- The paper presents a novel tree search algorithm that integrates with LM agents to enhance planning and decision-making in complex web environments.
- It employs a model-based value function with best-first search, achieving a 39.7% improvement on VWA tasks and 28.0% on WA tasks.
- The method mitigates common LM failure modes by using backtracking and trajectory pruning to effectively navigate vast action spaces.
Tree Search for LLM Agents
The paper "Tree Search for LLM Agents" explores the integration of tree search algorithms with LLM agents, specifically aiming to enhance their capability to perform multi-step planning and exploration in web environments. The authors propose a novel inference-time search algorithm that improves the performance of LLM agents on challenging web tasks, effectively leveraging environmental feedback to navigate vast action spaces.
Introduction
Existing LLM (LM) agents demonstrate proficiency in natural language understanding and generation but often struggle with tasks requiring complex reasoning, planning, and environmental feedback processing. In open-ended web environments, the action space can be vast, necessitating efficient exploration and trajectory pruning to achieve task objectives. The authors propose a best-first tree search algorithm operating within the real environment to improve success rates on web tasks like VisualWebArena (VWA) and WebArena (WA).
The algorithm introduces a considerable increase in success rates over baseline models, showing a 39.7% improvement on VWA tasks and a 28.0% improvement on WA tasks when integrated with GPT-4o agents. These enhancements highlight the algorithm's potential to scale with increased test-time compute responsiveness, offering substantial progress toward autonomous web task execution.
Methodology
Agent Backbone
Most state-of-the-art agents utilize LLMs, often multimodal, conditioned on current observations to predict sequential actions. Strategies like ReAct, RCI, and CoT prompting support improved agent performance by enabling diverse sampling of possible action paths. The proposed tree search is compatible with and enhances these agent models by enabling broader and deeper exploration during inference.
Value Function
The authors employ a model-based value function to guide the search, estimating the expected reward associated with states. This heuristic aids in decision-making by evaluating environmental observations and task instructions to determine state success likelihood. Using a multimodal LM, they perform self-consistency prompting to refine these value estimates, enhancing search efficiency and reliability.
Search Algorithm
Inspired by A* search, the algorithm employs a best-first strategy augmented by LLM-driven action sampling. It iteratively constructs a search tree, evaluating nodes via the value function while expanding promising branches up to defined depths and budgets. This search method benefits from increased compute allowances, effectively managing expansive possibilities without becoming computationally prohibitive.
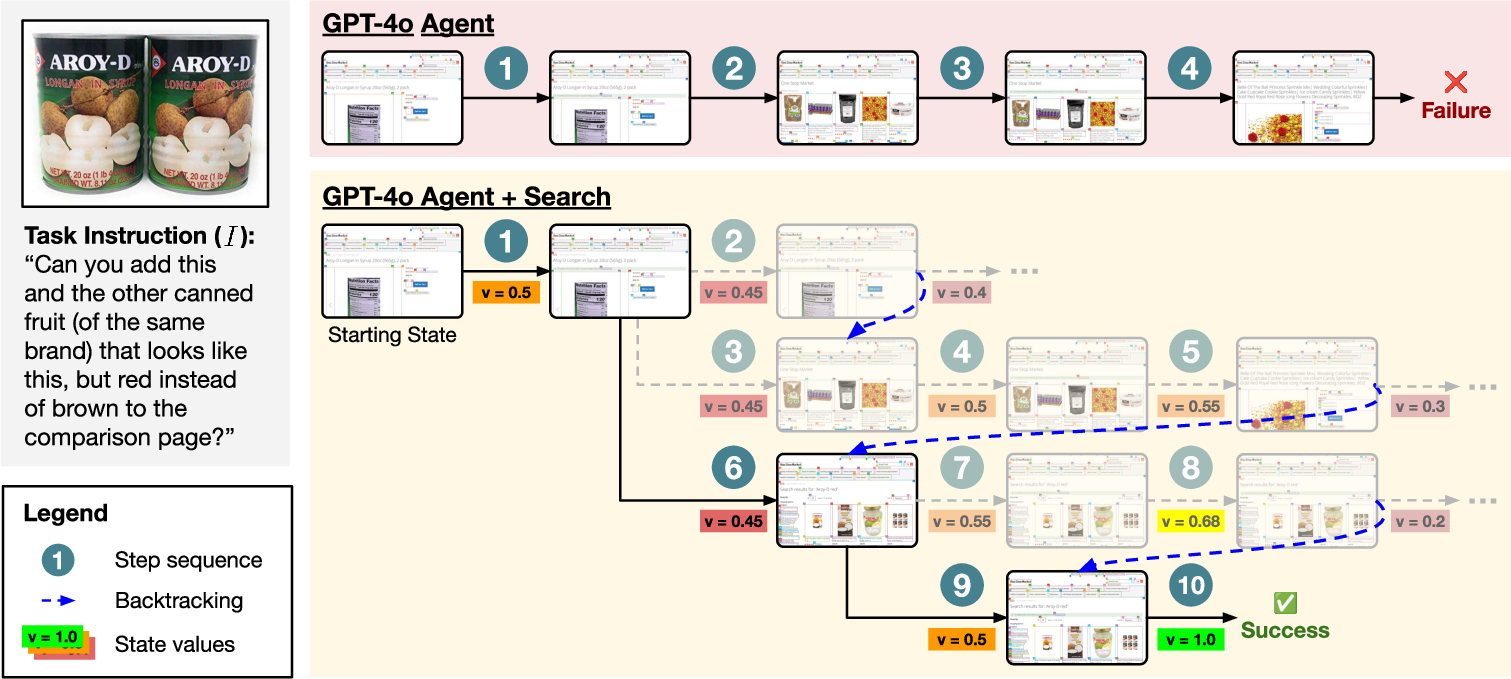
Figure 1: Our proposed search algorithm. At each iteration, we pick the next state sp to expand from frontier $\mathcal{F and compute a score$v$ for it using the value function.</p></p>
<h2 class='paper-heading' id='experimental-results'>Experimental Results</h2>
<p>Experiments conducted across 910 tasks on VWA and 812 on WA demonstrate significant improvements, setting new benchmarks in success rates with the tree search integration. The analysis reveals the search algorithm's capacity to leverage increased computing resources, manifesting notable improvements in task execution efficiency and accuracy under scaled parameters.
<img src="https://emergentmind-storage-cdn-c7atfsgud9cecchk.z01.azurefd.net/paper-images/2407-01476/search_budget_0.4.png" alt="Figure 2" title="" class="markdown-image" loading="lazy">
<p class="figure-caption">Figure 2: Success rate on a subset of 200 VWA tasks with search budget $c.c=0indicatesnosearchisperformed.Successrategenerallyincreasesasc$ increases.
Qualitative Analysis
The tree search methodology enhances robustness by allowing agents to explore beyond the first sampled action, effectively backtracking to prune non-viable paths. This approach addresses typical failure modes in LM agents—such as compounded errors and decision loops—by providing explicit rollbacks to alternative, potentially successful trajectories.
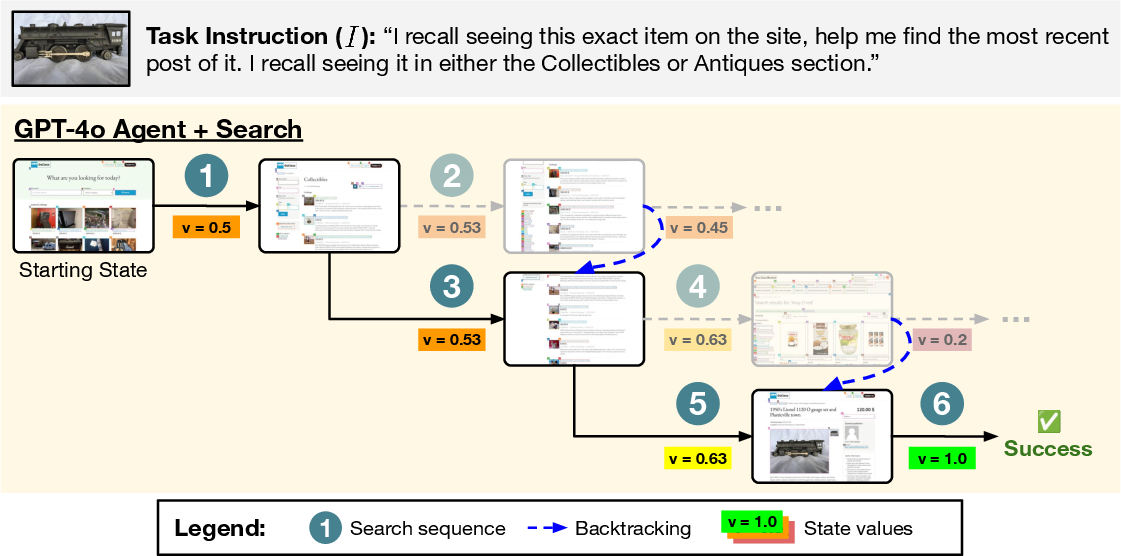
Figure 3: Search can improve robustness by backtracking from bad actions. Shown above is a trajectory for VWA classifieds task #48 where greedily picking the first sampled actions would have led to a failure (the path in the first row).
Limitations and Future Work
While effective, the current search implementation can be computationally expensive, notably due to the backtracking mechanism requiring full environment resets and action sequence replays. Practical deployment would require refined strategies to reduce overhead and potentially incorporate non-destructive action criteria. Future work might explore more sophisticated search algorithms or value functions that further streamline these processes, enhancing scalability and responsiveness in real-world applications.
Conclusion
This study introduces a meaningful advancement in LM agent capabilities through tree search integration, demonstrating improved success rates and efficiency in navigating complex web tasks. The algorithm provides a scalable framework for expanding web agent task capabilities, offering insights into broader applications requiring intricate planning and execution—making it a promising direction for future artificial intelligence research and development.