Spatial-SSRL: Enhancing Spatial Understanding via Self-Supervised Reinforcement Learning
Abstract: Spatial understanding remains a weakness of Large Vision-LLMs (LVLMs). Existing supervised fine-tuning (SFT) and recent reinforcement learning with verifiable rewards (RLVR) pipelines depend on costly supervision, specialized tools, or constrained environments that limit scale. We introduce Spatial-SSRL, a self-supervised RL paradigm that derives verifiable signals directly from ordinary RGB or RGB-D images. Spatial-SSRL automatically formulates five pretext tasks that capture 2D and 3D spatial structure: shuffled patch reordering, flipped patch recognition, cropped patch inpainting, regional depth ordering, and relative 3D position prediction. These tasks provide ground-truth answers that are easy to verify and require no human or LVLM annotation. Training on our tasks substantially improves spatial reasoning while preserving general visual capabilities. On seven spatial understanding benchmarks in both image and video settings, Spatial-SSRL delivers average accuracy gains of 4.63% (3B) and 3.89% (7B) over the Qwen2.5-VL baselines. Our results show that simple, intrinsic supervision enables RLVR at scale and provides a practical route to stronger spatial intelligence in LVLMs.








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Spatial-SSRL: A simple explanation
Overview
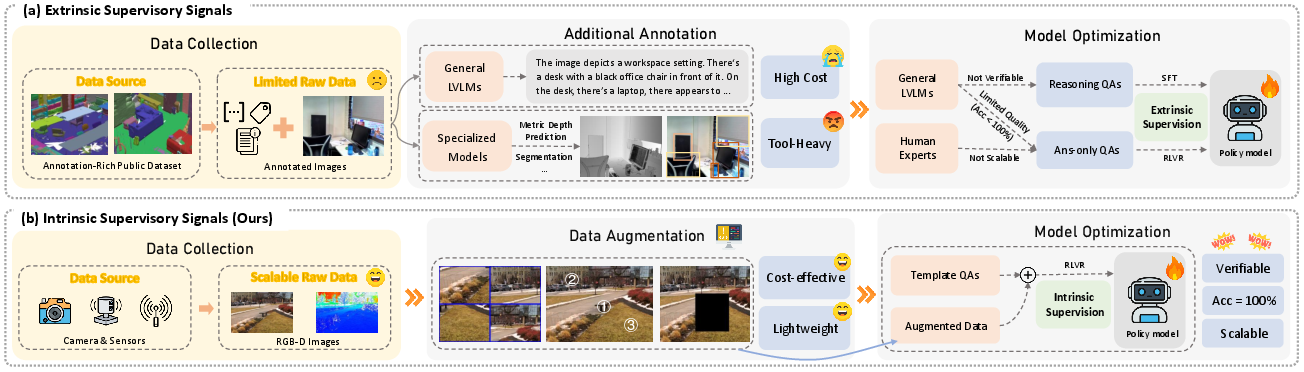
This paper is about teaching AI systems to better understand where things are in pictures and videos—both in 2D (like positions on a screen) and in 3D (like how far away and how objects are oriented). The authors created a new training method called Spatial-SSRL that helps vision-LLMs (AIs that look at images and read text) reason about space using only regular images and simple checks, without needing humans to label data or fancy tools.
What questions did the researchers ask?
- How can we help AI models understand space—like “which object is closer,” “which way is something facing,” or “where is it from another object’s viewpoint”—without spending lots of money on labeled data or special software?
- Can we use everyday pictures (and, when available, depth maps that show how far each pixel is) to create training exercises the AI can automatically check?
- Will this training make models better at spatial reasoning without hurting their general skills on other visual tasks?
How did they do it?
The team used a mix of self-supervised learning and reinforcement learning:
- Self-supervised learning means the AI learns from patterns in the data itself, not from human-labeled answers. Think of it like practicing with puzzles where the correct solution can be checked automatically.
- Reinforcement learning means the AI tries to answer a question, gets a reward if it’s right, and learns to do better next time—like a game where you score points for correct moves.
- Verifiable rewards means every exercise has a clear, checkable correct answer. If the AI gets it right, it gets a point. If not, it doesn’t.
They built five simple, puzzle-like tasks from regular RGB images and RGB-D images (RGB-D includes a “depth map,” which is basically a per-pixel measurement of distance from the camera):
Here are the five tasks. Each one is designed so the right answer can be checked automatically.
- Shuffled patch reordering: The image is cut into tiles and shuffled like a jigsaw puzzle. The AI must put the tiles back in the right order. This teaches global layout and “where things belong” in 2D.
- Flipped patch recognition: One tile is flipped (left-right or up-down). The AI must find which tile was flipped and how. This teaches understanding of orientation and mirror symmetry.
- Cropped patch inpainting: A square hole is cut out of the image, and the AI must choose the correct patch that fits into the hole from several look-alike options. This teaches matching local texture and context.
- Regional depth ordering: Using a depth map, the AI must order marked regions from closest to farthest. This teaches 3D distance and “which thing is in front.”
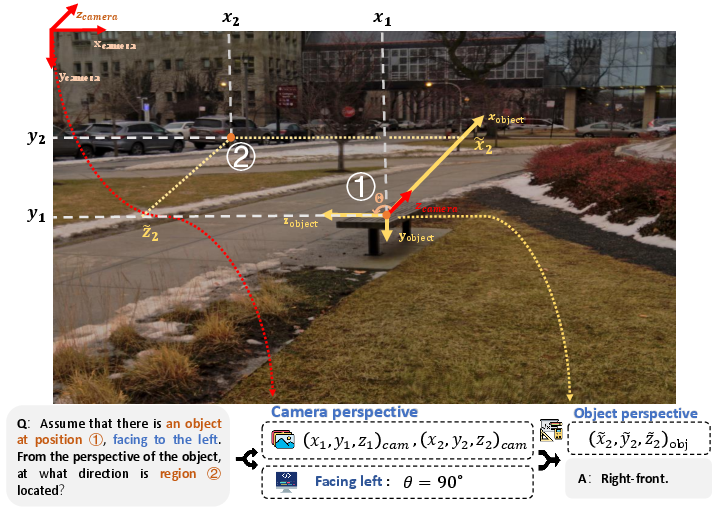
- Relative 3D position prediction: Given two points and an object’s facing direction (like “facing left” or “facing the camera”), the AI must say where the second point is relative to the object (e.g., left-front, right-back). This teaches egocentric 3D reasoning—thinking from the object’s point of view.
Training approach:
- First, a short warm-up (called supervised fine-tuning) helps the model learn the right answer format so it doesn’t get confused.
- Then, reinforcement learning takes over. The model generates an answer with a short reasoning process. A simple checker confirms if the answer is correct and properly formatted. The model gets a higher reward for correct answers and a small reward for following the format.
Data:
- They automatically created a dataset of about 81,000 question-answer pairs (called Spatial-SSRL-81k) from real-world images and depth maps. No humans were needed to label anything, because every puzzle had a built-in, checkable solution.
What did they find, and why is it important?
They tested their improved models on seven different spatial understanding benchmarks (covering images and videos), and also on several general visual tasks. The key results show the approach works well and doesn’t harm the model’s overall abilities.
Here are the highlights:
- Spatial reasoning gains: Their models beat strong baselines by an average of about +4.63% (smaller 3B model) and +3.89% (larger 7B model) across seven spatial benchmarks.
- Biggest boost: On a tough benchmark called Spatial457, which requires precise 3D reasoning and multiple steps of logic, the larger model improved by +8.67%.
- Works on videos too: Even though they trained only on images, the model did better on a video spatial benchmark (VSI-Bench), showing the skills transfer across modalities.
- Better reasoning, not just guessing: Baseline models tended to get worse when asked to “show their work” (reasoning steps). Spatial-SSRL made reasoning helpful, boosting accuracy when the model explained its steps.
- No loss of general skills: On general visual tasks like question answering, reading text in images (OCR), and charts, the models kept their performance and usually improved slightly.
These improvements matter because spatial understanding is important for things like:
- Self-driving cars: judging distances, directions, and relative positions
- Robots: picking up and moving objects safely and precisely
- Augmented reality and navigation: placing digital objects correctly or guiding users through spaces
What’s the big takeaway?
Spatial-SSRL shows that:
- You can teach AI strong spatial skills using simple, puzzle-like tasks built from ordinary images and depth maps.
- You don’t need expensive labels, special tools, or simulated worlds—just a clever way to create self-checking exercises.
- Reinforcement learning with verifiable rewards is a great match for these tasks: the AI learns by trying, getting instant feedback, and improving.
- The approach scales easily and can be extended by adding new puzzle types.
In short, this research offers a practical, low-cost path to give AI better “spatial common sense,” which could speed up progress in areas like robotics, autonomous driving, and smart assistants that understand the physical world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Depth availability and quality: The approach relies on RGB-D inputs for depth-based tasks, but the robustness to noisy, sparse, or monocularly-estimated depth (e.g., MegaDepth’s SfM-derived depth) is not analyzed; quantify performance degradation under different sensor types and noise levels.
- Vertical relations omitted: Relative 3D position prediction explicitly ignores the vertical (y) axis and above/below relations; extend to full 3D (including pitch/roll) and evaluate tasks requiring vertical reasoning (e.g., staircases, shelving).
- Discrete orientation assumptions: Object orientation is sampled from four discrete directions and assumed parallel to the ground; investigate continuous orientations, tilted objects/camera, and orientation estimation uncertainty.
- Object-level semantics missing: Depth-based tasks use pixel points rather than object instances; develop verifiable, tool-free, self-supervised object-level relation tasks (e.g., left-of/behind relationships between discovered object masks) without external detectors.
- Metric geometry vs. ordinal depth: Supervisory signals focus on ordinal depth ordering; add verifiable tasks for metric scale, distance estimation, and camera-aware geometry (using intrinsics/extrinsics) to move beyond ordinal reasoning.
- Camera calibration assumptions: The coordinate transformation uses normalized depth without explicit camera intrinsics/extrinsics; analyze accuracy impacts and incorporate calibrated geometry for metric-consistent 3D reasoning.
- Temporal and motion cues: Training uses static images; design self-supervised, verifiable video tasks (temporal ordering, motion parallax, dynamic occlusion) and quantify gains on video benchmarks beyond VSI-Bench.
- Task coverage breadth: Current pretexts do not explicitly target occlusion reasoning, collision prediction, scale constancy, or affine/viewpoint changes; expand verifiable tasks to cover these spatial competencies.
- Cross-view consistency: Despite multi-view spatial benchmarks, there is no pretext leveraging multi-view geometric constraints (e.g., epipolar consistency, triangulation); add self-supervised multi-view tasks for stronger 3D reasoning.
- Reward sparsity and shaping: Accuracy rewards are binary and final-answer-only; explore partial-credit scoring (e.g., sequence edit distance for ordering), intermediate-step verification, curriculum schedules, and anti-reward-hacking strategies.
- Reasoning trace verification: The method enforces format but does not verify the correctness of the reasoning chain; investigate program-of-thought, geometric proof checkers, or consistency checks to reward valid intermediate reasoning.
- RL algorithm choice and stability: Only GRPO is used, with limited details on stability, seeds, and sensitivity; compare PPO variants, off-policy methods, sequence-level RL, and curriculum RLVR to assess robustness and sample efficiency.
- Scaling laws and efficiency: The dataset is 81k samples; characterize scaling curves (data size, rollout group size, KL regularization, temperatures) and compute costs to guide efficient training at larger scales.
- Cold-start reliance: RL was unstable without SFT warm-up; quantify how much warm-up is necessary, and test alternative initialization strategies (e.g., format-only SFT, reward shaping warm-start).
- Dataset ambiguity and verifiability claims: The paper asserts “100% ground-truth accuracy” for SSL targets; audit ambiguity rates (especially for inpainting distractors and reordered patches), release ambiguity diagnostics, and human-check subsets.
- Domain robustness: Evaluate cross-domain generalization (night/adverse weather, aerial/remote sensing, medical/industrial, synthetic/cartoon) to validate the claim of broad applicability.
- Sensor generalization: Test across different RGB-D sources (ToF, structured light, stereo, LiDAR projection), varying baselines and noise profiles, and depth holes to ensure pipeline reliability in real-world deployment.
- Failure-case taxonomy: Provide systematic error analysis (scene types, object categories, depth noise, occlusions, reflective/transparent surfaces) to inform targeted task design and training strategies.
- Architecture generality: Results are limited to Qwen2.5-VL-3B/7B; replicate on other LVLM families (e.g., LLaVA, InternVL, Idefics) to demonstrate architecture-agnostic benefits.
- Baseline fairness: Report apples-to-apples comparisons (identical prompting regimes with/without reasoning) and direct head-to-head against tool- or simulation-based RLVR pipelines to substantiate cost–performance claims.
- Downstream embodiment: Validate transfer to closed-loop embodied tasks (robot manipulation, navigation, autonomous driving) with real-time constraints, safety metrics, and end-to-end success rates.
- Video training: Although VSI-Bench gains are observed without video training, investigate adding self-supervised video tasks and measure incremental improvements over image-only SSRL.
- Integration with extrinsic supervision: Explore hybrid pipelines combining self-supervised tasks with limited, high-quality tool-based or human-curated verifiers to balance cost with coverage.
- Shortcut exploitation: Assess whether models solve patch reordering/inpainting via low-level border/texture cues; design anti-shortcut augmentations and evaluate true spatial reasoning gains with controlled tests.
- Format dependency: The format reward enforces think/boxed outputs; study whether reasoning benefits persist without special formatting and whether formatting constraints impact generalization in different inference environments.
- General capabilities breadth: General VQA evaluations are limited; add detection/segmentation, grounding, and OCR+numeracy stress tests to thoroughly assess potential trade-offs or regressions.
- Data contamination: Check for benchmark data overlap or near-duplicates with COCO/MegaDepth/DIODE-derived training samples to rule out leakage.
- Compute and reproducibility: Report compute budget, hardware, training time, seeds, and run-to-run variance; release logs/configs to enable reproducible comparisons and stability studies.
- Threshold sensitivity: Ablate r_max, d_min, and direction thresholds (δx, δz) used to enforce unambiguous depth/position labels; design adaptive thresholding or uncertainty-aware verifiers.
- Human-level performance gap: Quantify remaining gap to human performance on spatial tasks and outline a roadmap (new tasks, richer geometry, embodiment) for closing that gap.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging the paper’s open-source model, data, and code to improve spatial understanding in vision-language systems without costly labels or tool-heavy pipelines.
- Improved LVLM fine-tuning pipelines for spatial reasoning
- Sector: Software/ML Ops
- What emerges: A “Spatial-SSRL trainer” that plugs into existing post-training workflows (e.g., GRPO-based RLVR) to boost spatial tasks such as orientation, depth ordering, and multi-view location understanding with zero human labels.
- Assumptions/Dependencies: Access to compute for GRPO; a base LVLM compatible with structured prompting; optional RGB-D imagery for depth-based tasks (depth-free tasks work with RGB only).
- Tool-free dataset curation from in-domain images for self-supervised spatial RL
- Sector: Software, Robotics, Retail, Logistics, Manufacturing
- What emerges: Automated pipelines that convert warehouse camera feeds, shop-floor photos, or assembly images into pretext QAs (patch reordering, flip detection, inpainting, regional depth ordering, relative 3D positioning) for continual spatial post-training.
- Assumptions/Dependencies: Sufficiently diverse RGB (and ideally RGB-D) data; data governance approval; process to filter low-quality depth for depth-based tasks.
- Spatial audit suites for LVLMs and vision models
- Sector: Software, Academia, Policy
- What emerges: A “Spatial-Audit” harness using the paper’s verifiable tasks to measure orientation sensitivity, layout coherence, and ordinal depth competence; can be integrated into CI for model releases.
- Assumptions/Dependencies: Standardized prompts and reward verifiers; adoption of open benchmarks (e.g., Spatial457, 3DSRBench); reproducible evaluation via VLMEvalKit.
- AR/VR content verification and placement checks
- Sector: AR/VR, Gaming, Interior Design
- What emerges: Orientation and depth-consistency checks to prevent mirrored assets, wrong-facing furniture, or occlusion errors; “Pose & Placement Validator” for level editors and AR staging tools.
- Assumptions/Dependencies: Reliable depth estimation (RGB-D preferred, monocular depth acceptable with quality screening); integration into content pipelines; domain-specific scene priors.
- Photo/video post-processing with occlusion-aware inpainting and flip detection
- Sector: Creative Tools, Media
- What emerges: Plugins that detect flipped sub-regions (e.g., mirrored text/logos) and select contextually consistent fills using the cropped patch inpainting task; auto-suggest composition fixes.
- Assumptions/Dependencies: High-quality patch extraction and distractor generation; UI for human-in-the-loop correction; adequate performance on consumer devices or via cloud.
- E-commerce and catalog QA for image integrity
- Sector: Retail/E-commerce
- What emerges: Systems that flag mirrored product photos, inconsistent multi-view placements, and implausible occlusions that mislead consumers; auto-curation tools for product galleries.
- Assumptions/Dependencies: Access to product image pipelines; tolerance for occasional false positives; depth-free tasks suffice.
- Video analytics modules for orientation and proximity cues
- Sector: Sports Analytics, Security, Robotics
- What emerges: Orientation-aware tracking and relative position estimation across frames to improve event detection (e.g., “who is left/right/front”), collision prediction, and spatial pattern analysis.
- Assumptions/Dependencies: Transfer from image-trained SSL tasks generalizes to videos (as supported by VSI-Bench gains); good camera calibration improves robustness but is not strictly required.
- Education tools for spatial cognition and geometry reasoning
- Sector: Education
- What emerges: Tutor modules that generate and grade jigsaw/permutation tasks, orientation challenges, and depth/relative position exercises; adaptive drills for mental rotation and spatial logic.
- Assumptions/Dependencies: Curriculum alignment; age-appropriate content; depth-free tasks universally applicable.
- Cost-effective research workflows combining RLVR and SSL
- Sector: Academia/Research
- What emerges: Open, reproducible workflows to study spatial reasoning, ablations across pretext tasks, and scaling strategies without proprietary tools, enabling broad experimentation.
- Assumptions/Dependencies: Access to open datasets (COCO, DIODE, MegaDepth); willingness to adopt GRPO and structured reward formats.
Long-Term Applications
These applications require further research, scaling, integration, or domain-specific validation to reach production-grade deployment.
- Embodied agents with robust spatial LVLMs for manipulation and navigation
- Sector: Robotics (household, industrial, warehouse)
- What emerges: Agents that use improved LVLM spatial understanding for pick-and-place, part orientation, shelf stocking, and waypoint navigation with natural-language instructions.
- Assumptions/Dependencies: Safety and reliability testing; closed-loop control integration; domain adaptation to robot sensors; real-time constraints and edge inference optimizations.
- Driver assistance and autonomous driving perception augmentation
- Sector: Automotive
- What emerges: Modules that reason about relative positions (left/right/front/back), ordinal depth, occlusions, and multi-view consistency to aid scene understanding and hazard prediction.
- Assumptions/Dependencies: High regulatory bar; extensive validation on real driving data; robust depth sensing or top-tier monocular depth; integration with existing perception stacks.
- Digital twins and 3D reconstruction from sparse views
- Sector: AEC (Architecture/Engineering/Construction), Real Estate, XR
- What emerges: Improved occlusion reasoning and multi-view spatial consistency for reconstructing scenes from limited images; quality control for model alignment and scene graph consistency.
- Assumptions/Dependencies: Calibration and pose metadata improve outcomes; combining SSL tasks with SfM/NeRF-like pipelines; acceptance testing against ground-truth scans.
- Generative systems with enforced spatial consistency
- Sector: Creative AI, Content Generation
- What emerges: RLVR-trained VLMs that act as spatial critics/planners guiding image/video generation to respect orientation, depth ordering, and relative positions (e.g., for cinematic blocking).
- Assumptions/Dependencies: Coupling with generative models (diffusion/transformers); stable reward shaping for generation; scalable verifier-tooling.
- Large-scale, tool-free continual training on enterprise imagery
- Sector: Enterprise ML, Logistics, Retail, Manufacturing
- What emerges: Continuous self-supervised RL on unlabeled camera logs to maintain up-to-date spatial competence across changing environments (layouts, products, equipment).
- Assumptions/Dependencies: Data governance approvals; scheduling and compute for periodic RL updates; depth sensors improve 3D tasks but depth-free objectives still provide gains.
- Standardization and certification of spatial intelligence in AI systems
- Sector: Policy/Standards, Safety
- What emerges: Benchmarks and verifiable reward protocols for certifying spatial competence levels (e.g., minimum orientation and depth-order accuracy) for safety-critical deployments.
- Assumptions/Dependencies: Community consensus on metrics; test suites covering edge cases; mapping verifiable pretexts to real-world risk models.
- Healthcare and surgical robotics spatial reasoning
- Sector: Healthcare/Medical Robotics
- What emerges: Orientation- and depth-aware assistance in endoscopy and surgical tool placement; spatially consistent guidance and anomaly detection in procedures.
- Assumptions/Dependencies: Medical-grade validation; specialized sensors and domain adaptation; stringent regulatory compliance; robust handling of non-Lambertian surfaces and biological variability.
- Remote sensing and infrastructure inspection
- Sector: Energy, Utilities, Civil Engineering
- What emerges: Orientation-aware and depth-ordering analyses for aerial/satellite imagery and drone inspections, aiding fault localization and asset mapping.
- Assumptions/Dependencies: Domain shift handling (scale, viewpoint, atmospheric effects); integration with GIS pipelines; high-quality depth or stereo if available; calibration metadata.
- On-device AR measurement and spatial assist features
- Sector: Consumer Mobile, AR
- What emerges: Smartphone features for room measurement, object orientation hints, and occlusion-aware placement using compact spatially fine-tuned LVLMs.
- Assumptions/Dependencies: Model compression and acceleration; efficient RGB-D capture (e.g., LiDAR in high-end phones) or robust monocular depth estimation; battery/performance trade-offs.
- Misinformation detection via spatial forensics
- Sector: Trust & Safety
- What emerges: Systems that flag plausibly fake or manipulated media using orientation anomalies, inconsistent occlusions, or layout incoherence detectable by spatially trained LVLMs.
- Assumptions/Dependencies: Robustness against adversarial editing; cross-domain generalization; careful thresholding to balance false positives/negatives; explainability tooling.
Notes on feasibility across applications:
- Depth-based tasks perform best with reliable depth (RGB-D sensors or high-quality monocular depth); depth-free tasks still deliver improvements in pure RGB settings.
- GRPO/RLVR requires structured prompts and deterministic verifiers; organizations should establish formatting standards and logging to trace training/reward decisions.
- Safety-critical sectors (automotive, healthcare, robotics) need rigorous validation, domain adaptation, and compliance checks before deployment.
- Scaling benefits stem from tool-free, label-free curation; however, data quality controls (e.g., filtering noise, handling motion blur, ensuring diversity) remain important to achieve robust gains.
Glossary
- Ablation studies: systematic experiments that remove or isolate components to evaluate their individual contributions; "Ablation studies show that each task contributes to improved spatial understanding."
- Azimuth: the angular direction of an object around the vertical axis, used to describe orientation in 3D scenes; "the ability to reason over depth, distance, azimuth, and relative object positions"
- Cold-start: an initial stabilization phase before RL to familiarize a model with formats and reduce training instability; "Cold-start with SFT."
- Contrastive learning: a self-supervised technique that learns representations by pulling similar pairs together and pushing dissimilar pairs apart; "contrastive learning \cite{chen2020simpleframeworkcontrastivelearning, he2020momentum}"
- Cropped Patch Inpainting: a self-supervised task where the model selects the correct patch to fill a masked region, testing texture and structural coherence; "Cropped patch inpainting tests texture-context matching and fine-grained structural reasoning."
- Depth-based tasks: self-supervised objectives that use depth information to supervise 3D understanding; "Depth-based tasks exploit depth to supervise relative depth or distance ranking and 3D relation consistency under perspective transformations."
- Depth-free tasks: self-supervised objectives that operate only on RGB images to enhance 2D spatial understanding; "Depth-free tasks target 2D structure, including relative position between regions, permutation ordering, and cross-view correspondence."
- Depth map: an image-sized array encoding per-pixel distances from the camera; "Given an image and its normalized depth map "
- Deterministic verifier: a check that programmatically confirms answer correctness to compute rewards; "with a deterministic verifier producing binary or scalar rewards."
- Egocentric spatial relations: spatial relations defined from an object's viewpoint (e.g., left/right, front/back); "Relative 3D position prediction assesses egocentric spatial relations (left/right, front/back) conditioned on object orientation."
- Egocentric videos: first-person perspective video data used for spatial understanding evaluation; "VSI-Bench focuses on understanding egocentric videos."
- Flipped Patch Recognition: a self-supervised task where the model detects which patch was flipped and in which direction; "Flipped patch recognition demands sensitivity to mirror symmetries and local orientation cues."
- Group Relative Policy Optimization (GRPO): a policy-gradient RL algorithm that optimizes models using groupwise relative rewards; "Group Relative Policy Optimization (GRPO) \cite{shao2024deepseekmath}"
- Hallucination diagnostics: evaluations that test whether models generate spurious or incorrect content; "hallucination diagnostics \cite{liu2024mmbench,fu2024blink,guan2024hallusionbench}"
- Jigsaw: a self-supervised puzzle-like task that requires reconstructing shuffled image patches; "permutation/jigsaw tasks \cite{cruz2017deeppermnetvisualpermutationlearning, chen2020simpleframeworkcontrastivelearning,he2020momentum}"
- KL regularization: a penalty on divergence from a reference policy to stabilize RL training; "During GRPO, we apply KL regularization with weight 0.01."
- Large Vision-LLMs (LVLMs): multimodal models that jointly process visual and textual inputs; "Spatial understanding remains a weakness of Large Vision-LLMs (LVLMs)."
- Masked autoencoders (MAE): vision models trained to reconstruct masked patches, used for self-supervised pre-training; "masked autoencoders (MAE \cite{he2021maskedautoencodersscalablevision})"
- Masked LLMs (BERT): models trained to predict masked tokens in text for self-supervised learning; "masked LLMs (BERT \cite{devlin2019bertpretrainingdeepbidirectional})"
- Monocular depth: depth estimated from a single RGB image, often noisy compared to RGB-D; "inherits errors from detectors and monocular depth"
- Occlusion reasoning: understanding which objects block others and how visibility changes with depth; "foundational skills for tasks such as occlusion reasoning and 3D scene reconstruction."
- Ordinal depth perception: the ability to rank regions by relative distance without exact metric values; "Regional depth ordering evaluates ordinal depth perception across image regions."
- Ordinal reasoning: reasoning based on order relations (e.g., nearer/farther) rather than precise magnitudes; "Ranking regions by distance from the camera requires integrating depth cues, perspective understanding, and ordinal reasoning"
- Perspective transformations: geometric changes in appearance due to viewpoint, central to 3D consistency; "3D relation consistency under perspective transformations."
- Policy-gradient RL: reinforcement learning methods that directly optimize the policy via gradients of expected rewards; "a policy-gradient RL algorithm well-suited for verifiable reward signals."
- Pretext tasks: self-supervised objectives that provide intrinsic supervision signals for training; "Spatial-SSRL automatically formulates five pretext tasks that capture 2D and 3D spatial structure"
- Regional Depth Ordering: a depth-based task that requires ordering labeled regions from closest to farthest; "Regional depth ordering evaluates ordinal depth perception across image regions."
- Relative 3D Position Prediction: a depth-based task to predict the relative location of a point from an object's oriented frame; "Relative 3D position prediction assesses egocentric spatial relations (left/right, front/back) conditioned on object orientation."
- Reinforcement Learning with Verifiable Rewards (RLVR): RL paradigm where reward correctness is programmatically checked; "reinforcement learning with verifiable rewards (RLVR) pipelines depend on costly supervision"
- RGB-D images: images that include both color (RGB) and per-pixel depth (D); "ordinary RGB or RGB-D images."
- Rigid transformation: a combination of rotation and translation that preserves distances and angles; "we apply a 2D rigid transformation (translation followed by rotation) to "
- Rollout group: a set of multiple sampled responses per input used to compute RL rewards; "For each training sample, we generate a rollout group of 5 responses with temperature 1.0."
- Self-Supervised Learning (SSL): learning from intrinsic data structure without manual labels; "Self-supervised learning (SSL), which obtains supervision from the inherent structure of the data itself without relying on manual labels"
- Simulation-based approaches: pipelines that render synthetic 3D scenes to create training/evaluation data; "Simulation-based approaches render 3D scenes and synthesize QAs"
- Shuffled Patch Reordering: a self-supervised task that recovers the original layout from shuffled image patches; "Shuffled patch reordering requires recovering global 2D layout consistency from permuted patches."
- Supervised Fine-Tuning (SFT): training with labeled data to refine a pretrained model on specific tasks; "Early data-centric Supervised Fine-Tuning (SFT) approaches"
- Tool-based approaches: methods that rely on external models/tools (e.g., detectors, depth estimators) in the pipeline; "Tool-based approaches incorporate tools within their pipelines."
- Verifiable rewards: reward signals that can be automatically checked for correctness to guide RL; "optimizing with verifiable rewards"
- VLMEvalKit: an open-source toolkit for standardized evaluation of vision-LLMs; "We evaluate all models using VLMEvalKit"
- Visual question-answering (VQA): tasks where models answer questions about visual inputs; "visual question-answering (VQA)"
Collections
Sign up for free to add this paper to one or more collections.

