general multimodal capabilities:
- The claim of “without side-effect to general capabilities” is only partially supported; tables show some drops vs. proprietary baselines and mixed trends post-RL.
- No systematic analysis of catastrophic forgetting, transfer interference, or Pareto trade-offs between spatial and general tasks.
- Generalization across architectures:
- Results are reported on Qwen2.5-VL backbones; it is unclear how VST transfers to other VLM architectures (e.g., InternVL, LLaVA variants) or to encoders with different tokenization schemes.
- 3D detection evaluation completeness:
- SUN RGB-D results emphasize AP@15; full metrics (AP@25/AP@50, AR curves, category breakdowns) and statistical significance are not consistently reported.
- No calibration analysis of absolute scale accuracy or depth-range performance.
- Multi-turn training dynamics:
- The “reference previous box” training approach could induce exposure bias or error compounding; no study of context length, memory effects, or robustness to earlier mistakes.
- FoV unification vs. metric scale:
- Unclear how the virtual projection interacts with metric scale estimation when original intrinsics vary; no error profile for absolute distance estimates across intrinsics distributions.
- Scene captioning quality and biases:
- Captions are generated by prompting a large VLM with ground-truth 3D relations; risk of artifacts or stylistic biases is not examined.
- No comparison to captions derived from learned 3D perception (without GT) or to human-written spatial captions.
- Data contamination and benchmark integrity:
- The paper aggregates many public datasets; there is no detailed deduplication protocol or leakage audit to ensure benchmarks are free of overlap with training data.
- Robustness to sensor effects:
- Lens distortion, rolling shutter, motion blur, and HDR/low-light conditions are not studied; their impact on 3D inference and spatial reasoning remains unknown.
- Interpretability of learned spatial representations:
- No probing or diagnostics (e.g., depth maps, pointwise relative distance probes, internal attention maps) to verify if the model internalizes geometric structure vs. pattern memorization.
- Scaling laws and saturation:
- 3D detection appears to saturate at 7B; no principled analysis of why (data bottlenecks, label noise, objective mismatch) or whether targeted data/architectural changes would resume gains.
- Multi-view correspondence noise:
- No quantification of correspondence errors (RGB-D alignment, point matching) or their impact on downstream spatial tasks; no noise-robust training objectives.
- VLA adaptation and action quantization:
- Actions are discretized into 256 tokens; no sensitivity analysis for bin count, continuous outputs, or hybrid token-continuum approaches.
- Real-robot closed-loop evaluations are absent; only LIBERO improvements are reported, without sim-to-real studies or latency/safety analyses.
- Computational and efficiency considerations:
- Training/inference compute costs, throughput, and memory footprints are not reported; efficiency trade-offs of the progressive SFT+RL regimen are unclear.
- Safety, reliability, and failure analysis:
- No analysis of failure modes (e.g., mislocalized objects leading to incorrect actions) or mitigation strategies in physical settings (robotics, AR/VR).
- Extending beyond 3D boxes:
- The pipeline centers on 9-DoF boxes; potential gains from richer geometry (meshes, implicit fields, voxel grids) or physics priors (support, stability) are unexplored.
- Benchmark breadth and realism:
- Spatial reasoning is mainly evaluated on curated academic benchmarks; deployment-oriented tests (open-world scenes, clutter, partial observability, adversarial layouts) are missing.
- Mixing ratios and curriculum:
- The paper does not study the effect of data/task mixing ratios (across single/multi-image/video, captions vs. detection vs. depth) or curriculum schedules on final spatial performance.
- Long-horizon CoT reasoning:
- CoT improvements are reported, but the limits of long-form spatial reasoning (multi-step navigation, multi-room layout reconstruction, counterfactuals) are not evaluated.
Glossary
- 2.5D: An intermediate representation capturing depth cues from a single image without full 3D reconstruction. "relative depth estimation (2.5D)"
- 3D bounding box: A box in 3D space describing an object’s position, size, and orientation. "Specifically, the 3D bounding box is defined by "
- 3D grounding: Linking language references to specific 3D objects or regions in space. "3D grounding, attribute measurement, and distance estimation tasks."
- 3D inductive biases: Architectural or training assumptions that encourage models to capture 3D structure. "special encoder with 3D inductive biases"
- 3D Intersection over Union (IoU): Overlap metric between predicted and ground-truth 3D boxes. "the 3D Intersection over Union (IoU) score"
- 3D object detection: Identifying and localizing objects with 3D bounding boxes. "In the 3D object detection task, we predict the 9-DoF bounding box in the camera coordinate system."
- 9-DoF bounding box: A 3D box parameterized by center, size along axes, and rotation around three axes. "we predict the 9-DoF bounding box in the camera coordinate system."
- Action de-tokenizer: Component that converts predicted tokens back into low-level action commands. "through an action de-tokenizer."
- AdamW: An optimizer that decouples weight decay from gradient-based updates. "the AdamW~\cite{adamw} optimizer"
- AP@15: Average Precision measured at an IoU threshold of 0.15. "AP@15 on SUN RGB-D 3D object detection benchmark"
- AR@100: Average Recall considering the top 100 predictions. "average recall for the top 100 predictions (AR@100)"
- Auto-regressive objective: Training objective where each token is predicted conditioned on previous tokens. "standard auto-regressive objective:"
- Axis-aligned bounding box: A box whose edges are aligned with coordinate axes (no rotation). "axis-aligned"
- BEV (Bird’s-Eye View) annotation: Top-down scene representation used to make spatial relations explicit. "prompting with Birdâs-Eye View (BEV) annotation."
- Bipartite matching: Optimal pairing between two sets (e.g., predictions and ground truth) for evaluation. "a bipartite matching~\cite{kuhn1955hungarian}"
- Camera coordinate system: The 3D coordinate frame defined relative to the camera. "in the camera coordinate system."
- Camera intrinsics: Parameters describing the camera’s internal geometry (e.g., focal length, principal point). "variability in camera intrinsics"
- Catastrophic forgetting: Loss of previously learned skills when training on new tasks. "mitigating catastrophic forgetting of its original capabilities."
- Chain-of-Thought (CoT): Step-by-step reasoning traces used to guide model inference. "chain-of-thought (CoT) processes"
- Data packing strategy: Technique to combine multiple sequences to improve training efficiency. "a dynamic data packing strategy"
- Euler angles: Angle triplet representing 3D rotations around coordinate axes. "using Euler angles."
- F1 score: Harmonic mean of precision and recall used to assess detection quality. "the F1 score"
- Field of View (FoV) unification: Normalizing images to a virtual camera with a fixed FoV to remove intrinsic disparities. "Field of View (FoV) unification strategy."
- GRPO (Group Relative Policy Optimization): RL method that compares responses within a group to compute advantages without a value model. "Group Relative Policy Optimization (GRPO) algorithm"
- MLP merger: A multilayer perceptron used to fuse visual and language features. "via an MLP merger."
- Peripersonal space: The space immediately surrounding an agent, crucial for spatial interactions. "within its peripersonal space."
- Pseudo labels: Automatically generated labels (often by a teacher model) used for training. "create pseudo labels for wild images"
- Reinforcement Learning (RL): Learning paradigm optimizing actions via reward signals. "followed by reinforcement learning to further improve spatial reasoning abilities."
- Scene caption: Text describing objects and their spatial layout, beyond general image content. "we introduce the scene caption."
- Scene graph: Structured representation of objects and their relationships in a scene. "from the scene graph~\cite{zhu20233d}"
- Spatiotemporal relationships: Joint spatial and temporal relations among entities in video. "spatiotemporal relationships"
- Supervised fine-tuning (SFT): Training with labeled data to adapt or specialize a model. "Stage 1: Supervised Fine-tuning."
- Tokenizer: Component mapping text (or discretized actions) to token IDs and back. "language tokenizer."
- Value model: A model estimating expected return used in many RL algorithms. "bypasses the need for a value model"
- ViT-MLP-LLM paradigm: Architecture combining a Vision Transformer, an MLP fusion module, and a LLM. "follows the widely used "ViT-MLP-LLM" paradigm"
- Vision Transformer (ViT): Transformer-based architecture for image encoding. "Vision Transformer (ViT)"
- Vision-Language-Action (VLA): Models that map visual inputs and language instructions to actions. "Vision-Language-Action (VLA) tasks."
- Vision-LLMs (VLMs): Models jointly processing visual and textual inputs. "Vision-LLMs (VLMs)~\cite{gpt4, gemini2.5, seed_1.5, qwen2vl,internvl2.5}"
Practical Applications
Immediate Applications
The following bullet points summarize practical use cases that can be deployed now, leveraging the paper’s datasets (VST‑P, VST‑R), training pipeline (SFT → CoT → RL/GRPO), BEV prompting, field-of-view (FoV) unification, text-based scene layout descriptions, and VLM→VLA adaptation.
- Robotics (industrial/warehouse): Spatially tuned VLA for pick-and-place and simple manipulation
- Application: Use the VST-enhanced VLA to improve success rates in bin picking, kitting, and assembly station tasks with monocular RGB cameras.
- Tools/workflows: Integrate the action detokenizer (256-bin discrete actions) into a ROS stack; fine-tune on task-specific trajectories (e.g., LIBERO-like tasks).
- Assumptions/dependencies: Camera intrinsics known or reliably estimated; discrete action bins sufficient (may need hybrid continuous actions for fine control); safety guardrails for deployment.
- Retail and logistics: Shelf auditing, inventory counting, and product placement from video
- Application: Leverage VST video capabilities (appearance order; object counting) to automatically audit stock levels, restocking events, and shelf layout compliance.
- Tools/products: “Appearance-order and counting” API; store camera feeds processed via VST-P/VST-R-tuned VLM.
- Assumptions/dependencies: Adequate coverage and viewpoints; domain fine-tuning for packaging/label variability.
- Manufacturing safety: Proximity and hazard monitoring
- Application: Monocular 3D object detection and distance estimation to monitor safe distances between workers and machinery/robot arms.
- Tools/workflows: “Monocular distance and 3D box” service with FoV normalization; alerts integrated into HSE dashboards.
- Assumptions/dependencies: Sufficient camera placement; calibration metadata; latency and accuracy thresholds for real-time safety.
- Real estate and interior design: Photo-to-layout and measurements
- Application: Generate room size estimates, object sizes, and floorplan-like spatial captions from photos for listings or renovation planning.
- Tools/products: “Spatial scene captioning” and “Monocular 3D detection” APIs; automatic layout descriptions emphasizing spatial relations.
- Assumptions/dependencies: Indoor scene bias in training data; FoV normalization requires intrinsics or robust default assumptions; post-processing to CAD/BIM formats.
- AR/VR (consumer and enterprise): Spatial anchoring and occlusion-aware placement
- Application: Use scene captions and 3D boxes to place virtual objects with correct depth/occlusion; anchor content persistently across views.
- Tools/workflows: Unity/Unreal plugin calling VST-tuned VLM for layout text and object positions; multi-view camera alignment using the multi-image data engines.
- Assumptions/dependencies: Indoor focus; camera motion modeling available; runtime performance constraints on mobile devices.
- Security and surveillance: Multi-camera correlation and camera-motion analysis
- Application: Infer correspondences across views and reason about camera motion to reconstruct object trajectories in indoor spaces.
- Tools/workflows: “Multi-view correspondence” module; camera-pose estimation via Euler angles; BEV-aware scene summaries.
- Assumptions/dependencies: Overlapping viewpoints; time-sync; privacy/compliance.
- Software/ML Ops: Data generation and training improvements
- Application: Adopt BEV prompting to synthesize higher-quality chain-of-thought (CoT) for multi-view tasks; use rule-checkable data to drive RL with GRPO.
- Tools/workflows: Prompt templates with BEV overlays; reward functions combining accuracy and format checks; VeRL-compatible pipelines.
- Assumptions/dependencies: Access to ground-truth 3D boxes or approximate via SLAM; compute resources for SFT+RL.
- Computer vision pipelines: FoV unification as a preprocessing layer
- Application: Standardize images to a virtual camera FoV to improve cross-dataset generalization in 3D tasks without specialized encoders.
- Tools/workflows: “FoV normalizer” library integrated into training and inference.
- Assumptions/dependencies: Intrinsics availability or robust estimation; downstream models accept normalized inputs.
- Academia (vision-language and embodied AI): Reproducible benchmarks and curricula
- Application: Use VST-P and VST-R to study a cognitive-inspired progression from spatial perception to reasoning; evaluate on CVBench/VSIBench/MMSI-Bench.
- Tools/workflows: Open-source code and data; progressive SFT→CoT→RL training recipes; ablations for single/multi-image/video tracks.
- Assumptions/dependencies: Licensing constraints of underlying datasets; adherence to benchmark protocols.
- Daily life (consumer apps): AR measuring and layout assistance
- Application: Smartphone apps that estimate distances, object sizes, and produce spatial descriptions for furniture arrangement or home organization.
- Tools/products: “AR measuring assistant” using monocular depth priors and 3D boxes; spatial text guidance for layout.
- Assumptions/dependencies: Camera quality and intrinsics; indoor scene suitability; user experience for measurement verification.
Long-Term Applications
These use cases require further research, scaling to new domains (e.g., outdoor, dynamic scenes), or productization beyond current capabilities.
- Autonomous driving and mobile robotics (outdoor): Multi-view spatial reasoning at scale
- Application: Extend VST beyond indoor to outdoor, dynamic traffic scenes; integrate BEV prompting with HD maps; robust ego-motion handling.
- Tools/products: “VST-AD” dataset and pipeline; multi-sensor fusion (RGB, LiDAR); BEV-enhanced CoT for trajectory and scene reconstruction.
- Assumptions/dependencies: Large-scale labeled outdoor data; real-time constraints; safety and regulatory approvals.
- Home service robots and embodied assistants: End-to-end household tasks
- Application: Spatially grounded planning for navigation, tidying, and fetching across rooms with limited cameras.
- Tools/workflows: Hybrid action spaces (continuous + discrete); closed-loop VLA with online RL; integration with smart-home sensors.
- Assumptions/dependencies: Robust generalization to clutter and occlusions; safety and reliability standards; privacy-preserving data.
- Assistive technologies (healthcare): Spatial narration and hazard alerts for visually impaired users
- Application: On-device multi-view summarization and distance-aware guidance; temporal event narration (“what moved, where, and when”).
- Tools/products: Wearable cameras; BEV-informed spatial CoT narration; low-latency edge inference.
- Assumptions/dependencies: Strong privacy constraints; battery, compute limits; clinical validation.
- Construction/BIM and facilities management: Photo-to-3D updates and compliance checks
- Application: Convert multi-view site photos into textual layout reconstructions and 3D updates; verify distances and clearance rules against building codes.
- Tools/workflows: “Text-to-layout co-pilot” integrated with BIM; rule-checkable reward frameworks for code compliance.
- Assumptions/dependencies: Domain-specific datasets; precise scale recovery; integration with engineering workflows.
- Smart buildings and digital twins: Real-time occupancy and spatial analytics from distributed cameras
- Application: Reconstruct interior layouts and track movement across views to optimize space usage and energy.
- Tools/products: BEV aggregator; multi-view correspondence engine; privacy-aware analytics.
- Assumptions/dependencies: Camera calibration and synchronization; data governance; compute at the edge/server.
- XR content authoring: Automatic scene layout inference for asset placement and occlusion
- Application: Authoring tools that parse real-world scenes from photos/videos to auto-place assets; maintain occlusion and scale consistency.
- Tools/workflows: VST-enhanced scene parser; export to DCC tools; QA via rule-checkable constraints.
- Assumptions/dependencies: Accurate absolute scale; standardized metadata; creator workflows.
- Policy and standards: Certification and evaluation frameworks for spatially aware AI
- Application: Establish spatial understanding benchmarks and reward-driven validation as part of safety certification for robots and cameras.
- Tools/workflows: MMSI/VSIBench-inspired standardized tests; metadata standards for camera intrinsics/FoV; documentation for RL reward audits.
- Assumptions/dependencies: Multi-stakeholder coordination; harmonization across industries; auditability and transparency requirements.
- Medical robotics and OR workflows: Instrument counting and sterile field monitoring
- Application: Count instruments, enforce distances from sterile fields, detect occlusion risks in OR.
- Tools/products: Multi-view video analysis with spatial reasoning; integration with OR platform APIs.
- Assumptions/dependencies: High reliability; clinical compliance; domain-specific datasets.
- Insurance and finance: Visual claims assessment and property valuation
- Application: Infer room dimensions, damage extent, and item counts from claim photos/videos; validate measurements against policies.
- Tools/workflows: Monocular 3D estimation with FoV normalization; rule-checkable outputs for audit trails.
- Assumptions/dependencies: Domain generalization; explainability; compliance with fraud detection protocols.
- Search and rescue: Multi-agent, multi-view spatial reasoning
- Application: Cross-view layout reconstruction in cluttered, partially observable environments for locating victims or hazards.
- Tools/products: Drone-mounted cameras; BEV-enabled multi-view CoT; uncertainty-aware planning.
- Assumptions/dependencies: Robustness to adverse conditions; outdoor generalization; coordination protocols.
- General-purpose VLM training practice: Progressive SFT→CoT→RL recipe for reasoning
- Application: Apply the VST training strategy (including rule-checkable reward design, GRPO, CoT cold start) to domains beyond spatial (e.g., scientific, procedural).
- Tools/workflows: VeRL integration; mixed accuracy/format rewards; dataset curation pipelines modeled on VST-P/VST-R.
- Assumptions/dependencies: Domain-specific rule-checkable tasks; compute budgets; careful balance to avoid catastrophic forgetting.
Common assumptions and dependencies across applications
- Data/domain shift: VST is trained heavily on indoor scenes; outdoor/generalization may require additional data and adaptation.
- Camera metadata: FoV unification and accurate depth/distance estimation often assume known or well-estimated intrinsics.
- Performance and safety: Real-time constraints and safety-critical deployments (robots, healthcare) require rigorous validation, latency guarantees, and fail-safes.
- Privacy and compliance: Multi-camera, multi-view deployments raise privacy, consent, and data governance requirements.
- Hardware constraints: Mobile/edge deployments may need model compression or distillation without degrading spatial reasoning.
- Licensing and openness: Use of datasets and code must respect licenses; proprietary teacher models used in data generation (e.g., for scene captions/CoT) may need alternatives in some environments.
Collections
Sign up for free to add this paper to one or more collections.