- The paper introduces SSR, a framework that transforms depth data into structured textual rationales to enhance spatial reasoning in VLMs.
- It employs an Image-Depth Interpreter and knowledge distillation to integrate depth perception without additional hardware.
- Experiments on a million-scale visual-language dataset demonstrate significant improvements in spatial reasoning and task efficiency.
Enhancing Depth Perception in Vision-LLMs via Rationale-Guided Spatial Reasoning
The study titled "SSR: Enhancing Depth Perception in Vision-LLMs via Rationale-Guided Spatial Reasoning" introduces a novel framework aimed at improving the spatial reasoning capabilities of Vision-LLMs (VLMs) by integrating depth perception information. This integration is achieved using rationale-guided spatial reasoning, which is posited to enhance VLMs towards achieving a human-like understanding of multi-modal tasks.
Introduction and Motivation
Conventional VLMs primarily rely on RGB inputs to perform various multi-modal tasks. While these models have shown remarkable capabilities, they fall short in accurately capturing spatial information that involves depth and relative positioning. Such limitations can hinder the comprehensive understanding of complex visual scenes, which is crucial for applications in robotics and spatial reasoning tasks (Figure 1).
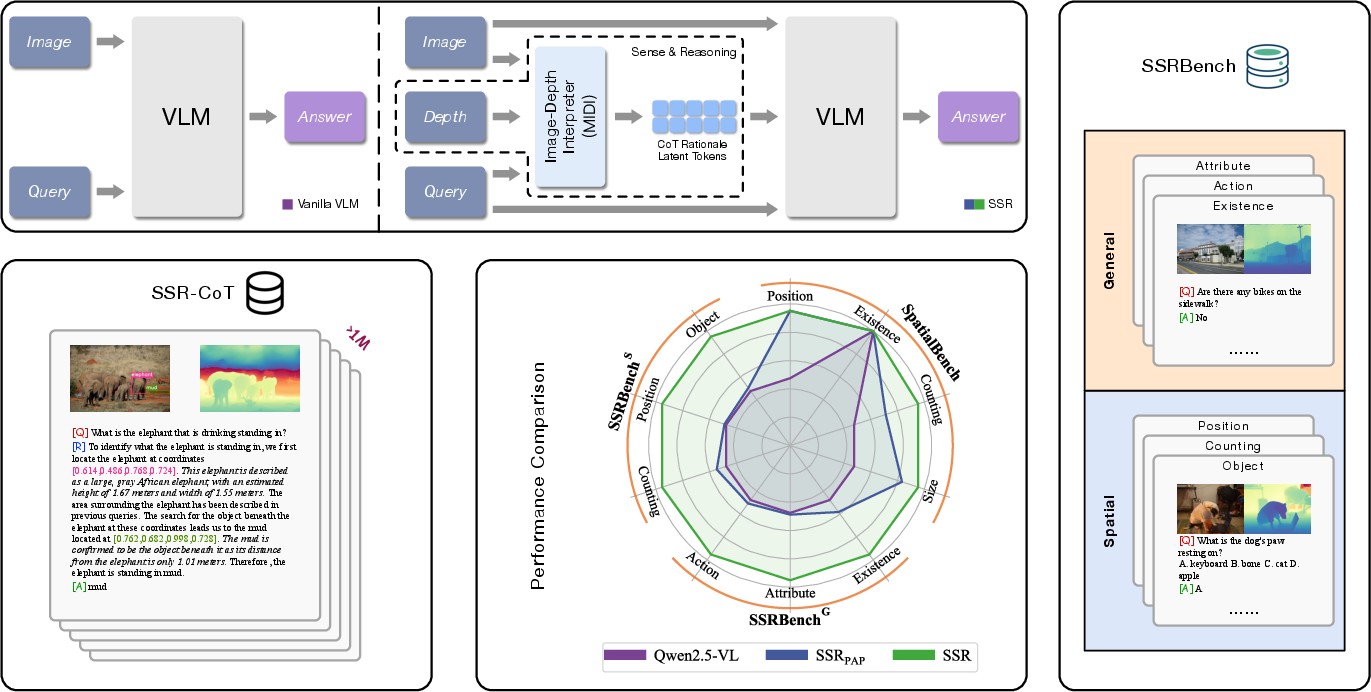
Figure 1: Unlike conventional VLMs, integrates depth perception to enhance spatial reasoning. We introduce a curated dataset and benchmark, demonstrating significant improvements in spatial reasoning tasks.
Recently, methodologies such as point clouds have been utilized to incorporate spatial data, but these methods often require specialized equipment and sensors, making them impractical for widespread use. To address this challenge, this study proposes SSR (Spatial Sense and Reasoning), a framework that converts raw depth data into structured textual rationales, thereby enhancing spatial reasoning without additional hardware.
Methodology
The SSR framework is characterized by its structured approach to transforming depth information into interpretable rationales. This process serves as an intermediate representation that significantly augments spatial reasoning capabilities. Key components of the SSR framework include:
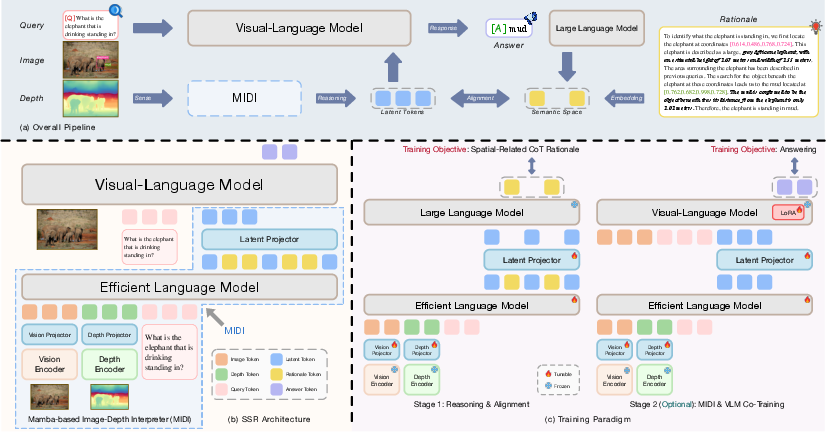
Figure 2: Schematic of SSR framework. (a) Overall pipeline. (b) Full architecture comprising the MIDI module followed by the VLM. (c) Two training stages outline the framework's operational phases.
Image-Depth Interpreter: SSR utilizes a Mamba-based Image-Depth Interpreter (MIDI) which generates depth-aware latent token representations. These representations feed into the VLM, enabling efficient integration of spatial reasoning information.
Knowledge Distillation: To create resource-efficient embeddings, SSR applies a knowledge distillation strategy that compresses the structured rationales into latent embeddings. This process allows seamless integration into existing VLMs without requiring extensive retraining.
This modular design enhances flexibility, allowing existing VLMs to incorporate deeper spatial understanding capabilities effortlessly.
Dataset and Benchmark Development
To enable effective evaluation of spatial reasoning enhancements, SSR introduces a new million-scale visual-language reasoning dataset, enriched with spatial reasoning annotations (Figure 3). This dataset is tailored to test the efficacy of VLMs in handling spatial tasks.
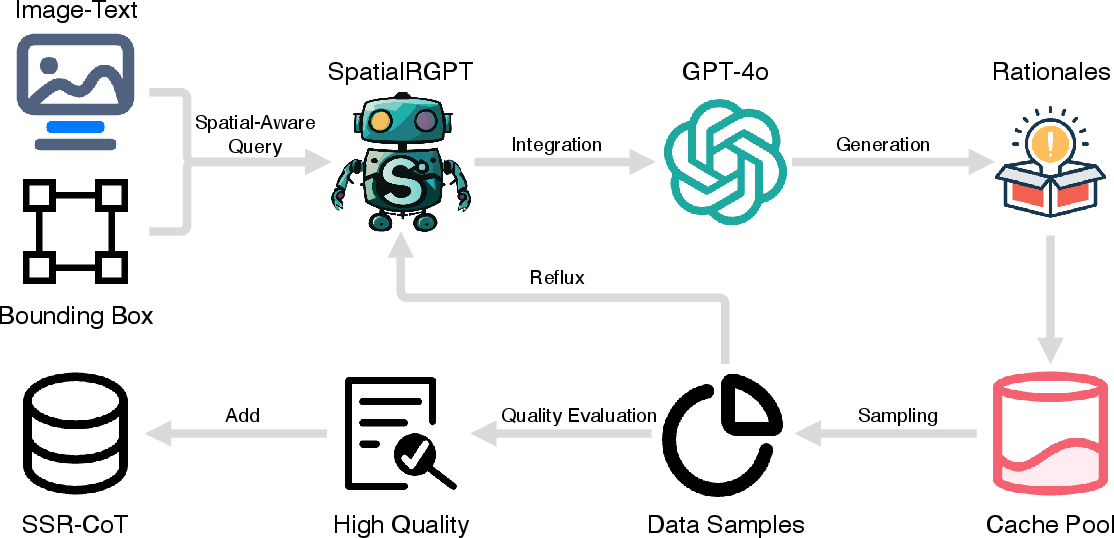
Figure 3: Schematic of SSR-CoT annotation pipeline.
Additionally, SSR presents a comprehensive multi-task benchmark designed to evaluate models across general and spatial reasoning domains (Figure 4).

Figure 5: Illustrative samples of the SSR dataset.
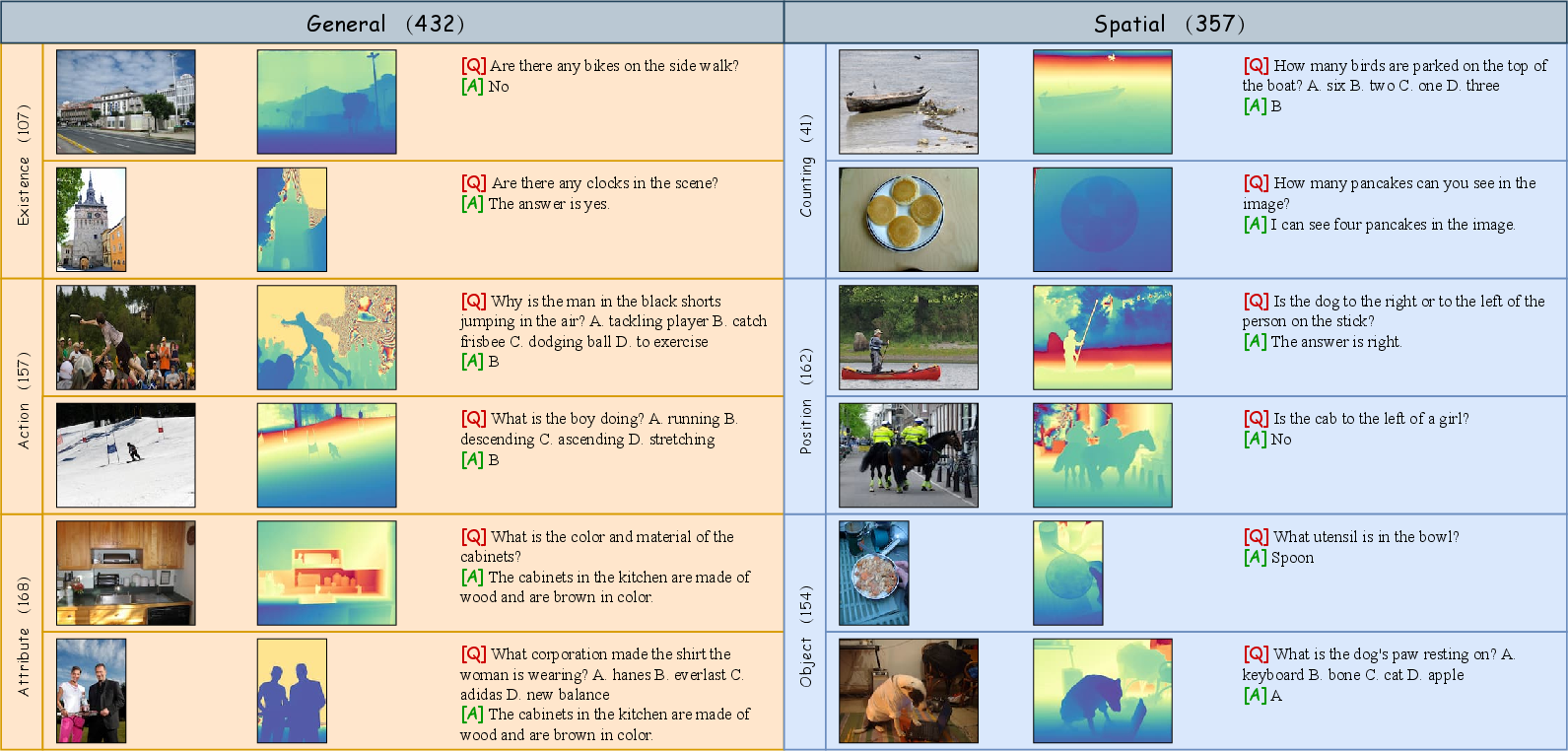
Figure 4: Examples for each task within the SSR benchmark.
Experiments and Results
Extensive experiments conducted using various benchmarks demonstrate that SSR achieves significant improvements in spatial reasoning capabilities. The integration of depth perception through rationale-guided reasoning allows VLMs to perform complex spatial tasks more effectively.
Notably, SSR models show improved performance in question-answering tasks involving spatial relationships, achieving higher accuracy and efficiency compared to existing models. These results underscore the framework's potential in enhancing the spatial comprehension of VLMs.
Conclusion
The SSR framework is a pivotal step towards advancing the spatial reasoning capabilities of Vision-LLMs. By transforming depth data into structured rationales, SSR significantly enhances the ability to understand and interpret spatial information, thereby aiding complex reasoning tasks essential for robotics and real-world applications.
The modularity and efficiency of SSR suggest broader applicability and integration opportunities for existing VLMs in various domains. Future developments may explore further sophistication of rationale representations and their potential implications in advancing AI-driven spatial reasoning.

