Not-a-Bandit: Provably No-Regret Drafter Selection in Speculative Decoding for LLMs
Abstract: Speculative decoding is widely used in accelerating LLM inference. In this work, we focus on the online draft model selection problem in speculative decoding. We design an algorithm that provably competes with the best draft model in hindsight for each query in terms of either the token acceptance probability or expected acceptance length. In particular, we show that we can accurately evaluate all draft models, instead of only the chosen model without incurring additional queries to the target model, which allows us to improve exponentially over the existing bandit-based approach as the number of draft models increases. Our approach is generically applicable with any speculative decoding methods (single draft, multi-drafts and draft-trees). Moreover, we design system-efficient versions of online learners and demonstrate that the overhead in computation and latency can be substantially reduced. We conduct extensive experiments on open-source LLMs and diverse datasets, demonstrating that our methods substantially outperform the state-of-the-art EAGLE3 and the BanditSpec baseline in a variety of domains where specialized domain-expert drafters are available, especially when long reasoning chains are required.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making big LLMs respond faster. It focuses on a speed-up trick called “speculative decoding,” where a small helper model (a “drafter”) quickly guesses several next words, and the big main model (the “target”) checks those guesses. If the guesses are right, the system accepts multiple words at once, saving time.
The problem the paper solves: when you have many different helper models, which one should you pick for each new user question to get the most speed without hurting quality?
The authors introduce a method called “HedgeSpec” that smartly picks the best helper for each request and proves it performs almost as well as the best possible choice you could have made if you knew the future.
What questions does the paper ask?
- Given a pool of different helper models (drafters), can we automatically choose the best one for each user question?
- Can we do this without wasting time “exploring” bad helpers?
- Can we guarantee (prove) that our choices won’t be much worse than the best helper in hindsight?
- Will this approach work with different speculative decoding styles (single helper, multiple helpers, or “draft trees”)?
- Does it actually make LLMs faster in real tests?
How does the method work?
Speculative decoding in plain words
Think of writing with a partner:
- The small helper (drafter) quickly writes a few words ahead.
- The main editor (the big LLM) checks those words at once.
- If the helper’s words match what the editor would have written, you keep them and save time. If not, you fix the mistake and continue.
Two key ideas help measure performance:
- Acceptance probability: how often a drafter’s next word matches the editor.
- Acceptance length: how many words in a row the drafter gets right before a mismatch.
Higher acceptance = fewer slow checks by the big LLM = faster replies.
The challenge: picking the right helper
Different helpers are good at different things:
- A helper trained on code might be great for programming tasks but bad for news summaries.
- A helper trained on medical questions might be great there but weak on math.
So, for every new question, we want to pick the helper that will most likely guess correctly for that question’s topic.
Bandits vs full information (slot machines vs seeing everything)
Past work treated this like a “multi-armed bandit” game:
- Imagine several slot machines (helpers). Each time you try one, you only learn how that one did.
- You need to balance “exploration” (trying different helpers) and “exploitation” (using the best helper you’ve found).
This paper makes a surprising observation:
- In speculative decoding, you don’t need to “explore” the helpers one-by-one.
- With a single checked run from the big LLM, you can compute how all helpers would have done—without asking the big LLM any extra questions.
In other words, this is “not-a-bandit.” It’s full information: you can get feedback for every helper each time.
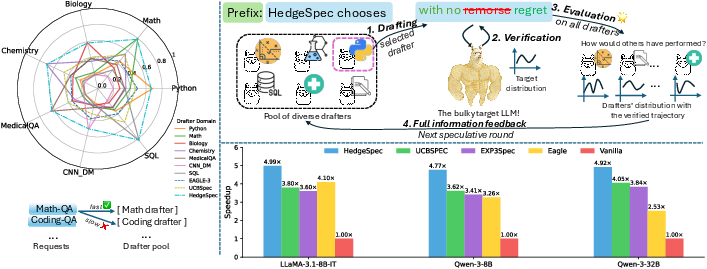
HedgeSpec: the core idea
- After the big LLM checks a chunk of words, the system “prefills” that same text into every helper and quickly computes how likely each helper would have matched the big LLM at each step.
- With this “panoramic feedback,” the method updates weights for each helper: helpers that did well get more weight; helpers that did poorly get less.
- It uses well-known learning algorithms (like Hedge or NormalHedge) that are designed to perform nearly as well as the best choice over time (“no-regret” learning).
- A clever estimator lets the system estimate “how many words in a row this helper would have gotten right” using probabilities, all from that single checked run. No extra big LLM calls needed.
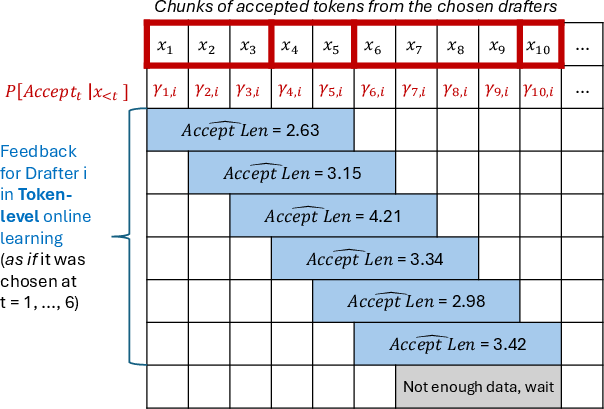
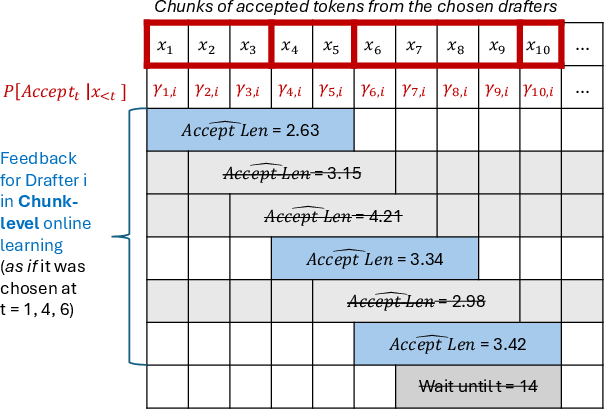
Handling delays and different drafting styles
- The feedback arrives in chunks (after the big LLM finishes checking), so the method deals with “delayed feedback” carefully and still learns fast.
- It works with different speculative decoding setups:
- Single helper drafting.
- Multiple helpers drafting.
- “Draft trees” (like EAGLE models) that build several likely next-word paths.
What did they find, and why is it important?
Here are the main takeaways, explained simply:
- HedgeSpec is faster and more efficient across many tasks.
- It beat strong baselines like EAGLE-3 (a widely used drafting system) and BanditSpec (which uses bandit-style selection).
- On some tasks (like SQL with Qwen models), HedgeSpec increased speed by up to about 83.7% tokens per second and accepted far more tokens in a row.
- Across mixed workloads, it achieved about a 46.1% average speedup.
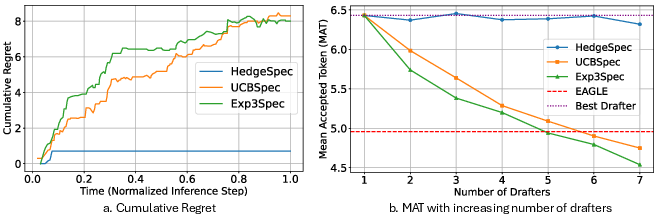
- It scales better when you have more helpers.
- Bandit-style methods get slower when you add more helpers (they need more exploration).
- HedgeSpec uses full information, so it quickly finds the best helper even among many options.
- The overhead is tiny.
- Evaluating all helpers after one big LLM check is very cheap (like checking lots of small calculators after one big calculation).
- Even a small boost in accepted tokens per chunk pays for the evaluation cost many times over.
- It’s robust to unexpected inputs.
- A “static router” (a pre-trained classifier that picks a helper based on the text) can break when the phrasing changes or the question is out-of-distribution.
- HedgeSpec adapts on the fly using live feedback, so it stays effective even when queries look different than training data.
- It has solid theory behind it.
- The authors prove “no-regret” guarantees: over time, HedgeSpec performs almost as well as the best helper you could have picked with perfect hindsight.
- Its learning quality depends only lightly on the number of helpers (logarithmically), which is much better than bandits as the pool grows.
Why does this matter?
- Faster AI responses: By accepting more tokens per check, the system calls the big LLM less often, reducing latency and cost.
- Smarter helper choice: Automatically picking the best helper for each question means consistent performance across diverse topics (math, code, biology, etc.).
- Scalable serving: Works well even with lots of specialized helpers—useful for cloud systems serving many domains.
- Robust in the real world: Handles new or unexpected prompts without breaking, because it learns from what happens during generation (not just from training labels).
- Broadly applicable: The idea plugs into any speculative decoding setup, including popular systems like EAGLE-3.
In short, HedgeSpec makes LLMs faster and more reliable by turning helper selection from a guessing game into a smart, data-driven process that uses all available feedback—without extra costly checks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes what remains missing, uncertain, or unexplored in the paper, framed as concrete items actionable for future research:
- Quantify and model the variance (not just unbiasedness) of the acceptance-length estimator, and develop confidence-aware updates (e.g., variance-weighted losses, robust learning rates) to stabilize learning under noisy prefixes.
- Tighten regret bounds for the EAL objective under delayed full-information feedback; characterize constants and dependence on K, L, and drafter distributions, and establish matching lower bounds.
- Provide formal guarantees under non-iid, non-stationary (Markovian or adversarial) prefix distributions induced by real-world prompts and multi-turn interactions, rather than relying on heuristic stochastic assumptions.
- Extend the full-information estimator and proofs to randomized draft-tree growth and dynamic pruning policies (e.g., EAGLE-2 variants), including how gamma computation changes when the candidate set depends on stochastic pruning.
- Incorporate drafter-specific computational costs and memory footprints into the objective (cost-aware selection), and analyze trade-offs between acceptance gains and evaluation overhead when drafters are heterogeneous.
- Systematically evaluate scalability of HedgeSpec’s evaluation phase for large N (e.g., 50–200 drafters), including GPU memory pressure, data movement, kernel scheduling, and inter-drafter parallelism limits.
- Measure and optimize tail latency (P95/P99) and request-level QoS under HedgeSpec, not just average token/s and MAT; assess whether frequent drafter switching increases tail latency.
- Conduct comprehensive non-greedy decoding studies (varying temperature, top-p, repetition penalties) to quantify how sampling settings affect gamma estimation, learning stability, and end-to-end throughput.
- Analyze and optimize switching granularity (per-token vs per-chunk vs per-turn), including the system cost of frequent drafter changes and policies that constrain switching to reduce overhead.
- Generalize and validate the full-information feedback mechanism for other speculative decoding methods (e.g., Medusa, multi-drafter concurrent schemes), with explicit gamma formulations and estimator correctness.
- Investigate adaptive control of speculative parameters (K depth, L branching) jointly with drafter selection, including learning policies to set K/L per-prefix to balance acceptance and latency.
- Study robustness to distribution shift in a principled way (benchmarks, controlled OOD perturbations), and develop methods to detect OOD prefixes and adjust learning dynamics (e.g., exploration boosts, fallback policies).
- Develop and evaluate hybrid routers that combine offline classifiers (warm start) with online HedgeSpec updates, including safe handoff mechanisms and safeguards against misrouting under OOD prompts.
- Characterize sensitivity to target-model changes (quantization levels, batching, caching, fine-tuning mid-serving) and whether HedgeSpec retrains or adapts fast enough to maintain no-regret under such shifts.
- Provide correctness/quality metrics (e.g., pass@1 on HumanEval, GSM8K accuracy, BLEU/ROUGE for summarization) to empirically validate that HedgeSpec’s acceleration does not inadvertently affect output quality in real deployments.
- Explore privacy/security implications of evaluating all drafters (e.g., potential side channels, malicious drafters) and design defenses for adversarial drafters intended to game the selection process.
- Evaluate multi-tenant and high-concurrency settings (batch sizes >1, request multiplexing) to quantify interference between drafter evaluations and target verification, and propose scheduling policies that preserve throughput gains.
- Provide a thorough breakdown of the end-to-end overhead beyond per-forward timing (e.g., memory bandwidth, KV-cache interactions, prefix prefill costs for long contexts), and quantify when overhead negates acceptance gains.
- Examine the impact of extremely long generations (thousands of tokens) on learning stability, delay handling, memory use, and estimator accuracy; propose adaptations for long-horizon scenarios.
- Compare NormalHedge to other expert algorithms (AdaHedge, Squint, Tsallis-INF) under delayed full-information feedback with EAL losses, and determine if any yield faster or more stable convergence.
- Validate full-information gamma computation for EAGLE under different token ranking ties, temperature-invariant configurations, and dynamic-pruning thresholds; document edge cases where rankings are unstable.
- Investigate automated drafter discovery/curation (e.g., clustering prompts, meta-learning), including how to add/remove drafters online without destabilizing HedgeSpec or inflating regret.
- Provide guidelines and algorithms for setting speculative decoding hyperparameters and HedgeSpec internals (e.g., queue management for delayed feedback) that optimize throughput across diverse hardware and model stacks.
- Study cross-model generalization to closed-source targets and different architectures (mixture-of-experts, stateful agents) to assess how target distributions and verification APIs affect feedback fidelity and performance.
- Analyze censoring effects empirically (not only theoretically), quantify real-world frequency of truncated feedback, and design mitigation strategies (e.g., anticipatory verification or buffered evaluation) that reduce learning stalls.
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now, leveraging the paper’s methods and findings. Each item includes relevant sectors, potential tools/workflows, and assumptions/dependencies.
- Dynamic drafter orchestration for LLM serving
- Sector: software/cloud, AI infrastructure
- What: Integrate HedgeSpec into existing speculative decoding stacks (e.g., EAGLE-3, single/multi-draft, draft trees) to select the most effective drafter per request using full-information feedback (NormalHedge + delayed-feedback handling).
- Tools/workflows:
- “HedgeSpec” plugin for inference servers (e.g., vLLM/TGI/custom engines)
- Runtime pipeline: verification → lightweight evaluation (prefill all drafters) → compute acceptance probabilities/length via the unbiased estimator → update drafter weights → select next drafter
- Observability: log Mean Accepted Tokens (MAT), token/s, acceptance probabilities γt[i], and per-drafter loss
- Benefits: Significant end-to-end throughput gain (e.g., 46.1% average across mixed queries; up to 83.7% token/s gain on SQL), reduced tail latency, faster convergence than bandit routers
- Assumptions/dependencies:
- Availability of multiple domain drafters (EAGLE or similar)
- Target model supports speculative decoding and exposes needed logits/probabilities for verification
- Parallel evaluation capability (low overhead for drafter forward passes)
- Chunk size K and verification schedule compatible with delayed-feedback learners
- Cost and energy optimization in LLM inference
- Sector: cloud operations, energy management, finance
- What: Reduce compute-expensive target passes via higher acceptance lengths, lowering energy use and operating cost per token
- Tools/workflows: Integrate HedgeSpec into autoscaling policies; monitor energy per request and token/s with MAT as a leading indicator; A/B tests comparing EAGLE vs. HedgeSpec
- Assumptions/dependencies: Instrumentation for per-request energy/cost metrics; ability to deploy HedgeSpec across serving clusters
- Robust routing under out-of-distribution (OOD) prompts (routerless or router-augmented serving)
- Sector: software/cloud, MLOps
- What: Replace or augment static offline routers with HedgeSpec’s full-information learner to adapt at runtime when prompts diverge from training distribution (demonstrated large wins vs. BERT-based static router under minor prompt shifts)
- Tools/workflows:
- HedgeSpec as primary router
- Optionally use offline router for warm-start routing in first few steps; HedgeSpec takes over via feedback
- Assumptions/dependencies: OOD prompts are common; expert drafters remain useful; real-time feedback is available to adapt weights
- Domain-optimized services (code, SQL analytics, summarization, medical QA) with curated drafter pools
- Sector: software (developer tools/IDE assistants), data analytics, media, healthcare
- What: Deploy domain-specialist drafters (e.g., Python, SQL, CNN_DailyMail summarization, MedQA) and orchestrate them with HedgeSpec to accelerate long-form outputs and complex reasoning
- Tools/workflows:
- Drafter training pipeline (e.g., SpecForge) for domain finetuning
- HedgeSpec orchestration during inference to exploit specialist strengths without sacrificing generality
- Assumptions/dependencies: Access to domain datasets, curated specialist drafters; alignment between drafter domains and request mix
- SLA improvement and tail-latency reduction for long reasoning chains
- Sector: cloud serving, enterprise AI platforms
- What: Use HedgeSpec to minimize long-tail latency by selecting high-acceptance drafters on a per-query basis, especially for models like Qwen reasoning (benefit grows with output length)
- Tools/workflows: SLA dashboards tracking tail latencies; integrate MAT/token/s targets into SLOs
- Assumptions/dependencies: Requests include long chains; speculative verification parallelism is enabled; EAGLE-like draft trees supported
- Observability, diagnostics, and online tuning of drafter pools
- Sector: MLOps, reliability engineering
- What: Use the paper’s unbiased acceptance-length estimator to build real-time telemetry for drafter performance (per-domain, per-prompt family); quickly detect underperforming drafters and retune/retire them
- Tools/workflows: Acceptance-length dashboards; per-drafter γt[i] tracking; automated alerts for drift or degradation
- Assumptions/dependencies: Access to per-round acceptance probabilities; storage and processing for telemetry
- Edge/on-prem acceleration with lightweight drafters
- Sector: enterprise on-prem, edge AI
- What: Run small EAGLE-like drafters locally and use HedgeSpec to accelerate large local LLM inference (prefill multiple drafters with minimal overhead)
- Tools/workflows: Parallel drafter evaluation (GPU or mixed GPU/CPU); small transformer drafters tuned for local domains
- Assumptions/dependencies: Adequate local resources for parallel drafter eval; speculative decoding supported by the target model
- Academic replication and extension
- Sector: academia/research
- What: Reproduce the paper’s full-information drafter selection; use the off-policy acceptance-length estimator and delayed-feedback reduction to study adaptation dynamics and regret bounds in LLM serving
- Tools/workflows: NormalHedge implementation; delayed-feedback algorithms (per Joulani et al.); EAGLE-3 or equivalent speculative decoders
- Assumptions/dependencies: Access to open-source LLMs/datasets; careful measurement of γt and EAL/ETAP
Long-Term Applications
The following use cases are promising but need further research, scaling, tooling, or integration work.
- Scaling to very large, heterogeneous drafter marketplaces
- Sector: software/cloud platforms, model marketplaces
- What: Offer tens–hundreds of specialist drafters (including retrieval-augmented, tool-using, multilingual, domain-specific) and let HedgeSpec scale selection under low overhead and strong regret guarantees
- Tools/workflows: Drafter registry; parallel evaluation schedulers; adaptive memory/compute budgeting per drafter; dynamic pool pruning
- Assumptions/dependencies: Efficient parallelization across many drafters; memory footprint management; robust γt estimation for heterogeneous draft mechanisms
- Generalizing full-information feedback beyond drafting to tool selection and agent orchestration
- Sector: software, robotics, enterprise automation
- What: Apply the “counterfactual full-information” idea to select among tools/functions (retrieval, calculators, code execution) and agent planners; compute unbiased or low-bias acceptance/utility estimators per tool from a single verified trajectory
- Tools/workflows: HedgeSpec-like orchestration layer for tools; verification signals that can be reused across candidate tools; delayed-feedback handling for multi-step toolchains
- Assumptions/dependencies: Well-defined verification/utility signals per tool; tractable estimators akin to γt for non-token actions; theoretical guarantees for partial monitoring with complex feedback
- Continuous AutoML for drafter creation and lifecycle management
- Sector: MLOps, AutoML, data engineering
- What: Automatically discover domains with poor acceptance, spin up new drafters via pipelines like SpecForge, and retire or retrain weak ones based on HedgeSpec telemetry
- Tools/workflows: Data collection and labeling for emerging domains; auto-finetuning pipelines; governance for deploying/retiring drafters
- Assumptions/dependencies: Sufficient domain data; safe deployment practices; guardrails for drift and privacy
- Cross-model and multi-target scheduling
- Sector: cloud orchestration, distributed systems
- What: Extend HedgeSpec to choose both drafter and target model variants (e.g., 8B vs. 32B targets) per query; optimize for throughput vs. quality under resource constraints
- Tools/workflows: Multi-model schedulers; cost-aware learners; per-target verification APIs; SLA-aware routing policies
- Assumptions/dependencies: Consistent verification interface across targets; theoretical extensions for multi-armed delays; resource-aware regret bounds
- Streaming and non-greedy sampling support with variable delays
- Sector: conversational AI, RAG, long-form generation
- What: Adapt HedgeSpec for streaming output, nucleus/temperature sampling, and variable chunk sizes; handle non-constant delays and censoring more robustly
- Tools/workflows: Variable-K learners; stochastic delay models; modified NormalHedge or alternative algorithms tailored to streaming
- Assumptions/dependencies: New theory/practice for variable delay reductions; measurement of γt under non-greedy scenarios
- Hardware–software co-design for drafter evaluation
- Sector: hardware acceleration, data center engineering
- What: Design accelerators (e.g., FP16/INT8, ASIC/FPGAs) optimized for rapid drafter prefills and γt computation; integrate with target model verification pipelines
- Tools/workflows: Custom kernels for Top-L ranking and tree construction; parallel pipelines for multi-drafter evaluation
- Assumptions/dependencies: Hardware R&D; ecosystem integration; careful cost/benefit analysis vs. general-purpose GPUs
- Provider governance, billing, and energy-aware scheduling
- Sector: policy, cloud business models, sustainability
- What: Introduce pricing models tied to accepted tokens/throughput; prioritize energy-efficient drafter configurations; enforce sustainability SLOs leveraging HedgeSpec’s telemetry
- Tools/workflows: Billing metrics tied to MAT/token/s; energy dashboards; scheduling that favors high-acceptance configurations during peak load
- Assumptions/dependencies: Customer acceptance; accurate and auditable metrics; alignment with provider policies
- Safety-aware drafter orchestration
- Sector: safety, security
- What: Maintain “safety drafters” and use HedgeSpec to detect OOD/jailbreak-like prompts; route to safety specialists or reduce speculative aggressiveness when risk increases
- Tools/workflows: Safety detectors as drafters; acceptance signals as early warnings; adaptive throttling
- Assumptions/dependencies: Reliable safety signals; curated safety drafters; careful integration to avoid degradation of benign throughput
- Personalized education and domain tutoring
- Sector: education/edtech
- What: Build LLM tutors that select the best drafter per subject/topic (math, biology, chemistry) and per student’s prompt style to reduce latency and increase coherence of long explanations
- Tools/workflows: Tutor orchestration layer; student-profile-aware drafter weighting; content safety filters
- Assumptions/dependencies: Availability of high-quality domain drafters; safe deployment in educational settings; alignment with curricula
- End-user applications (chat, IDE assistants, analytics dashboards)
- Sector: daily life, productivity tools
- What: Faster, more reliable LLM responses for long tasks (coding, SQL querying, complex reasoning, long summaries) using HedgeSpec-driven drafter selection
- Tools/workflows: Client-side or server-side HedgeSpec integration; caching of drafter evaluations; UI telemetry showing speed gains
- Assumptions/dependencies: Speculative decoding enabled in serving stack; multiple drafters packaged with the product; privacy-compliant logging of acceptance metrics
These applications leverage the paper’s core innovations—full-information feedback for all drafters, an unbiased acceptance-length estimator, and delayed-feedback online learning—to produce tangible gains in LLM throughput, robustness, and cost-efficiency across sectors.
Glossary
- Acceptance length: The number of consecutive drafted tokens that are verified as correct before the first mismatch in a chunk. "The acceptance length is the number of consecutive tokens accepted before the first mismatch."
- Acceptance probability: The probability that a drafted token (or step) is accepted by the target model under the speculative decoding verification rule. "The acceptance probability of the above algorithm is $\sum_{x\inV} \min\{p(x),q(x)\} = 1- TV(p,q)$"
- Bandit feedback: A feedback setting where the learner only observes the outcome of the selected action (drafter), not of all alternatives. "we can get feedback for all draft models, i.e., the full-information feedback, rather than only the draft model that we choose to play, i.e., the Bandit-feedback model."
- BanditSpec: A prior bandit-based drafter selection approach that balances exploration and exploitation. "Their approach, BanditSpec, balances exploration (trying different drafters) and exploitation (using the empirically best drafter)."
- Chunk: A group of K drafted tokens verified together in speculative decoding. "Speculative decoding drafts tokens per chunk starting at index "
- Censoring issue: A feedback problem where insufficient acceptance prevents computing losses for unobserved longer acceptances, potentially biasing learning. "We refer to this problem a censoring issue."
- Counterfactual estimator: An estimator that uses a single verified trajectory to compute unbiased estimates for alternative drafters’ outcomes. "The 'one-step counterfactual' estimator:"
- Delayed feedback: A setting where the loss/feedback for an action is revealed after some delay, not immediately at the decision time. "These issues can be modeled as 'delayed feedback'"
- Draft tree: A tree-structured set of candidate continuations (depth K, branching L) used by EAGLE-style speculative drafting. "For EAGLE's Greedy-Draft Tree approach is the total probability of children nodes of parent on the draft tree"
- Drafter: A smaller surrogate model used to propose tokens that the target model will verify. "a smaller surrogate model---referred to as a draft model or simply a drafter"
- Dynamic pruning: An EAGLE mechanism that prunes low-probability branches in the draft tree to improve efficiency. "If dynamic pruning is used, then the candidate set should be replaced with the pruned set of descendants"
- EAGLE: A family of speculative decoding drafters that construct multi-branch draft trees for verification by the target model. "The EAGLE family is the most widely deployed speculative decoding models"
- EAGLE-3: A specific EAGLE variant with multi-layer feature fusion and training-time test mechanism. "All drafters in this paper are implemented with EAGLE-3, a widely used framework for speculative decoding."
- Experience Replay: An analogy from RL where past trajectories are reused for evaluation; here used to evaluate all drafters from a single verified trajectory. "Our evaluation phase is similar to Experience Replay in the RL literature at a glance."
- Exp3Spec: A bandit baseline (EXP3-based) for drafter selection. "including both Exp3Spec and UCBSpec variants."
- Expected Acceptance Length (EAL): The expected number of accepted tokens per chunk, averaged over prefix distribution and decoding randomness. "We use two key metrics to evaluate a speculative decoding method : the Expected Token Acceptance Probability (ETAP) and the Expected Acceptance Length (EAL)."
- Expected Token Acceptance Probability (ETAP): The expected per-token acceptance probability over a distribution of prefixes. "We use two key metrics to evaluate a speculative decoding method : the Expected Token Acceptance Probability (ETAP) and the Expected Acceptance Length (EAL)."
- Full-information feedback: Feedback that provides losses or acceptance statistics for all drafters, not just the chosen one. "we can get feedback for all draft models, i.e., the full-information feedback"
- Full-information online learning: An online learning setting where the learner observes the loss/feedback for all actions at each round. "This transforms the problem from a bandit setting into a full-information online learning problem."
- Hedge: A classic expert/online learning algorithm that maintains multiplicative weights over actions. "HedgeSpec, which uses algorithms such as Hedge \citep{littlestone1994weighted,vovk1995game} or NormalHedge"
- HedgeSpec: The proposed full-information drafter selection framework with theoretical guarantees and practical efficiency. "We present HedgeSpec, a full-information online learning framework for drafter selection."
- Markov process: A stochastic process where the next state depends only on the current state; used to describe the non-adversarial nature of losses in practice. "but rather a Markov process induced by the target LLM"
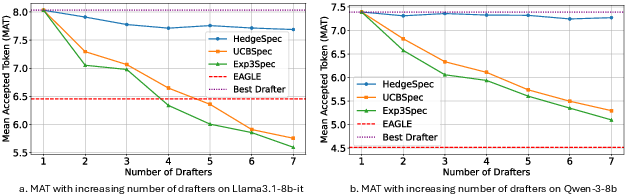
- Mean Number of Accepted Tokens (MAT): An empirical metric measuring average accepted tokens per verification cycle. "We report the Mean Number of Accepted Tokens (MAT) along with the wall-clock time required to complete each request"
- Multi-armed bandit: A sequential decision problem balancing exploration and exploitation with partial feedback. "who framed it as a multi-armed bandit task."
- NormalHedge: A parameter-free hedging algorithm used as the base learner in HedgeSpec. "HedgeSpec, which uses algorithms such as Hedge ... or NormalHedge \citep{chaudhuri2009parameter}"
- Off-policy estimator: An estimator that evaluates a policy (drafter) using data generated by a different policy without extra target calls. "an off-policy estimator that returns the correct acceptance length in expectation"
- Panoramic feedback: Comprehensive feedback across all drafters obtained after verification to accelerate selection. "a lightweight evaluation collects panoramic feedback from drafters"
- Partial monitoring: An online learning setting where the feedback signals can be indirect; referenced in delay-handling algorithms applied here in full-information mode. "stated for the more general 'partial monitoring' setting"
- Prefill: The act of conditioning a drafter on the verified tokens from the target trajectory to compute feedback. "we prefill them into for each of the other ."
- Prefix distribution: The distribution over token prefixes encountered during decoding, used to define expectations like ETAP/EAL. "The distribution over prefixes provides a useful abstraction"
- Speculative decoding: An inference technique using a small drafter to propose tokens that a larger target model verifies in parallel to accelerate generation. "Speculative decoding is widely used in accelerating LLM inference."
- Speculative tokens: The K drafted tokens proposed by the drafter before verification. "A speculative decoding method uses to generate speculative tokens"
- Target model: The large, accurate model whose outputs define correctness and which verifies drafter proposals. "without incurring additional queries to the target model"
- Top-L set: The set of top L tokens (by drafter probability) considered at a node in an EAGLE draft tree. "the candidate set "
- Total variation distance: A divergence measure between distributions; in basic speculative decoding, acceptance probability equals 1 minus TV. "where denotes the total variation distance"
- UCBSpec: A bandit baseline (UCB-based) for drafter selection. "including both Exp3Spec and UCBSpec variants."
- Verification phase: The stage where the target model checks drafted tokens, after which global feedback is computed. "After the verification phase, a lightweight evaluation collects panoramic feedback from drafters"
Collections
Sign up for free to add this paper to one or more collections.