AdaSPEC: Selective Knowledge Distillation for Efficient Speculative Decoders
Abstract: Speculative Decoding (SD) accelerates LLM inference by employing a small draft model to generate predictions, which are then verified by a larger target model. The effectiveness of SD hinges on the alignment between these models, which is typically enhanced by Knowledge Distillation (KD). However, conventional KD methods aim to minimize the KL divergence between the draft and target models across all tokens, a goal that is misaligned with the true objective of SD, which is to maximize token acceptance rate. Therefore, draft models often struggle to fully assimilate the target model's knowledge due to capacity constraints, leading to suboptimal performance. To address this challenge, we propose AdaSPEC, a novel method that incorporates selective token filtering into the KD process. AdaSPEC utilizes a reference model to identify and filter out difficult-to-fit tokens, enabling the distillation of a draft model that better aligns with the target model on simpler tokens. This approach improves the overall token acceptance rate without compromising generation quality. We evaluate AdaSPEC across diverse tasks, including arithmetic reasoning, instruction-following, coding, and summarization, using model configurations of 31M/1.4B and 350M/2.7B parameters. Our results demonstrate that AdaSPEC consistently outperforms the state-of-the-art DistillSpec method, achieving higher acceptance rates across all tasks (up to 15\%). The code is publicly available at https://github.com/yuezhouhu/adaspec.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Easy-to-understand summary of “AdaSPEC: Selective Knowledge Distillation for Efficient Speculative Decoders”
What is this paper about?
This paper is about making big AI LLMs (like chatbots) faster without making their answers worse. It focuses on a trick called speculative decoding, where a small model “guesses” a few next words, and a big model quickly checks those guesses. The new method, called AdaSPEC, helps the small model make better guesses so the big model accepts more of them. That means fewer slow steps and faster responses.
What questions are the researchers trying to answer?
- How can we train the small “draft” model so that the big “target” model accepts more of its guesses?
- Is it wasteful for the small model to try to learn everything the big model knows?
- Can we focus training on the tokens (pieces of words) that the small model can actually learn well, to improve speed and keep quality?
- Does this approach beat the current best method (DistillSpec) across different tasks and model sizes?
How does the method work? (Explained with simple ideas)
First, a few quick definitions:
- Speculative decoding: Think of it like a student (small model) making several quick guesses on a multiple-choice test, and a teacher (big model) confirming which guesses are right in one go. If many guesses are correct, grading is fast.
- Acceptance rate: The percentage of the small model’s guesses that the big model accepts. Higher = faster.
- Knowledge distillation: Teaching the small model to imitate the big model (like a tutor summarizing a textbook for a student).
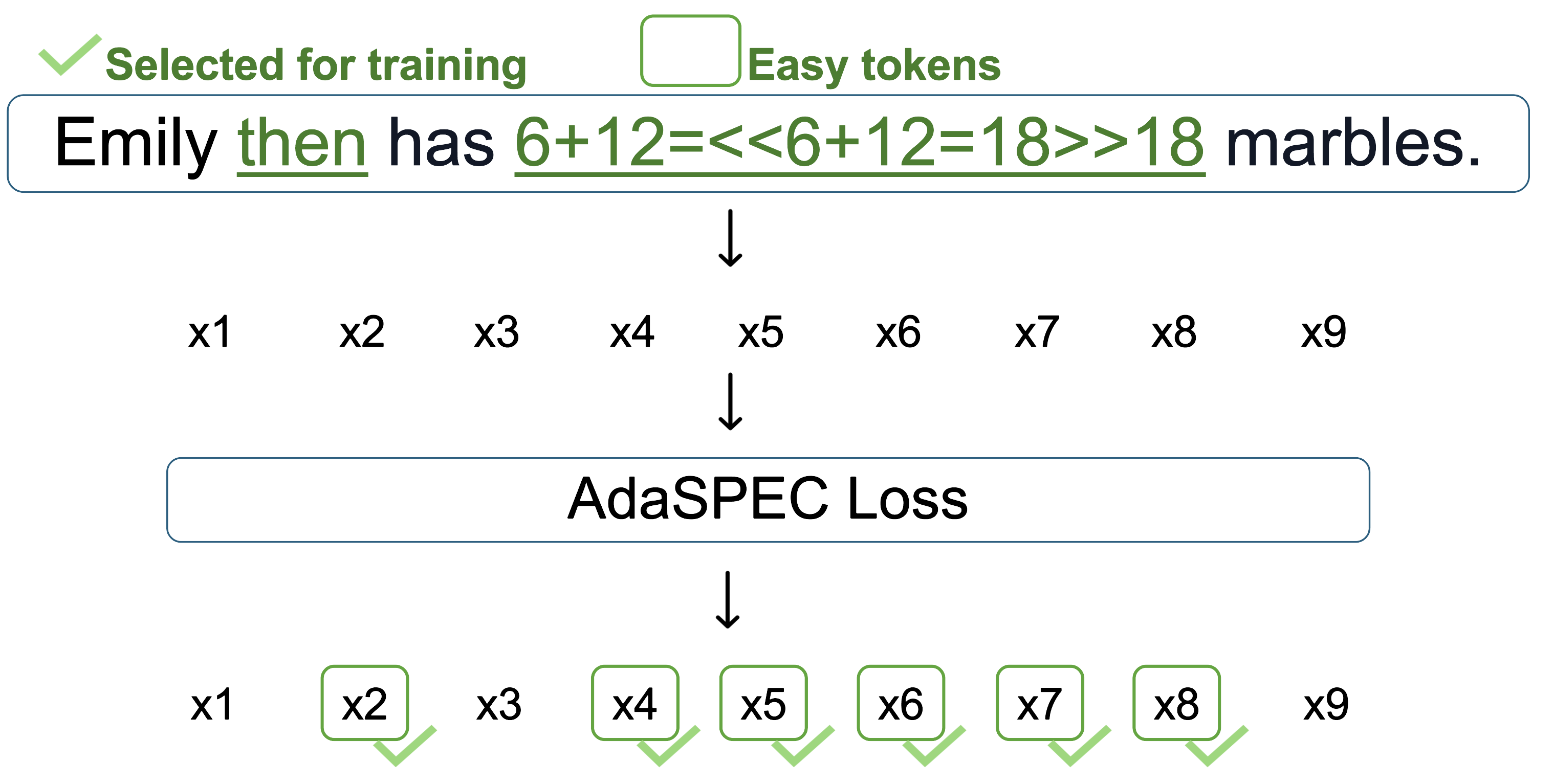
The main idea in AdaSPEC is: don’t try to learn every single token. Instead, focus on the tokens the small model can realistically learn well. It’s like studying for a test by putting more time into questions you can get right, rather than struggling forever with the hardest ones.
AdaSPEC happens in two steps:
- Train a “reference model” to act as a filter
- Start with a copy of the small model and teach it using the big model.
- Use this reference model to figure out which tokens are “hard” for small models.
- Mark those hard tokens so we can avoid them during main training.
- Teach the draft (small) model selectively
- Remove the hard tokens from the training data.
- Train the small model to match the big model only on the more learnable tokens.
- This helps the small model use its limited “brain space” wisely and boosts the acceptance rate.
Analogy: If you’re on a sports team with limited practice time, you focus drills on plays your team can actually master now, not on moves that only superstar teams can do. That way, your overall game improves faster.
What did they find, and why does it matter?
- Across many tasks (math word problems, following instructions, code generation, and summarization), AdaSPEC made the big model accept more of the small model’s guesses—up to 15% more than the previous best method (DistillSpec).
- This higher acceptance rate led to real speed-ups in practice (about 10–20% faster in their tests) without hurting the quality of the generated text.
- It worked on different model sizes and even when the small and big models came from different families (not just “matching” models).
- It also played nicely with more advanced speculative decoding systems (like EAGLE), giving both better accuracy and speed.
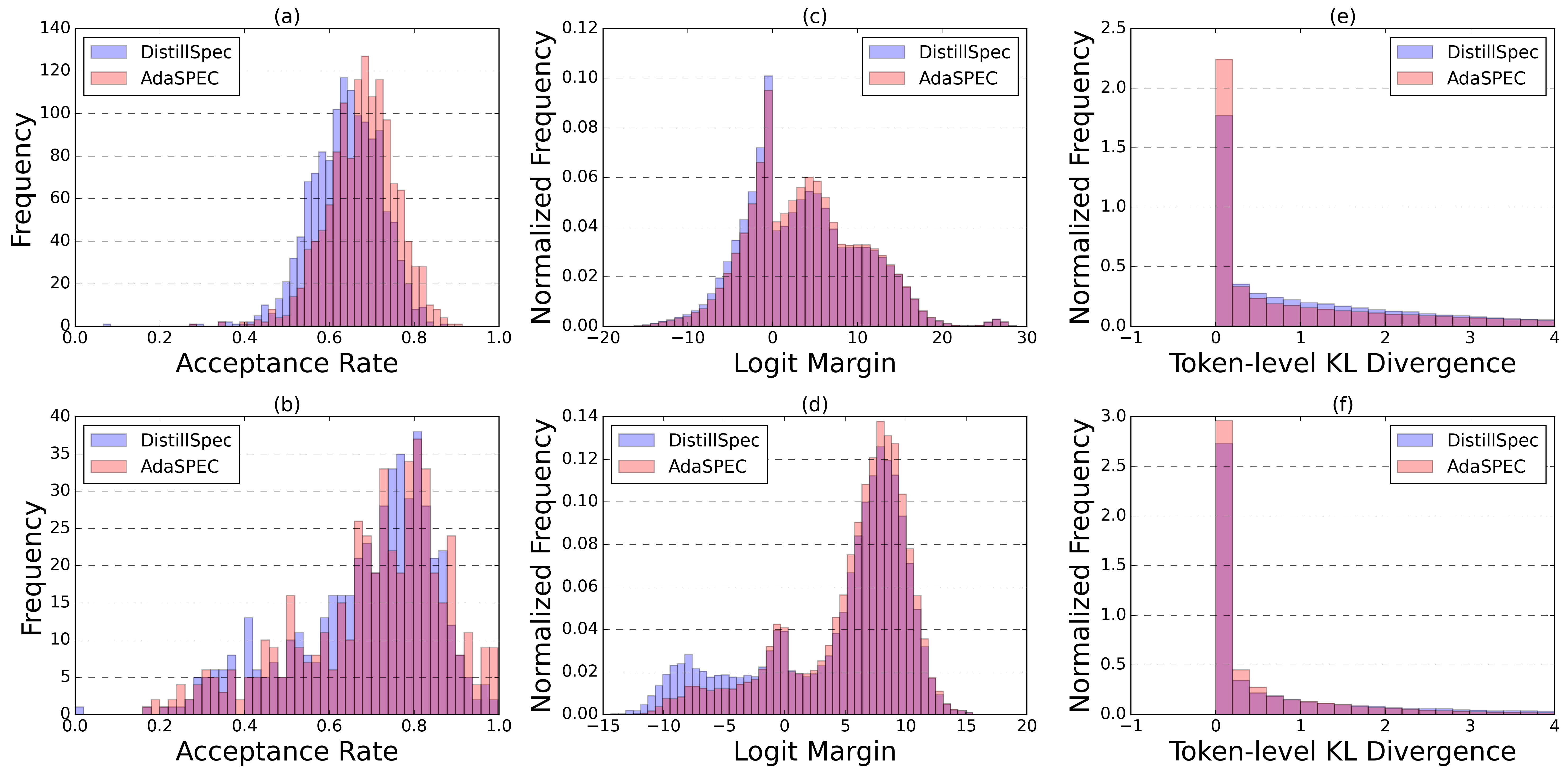
- In detailed checks, AdaSPEC’s predictions were more confident and closer to the big model’s choices, and its mistakes often overlapped with or were fewer than those from the older method.
Why this matters: Faster models mean lower cost, less waiting, and more practical use on everyday devices, while still keeping answers good.
What’s the bigger picture or impact?
- AdaSPEC shows that training small models to be good “guessers” doesn’t require learning everything—just the right things.
- This selective training idea can make AI assistants faster and cheaper to run, helping them work better on phones, laptops, or in large-scale services.
- It scales to bigger model pairs and can be combined with other speed-up techniques.
- Future work could make the token filtering even smarter and combine it with more complex verification methods for even bigger gains.
In short: Instead of trying to teach a small model to be a mini version of a huge model, AdaSPEC teaches it to be really good at making the kinds of guesses that are likely to be accepted. That simple shift leads to faster AI without sacrificing quality.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and concrete research directions that emerge from the paper.
- Lack of acceptance-aware objectives: The method optimizes forward KL on selected tokens, but does not directly optimize a surrogate for acceptance rate. Develop differentiable, stable objectives or RL-style surrogates that explicitly target expected acceptance/block efficiency.
- Token selection rationale is heuristic and static: Selection uses a fixed top-k percent of tokens by ΔKL without a principled derivation. Investigate theoretically grounded criteria (e.g., teacher entropy, acceptance probability estimators, margin-based risk) and adaptive schedules (curriculum/annealing or online re-selection).
- Inconsistency in token difficulty signals: The paper alternately references “perplexity differences” and token-wise KL for filtering. Clarify and compare alternative difficulty signals (KL, cross-entropy, margin, entropy, gradient norm), and quantify their impact on acceptance and quality.
- No theoretical analysis linking selective KD to acceptance improvements: Provide formal guarantees or bounds connecting ΔKL-based filtering to acceptance rate, block efficiency, and wall-time speed-up under various γ and cost ratios.
- Unquantified training overhead of filtering: Measuring both draft and reference token-level KL across the dataset adds compute/memory. Quantify overhead, propose efficient approximations (e.g., sampling, caching, teacher logits sparsification), and report end-to-end training cost.
- Absence of comprehensive output quality evaluation: Claims of “without compromising generation quality” are not substantiated with task metrics (e.g., GSM8K accuracy, MBPP pass@k, ROUGE/BS for summarization). Evaluate target task quality and acceptance jointly to reveal trade-offs.
- Greedy decoding only: Acceptance and gains are reported under greedy decoding. Validate robustness under common generation settings (temperature, top-k/p, nucleus sampling, beam search) and quantify acceptance-rate sensitivity.
- No analysis across block sizes γ: Acceptance is linked to block efficiency, but γ is not varied. Systematically evaluate γ’s effect on acceptance, block efficiency, and real-world throughput.
- Limited hardware/serving coverage: Speed-ups are reported on single A100 vLLM; no evaluation across GPUs, batch sizes, sequence lengths, multi-tenant loads, or diverse inference engines. Provide latency/throughput curves and resource utilization.
- Reference model quality sensitivity: The approach depends on a reference model distilled via DistillSpec. Analyze sensitivity to reference quality (e.g., using a non-distilled reference, larger/smaller reference than draft) and failure modes if the reference misaligns.
- Filtering vs weighting: Only hard filtering (indicator mask) is explored. Compare soft weighting schemes (importance reweighting, focal loss, confidence-based weights) to reduce gradient starvation and catastrophic forgetting.
- Catastrophic forgetting and rare/semantically critical tokens: Filtering may bias against rare or domain-critical tokens. Quantify forgetting, semantic consistency, and coverage of rare tokens; propose constraints or safety nets (e.g., minimum coverage per token class).
- Token-type and position-specific effects: Provide acceptance breakdown by token type (e.g., numerals, operators, identifiers, punctuation) and position (early vs late in sequence), especially for reasoning and coding tasks.
- Cross-family/tokenizer alignment: Cross-family experiments rely on “aligned tokenizer” but details are sparse. Evaluate robustness under tokenizer mismatches (byte-level, sentencepiece variants) and provide recipes for alignment/generalization.
- Distribution shift robustness: Filtering learned on training data may degrade under different domains/prompts. Test out-of-distribution settings, mixed-domain workloads, and online/speculative serving where inputs vary widely.
- Stability and convergence analysis: While DistillSpec is said to have convergence issues, AdaSPEC’s stability is not analyzed. Report loss dynamics, variance, and convergence properties under different k, objectives, and optimizers.
- Alternative distillation objectives under SD: RKL and TVD underperform in the paper’s setup. Explore why (e.g., mode-seeking vs mode-covering behaviors) and whether hybrid/f-divergence or sequence-level objectives can better target acceptance.
- Curriculum and k scheduling: Fig. on k suggests smaller k can help, but scheduling is not studied. Investigate dynamic k (warm-up, cosine annealing), per-example k, or uncertainty-aware selection to balance capacity and coverage.
- Integration breadth with advanced SD: Only EAGLE is tested. Evaluate orthogonality with other SD variants (Medusa, self-speculative, online SD, tree-based verification) and quantify additive benefits and conflicts.
- Scaling laws and limits: Demonstrate how acceptance gains scale with draft-target size ratio (beyond the reported cases), sequence length, and data size, and identify regimes where selective KD saturates or fails.
- Safety, bias, and compliance impacts: Filtering may skew token distributions and affect safety/compliance outputs. Conduct targeted evaluations (toxicity, bias, instruction adherence) to ensure selective KD does not degrade safety.
- Acceptance-quality trade-offs: Provide Pareto curves or joint metrics that elucidate how increases in acceptance rate translate to task accuracy and user-centric quality, guiding practitioners in setting k and objectives.
- Per-token acceptance modeling: Explore training a predictor for per-token acceptance probability, using it to guide selection or to design acceptance-aware KD losses.
- Online/adaptive SD training: Investigate training regimes that use acceptance feedback during decoding (on-policy or self-training) to adapt filtering and align the draft to the target’s verification behavior.
- Rare error analysis and failure cases: Beyond case studies, provide systematic analysis of tokens and contexts where AdaSPEC fails, and whether errors are indeed a subset of DistillSpec across tasks.
- Reproducibility details and hyperparameters: While an appendix is mentioned, ensure release of all selection thresholds, k schedules, optimizer settings, and code paths for filtering and distillation, particularly for cross-family setups.
Practical Applications
Immediate Applications
The following applications can be deployed using current toolchains and model ecosystems, leveraging AdaSPEC’s selective knowledge distillation to raise token acceptance rates and accelerate speculative decoding while preserving target-model quality.
- Stronger speculative decoding in production LLM serving (software, cloud/infra)
- What: Train draft models with AdaSPEC to increase acceptance rate (reported +5–15%) and reduce wall-clock latency (10–20% on vLLM/A100), improving throughput and cost efficiency for chat, search, and API workloads.
- Tools/workflows: Integrate AdaSPEC into existing SD pipelines (e.g., vLLM, EAGLE) as a “draft-model training stage”; add acceptance-rate monitoring as a KPI; choose k≈0.2–0.4 for token selection; forward-KL distillation objective.
- Assumptions/dependencies: Access to target model logits; tokenizer alignment between draft/target; compute for reference-model and draft training; SD-friendly inference engine; improvements vary with block size γ and cost ratio c; model licensing permits distillation.
- Faster code completion and review assistants (software, developer tools)
- What: Use AdaSPEC-trained drafts for speculative decoding in code assistants to speed up completions and in-IDE suggestions (validated on MBPP).
- Tools/workflows: Fine-tune target on code; distill reference; run AdaSPEC selective KD; deploy with SD or tree-based SD (e.g., EAGLE) for IDE integrations.
- Assumptions/dependencies: Sufficient domain data; compatible tokenizers; acceptance-rate gains translate into IDE latency wins; guardrails for correctness and security remain with target verification.
- Low-latency customer support and sales chat (enterprise software, CX)
- What: Reduce response latency for instruction-following agents (Alpaca-like data) while maintaining target-model response quality due to verification.
- Tools/workflows: Add AdaSPEC as a pre-deploy training step for draft models; track acceptance rate and wall-time; autoscale to exploit higher throughput.
- Assumptions/dependencies: Domain tuning of target/draft; compatible inference stack; privacy and compliance controls remain in target verification pass.
- Document and email summarization at scale (enterprise content, media)
- What: Accelerate summarization pipelines (validated on CNN/DailyMail, XSum) to process backlogs and real-time feeds with lower GPU hours.
- Tools/workflows: Batch inference with SD; priority queues that route long docs to AdaSPEC-enabled pipelines; acceptance-rate-aware schedulers.
- Assumptions/dependencies: Target model quality adequate for the domain; long-context throughput bounded by memory and engine limits; tokenizer aligned.
- Math and step-by-step tutoring latency reduction (education)
- What: Improve responsiveness for arithmetic reasoning assistance (GSM8K), increasing student engagement without sacrificing correctness (target verifies).
- Tools/workflows: Reference/draft trained on math corpora; SD-enabled tutoring backends; acceptance-rate dashboards for curriculum variants.
- Assumptions/dependencies: Availability of domain-specific target; bias checks to ensure token filtering doesn’t reduce coverage of “hard” reasoning cases.
- Cost and energy savings for AI platforms (energy, operations, FinOps)
- What: Translate 10–20% decoding speed-ups into fewer GPU hours and lower carbon footprint per token.
- Tools/workflows: FinOps dashboards that attribute saved GPU time to acceptance-rate gains; SLOs defined on latency and energy/token.
- Assumptions/dependencies: Realized speed-up depends on γ, c, batching, and engine (e.g., FlashDecoding++ interactions); measurement accuracy for energy.
- Research and reproducibility packages (academia)
- What: Use AdaSPEC as a baseline for selective KD, curriculum-at-token-level research, and SD benchmarks; adopt acceptance rate as a primary metric.
- Tools/workflows: Open-source repo; task suites (GSM8K, MBPP, CNN/DM, XSum); ablation templates for k-selection, losses, and logit-margin analysis.
- Assumptions/dependencies: Access to teacher logits; compute for reference and draft training; ethics review for dataset composition effects.
- Safer deployment in regulated workflows via verification-gated outputs (healthcare documentation, legal drafting)
- What: Deploy SD where final outputs must match the target model, using AdaSPEC to meet latency constraints while preserving quality through verification.
- Tools/workflows: “Verification must-pass” gates; audit trails logging acceptance and rejections; human-in-the-loop for flagged rejects.
- Assumptions/dependencies: Compliance requires auditability and data locality; target model is approved; SD integration does not alter final outputs.
- Mixed-task serving with less catastrophic forgetting (enterprise AI suites)
- What: Maintain capabilities across blended workloads (e.g., coding + math) by selective KD that emphasizes learnable tokens and reduces forgetting.
- Tools/workflows: Multi-domain training schedules; per-domain acceptance-rate tracking; dataset mixing with staged reference/draft cycles.
- Assumptions/dependencies: Order and mix of tasks matter; monitoring required to avoid coverage gaps on rare domains.
- Plug-in to advanced SD methods (software, inference systems)
- What: Use AdaSPEC with EAGLE/Medusa/draft-tree verifiers to further amplify decoding throughput (paper reports speed and accuracy gains with EAGLE).
- Tools/workflows: Modular training that outputs AdaSPEC drafts; inference engines selecting SD variant per prompt length and domain.
- Assumptions/dependencies: Engine must expose the draft/verify interface; hyperparameters tuned per SD variant; diminishing returns possible on already-optimized stacks.
Long-Term Applications
These applications are promising but depend on further research, scaling, or ecosystem support (e.g., hardware, model access, or regulation).
- Private on-device assistants with local SD (consumer devices, edge AI)
- What: Run both draft and a medium-size target model locally (or partially on-device) for private, low-latency assistants; AdaSPEC increases acceptance to make SD viable on resource-constrained hardware.
- Tools/products: NPU-optimized SD runtimes; on-device token-level acceptance controllers; adaptive k at runtime.
- Assumptions/dependencies: Availability of sufficiently strong on-device targets; memory and bandwidth; strong quantization + SD co-design; thermal limits.
- Real-time robotics and embodied AI planning (robotics)
- What: Faster plan generation and tool calls by combining AdaSPEC drafts with verification for safety-critical steps; improved reactivity in dynamic environments.
- Tools/products: SD-enabled planners with safety-verification tokens; fallback policies on reject bursts.
- Assumptions/dependencies: Robustness under distribution shift; real-time guarantees; integration with sensor fusion; verified safety envelopes.
- Clinical scribes and decision support with strong verifiability (healthcare)
- What: Latency-reduced, verification-gated summarization and note generation to fit clinical workflows; target acts as safety gate.
- Tools/products: Hospital EHR plugins using SD; audit logs of acceptance; domain-tuned k per specialty.
- Assumptions/dependencies: Regulatory approvals; privacy-preserving deployment (on-prem/edge); validation on medical corpora; bias audits to ensure token filtering doesn’t suppress rare but critical information.
- Compliance, KYC, and regulatory chat at scale (finance, policy)
- What: Low-latency compliance assistants and report generators with strict verification to reduce hallucination risk while meeting SLA.
- Tools/products: SD-accelerated policy engines with acceptance analytics; compliance dashboards showing draft/verify behavior.
- Assumptions/dependencies: Domain-specific targets; regulatory acceptance of SD pipelines; rigorous logging and explainability.
- Standardization of SD efficiency and reporting (policy, industry consortia)
- What: Create benchmarks and procurement criteria around acceptance rate, energy/token, and verification behavior to encourage “green AI” practices.
- Tools/products: Industry standards and audit protocols; acceptance-rate certification; environmental impact labels.
- Assumptions/dependencies: Community consensus; reproducible measurement tooling; diverse workload coverage to avoid gaming.
- Bias and safety auditing for selective distillation (governance, ethics)
- What: Develop fairness frameworks to test whether filtering “hard” tokens introduces unintended biases (e.g., rare dialects, minority-language tokens).
- Tools/products: Token-difficulty parity metrics; bias-aware k-selection; counterfactual evaluation suites.
- Assumptions/dependencies: Access to demographic/language annotations; cross-corpora evaluation; regulatory oversight.
- Hardware–software co-design for speculative verification (semiconductors, systems)
- What: Architect accelerators and kernels optimized for draft–verify patterns, token filtering, and dynamic γ scheduling; couple with FlashDecoding++-style kernels.
- Tools/products: SD-native memory layouts; fused kernels for verification; hardware counters for acceptance-rate telemetry.
- Assumptions/dependencies: Vendor adoption; ROI vs. general-purpose workloads; evolving SD algorithms (tree-based, multi-candidate).
- Multimodal speculative decoding with selective KD (multimedia, AV)
- What: Extend AdaSPEC to vision–language, speech, and code–execution models; focus capacity on learnable modality-specific tokens for faster cross-modal generation.
- Tools/products: Multimodal token-difficulty estimators; selective KD across modalities; streaming SD for AV assistants.
- Assumptions/dependencies: Access to multimodal logits; modality-aligned tokenization; robust evaluation protocols.
- Adaptive and task-aware token selection services (AutoML for SD)
- What: “Selective KD Studio” that auto-tunes k, chooses divergence objectives, identifies domain-critical tokens, and exports draft models for each task.
- Tools/products: Managed service or SDK; acceptance-rate predictors; domain routing policies.
- Assumptions/dependencies: Large-scale meta-data on prompts/tasks; generalization across domains; integration with CI/CD for models.
- Runtime acceptance-aware routing and scheduling (systems, MLOps)
- What: Dynamically route prompts to SD variants and adjust γ or k based on predicted acceptance rate to improve tail latencies and throughput.
- Tools/products: Acceptance predictors; scheduler plugins for inference clusters; feedback loops from production telemetry.
- Assumptions/dependencies: Accurate online predictors; safe adaptation without quality regressions; observability stack support.
Cross-cutting assumptions and dependencies
- Access to a high-quality target model that permits distillation and exposes logits; licensing constraints may apply.
- Tokenizer alignment between draft, reference, and target is critical for token-level selection and SD verification.
- Gains depend on block size γ, cost ratio c, batching, and inference engine support; realized speed-ups can vary across hardware and workloads.
- Selective filtering must be monitored to avoid neglecting rare/critical tokens; fairness, safety, and recall require evaluation and potentially hybrid strategies.
- Forward-KL with k≈0.2–0.4 is a strong default in typical resource-constrained training; other divergences may need longer training and careful tuning.
- Compute budget is needed to train the reference and draft; however, payback occurs in serving efficiency for sustained workloads.
Glossary
- Acceptance rate: In SD, the fraction of draft-generated tokens that the target model validates as correct. "The acceptance rate, , measures the accuracy of the draft model compared to the target model ."
- Aligned tokenizer: Using the same or compatible tokenization across models so token boundaries and IDs match for SD/KD. "these models use an aligned tokenizer to ensure token-level consistency"
- Autoregressive generation: Generating each next token conditioned on previously generated tokens. "SD leverages the draft model to autoregressively generate tokens"
- Block efficiency: Expected number of accepted tokens per decoding iteration (block) in SD. "Block efficiency \citep{chen2023accelerating, leviathan2023fast}, , quantifies the average number of tokens generated per iteration."
- Cost coefficient: Relative runtime cost of the draft model compared to the target model in SD speedup analysis. "where is the cost coefficient, representing the ratio of the time taken by a single execution of to that of ."
- Downstream task: A specific application task (e.g., reasoning, summarization) on which a model is fine-tuned. "Given a target model fine-tuned for a specific downstream task, AdaSPEC consists of two key steps:"
- Draft model: A smaller, faster model used to propose tokens before verification by the larger model in SD. "The core of SD lies in the design of the draft model."
- Forward KL divergence: The Kullback–Leibler divergence minimizing teacher-to-student mismatch by matching the teacher distribution. "The objective is to minimize the forward KL divergence between the target model and the reference model:"
- Greedy decoding: Decoding by selecting the highest-probability token at each step without sampling. "Using a greedy decoding strategy, only the tokens with the highest probabilities are selected for generation or verification."
- Indicator function: A function that returns 1 when a condition holds and 0 otherwise, used to mask/select tokens in losses. "where is the indicator function that equals 1 if the condition inside the brackets is satisfied, and 0 otherwise."
- Knowledge Distillation (KD): Training a smaller “student” model to mimic a larger “teacher” model’s outputs. "often using techniques like Knowledge Distillation (KD) \citep{hinton2015distilling}."
- Kullback–Leibler (KL) divergence: A measure of how one probability distribution diverges from another; central to KD objectives. "conventional KD methods aim to minimize the KL divergence between the draft and target models across all tokens"
- LLM families: Sets of models sharing an architecture but differing in scale, enabling cross-size alignment/transfer. "Modern LLMs are often developed as part of a family of models that share the same core architecture but differ in scale, typically measured by the number of parameters or the size of the training dataset."
- Logit margin: Difference between top-1 and top-2 logits; a proxy for confidence. "The logit margin, defined as the difference between the logits of the top-1 and top-2 predicted tokens, serves as a measure of prediction confidence."
- Perplexity: An exponentiated average negative log-likelihood; lower values indicate better predictive fit. "by comparing the perplexity differences between the reference and draft models on the training data."
- Reference model: An auxiliary model distilled from the teacher to score tokens and filter training targets for the draft. "Here the reference model serves a crucial role as a token filter."
- Reverse KL (RKL): The divergence ; a KD objective variant emphasizing mode-seeking behavior. "We expand AdaSPEC to more distillation approaches: Reverse KL (RKL) and Total Variation Distance (TVD)"
- Selective Knowledge Distillation: Focusing distillation on a subset of tokens deemed more learnable/effective for alignment. "Step 2: Selective Knowledge Distillation for the Draft Model."
- Selective token filtering: Removing hard-to-fit tokens during KD to better allocate student capacity. "incorporates selective token filtering into the KD process."
- Speculative Decoding (SD): A decoding scheme where a small model drafts tokens that a large model then verifies to accelerate inference. "Speculative Decoding (SD) accelerates LLM inference by employing a small draft model to generate predictions, which are then verified by a larger target model."
- Student model: The smaller model trained to imitate the teacher in KD (the draft in SD context). "transferring knowledge from the teacher (target) model to the student (draft) model."
- Teacher model: The larger or more capable model providing supervisory distributions in KD (the target in SD). "transferring knowledge from the teacher (target) model to the student (draft) model."
- Tokenizer alignment: Ensuring identical tokenization across models so per-token distributions are comparable. "these models use an aligned tokenizer to ensure token-level consistency"
- Total Variation Distance (TVD): A distributional distance metric sometimes used as a KD objective. "Reverse KL (RKL) and Total Variation Distance (TVD)"
- Tree attention: An attention mechanism over draft trees used in advanced SD methods like EAGLE. "an advanced SD algorithm featuring tree attention and adaptive expansion strategies."
- Verification stage: The phase in SD where the target model validates draft tokens in parallel. "Subsequently, the verification stage employs the original LLM to validate those draft output tokens in one forward pass."
- Wall-time: End-to-end elapsed time for generation; used to report practical speedup. "The speed-up factor for the total wall-time is given by:"
Collections
Sign up for free to add this paper to one or more collections.

