- The paper introduces a novel data synthesis pipeline that leverages 3D contextual extraction to create a large-scale spatial VQA dataset.
- It integrates expert models for segmentation, depth estimation, and captioning to convert 2D images into 3D spatial representations, enabling chain-of-thought reasoning.
- The SpatialVLM model outperforms state-of-the-art VLMs in qualitative (75.2%) and quantitative spatial reasoning tasks, opening new avenues for robotics applications.
SpatialVLM: Endowing Vision-LLMs with Spatial Reasoning Capabilities
Introduction
The paper "SpatialVLM: Endowing Vision-LLMs with Spatial Reasoning Capabilities" (2401.12168) addresses the limitations of Vision LLMs (VLMs) in spatial reasoning by introducing a new approach for enhancing their capabilities. Spatial reasoning, crucial for tasks such as Visual Question Answering (VQA) and robotics, remains underdeveloped in current state-of-the-art models like GPT-4V. The hypothesis presented is that these limitations are not inherent in the model architectures but rather stem from inadequate training data rich in 3D spatial knowledge. To remedy this, the paper proposes the creation of an extensive dataset featuring spatial reasoning questions derived from Internet-scale real-world images, followed by the development of a VLM pre-trained on this dataset.
Methodology
Data Synthesis Pipeline
The cornerstone of the SpatialVLM’s capability enhancement is its innovative data synthesis pipeline, designed to generate a spatial reasoning VQA dataset at an unprecedented scale:
- Semantic Filtering: Utilizing CLIP for filtering unsuitable internet images, ensuring the retention of scene-level photos essential for spatial reasoning tasks.
- 3D Contextual Data Extraction: Employing expert models for object-centric segmentation, depth estimation, and caption generation, transforming 2D images into 3D point clouds with spatial annotations.
- Ambiguity Resolution: Through clustering object captions based on CLIP similarity scores, the method ensures unambiguous question synthesis.
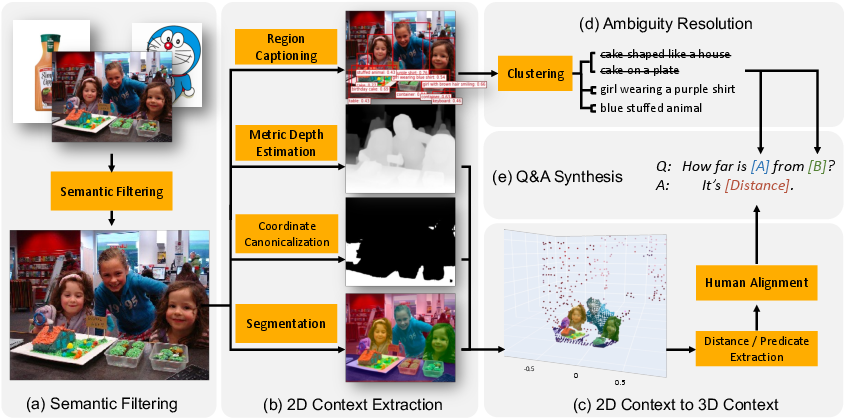
Figure 1: An overview of our data synthesis pipeline. (a) We use CLIP to filter noisy internet images and only keep scene-level photos. (b) We apply pre-trained expert models on internet-scale images so that we get object-centric segmentation, depth and caption. (c) We lift the 2D image into 3D point clouds, which can be parsed by shape analysis rules to extract useful properties like 3D bounding box. (d) We avoid asking ambiguous questions by clustering object captions using CLIP similarity score (e) We synthesize millions of spatial question and answers from object captions and extracted properties.
This pipeline results in a large-scale dataset used to pre-train the SpatialVLM model, significantly enhancing its spatial reasoning capabilities. The dataset encompasses both qualitative and quantitative spatial question-answer pairs, increasing model proficiency in tasks requiring spatial judgement and metric estimation.
SpatialVLM Model
The SpatialVLM model utilizes a mixture of traditional VLM datasets and the synthesized spatial reasoning dataset for training. Architecture-wise, it adapts the PaLM-E structure, incorporating a specialized vision encoder capable of understanding both direct spatial queries and enabling chain-of-thought reasoning by coordinating with powerful LLMs for complex spatial tasks.

Figure 2: Chain-of-thought spatial reasoning. We illustrate that we can perform Chain-of-Thought Spatial reasoning with SpatialVLM. In this example, with the help of an LLM orchestrating SpatialVLM, the system is able to answer questions like ``Does the blue coke can, the red coke can, and the green sponge on the table roughly form an equilateral triangle".
Experimental Results
The SpatialVLM demonstrates superior performance in a newly created spatial VQA benchmark with human-annotated questions evaluating qualitative and quantitative reasoning capabilities. Notably, it outperformed models like GPT-4V, PaLI, and other VLM baselines in accuracy of spatial reasoning tasks:
Unlocking New Applications
SpatialVLM extends its utility to robotics by serving as an enhanced reward generator, leveraging its spatial reasoning to annotate accurate rewards based on natural language queries. Furthermore, it demonstrates potential in complex reasoning tasks through Chain-of-Thought methodologies facilitated by an LLM interface, showcasing the capability to tackle iterative spatial problems and improve decision-making processes.

Figure 4: \smallSpatialVLM as reward generator for robotics tasks. SpatialVLM provides a natural-language queriable" distance estimation tool, and can be used for robotics tasks. For example, for the taskpick orange tea bottle", the reward/cost function can be the a function of the response of What is the distance between the yellow gripper fingers and the orange tea bottle". And for the taskput the apple into the bowl", the reward/cost function can be a function of the response of ``what is the distance between the apple and bowl". We sample different gripper positions and show the cost function in the above scatter plots.
Conclusion
The research presented in "SpatialVLM: Endowing Vision-LLMs with Spatial Reasoning Capabilities" highlights a substantial advancement in overcoming current limitations of VLMs in spatial reasoning. By leveraging a uniquely synthesized spatial VQA dataset, SpatialVLM not only enhances traditional qualitative and quantitative reasoning tasks but also opens avenues for novel applications in robotics and complex spatial problem solving. Future work might explore refining geometric and spatial nuances, further grounding VLMs in practical 3D spatial interaction contexts.
