- The paper introduces Spatial-ViLT, which integrates depth maps, 3D coordinates, and edge maps via a multi-task learning framework to enhance visual spatial reasoning.
- It details two variants, SpatialViLT and MaskedSpatialViLT, that show state-of-the-art results on tasks involving proximity, orientation, topology, and direction on the VSR dataset.
- The SpatialEnsemble approach combines outputs from different models, significantly outperforming traditional vision-language models in complex spatial configurations.
Spatial-ViLT: Enhancing Visual Spatial Reasoning through Multi-Task Learning
Introduction
"Spatial-ViLT: Enhancing Visual Spatial Reasoning through Multi-Task Learning" addresses the critical limitations in spatial reasoning capabilities of Vision-LLMs (VLMs). Although VLMs have advanced in multimodal reasoning tasks, they still face challenges when dealing with the spatial configuration of objects in 3D scenes. This paper introduces SpatialViLT, an enhanced VLM, to better integrate spatial features such as depth maps, 3D coordinates, and edge maps within a multi-task learning framework. The enhanced model includes two primary variants, SpatialViLT and MaskedSpatialViLT, with SpatialEnsemble combining both to achieve state-of-the-art results on the Visual Spatial Reasoning (VSR) dataset. This approach significantly improves AI's spatial intelligence, crucial for real-world applications.
Spatial Reasoning Challenges
Existing VLMs, like LXMERT and ViLT, significantly underperform on tasks requiring spatial understanding between objects in the VSR dataset. Despite existing approaches that incorporate datasets focused on spatial reasoning, traditional models lack robust mechanisms to comprehend and model spatial relations like proximity, orientation, and topology. The VSR dataset highlights these gaps by testing models on complex linguistic and spatial tasks, revealing deficiencies in current VLM configurations that lack spatial priors and enhanced 3D understanding.

Figure 1: Challenging spatial reasoning examples from the VSR dataset that highlight current limitations in vision-LLMs. These cases demonstrate failures in orientation understanding (airplane-truck), proximity detection in complex scenes (bus-cup), topological reasoning (cat-vase), semantic consistency (cake-dog), contact detection (plant-teddy bear), and precise spatial positioning (bed-bench).
Methodology
SpatialViLT extends the multimodal embedding space of existing VLMs with spatial priors using multi-task learning. It incorporates various spatial features—depth maps, 3D coordinates, and edge maps—through a dual-variant approach. SpatialViLT captures global spatial features, while MaskedSpatialViLT focuses on object-specific spatial relationship precisions.
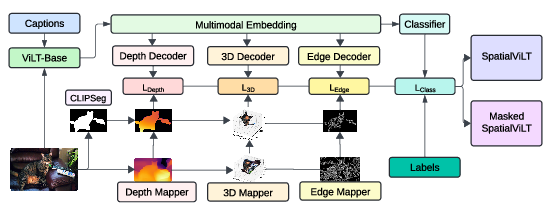
Figure 2: Framework for training SpatialViLT and Masked SpatialViLT. Captions and images are processed using ViLT (Base), with depth, 3D, and edge features extracted and decoded to calculate corresponding losses. These losses are backpropagated to improve the multimodal embeddings with spatial priors for enhanced spatial reasoning and classification.
The feature extraction pipeline comprises:
- Depth Map Creation: Leveraging MiDaS, depth maps estimate relative distances for spatial interpretation.
- 3D Coordinates: Extracted using pixel-based transformations to provide detailed object placements.
- Edge Maps: Canny edge detection accentuates object boundaries for enhanced ambient detection.
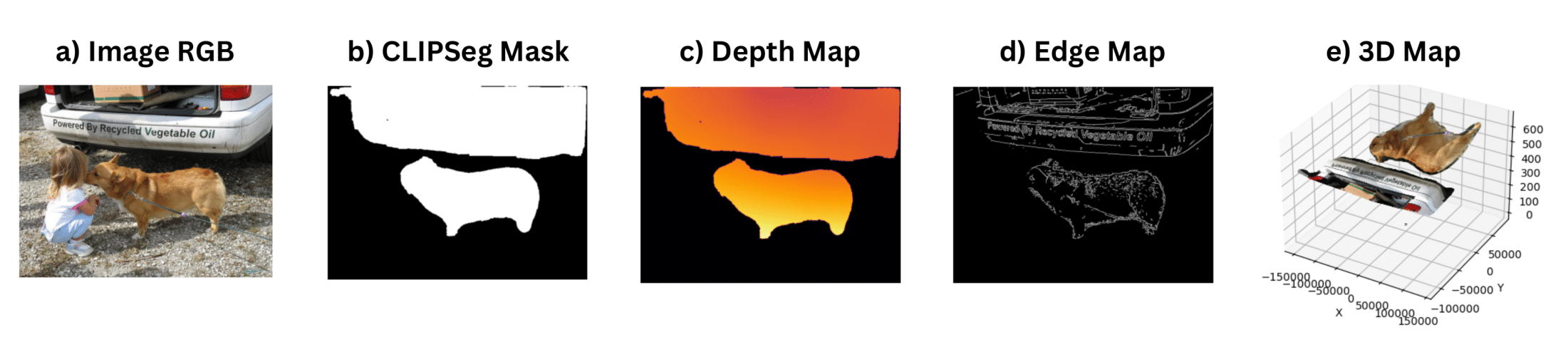
Figure 3: Feature extraction pipeline demonstrating the multi-modal spatial feature generation process: (a) Original RGB image, (b) CLIPSeg-generated object masks for "dog" and "truck" extracted from caption text, (c) MiDaS depth map showing relative distances, (d) Canny edge map highlighting object boundaries, and (e) 3D coordinate map derived from depth information.
Furthermore, SpatialViLT is structured for multi-task learning to predict spatial features and integrate these into the model's learning process.
Results and Analysis
Experiments on the VSR dataset underline the enhanced capabilities of SpatialViLT and MaskedSpatialViLT across meta-categories, outperforming state-of-the-art models. SpatialViLT excelled primarily in proximity and orientation tasks, while MaskedSpatialViLT achieved superior results on topological and directional tasks, underscoring the variants' ability to approximate spatial cues.
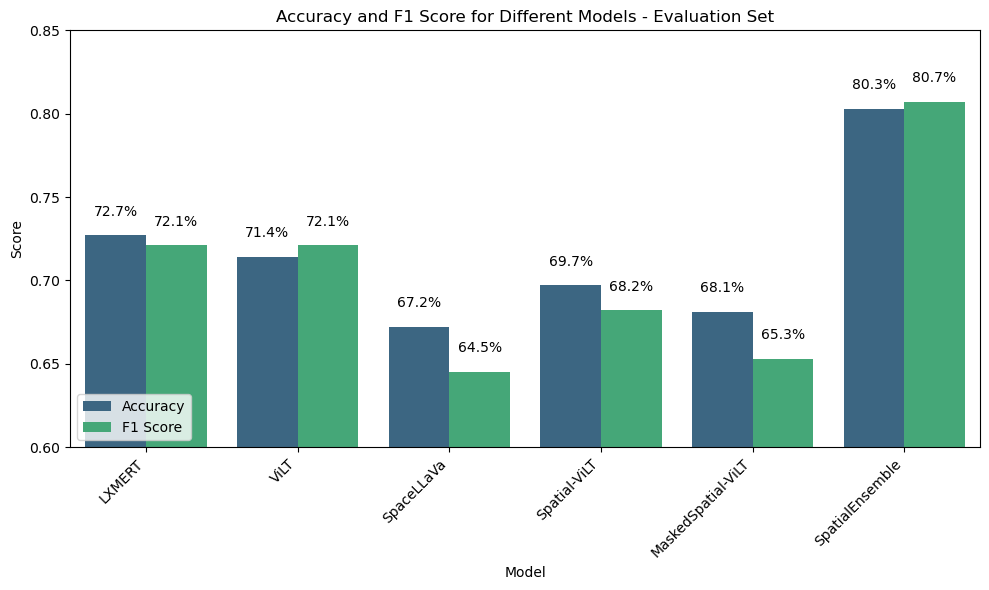
Figure 4: Accuracy and F1 Score of Different Models on the Evaluation Set.
The comprehensive SpatialEnsemble model showed enhanced performance, utilizing a weighted voting technique across models like LXMERT and ViLT. Noteworthy improvements in meta-categories like topological and directional relations validate the effectiveness of ensemble approaches.
Conclusion
The introduction of SpatialViLT and its extension through SpatialEnsemble represents notable progress in tackling spatial reasoning in Vision-LLMs. This research sets the foundation for augmenting VLMs by incorporating spatial priors and 3D understanding within a multi-task learning architecture. Future work could extend these models with pose and trajectory estimation for dynamic reasoning capabilities, thereby solving complex visual tasks that demand sophisticated spatial intelligence.