SpecDiff-2: Scaling Diffusion Drafter Alignment For Faster Speculative Decoding
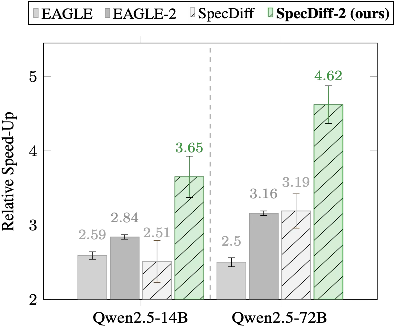
Abstract: Speculative decoding has become the standard approach for accelerating LLM inference. It exploits a lossless draft-then-verify procedure to circumvent the latency of autoregressive decoding, achieving impressive speed-ups. Yet, current speculative decoding approaches remain limited by two fundamental bottlenecks: (1) the autoregressive dependency during drafting which limits parallelism, and (2) frequent rejections of draft tokens caused by misalignment between the draft and verify models. This paper proposes SpecDiff-2, a novel framework to jointly address these two bottlenecks. It leverages discrete diffusion as a non-autoregressive drafter to address bottleneck (1) and develops novel techniques to calibrate discrete diffusion drafters with autoregressive verifiers, addressing bottleneck (2). Experimental results across a comprehensive benchmark suite show that SpecDiff-2 achieves a new state-of-the-art across reasoning, coding, and mathematical benchmarks, improving tokens-per-second by up to an average of +55% over previous baselines and obtaining up to 5.5x average speed-up over standard decoding, without any loss of accuracy.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a faster way for LLMs to generate text called SpecDiff-2. It focuses on a popular speed-up method known as speculative decoding, which uses a “small helper” model to quickly draft several tokens, and a “big main” model to check them. SpecDiff-2 solves two big problems that slow this process down and shows large speed improvements on tough tasks like math, coding, and reasoning—without losing accuracy.
What questions does the paper try to answer?
It asks:
- How can we draft multiple tokens quickly without waiting for one token at a time?
- How can we make sure the draft tokens match what the main model would produce, so fewer get rejected?
- Can we train and test the helper model in smart ways to increase the number of accepted tokens per cycle?
- Do these ideas actually make LLMs faster in real tasks while keeping answers unchanged?
How does it work? (Explained simply)
Think of two people working together:
- The “drafter” (helper) quickly writes a few words ahead.
- The “verifier” (main model) checks those words, keeps the ones it agrees with, and rejects the rest.
The paper improves both the speed and the agreement between these two.
The two main problems
- Regular drafters are slow because they write one token at a time (like a typist who can’t skip ahead).
- Drafts often get rejected because the drafter and verifier disagree too much (like a proofreader who keeps changing the writer’s words).
SpecDiff-2’s solutions
- Uses a “diffusion” drafter (non-autoregressive): Instead of typing one token at a time, the drafter fills in many tokens in parallel, like quickly sketching the whole sentence and refining it. This removes the slow dependency on earlier tokens.
- Aligns the drafter with the verifier in two ways:
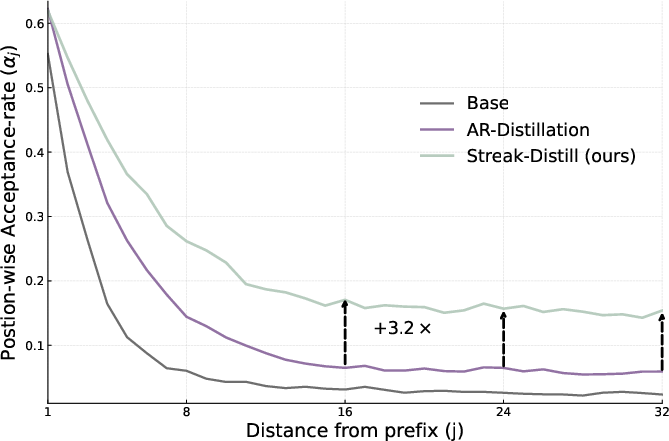
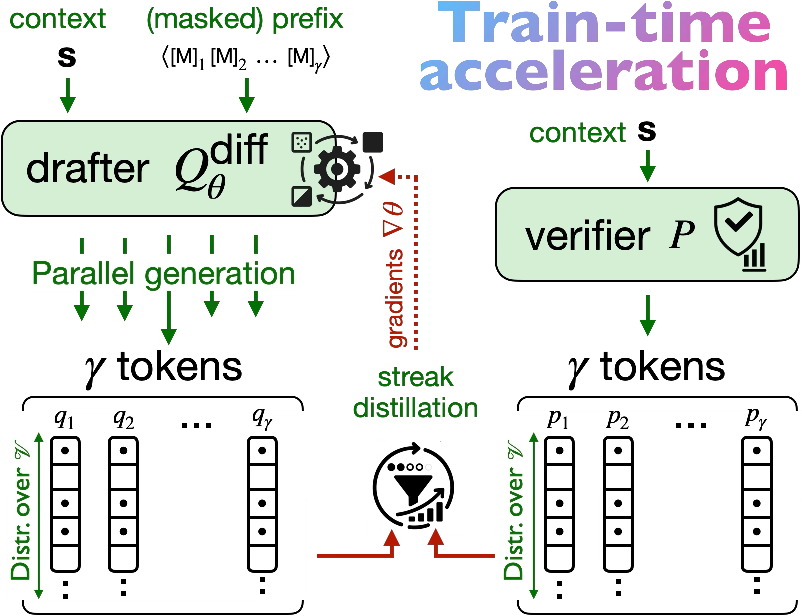
- Train-time: “Streak-distillation.” This teaches the drafter to produce long streaks of tokens that the verifier will accept. Think of training the drafter to write in the verifier’s style so more words pass without edits.
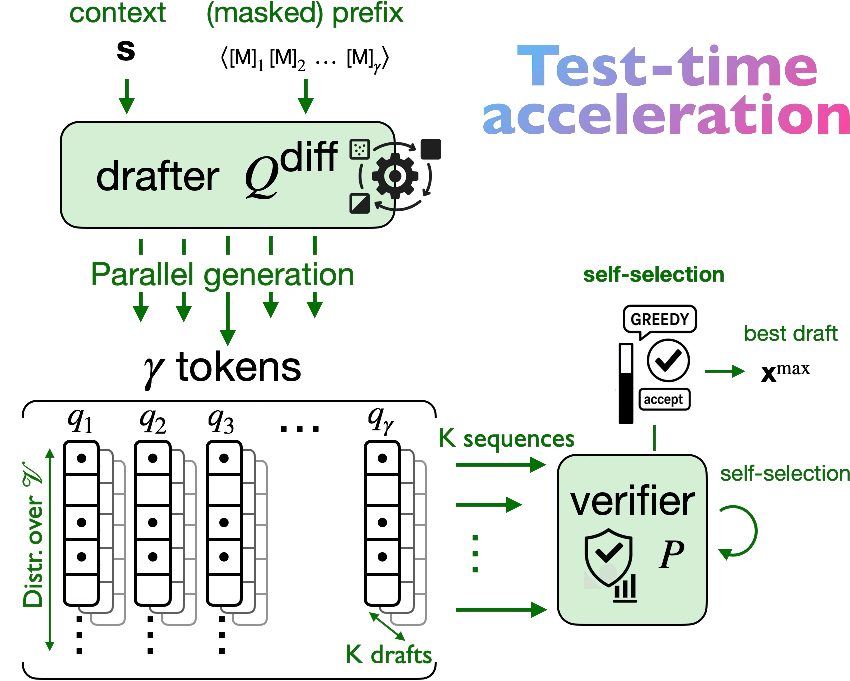
- Test-time: “Self-selection acceptance.” The drafter can quickly produce several possible drafts. The verifier scores them and picks the best one before checking token-by-token. This is like writing a few variations and the proofreader choosing the most promising draft to minimize edits.
A bit more on the techniques (in everyday terms)
- Diffusion drafting (masked discrete diffusion): Start with a block of masked tokens, then fill them in all at once with a few quick refinement steps. It’s fast and works great in parallel on modern hardware.
- Streak-distillation: Instead of only training the drafter to match the next single token, it is trained to maximize the number of consecutive tokens the verifier will accept—so the drafter learns how to write multi-token chunks in a way the verifier likes.
- Self-selection acceptance: When the drafter can cheaply generate many candidate drafts, the verifier picks the one expected to produce the longest accepted streak, then verifies it. This boosts throughput with little extra time.
What did they find, and why does it matter?
Across math, coding, and reasoning benchmarks, SpecDiff-2:
- Achieved up to 5.5× speed-up over standard (vanilla) decoding.
- Improved tokens-per-second by up to an average of +55% over previous acceleration baselines.
- Increased the average number of tokens accepted per verification cycle (longer “streaks”).
- Kept accuracy identical to the verifier (lossless decoding): the final output matches what the main model would produce.
This is important because:
- Faster generation means you can do more thinking (more chain-of-thought tokens) in the same amount of time.
- Under fixed time budgets, that extra thinking can significantly improve accuracy on hard tasks.
- The method works especially well for structured problems like math and code, where careful step-by-step generation matters.
What’s the bigger impact?
- Better time-limited reasoning: If you only have, say, 15 seconds to think, a faster pipeline lets the model produce more useful steps, which often means better answers.
- Practical scaling: Besides making models bigger, this paper shows you can “scale performance” by investing in smarter drafting and alignment—training the drafter and using test-time selection.
- Broad compatibility: Because verification stays lossless and independent of the drafter’s probability details, SpecDiff-2 can work with different tokenizers and diffusion models, making it flexible.
Summary
SpecDiff-2 speeds up LLMs by:
- Replacing slow, one-token-at-a-time drafting with fast, parallel diffusion drafting.
- Training the drafter to write longer stretches that the verifier will accept.
- Letting the verifier pick the best of several drafts before checking.
The result is faster text generation with no accuracy drop, especially helpful for math, coding, and reasoning tasks—letting models think more in the same time and perform better under tight deadlines.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of unresolved issues and concrete directions for future work that arise from the paper’s methods, analyses, and claims.
- Distributional faithfulness of “greedy acceptance” and self-selection:
- Provide a formal, sequence-level proof that self-selection followed by the proposed greedy acceptance (accept with probability and replace from the normalized residual of ) preserves exact equivalence to vanilla decoding from for all , , and prefixes—not just position-wise. Clarify conditions under which ignoring remains lossless.
- Compare theoretically and empirically the acceptance rule used here to the standard SD rule , including cases where is well-aligned (potentially enabling higher acceptance than ) and quantify any lost acceptance under greedy acceptance.
- Complexity and scaling analysis of self-selection:
- Quantify end-to-end latency, memory, and energy costs of ranking drafts (computing ) versus speed-up gains; provide a break-even analysis for and across different sequence lengths and hardware (single vs multi-GPU).
- Detail the implementation and resource profile of tree-style attention used to score candidates; include time/memory scaling curves and practical limits (e.g., maximum or before diminishing returns).
- Window size and position-wise alignment:
- Systematically ablate draft window size and report how and throughput change with ; determine optimal for diffusion drafters and whether gains persist for longer windows or degrade due to joint-generation miscalibration.
- Robustness across tasks and distributions:
- Evaluate on broader domains (multilingual, long-context summarization, dialogue, tool-use/function-calling, code repair) to test generalization of train/test-time alignment beyond Math500, HumanEval, and GPQA.
- Characterize failure modes in high-entropy or creative writing tasks where verifier posteriors are diffuse and draft variance increases, and quantify acceptance degradation.
- Cross-tokenizer scenarios:
- Empirically validate cross-tokenizer support claimed for greedy acceptance when and use different vocabularies; document edge cases (e.g., mismatched segmentation, rare tokens) and any impact on acceptance/throughput.
- Drafter temperature and draft variance:
- Study sensitivity of self-selection performance to drafter temperature and propose adaptive, prefix-dependent temperature schedules (e.g., using verifier entropy or uncertainty) to balance draft diversity and acceptance.
- Number of diffusion steps:
- Analyze trade-offs between number of denoising steps, draft quality, and latency; provide guidance on when single-step drafting suffices and when multi-step is beneficial, including theoretical or empirical criteria.
- Optimization stability of streak-distillation:
- Investigate whether the product-of-probabilities objective causes vanishing gradients or instability for large and small ; report stabilization tricks (e.g., log-space optimization, temperature scaling, smoothing) and their effects.
- Training compute, data, and reproducibility:
- Provide detailed finetuning compute budgets (GPU hours), data composition, and sampling strategy used for streak-distillation; include learning curves and ablations (steps, batch size) to support claims of generalization beyond finetuning data.
- Release code and exact training configurations to make results reproducible, especially given reported difficulties reproducing EAGLE-3.
- Theoretical link to TV reduction:
- Derive bounds connecting the proposed streak-distillation objective to actual acceptance under the true SD rule (not the greedy proxy), and clarify how/when streak optimization approximates minimizing total variation across the full draft window.
- Efficient computation and caching:
- Describe how candidate scoring () and subsequent verification reuse cached logits to avoid recomputation; quantify savings and identify optimal caching strategies for large .
- Adaptive K and γ at test-time:
- Explore policies that choose and per-prefix based on verifier uncertainty or predicted throughput (e.g., increase when is peaky), and evaluate benefits vs. overhead.
- Comparative baselines and coverage:
- Compare against additional acceleration baselines (e.g., Medusa, spec-decoder variants for Recurrent/Mamba, other non-AR drafting like edit-based methods) to contextualize gains beyond EAGLE/EAGLE-2 and SpS.
- Large-scale and quantized verifiers:
- Test scaling to larger verifiers (100B+) and quantized deployments (AWQ/GPTQ) to assess practical throughput gains under memory-bandwidth constraints and real serving environments.
- Streaming and production integration:
- Evaluate behavior under streaming generation (token-by-token delivery), mixed workloads, and server-side batching; quantify how self-selection and draft ranking interact with production schedulers and latency SLAs.
- Statistical robustness:
- Report variance, confidence intervals, and seed sensitivity for speed-ups and acceptance metrics; assess stability across prompts and datasets, especially for test-time compute scaling curves.
- Long-sequence behavior:
- Study how diffusion drafting and streak-distillation perform on very long sequences and long CoT traces; analyze whether alignment decays with distance from prefix and propose remedies.
- Downstream correctness under time budgets:
- Investigate whether accelerating early tokens systematically biases partial CoT trajectories (due to truncation by time budget) even if outputs are distributionally faithful under ; quantify any such bias on reasoning correctness.
- Integration with tool-use and function calling:
- Assess whether self-selection and diffusion drafting remain effective when outputs must satisfy constrained formats (e.g., JSON functions), and how verifier-calibrated selection behaves with strict schema compliance.
- Energy and cost accounting:
- Include energy use and cost-per-token metrics to complement tokens-per-second, enabling informed trade-offs between added test-time ranking compute and throughput gains.
Glossary
- Acceptance rate: The probability that drafted tokens will be accepted during speculative decoding, controlling realized speed-up. "The acceptance rate governs the realized speed-up in draft-then-verify decoding."
- Accelerator-friendly batching: Parallel computation style that exploits hardware (e.g., GPUs) by processing many positions simultaneously. "it eliminates the token-by-token dependency of autoregressive drafting, exploits accelerator-friendly batching"
- Autoregressive (AR): A modeling approach that generates tokens sequentially, each conditioned on previous tokens. "LLMs, being predominantly based on autoregressive (AR) architectures, produce tokens sequentially"
- Bernoulli: A binary random variable distribution used to model acceptance decisions. ""
- Causal prefixes: Past tokens that condition the next-token distribution in AR models under causal masking. "autoregessive models learn local next-token conditionals tied to causal prefixes."
- Chain-of-thought (CoT): A prompting strategy that elicits step-by-step reasoning before the final answer. "long chain-of-thought reasoning"
- Denoising step: An iteration in diffusion models that refines corrupted tokens toward fluent sequences. "Each denoising step updates all token positions in parallel"
- Diffusion LLMs (DLMs): LLMs that generate sequences via iterative diffusion/denoising rather than AR token-by-token generation. "leverages diffusion LLMs (DLMs) as non-autoregressive drafters"
- Discrete diffusion: A diffusion process over token space using categorical corruption/denoising. "It leverages discrete diffusion as a non-autoregressive drafter"
- Distributionally faithful: A property ensuring the final output matches the verifier’s distribution despite drafting/acceptance shortcuts. "These rules are distributionally faithful: the final transcript matches vanilla decoding from while enabling parallel proposal and verification"
- Drafter–verifier alignment: Calibration between the drafter’s proposals and the verifier’s preferences to maximize acceptance. "the drafter-verifier alignment, since misaligned proposals are likely to be rejected"
- Draft-then-verify: The speculative decoding paradigm where a small model proposes tokens and a larger model verifies and accepts them. "a draft-then-verify procedure"
- Expected accepted streak: The expected number of consecutive drafted tokens that will be accepted in one cycle. "align diffusion drafters to the verifier in a manner that directly improves the expected accepted streak in"
- Greedy acceptance: A proxy acceptance scheme using verifier probabilities directly to yield a smooth training signal. "The construction begins with a proxy for acceptance, greedy acceptance, that yields a smooth training signal."
- Joint distribution: A probability distribution over entire sequences, as modeled by diffusion drafters. "Diffusion models learn a joint distribution over entire sequences through denoising trajectories"
- Lossless acceptance rule: The standard acceptance criterion that guarantees outputs match vanilla decoding. "Tokens are committed left-to-right using the standard lossless acceptance rule"
- Masked cross-entropy: A training loss applied only to masked positions during diffusion denoising. "and is trained with masked cross-entropy over the currently masked set "
- Masked diffusion models (MDMs): Discrete diffusion models that use a special MASK token to corrupt positions independently. "In masked diffusion models (MDMs)"
- Next-token posteriors: The conditional probability distributions over the next token given a prefix. "the models expose next-token posteriors and "
- Non-autoregressive drafter: A drafter that proposes multiple tokens in parallel without sequential dependencies. "leverages discrete diffusion as a non-autoregressive drafter"
- Normalized residual: The distribution over replacement tokens proportional to the verifier’s mass not covered by the drafter at a rejection point. "a replacement is drawn from the normalized residual:"
- Position-wise acceptance: The probability that the j-th drafted token is accepted conditional on earlier acceptances. "Let denote the position-wise acceptance"
- Product-of-accepts identity: The identity expressing expected accepted tokens as a sum over products of position-wise acceptances. "Under the standard product-of-accepts identity, the expected number of committed tokens from a draft of length is:"
- Self-consistency: An inference-time technique that samples multiple reasoning paths and aggregates to improve accuracy. "self-consistency"
- Self-selection acceptance: A test-time mechanism that samples multiple drafts and uses the verifier to select the one maximizing expected throughput before verification. "a test-time acceptance mechanism, called self-selection acceptance"
- Speculative decoding (SD): An acceleration framework using a small drafter and large verifier to accept multiple tokens per cycle. "Speculative decoding (SD) algorithms are built on two LLMs, a small drafter model , and a heavier target verifier "
- Streak-distillation: A train-time alignment objective that directly optimizes the expected accepted streak across the draft window. "it develops streak-distillation, a novel train-time alignment method that encourages the drafter to produce long streaks of accepted tokens"
- Test-time compute scaling: Increasing inference-time computation (e.g., longer reasoning) to improve accuracy under fixed model parameters. "the emergence of test-time compute scaling"
- Tokens-per-second (TPS): A throughput metric measuring the rate of token generation during inference. "improving tokens-per-second by up to an average of "
- Total-variation distance (TV): A divergence measure between drafter and verifier distributions inversely related to acceptance rate. "the total-variation distance (TV) between and "
- Tree-style attention: An efficient attention computation strategy used to score multiple candidate drafts in parallel. "via tree-style attention"
- Throughput: The effective rate of accepted tokens, determining overall speed-ups in speculative decoding. "Thus, the realized throughput hinges on increasing {the expected acceptance per cycle} while keeping {drafter cost low} relative to the verifier."
- Verifier: The larger, accurate model that evaluates drafted tokens and decides acceptance. "a heavier verifier model evaluates the proposal in parallel to accept the longest matching sequence."
- Wall-time latency: The real-world elapsed time during inference, constrained by sequential decoding or long reasoning chains. "these gains are obtained at the cost of higher wall-time latency"
Practical Applications
Summary
The paper introduces SpecDiff-2, a speculative decoding framework that uses discrete diffusion LLMs (DLMs) as non-autoregressive drafters and aligns them with autoregressive (AR) verifiers through two key innovations: (1) streak-distillation (a train-time objective that maximizes expected accepted streak length), and (2) self-selection acceptance (a test-time mechanism that ranks multiple diffusion drafts with the verifier to maximize throughput). The system achieves up to 5.5× speed-ups over standard decoding and on average +55% throughput over prior speculative decoding baselines, with lossless outputs identical to the verifier. It is particularly effective on structured reasoning and coding tasks, and compounds test-time compute (e.g., chain-of-thought) advantages under fixed wall-time budgets.
Below are actionable, sector-linked applications, with immediate vs. long-term categorization, and key assumptions/dependencies for feasibility.
Immediate Applications
These applications can be implemented now using available LLMs, inference servers, and existing training fine-tuning pipelines.
- Faster, lossless LLM serving for latency-critical chat and agentic applications [Software/Cloud, Customer Support, Productivity]
- What: Drop-in acceleration for existing AR verifiers (e.g., Qwen2.5, LLaMA) using a diffusion drafter and SpecDiff-2’s train/test alignment to cut response latency without changing model outputs.
- Tools/products/workflows:
- Integrate a SpecDiff-2 backend into serving stacks like vLLM, TensorRT-LLM, TGI, or Ray Serve.
- Expose “acceleration-compute” knobs (K drafts, window size γ, drafter temperature, diffusion steps) in service configs and autoscaling policies.
- Add online telemetry for acceptance rate and average accepted streak; autoscale K or temperature based on live acceptance metrics.
- Assumptions/dependencies:
- Access to a pretrained diffusion LM drafter compatible with the verifier (e.g., DiffuLLaMA-7B for LLaMA-2, DiffuCoder-7B for Qwen2.x).
- Sufficient GPU memory to cache verifier logits for K drafts; tree-style attention kernels or equivalent to score drafts efficiently.
- Inference infra supports concurrent verifier scoring for self-selection at acceptable cost.
- Higher-throughput code assistants and CI automation [Software Engineering, DevTools]
- What: Use DiffuCoder as a drafter and a strong AR code verifier to speed up autocomplete, test generation, and refactoring suggestions with identical verifier outputs.
- Tools/products/workflows:
- IDE plugin backend uses SpecDiff-2 with K multi-drafts and streak-distillation fine-tuned on in-house repositories to maximize acceptance on a target codebase.
- CI steps (e.g., unit test synthesis, docstring completion) run as batch jobs with speed-ups for the same quality.
- Assumptions/dependencies:
- Domain fine-tuning data for streak-distillation (e.g., internal repos) to increase acceptance rates on company-specific code style/stack.
- GPU memory for verifier scoring in the IDE server; streaming-friendly implementation.
- Time-budgeted chain-of-thought (CoT) reasoning under SLAs [Education, Finance, Legal, Analytics]
- What: For workflows that cap reasoning time (e.g., 10–20s budgets), SpecDiff-2 yields more thought tokens per second, improving answer accuracy without changing verifier quality.
- Tools/products/workflows:
- “Think-then-decide” pipelines (CoT, self-consistency) with a hard time cutoff that trigger “wrap up” prompts; use SpecDiff-2 to maximize tokens generated before cutoff.
- A/B testing shows accuracy gains vs. vanilla decoding at equal wall-time.
- Assumptions/dependencies:
- Tasks benefit from more intermediate reasoning tokens (e.g., math, coding, structured analysis).
- Acceptance rates remain robust on the domain distribution (streak-distillation on representative prompts recommended).
- Lower-cost enterprise Q&A and RAG generation at scale [Enterprise Software, Knowledge Management]
- What: Reduce compute per answer for retrieval-augmented generation and enterprise knowledge Q&A without altering answers or safety profiles (lossless acceptance).
- Tools/products/workflows:
- SpecDiff-2 as an accelerator behind RAG pipelines; adopt K self-selection for predictable throughput per request.
- Monitoring dashboards show cost-per-token and acceptance distribution by query type; dynamic K per domain/topic.
- Assumptions/dependencies:
- Verifier’s outputs are the desired ground truth for governance/safety; acceleration does not change content, simplifying compliance.
- Slight increase in engineering complexity to integrate draft ranking and caching.
- Batch synthetic data and labeling pipelines [ML Ops, Data Engineering]
- What: Speed-up large-scale text generation (e.g., CoT rationales, Q/A pairs) used to pretrain or distill models.
- Tools/products/workflows:
- Use SpecDiff-2 in data generation clusters; schedule K based on cluster load and acceptance telemetry.
- Assumptions/dependencies:
- Batching-friendly memory and attention kernels; minimal I/O overhead to avoid negating speed-ups.
- Quantitative monitoring and acceptance-aware serving [ML Ops]
- What: Operate acceptance-rate and accepted-streak as first-class serving KPIs to guide runtime adaptation (e.g., adjust drafter temperature, K) for best throughput.
- Tools/products/workflows:
- Add acceptance/streak logging to tracing/observability (e.g., OpenTelemetry).
- Runtime controller: if acceptance dips (domain shift), lower K and/or raise temperature; if acceptance rises, increase K to harvest throughput.
- Assumptions/dependencies:
- Verifier-side scoring of multiple drafts; light-weight policy for control-loop stability.
- Low-latency AI assistance in end-user tools [Productivity Apps, Daily Life]
- What: Faster email drafting, spreadsheet analysis explanations, and writing assistance without loss in quality.
- Tools/products/workflows:
- SpecDiff-2-enabled backend in productivity suites; preserve streaming UX while lowering perceived latency.
- Assumptions/dependencies:
- Server-side hosting (verifiers are large); end-user devices connect to accelerated inference endpoints.
Long-Term Applications
These require further research, scaling, or engineering investments (e.g., training drafters, hardware kernels, new modalities).
- Domain-specialized diffusion drafters and acceptance-aware routers [Healthcare, Legal, Finance]
- What: Train multiple domain DLM drafters (medical notes, contracts, financial filings) and route queries to the best-matched drafter to boost acceptance and speed.
- Tools/products/workflows:
- “Mixture-of-drafters” router using acceptance forecasts; streak-distillation per domain; compliance-preserving, lossless verification by a single audited AR verifier.
- Assumptions/dependencies:
- High-quality domain corpora and compute for DLM pretraining/fine-tuning; robust acceptance metrics under distribution shift.
- Cross-tokenizer and cross-model drafting [Systems, Model Interop]
- What: Use drafters with differing tokenizers or architectures from the verifier (e.g., compact diffusion drafters for very large AR verifiers).
- Tools/products/workflows:
- Token-level mapping or detokenize/retokenize bridges; acceptance that relies only on verifier probabilities (as in SpecDiff-2) to relax drafter calibration needs.
- Assumptions/dependencies:
- Practical and accurate token mapping across vocabularies; careful handling of segmentation differences (merges/splits) to keep verification lossless.
- Multimodal speculative drafting (text+vision+speech) [Multimodal AI, Robotics]
- What: Extend diffusion drafters to multimodal tokens (e.g., VQ image tokens, audio tokens) and verify with AR multimodal models for accelerated captioning, planning, or dialog with perception.
- Tools/products/workflows:
- Masked discrete diffusion over multimodal token streams; streak-distillation generalized to modality-conditioned windows; self-selection with tree-scored multimodal verifiers.
- Assumptions/dependencies:
- Mature multimodal DLMs; efficient attention kernels for tree scoring across modalities; stable lossless acceptance rules for multimodal sequences.
- Hardware and kernel co-design for masked diffusion + tree-style scoring [MLSys, Cloud]
- What: Custom kernels for parallel masked denoising and K-draft verifier scoring to reduce memory bandwidth and latency.
- Tools/products/workflows:
- Fused attention with caching across K drafts; tensor-parallel scoring trees; memory-aware schedulers that keep K bounded per GPU.
- Assumptions/dependencies:
- Vendor support (CUDA/Triton/XLA) and library integration; profiling to avoid dispatcher overheads that erode speed gains.
- Adaptive “acceleration-compute” governance and SLAs [Policy, Cloud Economics]
- What: Treat acceleration compute (streak-distillation budget, K at inference) as a controllable resource with measurable energy and cost impacts.
- Tools/products/workflows:
- SLAs specifying maximum latency and “acceleration budget”; carbon-aware schedulers increase K when renewable energy is abundant; billing tiers reflect acceleration benefits.
- Assumptions/dependencies:
- Standardized efficiency metrics (accepted-streak, tokens-per-second) in industry benchmarks; reliable energy telemetry.
- Edge and on-device acceleration for smaller verifiers [Mobile, Embedded]
- What: Use compact AR verifiers (e.g., 3B–7B) with tiny diffusion drafters for low-latency on-device assistants.
- Tools/products/workflows:
- Quantized diffusion drafters; streak-distillation on-device domains (SMS, notes); K scaled to device constraints; partial verification offloaded to edge servers when available.
- Assumptions/dependencies:
- Efficient quantization and memory-aware draft ranking; hybrid cloud–edge orchestration.
- Robustness, safety, and compliance with lossless acceleration [Safety, Governance]
- What: Because outputs match the verifier exactly, organizations can decouple safety governance (verifier-centric) from performance (drafter-centric).
- Tools/products/workflows:
- Formal verification that acceptance remains lossless under all settings; safety evaluations focused on the verifier; separate audits for acceleration telemetry and controls.
- Assumptions/dependencies:
- Strong invariance guarantees (no acceptance-rule regressions); reliable fallback to vanilla decoding on anomalies.
- Research integrations: self-consistency, debate, tool-use, and planning at scale [Academia, Advanced AI Systems]
- What: Accelerate sampling-heavy inference-time methods (self-consistency, multi-agent debate, tool-augmented planning) by increasing usable tokens per second.
- Tools/products/workflows:
- SpecDiff-2 wrappers for multi-sample CoT, program-of-thoughts, and toolformer-style pipelines; K tuned per method; streak-distillation on method-specific trajectories.
- Assumptions/dependencies:
- Careful budgeting to ensure verifier-scoring overhead doesn’t dominate; method-specific acceptance characteristics understood and monitored.
Notes on Feasibility and Dependencies
- Compute/memory: Self-selection requires scoring K drafts per window; although draft sampling is cheap, verifier scoring can be memory- and latency-bound without optimized kernels and caching.
- Data for alignment: Streak-distillation benefits from domain-representative prompts; misaligned domains may see reduced acceptance and weaker gains (especially in open-ended generation).
- Drafters: Availability of high-quality diffusion drafters aligned to verifier tokenizers accelerates adoption. Cross-tokenizer operation may require reliable token bridging.
- Stability/robustness: Gains are strongest on structured outputs (code, math). For open-ended creative tasks, acceptance may drop; dynamic control of K and temperature mitigates regressions.
- Observability: Production systems should log acceptance and accepted-streak distributions and implement safe fallbacks to vanilla decoding when acceptance degrades.
- Lossless equivalence: SpecDiff-2 is designed to be distributionally faithful (final outputs identical to the verifier), simplifying safety and compliance—this assumption must be preserved in any engineering adaptation.
In summary, SpecDiff-2 enables a practical new axis—“acceleration-compute”—to scale real-world LLM systems, immediately improving latency and cost for structured and reasoning-heavy workloads, while setting the stage for domain-specialized, multimodal, and hardware-optimized advances in the longer term.
Collections
Sign up for free to add this paper to one or more collections.