- The paper demonstrates that scaling trajectory lengths and synthetic data difficulty via asynchronous RL is critical for achieving expert-level agentic search.
- It introduces ASearcher, a minimalistic agent that integrates search queries and web browsing, optimized end-to-end through reinforcement learning.
- Empirical results highlight significant accuracy gains and multi-turn tool use exceeding 40 turns, outperforming prior agentic search models.
Large-Scale Asynchronous RL for Long-Horizon Agentic Search: An Analysis of ASearcher
Introduction
The paper "Beyond Ten Turns: Unlocking Long-Horizon Agentic Search with Large-Scale Asynchronous RL" (2508.07976) addresses the limitations of current open-source LLM-based search agents in handling complex, long-horizon information-seeking tasks. The authors introduce ASearcher, an open-source framework that leverages fully asynchronous reinforcement learning (RL) and large-scale synthetic data generation to train agents capable of expert-level "Search Intelligence." The work demonstrates that prior approaches are fundamentally constrained by short tool-use horizons and insufficient data complexity, and provides empirical evidence that scaling both trajectory length and data difficulty is critical for robust agentic search.
Limitations of Existing Approaches
Current open-source agentic search systems, such as Search-R1 and prompt-based LLM agents, are limited by (1) artificially small turn limits (≤10), which preclude the emergence of complex, multi-step strategies, and (2) a lack of high-quality, challenging QA data. These constraints result in agents that are unable to decompose ambiguous queries, resolve conflicting information, or perform deep cross-document reasoning.
A detailed case study on the GAIA benchmark illustrates these deficiencies. Search-R1-32B fails to break down complex queries and exhibits hallucinations, while prompt-based agents like Search-o1 (QwQ) can perform extensive tool calls but lack the reasoning capacity to extract and verify key information. In contrast, ASearcher-Web-QwQ demonstrates uncertainty-aware reasoning, precise extraction from noisy content, cross-document inference, and grounded verification.
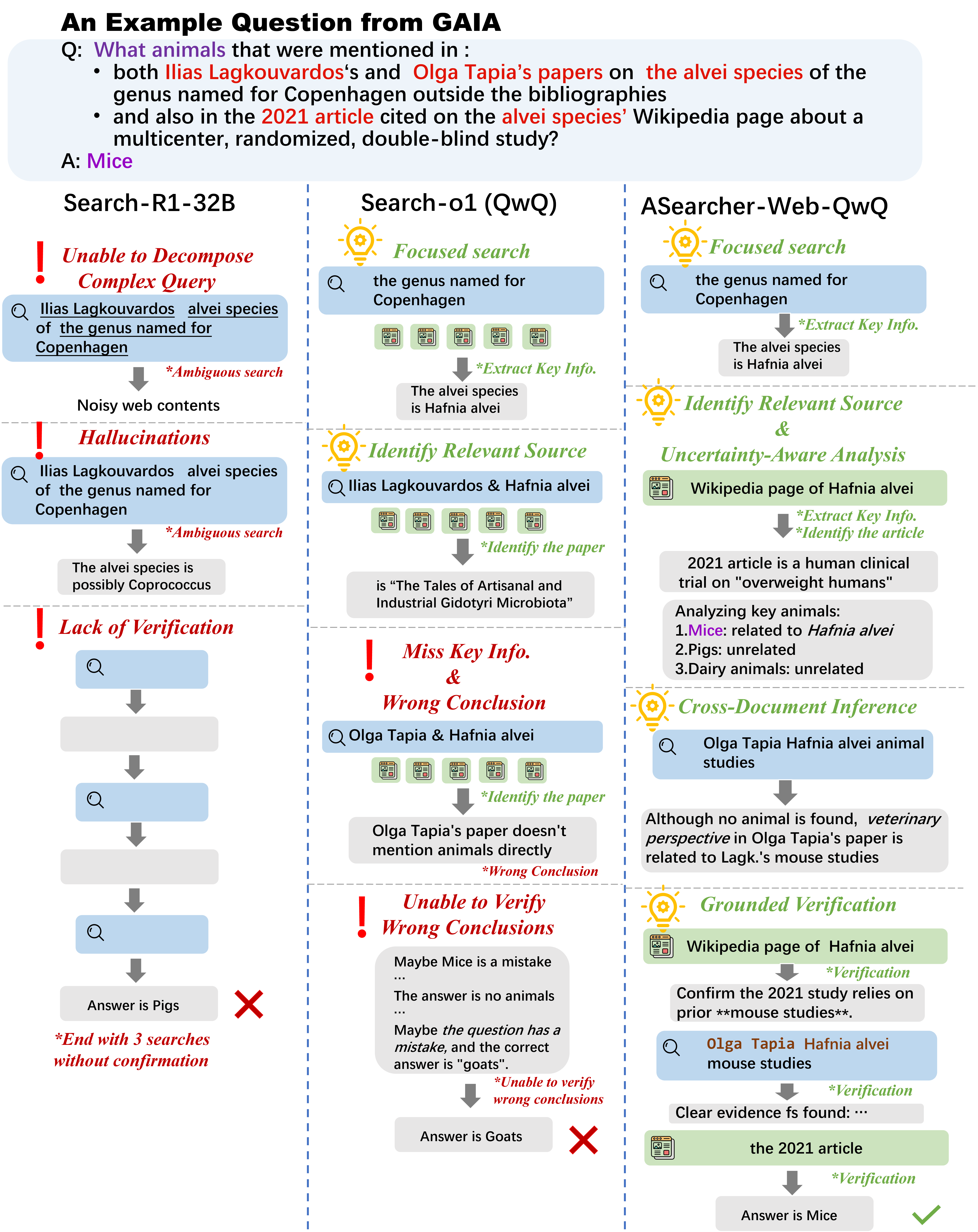
Figure 1: ASearcher-Web-QwQ exhibits expert-level search behaviors on a complex GAIA query, outperforming Search-R1-32B and Search-o1 (QwQ) in decomposition, extraction, and verification.
ASearcher: System Design
Agent Architecture
ASearcher employs a minimalistic agent design with two core tools: a search engine and a web browser. The agent is responsible for both issuing search queries and browsing web content, with an explicit summarization step for long documents. All agent outputs—including reasoning, tool calls, and summarization—are optimized end-to-end via RL.
For base LLMs (e.g., Qwen2.5-7B/14B), an append-only prompting strategy is used, while for advanced LRMs (e.g., QwQ-32B), the system maintains a compact, context-limited history to ensure efficient token usage.
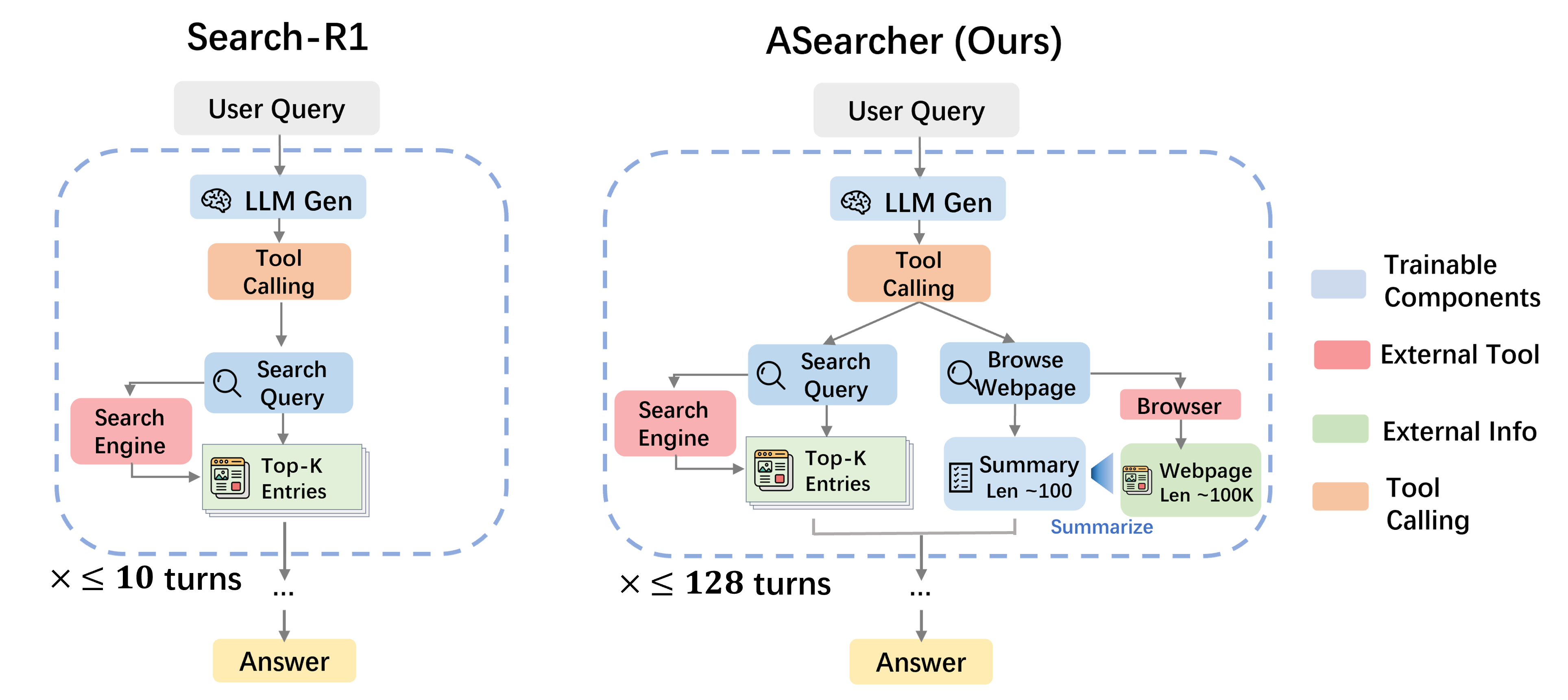
Figure 2: Comparison between ASearcher and Search-R1, highlighting ASearcher's unified reasoning and summarization capabilities via end-to-end RL.
Data Synthesis Pipeline
A key innovation is the data synthesis agent, which autonomously generates challenging QA pairs by iteratively applying two actions: Injection (adding external facts to increase complexity) and Fuzzing (obscuring information to increase uncertainty). Each synthetic question undergoes multi-stage validation for quality, difficulty, and answer uniqueness.
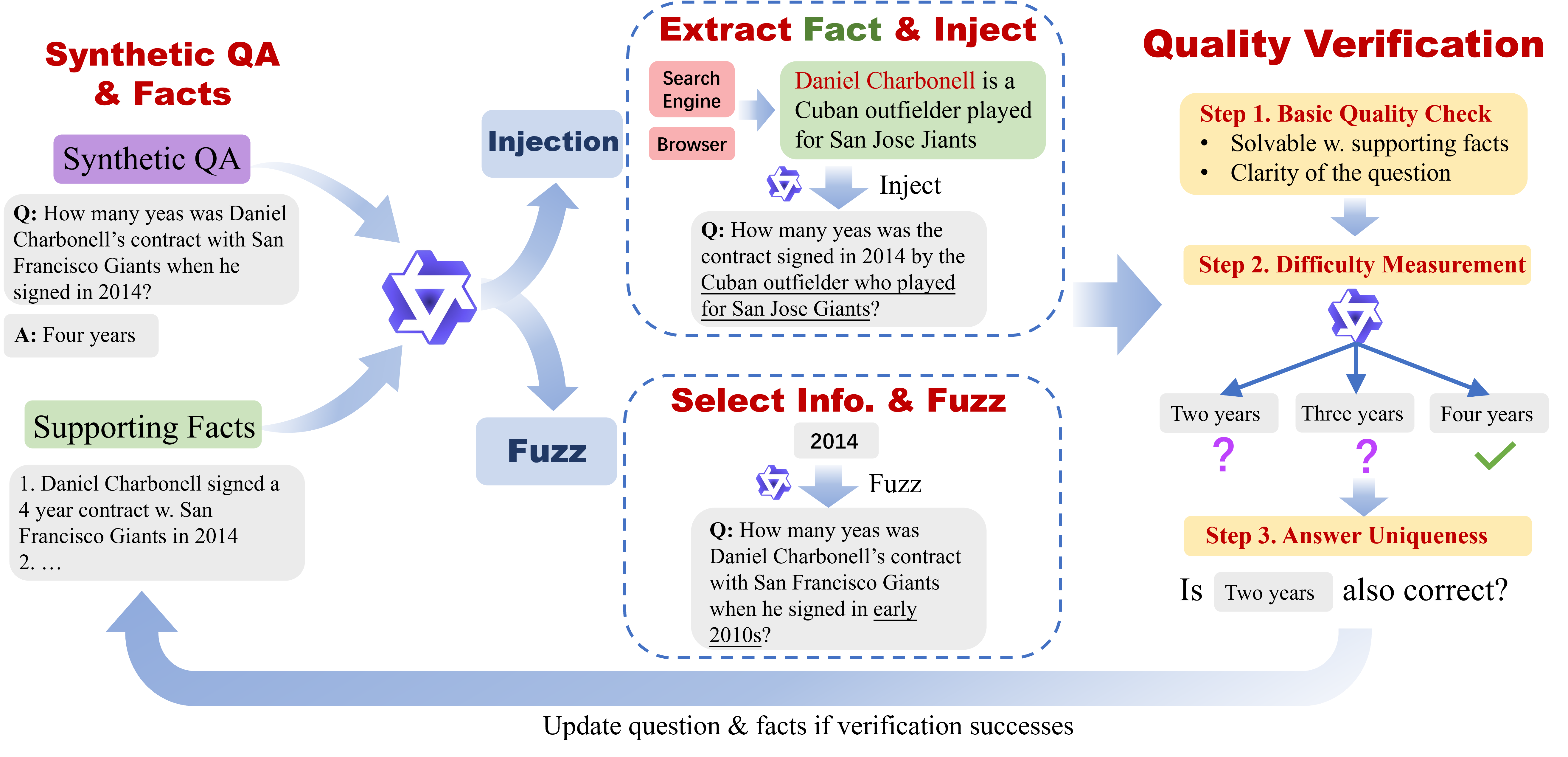
Figure 3: The data synthesis agent iteratively injects and fuzzes facts, with quality verification at each step to ensure challenging, grounded QA pairs.
The resulting dataset is significantly more difficult than existing open-source corpora, with a high proportion of questions requiring multi-turn tool use and cross-document reasoning.
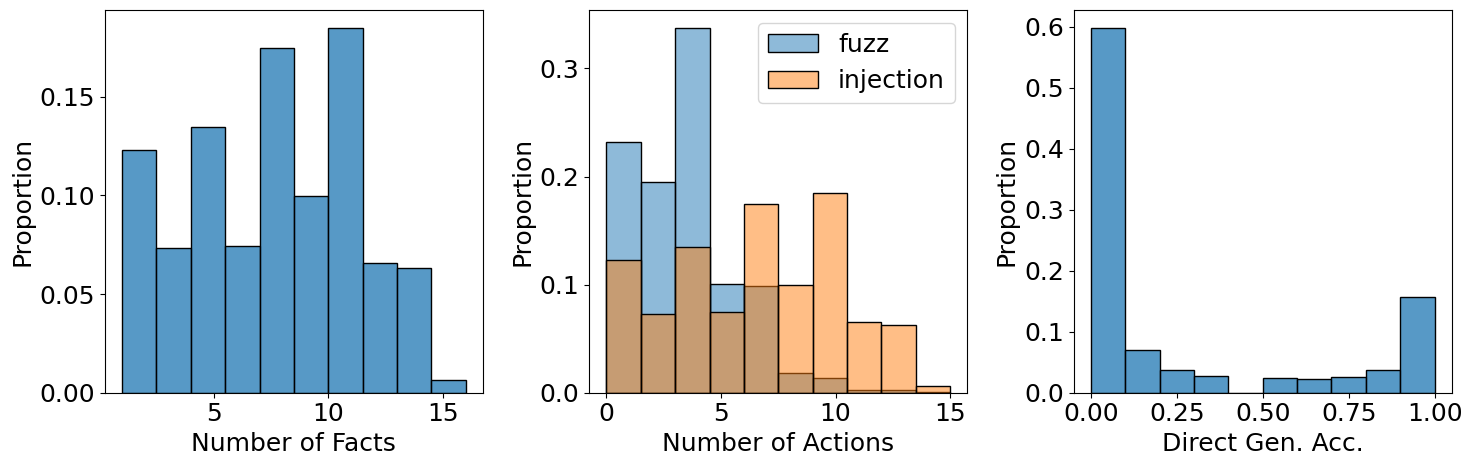
Figure 4: Statistics from the data synthesis process, showing distributions of supporting facts, injection/fuzz actions, and LRM answerability.
Fully Asynchronous RL Training
ASearcher introduces a fully asynchronous RL training paradigm, decoupling trajectory rollout from model updates and allowing each trajectory to proceed independently. This design eliminates the bottleneck of synchronous batch RL, where the slowest (longest) trajectory dictates overall throughput, and enables the use of large turn limits (up to 128 per trajectory).
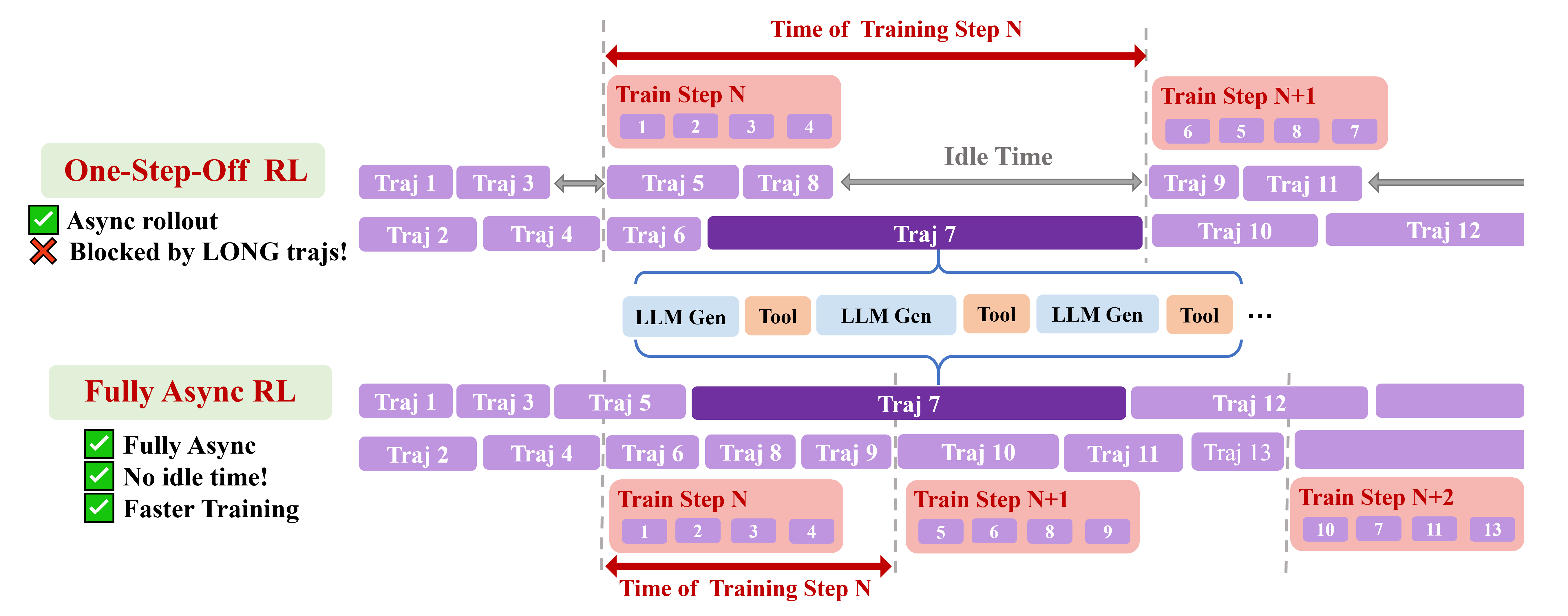
Figure 5: Fully asynchronous RL achieves near-full resource utilization by decoupling trajectory generation and model updates, in contrast to batch-based RL.
Empirical analysis shows that longer trajectories are essential for solving complex tasks, and that asynchronous training is necessary to maintain efficiency as trajectory length and variance increase.
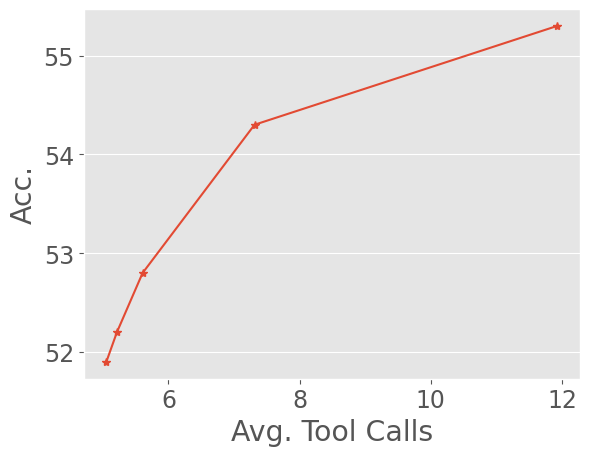
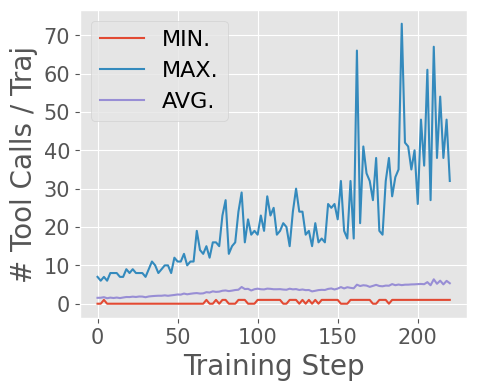
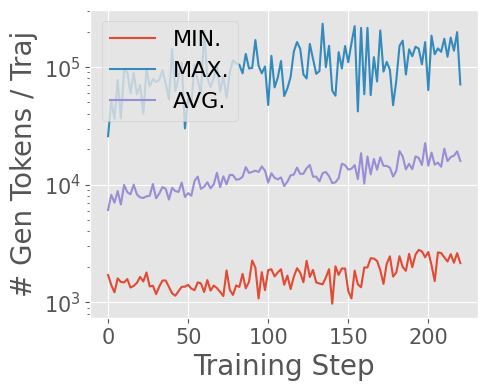
Figure 6: Test scaling of ASearcher-Web-QwQ demonstrates that accuracy improves with increased minimum tool-use turns, confirming the need for long-horizon trajectories.
Experimental Results
Benchmarks and Metrics
ASearcher is evaluated on a comprehensive suite of single-hop and multi-hop QA benchmarks, including HotpotQA, 2WikiMultiHopQA, MuSiQue, Bamboogle, and challenging real-world tasks such as GAIA, xBench-DeepSearch, and Frames. Metrics include F1, LLM-as-Judge (LasJ), Avg@4, and Pass@4.
Main Findings
- ASearcher-Local-14B achieves state-of-the-art performance on multi-hop and single-hop QA with local RAG, outperforming larger 32B baselines.
- ASearcher-Web-QwQ surpasses all open-source 32B agents on GAIA (Avg@4: 52.8, Pass@4: 70.1) and xBench-DeepSearch (Avg@4: 42.1, Pass@4: 68.0).
- RL training yields substantial improvements: +46.7% Avg@4 on xBench, +20.8% on GAIA, and +20.4% on Frames.
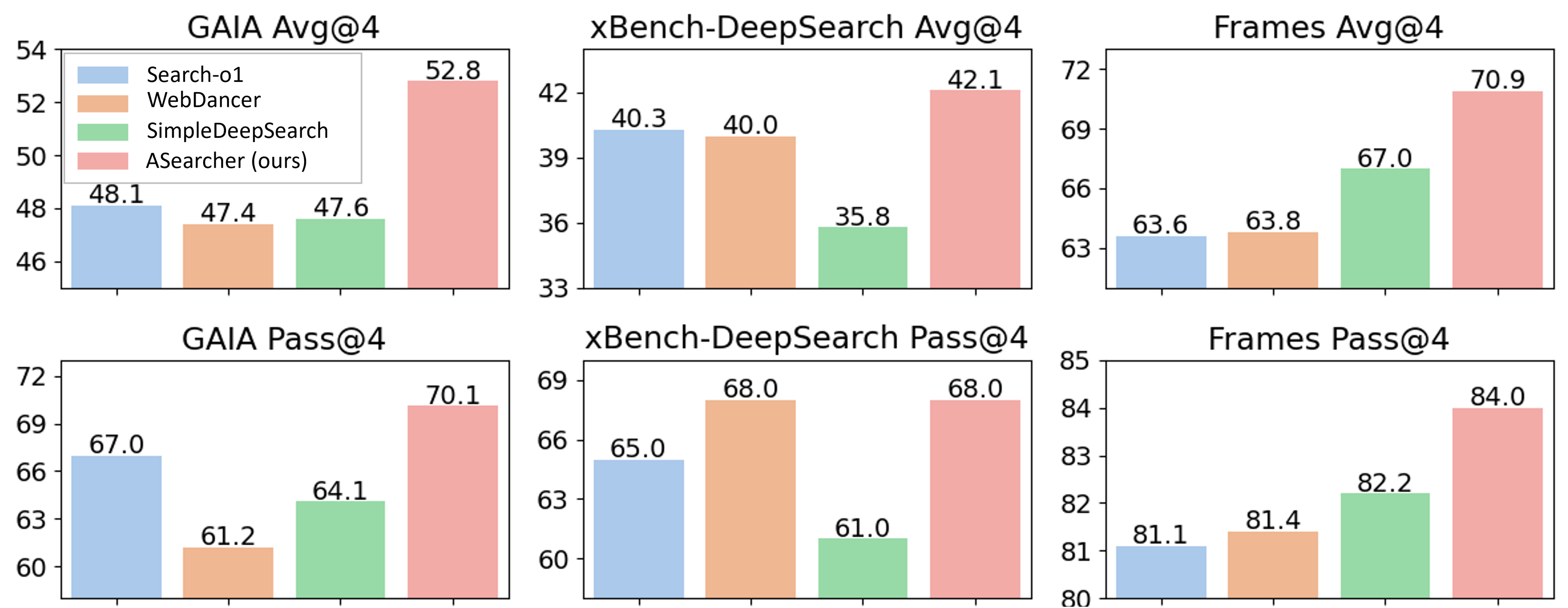
Figure 7: Avg@4 and Pass@4 of ASearcher-Web-QwQ compared to other 32B-scale agents, demonstrating superior performance.
- The agent learns to perform extreme long-horizon search, with tool calls exceeding 40 turns and output tokens surpassing 150k during training.
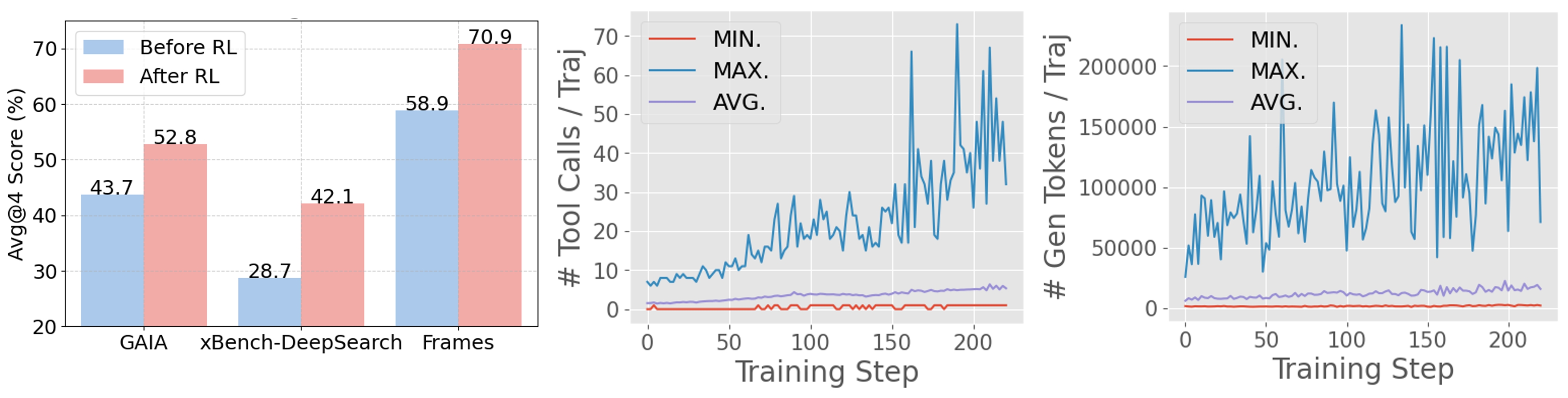
Figure 8: Asynchronous RL enables ASearcher-Web-QwQ to achieve substantial improvements and long-horizon tool use during training.
- Ablation studies confirm that the synthetic data pipeline is critical: RL on this data yields ≥10% higher accuracy than RL on standard multi-hop QA data.
Qualitative Analysis
Case studies on GAIA reveal that ASearcher-Web-QwQ can decompose complex queries, perform stepwise deduction, and verify conclusions, while baselines either hallucinate or fail to extract/verify key information.
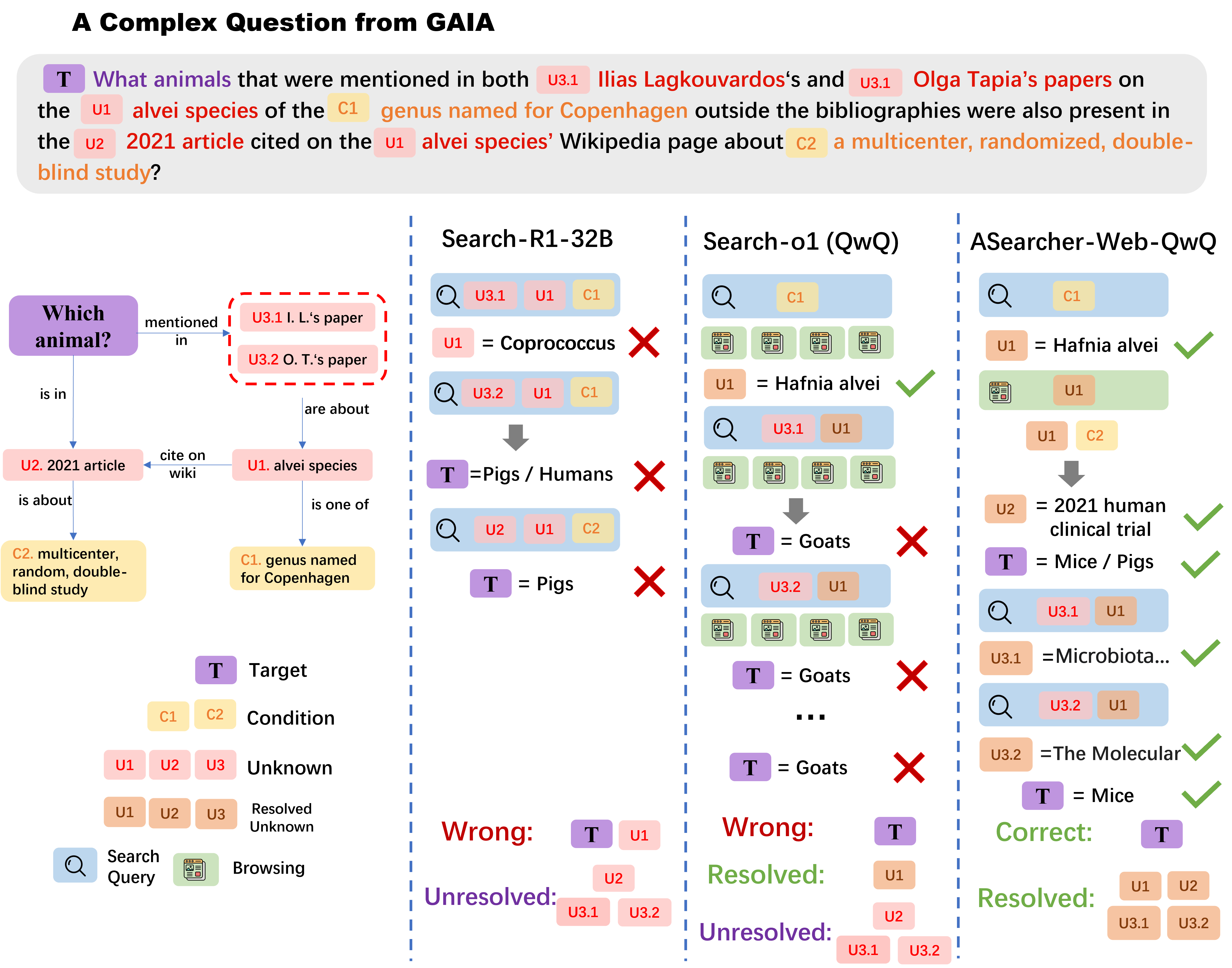
Figure 9: ASearcher-Web-QwQ resolves all unknown variables in a complex GAIA query via precise queries, multi-turn tool calls, and stepwise deduction.
Implementation Considerations
- Resource Requirements: Training ASearcher-Web-QwQ at 32B scale requires ~7.6k H800 GPU hours, with batch sizes of 64–128 and turn limits up to 128.
- Scalability: The fully asynchronous RL system is essential for scaling to long trajectories and large models; synchronous or batch-based RL is not viable for this regime.
- Data Quality: The effectiveness of the agent is contingent on the quality and difficulty of the synthetic QA data; rigorous multi-stage validation is necessary to avoid trivial or ambiguous questions.
- Deployment: The agent design is compatible with both local RAG and real web environments, and does not require external LLMs for summarization or reasoning.
Implications and Future Directions
This work demonstrates that scaling both trajectory length and data complexity is necessary and sufficient for training open-source agents with expert-level search intelligence. The fully asynchronous RL paradigm is a critical enabler for this scaling, and the synthetic data pipeline provides a practical solution to the lack of challenging QA data.
The implications are significant for the development of generalist LLM agents capable of robust, long-horizon reasoning and tool use in open environments. Future research may extend these methods to broader domains (e.g., scientific discovery, legal reasoning), integrate additional tools (e.g., code execution, structured databases), and further optimize the efficiency of asynchronous RL at even larger scales.
Conclusion
ASearcher establishes a new standard for open-source agentic search by combining fully asynchronous RL with large-scale, high-quality synthetic data. The system achieves state-of-the-art results on challenging benchmarks, demonstrates the necessity of long-horizon trajectories, and provides a scalable, reproducible framework for future research in agentic LLMs. The open-sourcing of models, data, and code further accelerates progress in this domain.