- The paper presents Actial, which activates 3D spatial reasoning in MLLMs by combining supervised and reinforcement learning.
- It introduces Viewpoint Learning with the Viewpoint-100K dataset to instill foundational spatial skills through a sequential fine-tuning approach.
- Experimental results demonstrate significant improvements on spatial benchmarks, validating enhanced generalization in complex visual tasks.
Actial: Activating Spatial Reasoning in Multimodal LLMs
Introduction
The paper presents Actial, a framework designed to activate and enhance the spatial reasoning capabilities of Multimodal LLMs (MLLMs). While MLLMs have demonstrated strong performance in 2D visual understanding, their ability to reason about 3D spatial relationships and cross-view consistency remains limited. Actial addresses this gap by introducing Viewpoint Learning, a targeted task and dataset (Viewpoint-100K) for foundational spatial skill acquisition, and a two-stage fine-tuning strategy combining supervised and reinforcement learning. The approach is evaluated across multiple spatial reasoning benchmarks, demonstrating significant improvements in both in-domain and out-of-domain tasks.
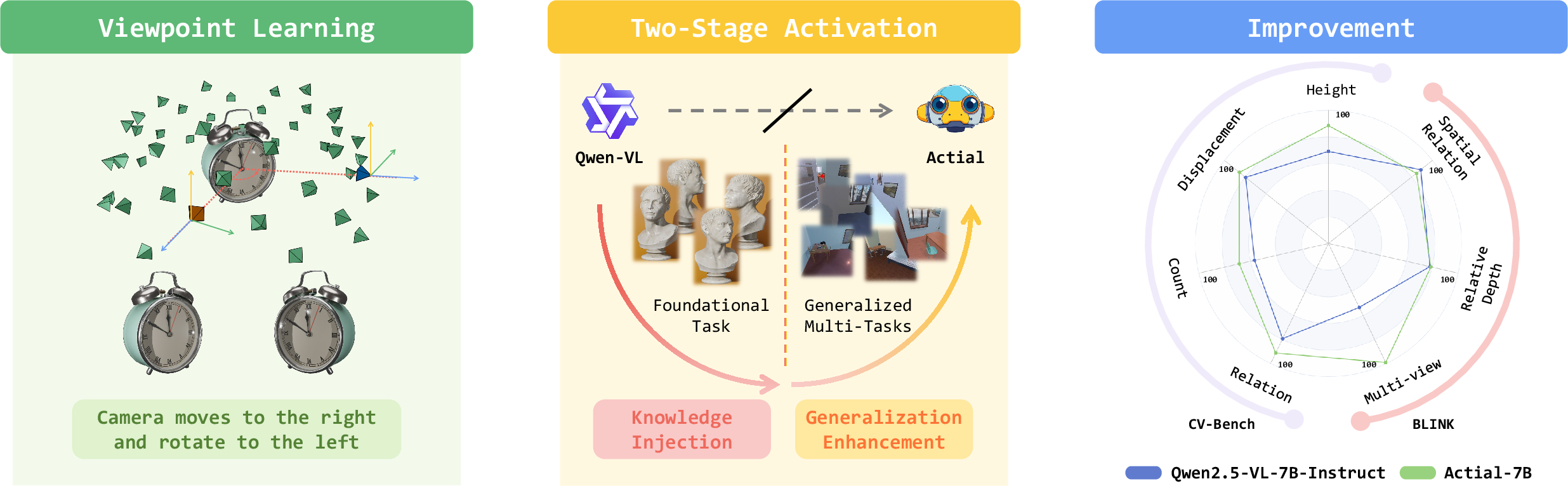
Figure 1: The Actial framework aims to activate MLLM spatial reasoning via Viewpoint Learning and a two-stage fine-tuning strategy.
2D Continuity vs. 3D Consistency
A central insight of the paper is the distinction between 2D continuity and 3D consistency. While 2D continuity refers to the smooth transition between adjacent frames in image sequences, 3D consistency requires the preservation of spatial and geometric relationships across views. The authors argue that most MLLMs, trained predominantly on 2D data, fail to capture the underlying 3D structure, leading to erroneous spatial reasoning when confronted with multi-view or viewpoint-dependent tasks.
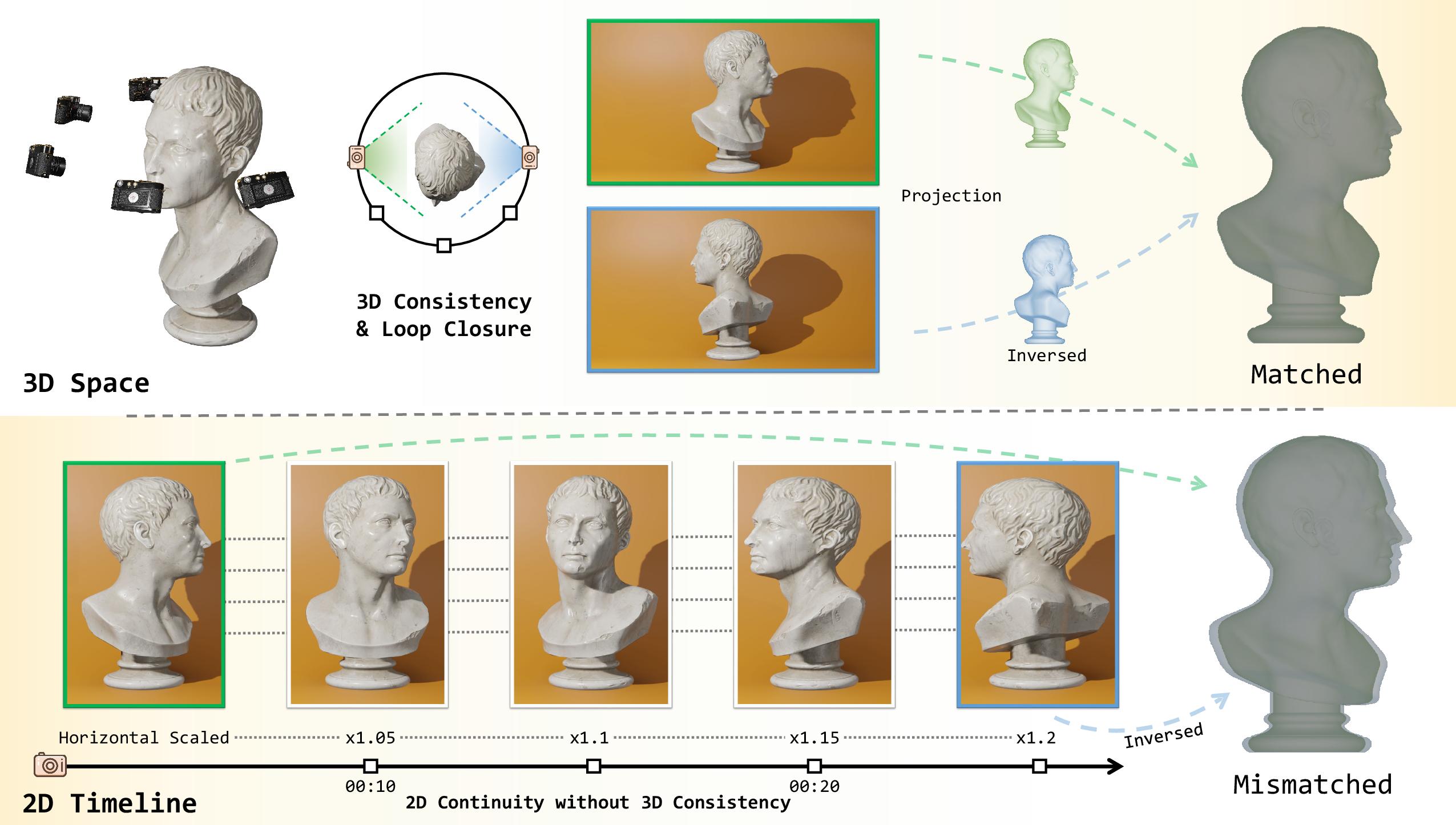
Figure 2: 2D continuity is not sufficient for 3D consistency; scale changes can destroy 3D consistency while maintaining 2D continuity.
Methodology
Viewpoint Learning and Dataset Construction
Viewpoint Learning is introduced as a foundational task for spatial reasoning. The Viewpoint-100K dataset consists of 100,000 object-centric image pairs with diverse viewpoints, each annotated with ego-centric and object-centric question-answer pairs. The dataset is constructed from MVImgNet, leveraging precise camera calibration data to generate questions about horizontal translation and rotation, abstracted into multiple-choice formats to facilitate learning.
Two-Stage Fine-Tuning Strategy
The training pipeline comprises two stages:
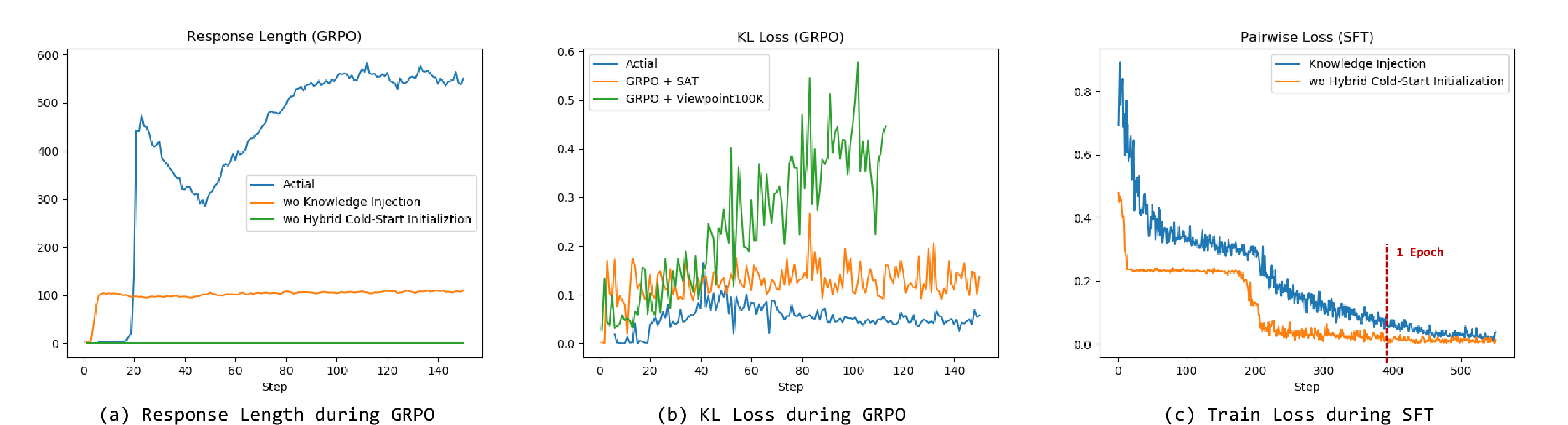
- Foundational Knowledge Injection (Supervised Fine-Tuning): The baseline MLLM is fine-tuned on Viewpoint-100K to inject explicit spatial knowledge. This stage is augmented with a hybrid cold-start initialization, mixing human-assisted pseudo chain-of-thoughts (CoTs) to maintain coherent reasoning and instruction-following behavior.
- Generalization Enhancement (Reinforcement Learning):
The model is further fine-tuned on the SAT dataset using Group Relative Policy Optimization (GRPO). This stage aims to improve generalization to broader spatial tasks, encouraging the model to generate its own reasoning chains and apply previously acquired spatial knowledge.
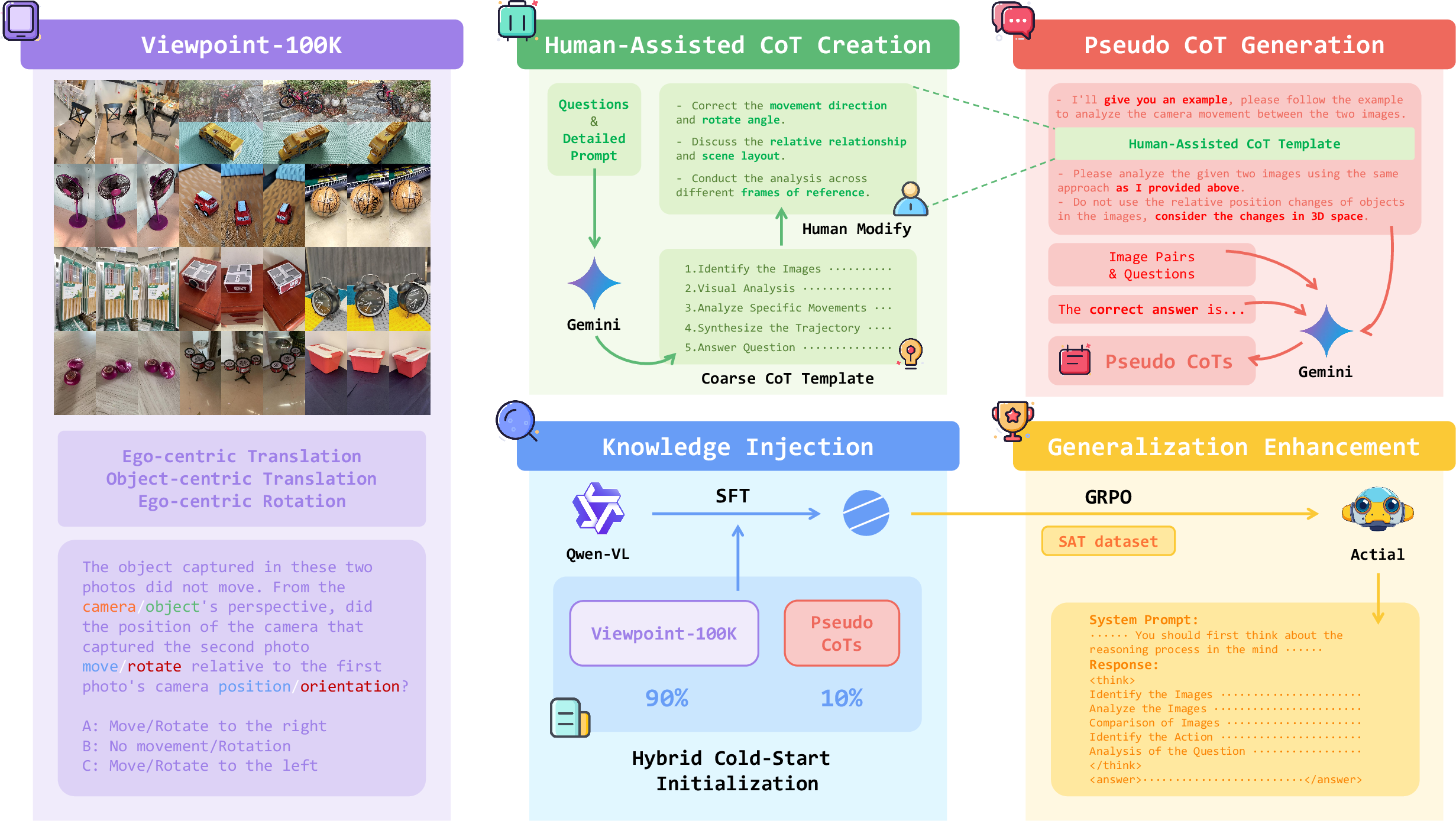
Figure 3: Actial pipeline overview, including dataset construction, knowledge injection, and generalization enhancement.
Hybrid Cold-Start Initialization
To address the degradation of instruction-following and reasoning format post-SFT, the authors introduce a hybrid cold-start initialization. This involves manually constructing correct CoT templates and generating pseudo CoTs using Gemini 2.5 Pro, which are mixed with the main dataset at a 0.1 ratio. This strategy ensures the model learns both viewpoint representations and robust reasoning processes.

Figure 4: Example of a generated pseudo chain-of-thought (CoT) used for hybrid cold-start initialization.
Experimental Results
Benchmarks and Evaluation
Actial is evaluated on 3DSRBench, CV-Bench, BLINK, and MMSI-Bench, using VLMEvalKit for standardized assessment. The baseline model is Qwen2.5-VL-7B-Instruct. Training details include SFT for 2 epochs and GRPO for 150 steps, with careful tuning of KL penalties and reward functions.
Ablation Studies
Ablation experiments confirm that knowledge injection via SFT is critical for foundational spatial skill acquisition, while generalization enhancement via GRPO is necessary to avoid overfitting and improve out-of-domain robustness. Mixing all datasets in a single SFT phase yields inferior results compared to the two-stage approach, underscoring the importance of sequential training.
Reasoning Process and Model Behavior
Qualitative analysis reveals that baseline MLLMs rely on superficial 2D cues for viewpoint questions, resulting in incorrect reasoning. Actial, after training, demonstrates correct spatial thinking, leveraging 3D consistency and reference frame transformations.

Figure 6: Baseline MLLMs rely on 2D cues for viewpoint questions, leading to erroneous results.

Figure 7: Actial's reasoning process employs correct spatial thinking, utilizing 3D consistency.
Dataset and Prompt Engineering
The Viewpoint-100K dataset provides three types of questions: ego-centric translation, ego-centric rotation, and object-centric translation. The hybrid cold-start initialization uses detailed CoT templates to guide the model's reasoning format.

Figure 8: Examples of Viewpoint-100K QA pairs, illustrating the diversity of spatial reasoning questions.
Implications and Future Directions
The results demonstrate that MLLMs possess latent 3D spatial perception capabilities that can be activated through targeted training. Explicit supervision on foundational spatial tasks is essential for robust spatial reasoning, with direct implications for robotics, autonomous navigation, and 3D scene understanding. The approach provides a practical pathway for improving MLLM performance in real-world spatial tasks.
However, the current dataset is limited to object-centric scenarios and multiple-choice questions, which simplifies the problem space. Future work should extend to more complex settings, such as camera pose regression, dynamic scenes, and embodied reasoning. Additionally, optimizing reasoning efficiency and output length is necessary for multi-step inference tasks.
Conclusion
Actial introduces a principled framework for activating spatial reasoning in MLLMs via Viewpoint Learning and a two-stage fine-tuning strategy. The approach yields substantial improvements in spatial reasoning benchmarks, demonstrating the necessity of foundational spatial skill training. While limitations remain in dataset diversity and reasoning efficiency, the work establishes a foundation for further advances in multimodal spatial intelligence and its application to embodied AI systems.